算力需求爆发,优刻得“国产智算+GPU切分”破解AI资源荒
考虑到数据向量化(3倍膨胀)与索引构建(1.15倍膨胀)带来的4倍整体数据膨胀,再叠加数据中心的3倍冗余需求(含复制、编码、系统开销及预留空间),若按11亿月活用户、单用户月均上传1GB RAG数据计算,年化原始数据量为66EB,实际所需的NAND存储容量则高达200EB。KV缓存动态内存:KV缓存的核心作用是避免注意力权重的重复计算,通过GQA技术优化后,单个token的KV缓存占用约480KB
内存迎来史上最强涨价周期,HBM与DDR5供需失衡,AI推理算力消耗在快速飙升——全球正走向一个“高成本算力时代”。面对行业算力告急,优刻得以大规模国产智算集群和新一代GPU虚拟化技术,为企业提供更可控、更高效的AI基础设施解法,让AI生产力在算力紧缩周期依然保持增长动能。

图片来源:Tiger Trade
12月4日,摩根士丹利中国团队在针对大中华区科技半导体的报告中指出,Memory市场正在酝酿一场供需错配的完美风暴。大摩的结论异常明确:内存超级周期不是尾声,而是才刚刚开始。
内存为什么涨价这么厉害
本轮内存价格上涨的核心原因可归结为供需失衡叠加市场情绪放大,具体如下:
-
需求端:AI大模型训练和推理的高速发展使得AI服务器对DRAM、HBM需求暴增,AI服务器和芯片研发服务器平均每台服务器内存达到2T-4T,同时消费电子新品备货、云厂商下单,多场景需求形成合力;
-
供给端:存储颗粒厂商如三星,海力士镁光等将产能转向高利润的DDR5、HBM,存储颗粒厂商把DDR4产线停工或升级至DDR5 ,且HBM良率低挤占晶圆,新产能落地周期长,传统内存供应缺口扩大;
-
市场端:经销商囤货溢价、模组厂批量采购消耗库存,市场需求被涨价效应恐慌性放大。
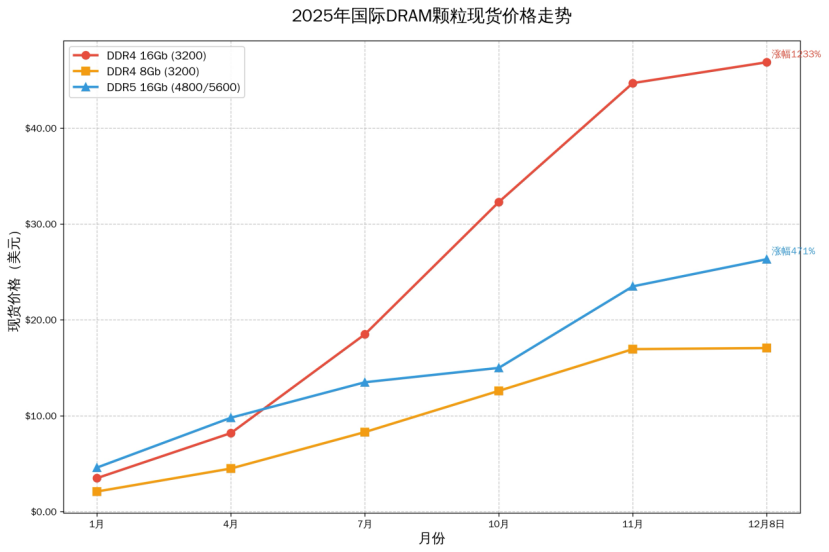
图片来源:全球半导体观察
AI大模型为什么会使用这么多内存
在大模型蛮生长的时代,市场需求主要由大模型训练环节主导,如今推理工作负载正成为需求核心。二者对存储系统的诉求存在明显差异:训练阶段的存储仅需承担两大核心任务,即向GPU输送海量训练数据集,以及处理模型检查点以规避训练中断风险;而推理阶段的存储链路则复杂得多,涵盖模型权重从存储介质加载至内存、KV缓存溢出时的分级卸载、基于RAG技术的外部数据检索等多个关键流程。
