体系结构论文(107):AscendOptimizer: Episodic Agent for Ascend NPU Operator Optimization
AscendOptimizer: Episodic Agent for Ascend NPU Operator Optimization
这篇文章讲的是什么
这篇文章关注的是华为 Ascend NPU 上的 AscendC operator optimization。
它不是做“从零生成一个 kernel”,而是做:
如何在极度缺少公开经验、缺少训练数据的情况下,把已有 AscendC operator 持续优化得更快。
作者提出的核心系统叫 `AscendOptimizer`。它把一个 Ascend operator 拆成两个耦合部分:
1. host 侧的 tiling program
2. device 侧的 kernel program
然后分别用两种不同策略去优化:
1. Stage I:对 host 侧 tiling 做 evolutionary-guided program search。
2. Stage II:对 kernel 侧代码做 optimization rewind + experience retrieval + guided rewriting。
最后在这两个阶段之间交替迭代。
简单说,这篇文章的核心观点是:
Ascend 上最缺的不是“一个万能模型”,而是“能自己积累优化经验的机制”。
为什么 Ascend operator 优化难
1. Ascend 和 CUDA 的差异不只是语法差异
文章在引言里借 Table 1 强调了一件事:通用甚至前沿模型在 CUDA 上还能做出像样结果,但在 AscendC 上几乎崩掉。
Table 1 里:
1. DeepSeek-R1 在 CUDA 上 Pass@1 为 52.6%,在 AscendC 上只有 1.4%。
2. Claude Sonnet 4 在 CUDA 上 47.0%,在 AscendC 上 2.1%。
3. Qwen3-235B 在 CUDA 上 44.2%,在 AscendC 上 0.7%。
这不是“差一点”,而是两个数量级的差距。
作者认为这背后不是简单的语法问题,而是知识稀缺问题:
1. Ascend 公开实现少。
2. host-kernel 协同知识难学。
3. buffer、tiling、pipeline、同步这些低层细节不在通用语料里。
2. Ascend operator 不是一段单体 kernel
AscendC operator 是一个“两段式工件”:
1. host 侧 tiling program:决定怎么分块、怎么搬数据。
2. device 侧 kernel code:决定怎么调度计算、怎么做 pipeline。
很多小白会误以为“kernel 优化”就是改 kernel 本体,但在 Ascend 上不是。性能往往由这两部分共同决定。
所以文章不是把优化问题看成“改一段代码”,而是看成:
一个 host-side tiling + device-side kernel 的联合优化问题。
3. 为什么不能只靠传统搜索
因为这个空间非常离散、非凸,而且充满隐式约束:
1. tile 稍微改一下就可能 UB 爆掉。
2. 某个数据搬运策略改一下就编译失败。
3. kernel 层面的同步、映射、pipeline 又有另一套结构性规律。
所以作者认为:
1. tiling 更像强约束、离散、脆弱的程序搜索问题。
2. kernel rewrite 更像结构化模式迁移问题。
这就是后面双阶段设计的理论基础。
一. Introduction
作者先从大模型训练和推理开讲,说现在模型越来越大,算力越来越关键,而operator 是 computation graph 的原子执行单元,它直接影响:
- 训练吞吐
- 在线推理延迟。
这段的意思很标准:
硬件峰值再高,算子写得差,实际性能也起不来。
为什么需要自动优化
作者指出,未优化算子通常吃不到硬件性能,原因包括:
- memory bandwidth wall
- 复杂的 instruction pipeline constraints
- 编译成功率低
- profiling 噪声大。
所以“算子自动优化”就成了一个桥梁问题:
一边连接上层算法,一边连接底层硬件。
为什么 GPU 上好做,Ascend 上难做
