一文梳理主流大模型推理部署框架:vLLM、SGLang、TensorRT-LLM、ollama、XInference
大模型推理部署框架的选择应基于业务需求、硬件资源和未来扩展规划。vLLM和TensorRT-LLM在企业级高并发场景下表现最佳,SGLang在高吞吐量和多轮对话场景下具有明显优势,Ollama适合个人开发和快速原型验证,XInference和LightLLM则在分布式部署和边缘计算方面展现出潜力,LMDeploy和昇腾框架则在国产硬件适配上具有独特优势。
本文系统性梳理当前主流的大模型推理部署框架,包括vLLM、SGLang、TensorRT-LLM、Ollama、XInference等。
随着大语言模型技术的快速发展,推理部署框架作为连接模型与实际应用的关键环节,其重要性日益凸显。本文将对当前主流的vLLM、SGLang、TensorRT-LLM、Ollama和XInference等推理框架进行系统性梳理,从核心技术、架构设计、性能指标和适用场景等多个维度进行深入分析,为大模型部署选型提供参考依据。
一、vLLM:基于PyTorch的高性能推理引擎
vLLM[1](Vectorized Large Language Model Serving System)是由伯克利大学团队开发的开源推理框架,专注于解决大模型服务中的显存效率与吞吐量瓶颈。
其核心技术创新在于引入了**PagedAttention(分页注意力)和Continuous Batching(连续批处理)**两大关键技术,通过借鉴操作系统内存分页管理思想,显著提升了显存利用率和推理吞吐量。
项目地址:https://github.com/vllm-project/vllm.git

1、核心技术特点
vLLM的核心架构基于PyTorch,但通过深度优化实现了高性能。其核心技术亮点包括:
- PagedAttention[2] :借鉴了操作系统的分页机制,将注意力键值对(KV Cache)存储在非连续显存空间。传统的大模型推理需要为每个请求的序列分配连续的显存块,而vLLM将KV Cache划分为固定大小的"页",动态分配和复用显存空间,解决了显存碎片化、预留浪费和并发限制三大瓶颈。这种设计使得显存利用率从传统框架的60%提升至95%以上,支持处理更多并发请求。