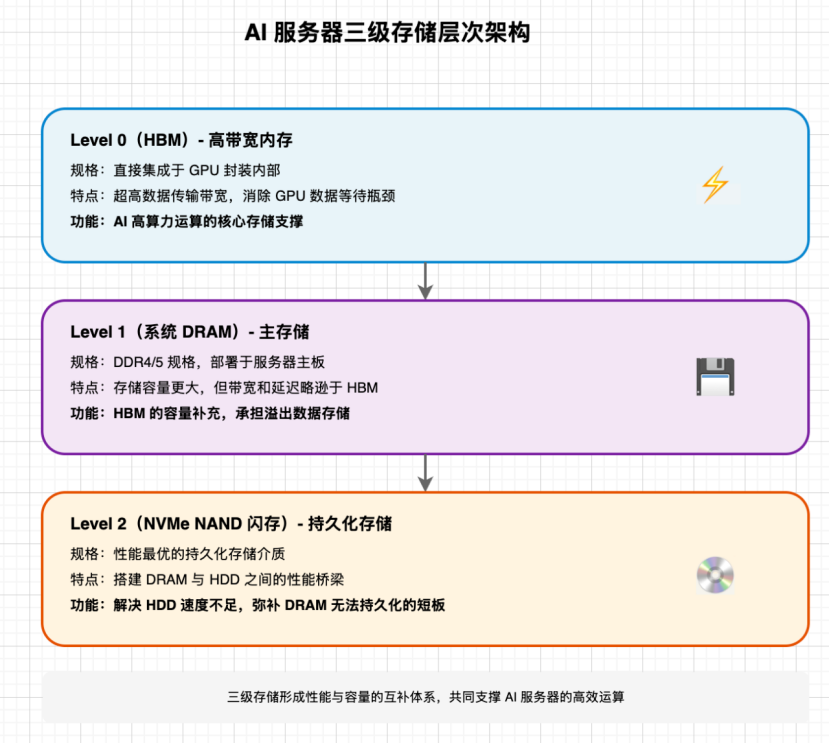
一、AI服务器的三级存储层次
AI服务器构建了清晰的三级内存层级体系,不同层级各司其职、形成性能与容量的互补:
Level 0(HBM):作为高带宽内存,HBM直接集成于GPU封装内部,凭借超高的数据传输带宽,可有效消除GPU的数据等待瓶颈,是AI高算力运算的核心存储支撑。
Level 1(系统DRAM):多采用DDR4/5规格,部署于服务器主板,相比HBM 具备更大的存储容量,但在带宽和延迟表现上略逊一筹,主要承担HBM的容量补充功能。
Level 2(NVMe NAND闪存):作为性能最优的持久化存储介质,NVMe NAND闪存搭建起DRAM与HDD之间的性能桥梁,既解决了HDD读写速度不足的问题,又弥补了DRAM无法持久化存储的短板。
二、GPT类大模型查询的完整数据流转链路
从运行过程看,一次典型查询会触发数据在这三级存储间的动态流转,每个环节都涉及巨量数据的加载、计算与缓存。以典型的GPT模型查询为例,其数据在三级存储体系中的流转可分为六个关键步骤:
-
用户推理请求率先抵达服务器节点;
-
若模型权重未提前加载,则从NVMe SSD中读取权重文件,并加载至HBM或系统DRAM;
-
进入Prefill阶段,对输入提示的所有Token进行并行处理,同时生成初始KV缓存作为模型的短期记忆;
-
若开启RAG功能,系统将从部署在NVMe SSD的向量数据库中,检索与查询相关的外部上下文信息;
-
进入Token生成阶段,模型逐一生成输出内容,KV缓存会随生成过程持续扩容,当容量超出HBM/DRAM上限时,部分缓存数据将被卸载至NVMe SSD;
-
最终生成的响应结果及相关元数据,会写入NVMe SSD完成持久化存储。
三、大模型对各层级存储的具体需求测算
从量化需求看,模型权重、动态KV缓存以及RAG等增强功能,共同驱动了各级存储达到PB乃至EB级别的天文数字需求。
1. HBM需求:静态权重与动态缓存双驱动
以典型的GPT模型为例,GPT-5推理对HBM的需求主要来自两大模块,且整体需求量达到26.8PB:
-
模型权重静态内存:对于4.5万亿参数的MoE架构GPT-5模型,其活跃专家权重需全部加载至HBM以保障响应效率,经测算这部分需求约为24PB;
-
KV缓存动态内存:KV缓存的核心作用是避免注意力权重的重复计算,通过GQA技术优化后,单个token的KV缓存占用约480KB,按照58亿的总并发Token规模计算,该模块需消耗2.8PB的HBM资源。