这一部分是全文最重要的逻辑铺垫。
CUDA 生态为什么能成功
作者说 NVIDIA GPU 这边已经形成了一整套自动优化技术路线:
- 早期:TVM、Ansor 这种搜索型 autotuning
- 后来:Astra、PRAGMA 这种 LLM/agent 驱动优化
- 再往后:基于 profiling、compiler feedback、硬件反馈的闭环优化。
关键原因不是“GPU 更容易”,而是:
GPU 有大量开源代码,提供了丰富的隐式优化模式。
换句话说,CUDA agent 能做起来,很大程度上是因为训练语料和先验太丰富了。
为什么迁移到 Ascend 很难
作者紧接着指出,把这套自动化方法照搬到 DSA/NPU 上会遇到严重问题,尤其是 Ascend:
- Ascend 用的是 Da Vinci architecture
- 它有显式管理的 memory hierarchy
- 不像 GPU 靠 cache 自动帮你处理很多事
- AscendC 需要开发者自己 orchestrate:
- 数据搬运
- UB 中数据布局
- 同步。
这里你可以把它理解成:
- GPU:很多细节被 runtime / compiler / cache 屏蔽了
- Ascend:很多细节要你亲自管
所以对 agent 来说,Ascend 优化更难,因为它不是纯粹“写个 kernel”就完事,而是得知道:
- UB 容量约束
- tile 怎么切
- 同步怎么放
- pipeline 怎么铺
- 搬运和计算怎么重叠
这属于更强的硬件感知软件优化。
作者说:
一个 AscendC operator 不是单体 kernel,而是一个 two-part artifact:
- host-side tiling program
- device-side kernel program
host-side tiling program 干什么
它决定:
- 输入怎么切块
- 一个 tile 多大
- 数据怎么搬到片上
- 搬几次
- 搬运和执行如何匹配
这本质上决定的是:
“where data move”
kernel program 干什么
它决定:
- 指令怎么发
- 计算怎么流水化
- SIMD / vector 指令怎么用
- 同步点怎么安排
这本质上决定的是:
“how instructions flow”
为什么单改 kernel 不够
作者明确说:
porting a kernel is insufficient: performance is co-determined by where data move and how instructions flow.
它的意思是:
- 在 GPU 上,你可能常常把优化理解成“把 kernel 写得更好”
- 但在 Ascend 上,kernel 再好,tiling 不对,也会慢
- 因为数据搬运和片上 buffer 利用本身就是性能决定因素
所以这篇文章不是单纯做 kernel rewrite,而是在做:
host tiling + device kernel 的联合优化
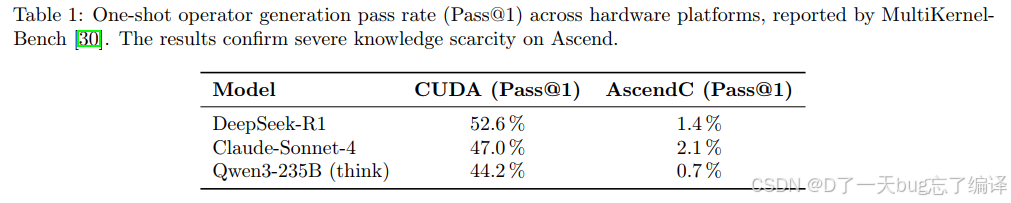
Table 1 给了一个非常关键的数据:
同样是 SOTA 大模型,CUDA kernel 的 one-shot generation pass rate 还能到 44%~52%,而 AscendC 只有 0.7%~2.1%。
这张表的意义
作者用这张表不是为了说“模型太弱”,而是为了证明:
Ascend 上的问题不是单纯语法问题,而是知识稀缺问题。
也就是说,大模型生成 AscendC 代码失败,不是因为不会写 C++ 风格代码,而是因为它不懂:
- tiling 约束
- pipeline orchestration
- buffer overflow 风险
- API 约束
- Ascend 特有执行模式。
所以这篇文章的方向不是继续赌“更强大模型一次写对”,而是转向:
通过反馈闭环 + 自举经验库,让优化过程可持续逼近正确解。
核心 insight
作者在这一段给出了全篇最核心的 insight:
when external data are insufficient, we can bootstrap experience internally by exploiting the structured nature of code.