PagedAttention:KV 缓存被划分为块;块在内存空间中不需要连续。
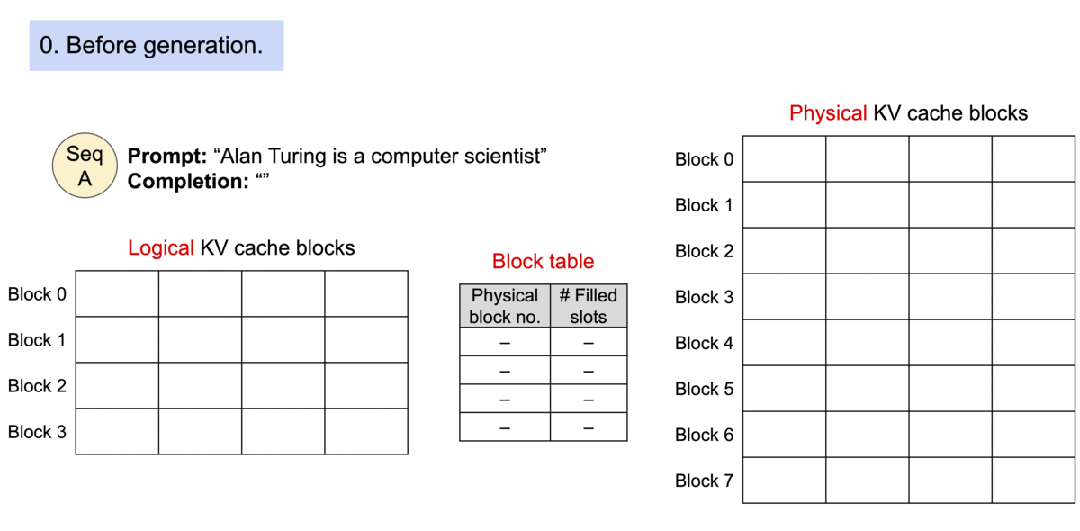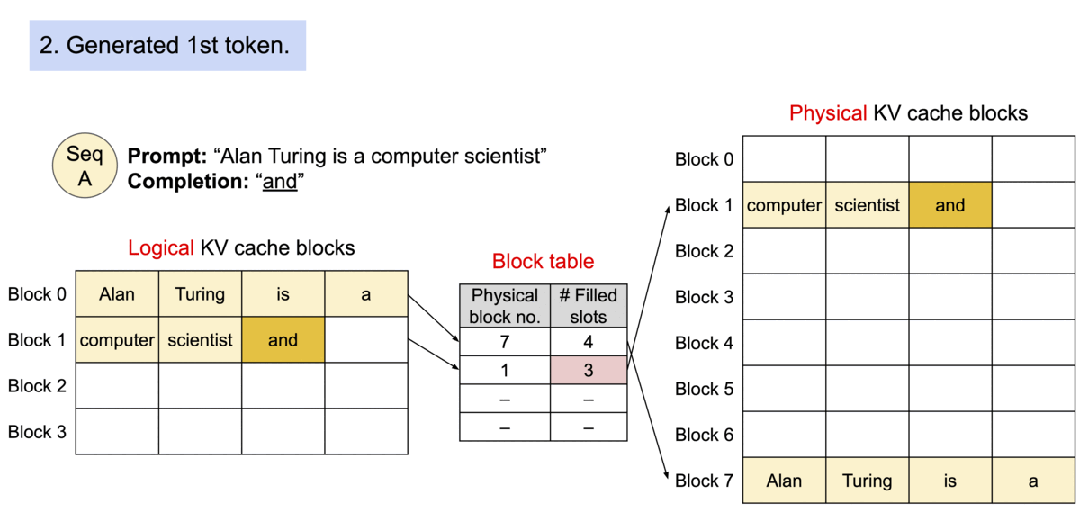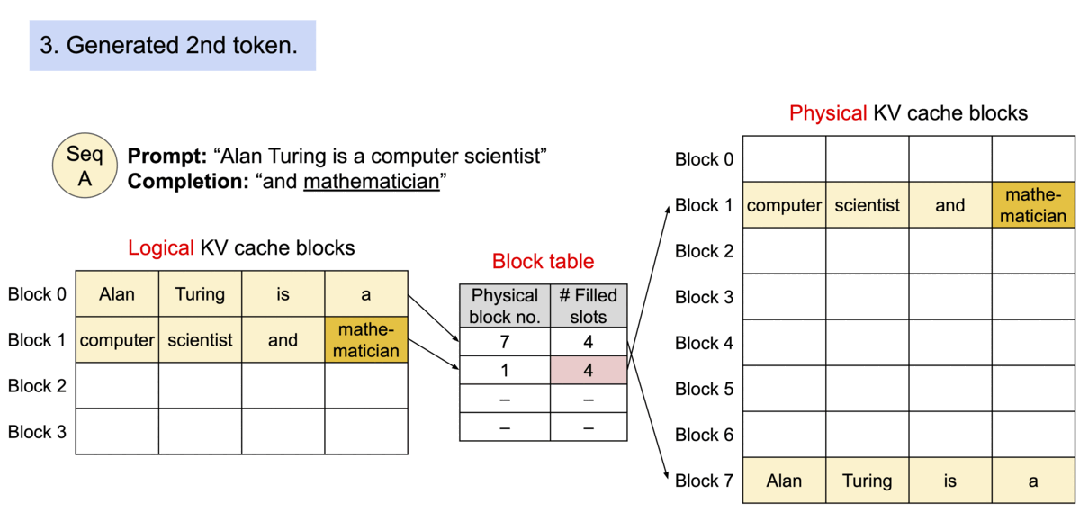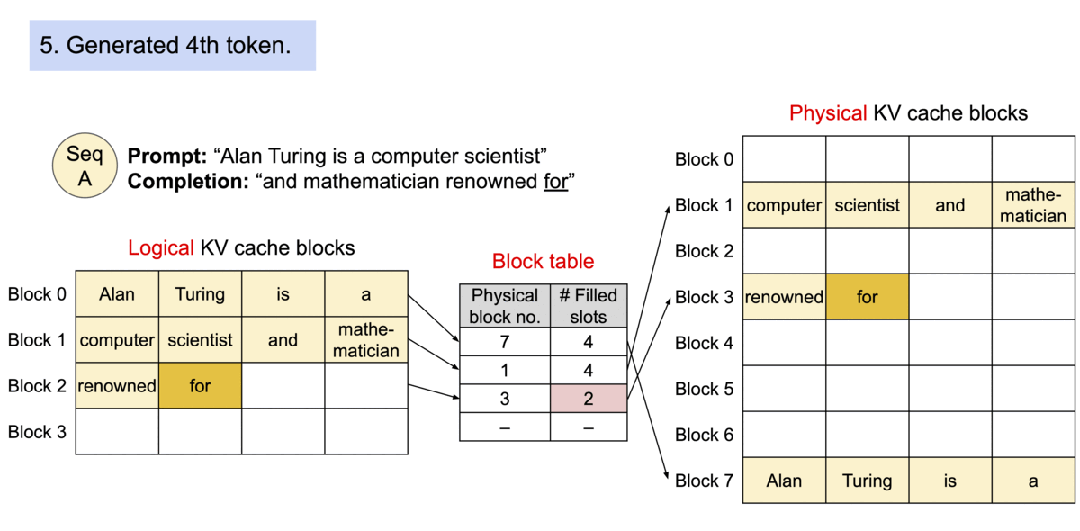
使用 PagedAttention 的请求示例生成过程
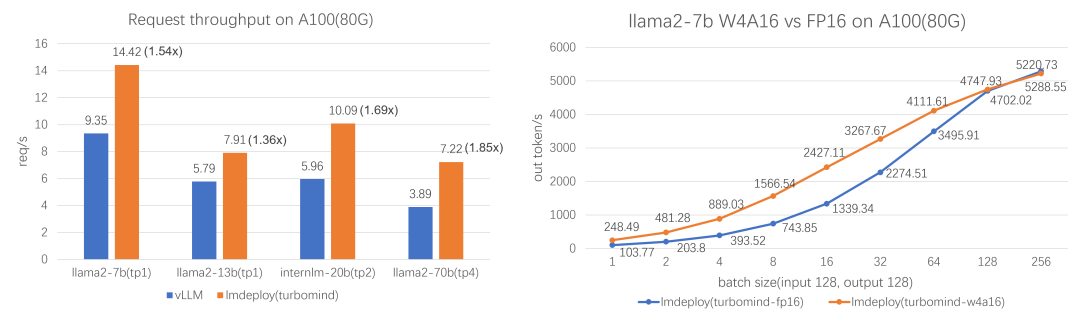
- Continuous Batching[3]:摒弃了传统的等待凑批处理模式,能够实时将新请求动态加入处理队列,确保GPU持续处于工作状态。这种技术使vLLM在高并发场景下保持较低的TTFT(首字出词时间),在Llama3.1-170B-FP8单H100测试中,TTFT仅为123ms,比TensorRT-LLM(194ms)和SGLang(340ms)表现更优。
- 多卡并行优化:支持张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism),通过NCCL/MPI等通信库实现模型权重的智能切分与同步,既优化了内存使用,又提升了整体计算性能。
- 量化优化支持 :内置 GPTQ[4]、AWQ[5] 等量化技术,有效压缩模型体积,进一步提升 GPU 资源利用率。
2、适用场景与优势局限分析
适用场景:vLLM特别适合企业级高并发应用,如在线客服、金融交易和智能文档处理等对延迟与吞吐量要求极高的场景。其在单卡和多卡部署中均能保持较低的TTFT,适合需要快速响应的实时应用。
| 优势 | 局限 |
|---|---|
| (1)高并发处理能力,支持横向扩展至多机多卡集群(2)显存利用率高达95%以上,显著降低硬件成本(3)支持多种Transformer架构模型,兼容性良好(4)提供生产级API服务,易于集成到现有系统 | (1)依赖高端GPU(如A100、H100),硬件投入成本较高(2)代码复杂度高,二次开发门槛较大(3)在极低延迟场景下可能不如TensorRT-LLM表现优异(4)分布式调度在超大规模集群中仍需优化 |