2.DRAM需求:聚焦KV缓存的容量支撑
DRAM的需求核心来自KV缓存,且需结合缓存命中率进行综合测算。在24小时时间窗口内,若输入KV缓存的重用率达到50%,可有效降低Prefill阶段的计算量。按每日38万亿的Token处理规模估算,GPT-5推理所需的DRAM容量约为9.1EB。
3. NAND需求:RAG场景为核心增量
NAND闪存的需求中,70%-80%来自RAG技术场景。RAG的完整流程包括外部知识库检索、提示词增强、最终结果生成,其依赖的向量数据库即部署于NVMe SSD。考虑到数据向量化(3倍膨胀)与索引构建(1.15倍膨胀)带来的4倍整体数据膨胀,再叠加数据中心的3倍冗余需求(含复制、编码、系统开销及预留空间),若按11亿月活用户、单用户月均上传1GB RAG数据计算,年化原始数据量为66EB,实际所需的NAND存储容量则高达200EB。
优刻得以“国产集群与GPU切分”
全面提升算力效率
全球主要内存颗粒原厂暂停报价,内存颗粒价格疯长,导致AI算力服务器厂商溢价严重。在AI算力短缺的全球趋势下,优刻得已经积极适配国产算力,基于国产通用CPU海光,龙芯,鲲鹏和国产GPU(GPGPU)昇腾、寒武纪、沐曦等更多架构建设的大规模智算集群,提供低延迟、高吞吐的GDR运行环境,基于集群配套的高性能存储和UK8S集群,能够快速构建大规模分布式训练环境,同时满足千亿大模型训练、推理等生成式AI场景。目前优刻得上海青浦智算中心已经落地国产千卡智算集群。
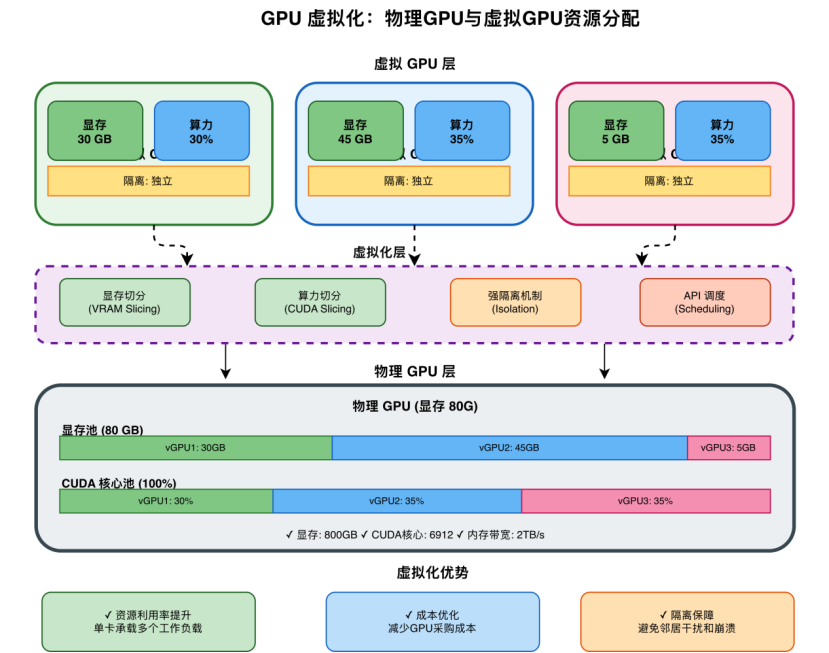
针对企业在AI算力任务中的资源浪费、GPU利用不足等痛点,优刻得正式发布新一代GPU虚拟化技术,通过显存与算力的双维度切分能力,将单张GPU的资源拆分为多个独立的虚拟算力单元,切分粒度最小可精确至10%。该能力使单卡可同时承载多个AI工作负载,在推理服务、模型开发、科研教学等场景显著提升资源利用率。
依托国产化算力底座与精细化的GPU虚拟化能力,优刻得正在构建一个更具弹性、更高利用率、更具成本效率的AI算力体系。以技术创新推动算力资源的充分释放,助力企业在AI需求持续爆发的时代加速业务创新、实现更可持续的智算生产力。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)