翻成更直白的话就是:
既然外部没有足够的专家数据,那就从代码本身的结构性出发,自举出优化经验。
它后面分两部分讲:
对 tiling 来说
- tiling 空间不连续
- 稍微一改可能从“快”变成“编不过”
- 但这种脆弱性反过来也是优势
因为真实硬件反馈会直接告诉你: - 可行 / 不可行
- 快 / 慢。
所以 tiling 适合用硬件反馈驱动的搜索。
对 kernel 来说
- kernel 优化模式比较结构化
- 比如 pipelining、vectorization、latency hiding 这些是可迁移的
- 虽然没有现成 bad-to-good 数据
- 但你可以从好代码出发,故意 rewinding,自己造出 bad-to-good 轨迹。
所以 kernel 适合用经验抽取 + 检索增强重写。

Table 2 是一张定位自己方法贡献边界的表。
比较维度有三个:
- Optimizes Existing Impl.
- Automatic Optimization
- Training-free
几类方法对应关系大概是:
- ASPLOS’25 / Hermes:
- 能优化已有实现
- 但不是自动化 end-to-end
- 更偏专家主导分析优化
- AscendKernelGen:
- 自动生成
- 但不属于 training-free
- 更偏从零生成而不是优化现有实现
- AscendOptimizer:
- 优化已有实现
- 自动化
- training-free。
作者想占据的生态位很明确:
不是专家调优系统,不是重训练模型的方法,也不是只做从零生成;而是一个“不依赖额外训练”的现有 AscendC 算子自动优化系统。
二、方法
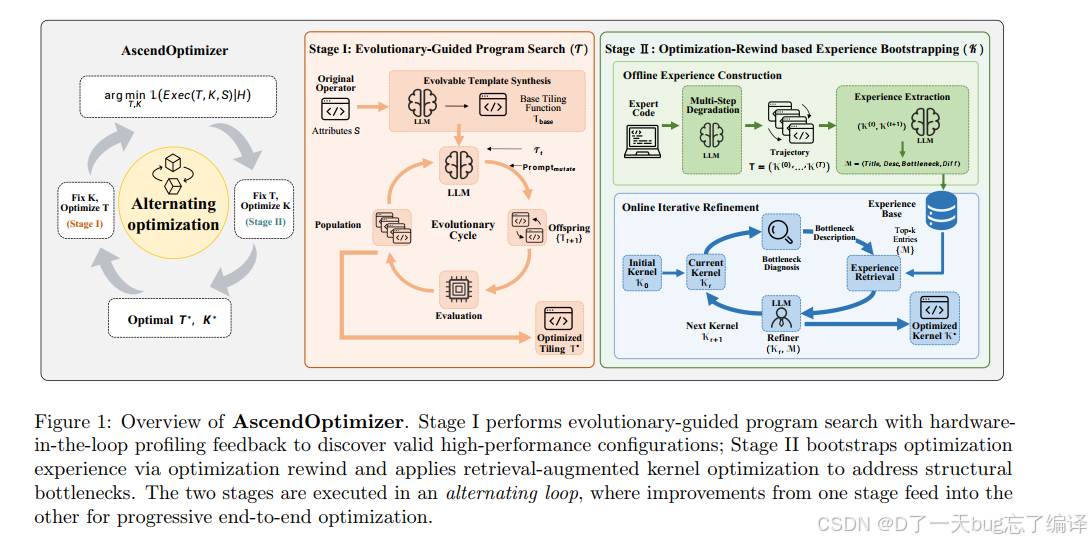
把 `AscendOptimizer` 分成两个阶段:
1. Stage I:Evolutionary-Guided Program Search
2. Stage II:Optimization-Rewind based Experience Bootstrapping
然后用 alternating optimization 的方式在两者之间切换。
作者的核心思想很聪明:
如果外部数据不够,那就从执行反馈和已有强实现里“自己长经验”。
具体来说:
1. 对 tiling,不依赖规则库,直接让硬件反馈告诉你什么可行、什么更快。