二、SGLang:基于Radix树的高吞吐推理引擎
SGLang[6] 是由伯克利团队开发的另一款大模型推理引擎,专注于提升LLM的吞吐量和响应延迟,同时简化编程接口。
其核心技术是RadixAttention,通过高效缓存和结构化输出优化,为高并发场景提供解决方案。
项目地址:https://github.com/sgl-project/sglang

1、核心技术特点
SGLang的核心创新在于引入了RadixAttention技术和结构化输出机制:
- RadixAttention[7] :利用Radix树管理KV缓存的前缀复用,通过LRU策略和引用计数器优化缓存命中率。与传统系统在生成请求完成后丢弃KV缓存不同,SGLang系统将提示和生成结果的缓存保留在基数树中,实现高效的前缀搜索、重用、插入和驱逐。这种技术使得SGLang在多轮对话和规划任务中表现突出,测试显示在Llama-7B上跑多轮对话,吞吐量比vLLM高5倍。
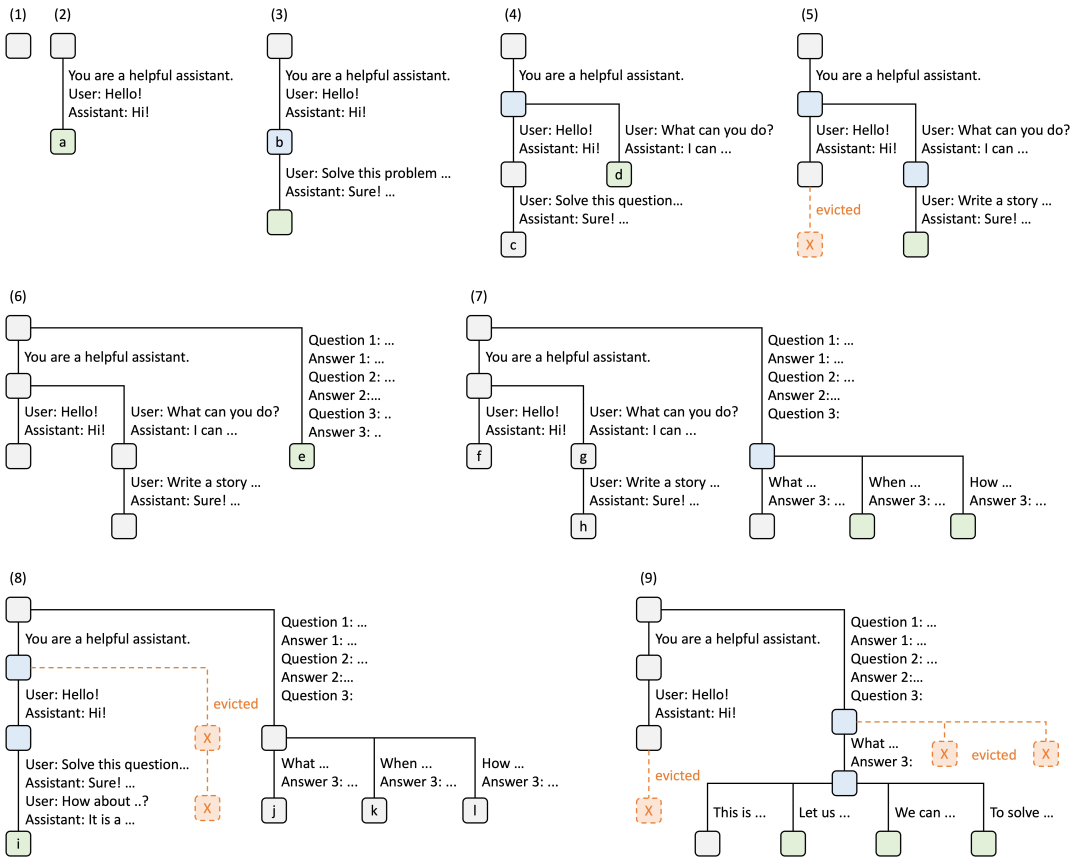
RadixAttention 操作示例,采用 LRU 驱逐策略,展示了九个步骤
- 结构化输出:通过正则表达式实现约束解码,可以直接输出符合要求的格式(如JSON、XML),这对API调用和数据处理特别有帮助。这种机制使得SGLang在处理结构化查询时更加高效,减少了后处理的工作量。
- 轻量模块化架构:采用完全Python实现的调度器,虽然代码量较小,但扩展性良好。其架构支持跨GPU缓存共享,进一步减少多卡计算的浪费
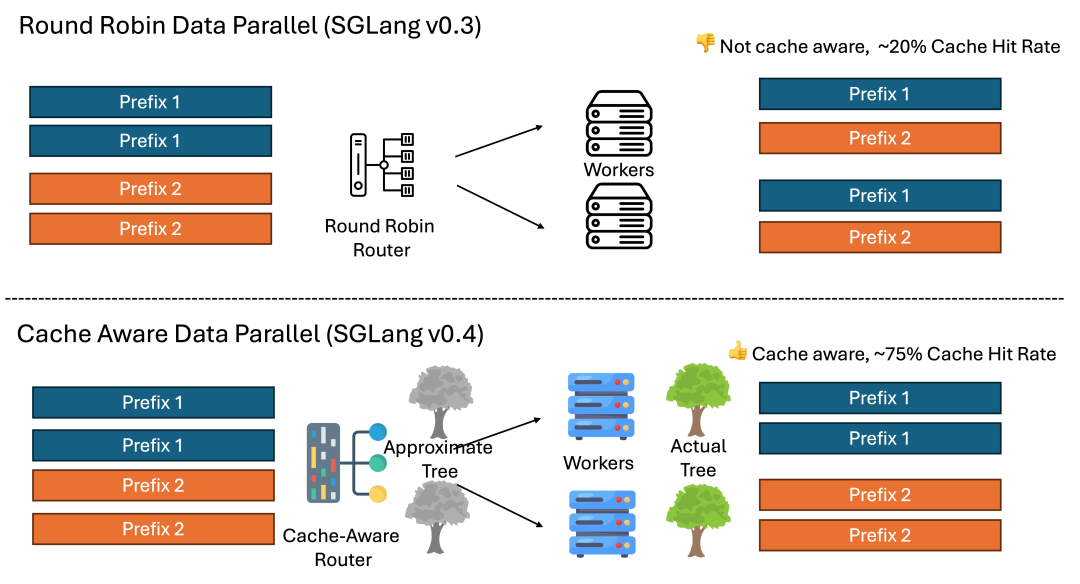
适用场景与优势局限
适用场景:SGLang特别适合需要高吞吐量的场景,如搜索引擎API、金融交易系统和实时数据处理平台等。其在处理结构化输出和多轮对话任务时具有明显优势。
| 优势 | 局限 |
|---|---|
| (1)超高吞吐量,在多轮对话场景下性能提升5倍 (2)极低响应延迟,适合高并发实时响应场景(3)结构化输出能力,减少后处理工作量(4)Python实现,代码简洁易懂(5)支持跨GPU缓存共享,减少多卡计算浪费 | (1)对多模态任务支持能力有限,生态尚在起步阶段 (2)对某些模型(如Mistralv0.3)的优化不足,性能可能不理想(3)扩展性受限于Python调度器,超大规模集群部署可能面临挑战 |