2. 对 kernel,不是盲目搜索,而是从少量好的 seed kernel 出发,故意把它们“去优化”,从而构造 bad-to-good 轨迹,再把这些优化经验存进可检索经验库。
这个想法比“再堆一点 prompt engineering”或者“直接全靠 RL 搜索”更有结构感。
Figure 1 里 Stage I 和 Stage II 并不是两个彼此独立的方法,而是对同一个目标的两种互补求解。
作者在文字里把它正式化成:
给定 operator `O = {T, K, S}`,
其中:
1. `T` 是 host 侧 tiling function
2. `K` 是 AI Core 上的 kernel code
3. `S` 是静态属性,如 shape、dtype、layout
优化目标是在真实硬件上最小化执行延迟。
Figure 1 真正想表达的是:
1. Stage I 通过硬件反馈去摸清可行 tiling 区域。
2. Stage II 通过经验库和语义改写去突破 kernel 结构瓶颈。
3. 两者交替迭代,因为更好的 tiling 会改变 kernel 可发挥空间,更好的 kernel 也会改变 tiling 的收益结构。
这就是典型的 alternating optimization 思路。
Stage I:Evolutionary-Guided Program Search
作者认为 tiling 优化的特点是:
1. 高度依赖 shape 和 layout。
2. 解空间不连续。
3. 很难抽象成通用规则。
所以他们不试图先手写规则库,而是把它建模成 program search。
具体来说:
1. 先构造一个 base tiling function 模板。
2. 在模板里放 evolution markers。
3. 让 LLM 基于这些可变位置做变异。
4. 再用真实 NPU 的 compile / execute / correctness 反馈作为 fitness。
这里的核心不是“用了 evolutionary search”,而是:
作者把硬件反馈本身当作边界探测器。
因为在 Ascend 上,可行域很脆:
1. 编译不过就说明违反约束。
2. 精度不对就说明语义错。
3. 延迟变好才说明真的有效。
这使得 Stage I 更像一种“在硬件围栏内的程序进化”。
Stage II:Optimization Rewind
Stage II 的想法非常值得单独讲。
作者观察到:
1. Ascend 上缺乏成体系的“差代码 -> 好代码”配对数据。