三、TensorRT-LLM:NVIDIA的深度优化推理引擎
TensorRT-LLM[8] 是NVIDIA推出的基于TensorRT的深度优化推理引擎,专为大语言模型设计,旨在充分发挥NVIDIA GPU的计算潜力。
项目地址:https://github.com/NVIDIA/TensorRT-LLM
1、核心技术特点
TensorRT-LLM的核心技术包括:
- 预编译优化:通过TensorRT的全链路优化技术,对模型进行预编译,生成高度优化的TensorRT引擎文件。这种预编译过程虽然带来冷启动延迟,但能显著提升推理速度和吞吐量。
- 量化支持:支持FP8、FP4和INT4等多种量化方案,通过降低计算精度减少显存占用和提升推理速度。在FP8精度下,TensorRT-LLM能实现接近原生精度的性能,同时显存占用减少40%以上。
- 内核级优化:针对Transformer架构的各个计算模块(如注意力机制、前馈网络等)进行深度优化,实现高效的CUDA内核。这种优化使得TensorRT-LLM在NVIDIA GPU上表现出色。
- 张量并行与流水线并行:支持多GPU协同工作,通过张量并行和流水线并行扩展模型规模,提高推理吞吐量
2、适用场景与优势局限
**适用场景:**TensorRT-LLM特别适合对延迟要求极高的企业级应用,如实时客服系统、金融高频交易和需要快速响应的API服务。
| 优势 | 局限 |
|---|---|
| (1)极低延迟,TTFT表现优异 (2)高吞吐量,适合大规模在线服务(3)充分发挥NVIDIA GPU优势,性能接近硬件极限(4)生态成熟,与NVIDIA整个AI生态无缝集成 | (1)仅限NVIDIA CUDA平台,跨平台部署存在局限 (2)预编译过程可能带来较长的冷启动延迟(3)对非NVIDIA GPU(如AMD或国产芯片)支持有限(4)定制化优化能力不如开源框架灵活 |
四、Ollama:轻量级的本地推理平台
Ollama[9] 是由AI社区开发的轻量级本地推理平台,专注于简化大模型本地部署和运行,特别适合个人开发者和研究者。
项目地址:https://github.com/ollama/ollama
1、核心技术特点
Ollama的核心技术特点包括:
- 基于Go语言的封装:Ollama基于Go语言实现,通过模块化封装将模型权重、依赖库和运行环境整合为统一容器。这种设计使得用户无需关注底层依赖,仅需一条命令行即可启动模型服务。
- llama.cpp集成:Ollama封装了llama.cpp,一个高性能的CPU/GPU大语言模型推理框架,支持1.5位、2位、3位、4位、5位、6位和8位整数量化。
- 跨平台支持:全面支持macOS、Windows和Linux系统,特别适合ARM架构设备,如苹果M系列芯片。
- 本地化部署:支持完全离线运行,确保数据安全与隐私,适合对本地数据保护有高要求的应用。
- 低硬件门槛:无需高端GPU,支持消费级设备和边缘设备运行,降低了大模型部署的硬件要求
2、适用场景与优势局限
适用场景:Ollama特别适合个人开发者、教育展示和本地隐私要求高的场景,如个人知识库、教育演示和原型验证等。
| 优势 | 局限 |
|---|---|
| (1)安装便捷,一键部署,无需复杂配置 (2)低硬件要求,支持消费级设备和边缘设备 (3)数据离线保障,适合隐私敏感场景 (4)易于上手,适合非专业开发者使用 (5)启动速度快,冷启动时间仅12秒左右 | (1)并发处理能力较弱,不适合大规模在线服务 (2)扩展性和插件定制能力有限,难以满足复杂业务需求 (3)仅支持文本生成类LLM(如Llama系列、Mistral),多模态支持不足 (4)性能优化不足,在高负载场景下可能无法满足需求 |
五、XInference:分离式部署的分布式推理框架
XInference[10] 是一个高性能的分布式推理框架,专注于简化AI模型的运行和集成,特别适合企业级大规模部署。
项目地址:https://github.com/xorbitsai/inference

1、核心技术特点
XInference的核心架构:
- API层:基于FastAPI构建,提供RESTful接口和OpenAI兼容接口,便于与现有应用集成。
- Core Service层:引入自主研发的Xoscar框架,简化分布式调度和通信任务,支持多卡并行和Kubernetes集群扩展。