2. 但如果你手头有一小批不错的 kernel,其实可以反向构造这种数据。
怎么构造?
就是所谓 `optimization rewind`:
1. 从一个优化过的 expert kernel 出发。
2. 故意把其中某些优化去掉,也就是“去优化”。
3. 于是你就能得到 slow version 和 fast version 的差别。
4. 再总结出这次优化的 motif / strategy。
这本质上是在自己制造“bad-to-good trajectory”。
这个想法很聪明,因为它绕开了一个现实障碍:
没有人会系统保存“所有糟糕版本是怎么一步步被优化好的”,但你可以从好版本往回拆。
作者进一步把这些轨迹蒸馏成可检索的 experience bank,用于在线优化时的 retrieval-augmented rewriting。
这使得 Stage II 不是纯搜索,而是“带经验回放的结构化改写”。

Algorithm 1 的本质,是一个面向 Ascend 算子的交替优化框架:外层循环逐轮继承当前最优解,内层先在固定 kernel 下搜索更优 tiling,再在固定 tiling 下重写更优 kernel,并通过真实硬件上的编译、正确性和延迟反馈来筛选候选,最终得到联合优化后的最优实现。
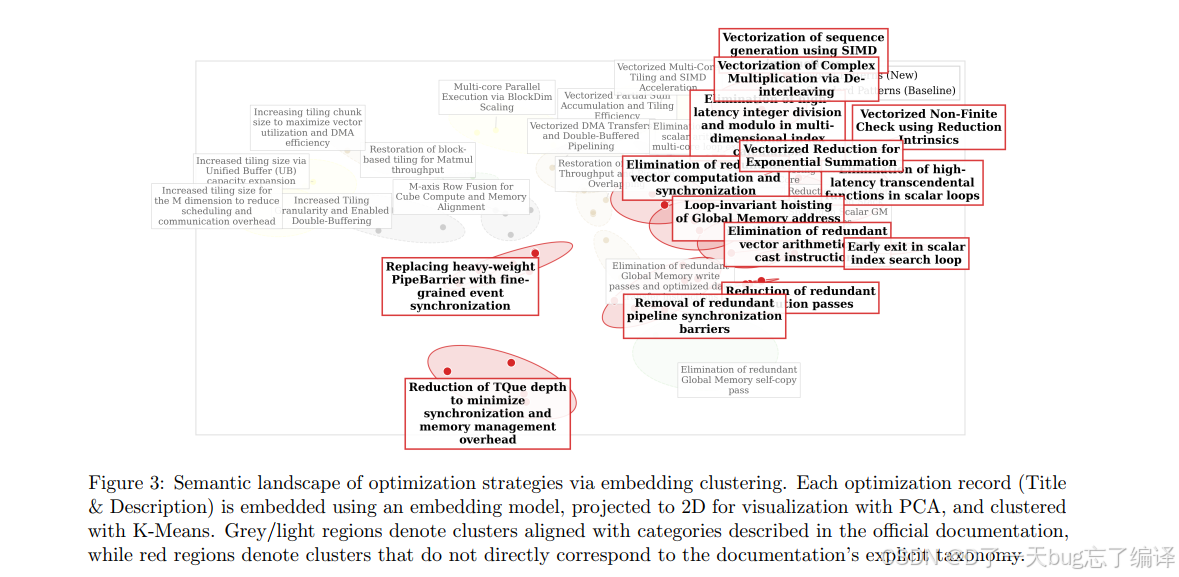
Figure 3 可视化了经验库里的优化策略语义聚类。
作者想说明两件事:
1. 有些 cluster 对应官方文档里的典型 best practice,例如 tiling、double buffering。
2. 还有一些 cluster 并不能直接映射到文档显式分类,比如更细粒度的同步、向量化非有限值检查、去高延迟标量指令等。
这张图的意义是:
经验库不只是把官方最佳实践重新抄了一遍,而是从实际 benchmark operator 里挖掘出一些“文档没系统整理、但真实反复出现”的模式。
这也是论文相对有说服力的地方。如果经验库只是文档摘录,那创新性会很弱;而 Figure 3 试图证明它确实挖到了额外结构。
Alternating Optimization
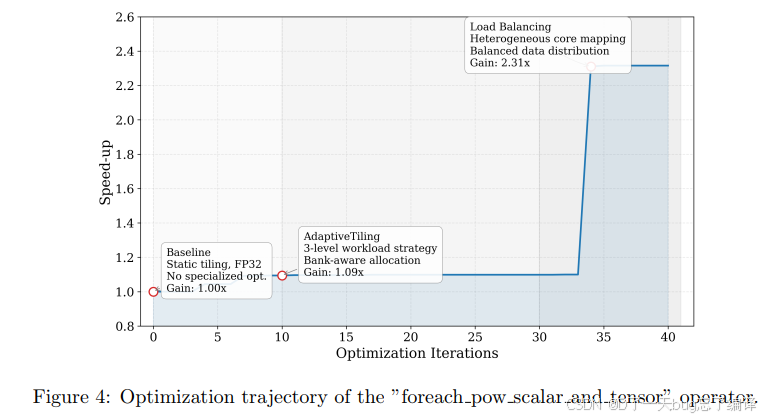
Figure 4 以 `foreach pow scalar and tensor` 为例展示优化轨迹。
这里作者每 10 次迭代切换一次 Stage I / Stage II。