- Actor层:由ModelActor组成,负责加载和执行模型任务。每个ModelActor分布在ActorPool中,可以独立运行和管理。
- 分离式部署:将模型的Prefill(初始计算)和Decode(生成阶段)分配到不同GPU,利用DeepEP通信库加速KVCache传输,提升资源利用率。
- 算子优化:在Actor层引入FlashMLA/DeepGEMM算子,适配国产海光DCU和NVIDIA Hopper GPU,提升计算效率。
- 连续批处理:结合vLLM的连续批处理技术,优化请求调度,提高GPU利用率
2、适用场景与优势局限
适用场景:XInference特别适合企业级大规模部署,如智能客服系统、知识库问答和需要分布式扩展的场景。
| 优势 | 局限 |
|---|---|
| (1)分布式推理能力,支持Kubernetes集群扩展 (2)分离式部署优化资源利用率,提升吞吐量(3)支持多模态任务(如文本转语音、图像标注) (4)冷启动时间短,适合快速部署 (5)与Dify等应用平台无缝集成,构建端到端解决方案 | (1)分布式调度复杂度高,运维门槛较大(2)依赖DeepEP通信库,跨平台兼容性受限(3)多模态支持仍在完善中,部分功能可能不成熟(4)社区生态相对年轻,文档和案例支持不足 |
六、LightLLM:轻量级高性能推理框架
LightLLM[11] 是一个基于Python的LLM推理和服务框架,以轻量级设计、易于扩展和高速性能而闻名。
项目地址:https://github.com/ModelTC/LightLLM

1、核心技术特点
LightLLM的核心技术包括:
- 三进程异步协作:将tokenization、模型推理和detokenization三个过程分别交给不同进程处理,实现异步执行,减少I/O阻塞。
- 动态批处理:根据请求特性和系统负载情况,智能调整批处理策略,平衡吞吐量和延迟。
- TokenAttention机制:以token为单位的KV缓存内存管理,实现内存零浪费,支持int8 KV Cache,可将最大token处理量提升约两倍。
- 零填充(nopad-Attention) :能够高效处理长度差异较大的输入序列,避免传统填充方式带来的计算资源浪费。
- FlashAttention集成:显著提升注意力计算速度,同时降低GPU内存占用。
- 张量并行技术:支持多GPU进行张量并行计算,加速大规模模型的推理过程
2、适用场景与优势局限
适用场景:LightLLM特别适合需要高吞吐量的场景,如大规模语言模型API服务、多模态模型在线推理和高并发聊天机器人后端等
| 优势 | 局限 |
|---|---|
| (1)高吞吐量,Llama2-13B吞吐量达480 tokens/s (2)显存占用低,资源利用率高 (3)支持边缘设备部署,如智能手机和IoT设备 (4)模块化设计,易于扩展和定制 (5)支持多种模型架构,兼容性良好 | (1)边缘设备上的具体性能数据尚未公开(2)多模态支持仍在完善中,部分功能可能不成熟(3)分布式部署能力不如XInference和vLLM成熟(4)社区生态相对年轻,文档和案例支持不足 |
七、国产硬件适配框架:昇腾与LMDeploy
随着国产AI芯片的发展,针对昇腾等国产硬件的推理框架也日益成熟。昇腾AI处理器和LMDeploy是国产硬件适配的代表。
1、昇腾AI处理器框架
昇腾AI处理器是华为基于自研达芬奇架构开发的AI加速芯片,其推理框架主要包括:
- MindSpore Inference[12] :华为开发的推理框架,基于昇腾达芬奇架构,支持On-Device执行(整图下沉至芯片)、算子融合(如矩阵乘法与激活函数合并)和静态图优化,提升推理性能 。
- CBQ量化技术:华为诺亚方舟实验室联合中科大开发的跨块重建后训练量化方案,仅用0.1%的训练数据,一键压缩大模型至1/7体积,浮点模型性能保留99%,真正实现"轻量不降智" 。
- 昇腾CANN软件栈:提供多层次编程接口,通过开发AscendCL和TBE编程接口,使不同AI应用可在CANN平台上高效快速地运行 。
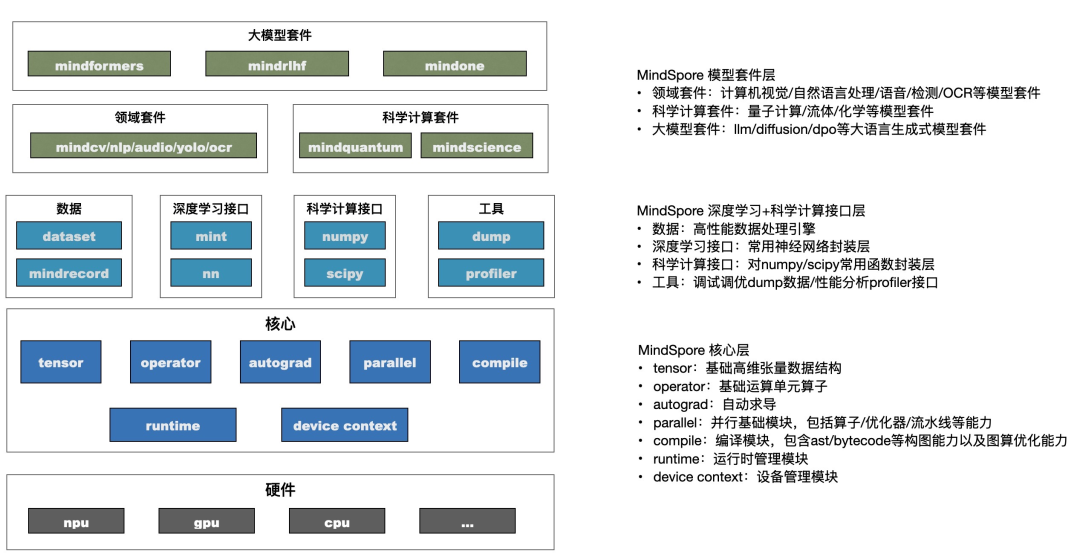
2、LMDeploy:视觉语言混合任务专家
LMDeploy[13]是由上海人工智能实验室模型压缩和部署团队开发的部署工具箱,专注于大语言模型和视觉语言模型的部署。
核心技术:
- 国产GPU深度适配,针对昇腾等国产硬件进行优化
- 显存优化,通过动态量化和模型切分降低显存占用
- 多模态融合支持,同时处理视觉和语言数据
- TurboMind引擎,提供高效的4bit推理CUDA kernel