图里看到的现象很有代表性:
1. Stage I 很快给出约 1.09x 提升。
2. 但之后会 plateau。
3. Stage II 通过经验检索和语义重写打破 plateau。
4. 在某个关键改写后速度直接跳到 2.31x。
这说明:
1. 仅靠 tiling/execution tuning 能吃掉一部分剩余空间。
2. 但真正大的突破往往来自 kernel 结构改写。

Figure 5 把其中一个关键 rewrite 展开:从 remainder-based per-core quota assignment 改成 block-level load balancing + nested scan across tensors。
简单理解就是:
原方法按余数分配任务,可能造成核间负载不均;
新方法按 block 更均匀地分配,并且做跨 tensor 的嵌套扫描,从而减少尾部不平衡,提高利用率。
这属于很典型、很硬核的性能优化逻辑。
三、实验
作者从 `cann-ops` 官方 AscendC operator 仓库里出发,筛出了 127 个 operator 作为最终测试集。
这里还有一个很重要的说明:
Stage II 构造经验库用的 seed kernels 就来自同一个 127-operator benchmark。
作者专门解释说,这不是传统机器学习意义下的 train/test leakage,因为他们不是在追求泛化评测,而是在做 training-free、episodic、transductive optimization。
这个解释在系统优化语境里是成立的。
换句话说,这篇文章不是在回答“你能不能泛化到一个完全没见过的 Ascend operator”,而是在回答“面对当前要优化的这批 operator,你能不能把它们调快”。
这两种问题不能混淆。
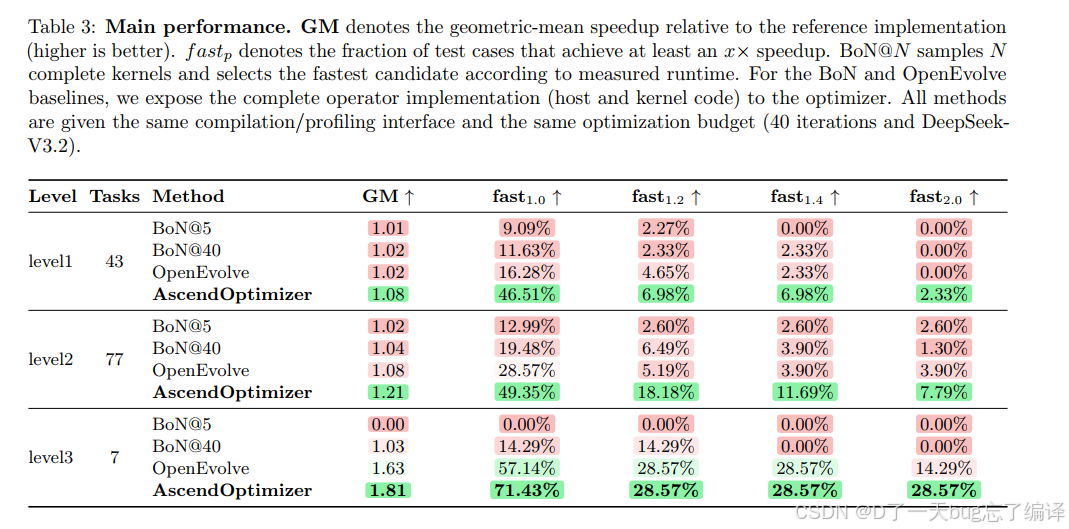
Table 3 报告了在 level1 / level2 / level3 上,BoN@5、BoN@40、OpenEvolve 和 AscendOptimizer 的表现。
指标包括:
1. GM:几何平均 speedup
2. `fast1.0`
3. `fast1.2`
4. `fast1.4`
5. `fast2.0`
先看总体趋势:
1. BoN 增加采样预算,从 5 到 40,只带来有限收益。
2. OpenEvolve 比 BoN 更强,说明迭代优化比单纯多采样更有效。