3、适用场景:
国内企业、政府机构部署,视觉语言混合任务。
八、框架选型对比与适用场景分析
| 技术优势 | 适用场景 | |
|---|---|---|
| vLLM | 适合动态批处理与多GPU扩展,TTFT表现优异,适合需要快速响应的场景 | 企业级高并发应用 |
| TensorRT-LLM | 在低延迟场景下表现最佳,适合对响应速度要求苛刻的生产级应用 | 企业级高并发应用 |
| SGLang | 在高并发稳定吞吐方面表现突出,适合需要持续高吞吐的场景 | 企业级高并发应用 |
| XInference | 提供分离式部署和分布式能力,适合需要快速验证分布式场景的开发者 | 企业级高并发应用 |
| Ollama | 安装便捷,支持跨平台,冷启动速度快,适合轻量级实验 | 个人开发与本地原型 |
| Llama.cpp | 零硬件门槛,适合无GPU环境下的基础推理,如物联网设备 | 个人开发与本地原型 |
| LightLLM | 轻量级设计,支持边缘设备部署,吞吐量表现优异 | 边缘设备部署 |
| LMDeploy | 针对昇腾等国产硬件深度优化,多模态支持能力强,适合视觉语言混合任务 | 国产硬件部署 |
| 昇腾框架 | 支持Qwen2.5-Omni等全模态模型,扩展至3D、视频、传感信号等全模态场景 | 国产硬件部署 |
写在最后
大模型推理部署框架的选择应基于业务需求、硬件资源和未来扩展规划。vLLM和TensorRT-LLM在企业级高并发场景下表现最佳,SGLang在高吞吐量和多轮对话场景下具有明显优势,Ollama适合个人开发和快速原型验证,XInference和LightLLM则在分布式部署和边缘计算方面展现出潜力,LMDeploy和昇腾框架则在国产硬件适配上具有独特优势。
零基础如何高效学习大模型?
你是否懂 AI,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和鲁为民博士系统梳理大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!
【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)