3. AscendOptimizer 在三层上都是最优。
具体看数值:
1. Level 1:GM 1.08,`fast1.0` 46.51%。
2. Level 2:GM 1.21,`fast1.0` 49.35%,`fast1.2` 18.18%。
3. Level 3:GM 1.81,`fast1.0` 71.43%,`fast2.0` 28.57%。
这里最值得注意的是:
1. Level 2 提升很扎实,说明方法对中等复杂 operator 很有效。
2. Level 3 样本只有 7 个,所以虽然结果亮眼,但统计稳定性有限,不能过度夸大。
总体来说,Table 3 能支持一个比较强的结论:
AscendOptimizer 相比纯采样和通用迭代优化框架,在 Ascend 场景下确实更有效。
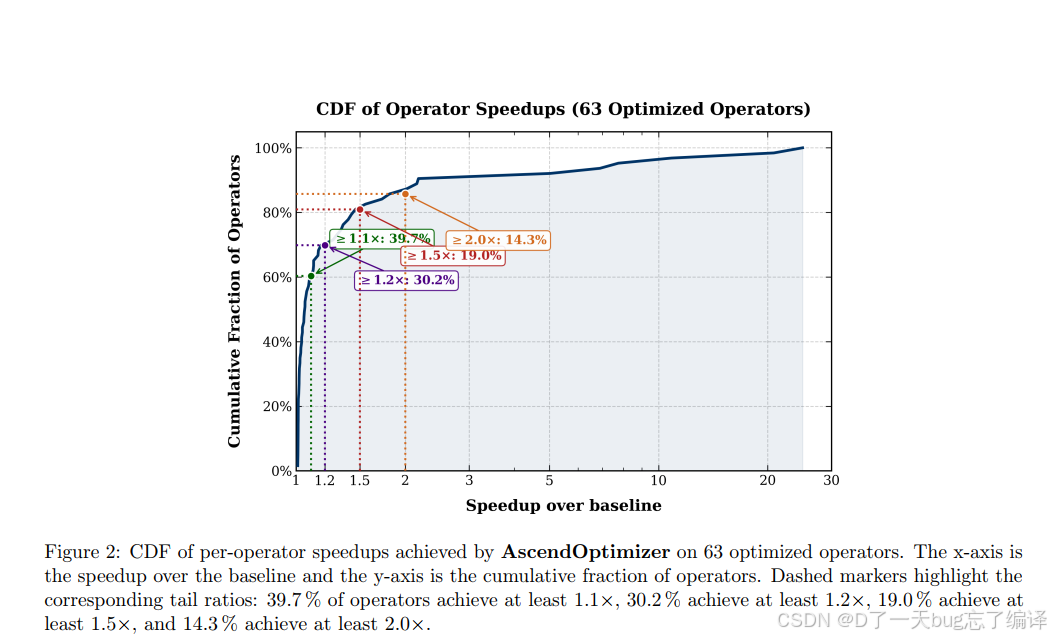
Figure 2 给的是 speedup 的 CDF。
这张图比单纯报 GM 更有意义,因为它说明:
1. 不只是个别 operator 被拉得特别高;
2. 而是有相当比例的 operator 获得了稳定中等提升;
3. 同时右侧长尾又表明少数 operator 能获得非常大收益。
作者给出:
1. 39.7% 的 operator 至少 1.1x
2. 30.2% 至少 1.2x
3. 19.0% 至少 1.5x
4. 14.3% 至少 2.0x
这张图增强了结果可信度,因为它显示收益不是完全由极端个例撑起来的。
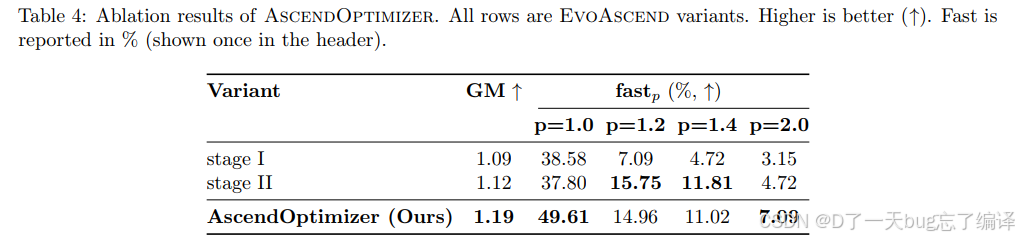
Table 4 对比:
1. 只有 Stage I
2. 只有 Stage II
3. 完整 AscendOptimizer
结果很有代表性:
1. Stage I:GM 1.09,`fast1.0` 38.58%,说明它善于保底、扩大可行解覆盖面。
2. Stage II:GM 1.12,`fast1.2` 和 `fast1.4` 更强,说明它更擅长做中高强度结构优化。
3. 完整系统:GM 1.19,`fast1.0` 和 `fast2.0` 最好。
这和作者的理论叙事是吻合的:
1. Stage I 更像参数/调度层面的外圈搜索。
2. Stage II 更像结构层面的内核重写。
3. 两者结合才能同时拉高平均水平和高端收益。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)