主流国产显卡调研报告
·
文章目录
一、前言
随着人工智能和大模型技术的快速发展,GPU算力需求持续增长。在国际形势变化和供应链安全的背景下,国产GPU/DCU成为重要的战略选择。本报告对当前市场上主流的国产AI加速卡进行全面调研,从硬件规格、软件生态、性价比等维度进行分析评估,为采购决策提供参考依据。
昇腾毋庸置疑是国产卡第一首选,本文主要叙述除昇腾外的其它国产显卡。
二、主要厂商及产品分析
2.1 海光DCU
| 型号 | 显存 | INT8 OPs | FP16 BF16 FLOPs | TF32 | FP32 FLOPs | FP64 | 显存带宽 | PCIe 接口 | 功耗 w |
|---|---|---|---|---|---|---|---|---|---|
| K100 AI版 | 64GB | 392T | 196T | 96T | 49T | - | 896GB/s | 5.0×16 | 350 |
| K100 | 64GB | 200T | 100T | - | 24.5T | 24.5T | 896GB/s | 4.0×16 | 300 |
文档中心:海光开发者社区
评估:
- ✅ 文档完善,开发者社区活跃
- ✅ 主流模型适配较好,有丰富示例
- ✅ 架构兼容性好(基于AMD CDNA架构)
- ✅ 性价比较高,K100标准版约2万元
2.2 璧仞科技
| 型号 | 显存 | INT8 OPs | FP16 BF16 FLOPs | FP32 FLOPs | 显存带宽 | 互联带宽 | 功耗 w |
|---|---|---|---|---|---|---|---|
| BR100 | 64GB HBM2e | 2048T | 1024T | - | 2.3 TB/s | 128 GB/s | - |
开发者论坛:璧仞开发者平台
评估:
- ⚠️ 硬件性能参数亮眼(FP16达1024T)
- ❌ 市场价格不透明
- ❌ 缺乏大模型部署相关文档和案例
- ❌ 生态建设不完善,使用风险较高
2.3 摩尔线程
| 型号 | 显存 | 核心数 | INT8 FLOPs | FP16 BF16 FLOPs | FP32 FLOPs | 显存带宽 | 显存位宽 bit | 功耗 w |
|---|---|---|---|---|---|---|---|---|
| MTT S4000 | 48 GB GDDR6 | - | 200T | 100T | - | 768 GB/s | - | 450 |
| MTT S3000 | 32GB GDDR6 | 4096 | - | - | 15.5 T | 448 GB/s | 256 | - |
社区:摩尔线程博客
评估:
- ✅ 有官方torch_musa适配
- ✅ 文档相对完善
- ⚠️ 驱动安装流程较复杂
- ⚠️ S4000性价比一般(约7万元)
- ⚠️ GDDR6显存带宽相对HBM较低
2.4 寒武纪
| 型号 | 显存 | INT4 OPs | INT8 OPs | INT16 OPs | FP16 BF16 FLOPs | FP32 FLOPs | 显存带宽 | 显存位宽 bit | 互联带宽 | 功耗 w |
|---|---|---|---|---|---|---|---|---|---|---|
| MLU590 | 96GB HBM2e | - | 628T | - | 314T | - | 2.76 TB/s | - | - | - |
| MLU370-S4/S8 | 24GB /48GB LPDDR5 | 384T (推测) | 192T | 96T | 72T | 18T | 307.2 GB/s | - | - | 75 |
社区:寒武纪开发者社区
评估:
- ✅ 生态建设较好,有vllm官方插件支持
- ✅ MLU370系列性价比极高(1-1.5万元)
- ✅ 有快速验证环境,可测试模型兼容性
- ✅ 社区活跃,有实际微调案例
- ⚠️ 主要支持容器化部署
2.5 天数智芯
| 型号 | 显存 | INT8 OPs | FP16 BF16 FLOPs | FP32 FLOPs | 显存带宽 | 互联带宽 | 功耗 w | 参考价 |
|---|---|---|---|---|---|---|---|---|
| 天垓150 | 64GB HBM2e | 384T | - | - | 1.6TB/s | - | 350 | ¥80759 |
| 天垓100 | 32GB HBM2 | 295T | 147T | 37T | 1.2TB/s | - | 250 | - |
| 智铠100 | 32GB | - | 200T | - | 800GB/s | - | - | - |
评估:
- ❌ 开源资料极少
- ❌ 生态建设不完善
- ❌ 不推荐选用
2.6 沐曦
| 型号 | 显存 | INT8 OPs | FP16 BF16 FLOPs | FP32 FLOPs | 显存带宽 | 显存位宽 bit | 功耗 w |
|---|---|---|---|---|---|---|---|
| 曦思 N100 | 16GB | 160T | 80T | - | - | - | - |
| 曦云 C500 | 64GB HBM2e | 560T | 280T | 36T | 1.8TB/s | - | 450 |
相关文档:
评估:
- ✅ C500性能强劲(FP16 280T)
- ✅ 有vllm插件支持
- ✅ 文档和demo较完整
- ✅ 支持Gitee AI算力租用测试
- ⚠️ 价格较高(C500约6.6万元)
2.7 燧原科技
| 型号 | 显存 | INT8 OPs | FP16 BF16 FLOPs | TF32 OPs | FP32 FLOPs | 显存带宽 | 功耗 w |
|---|---|---|---|---|---|---|---|
| S60 | 48GB | - | 392T | - | - | 672 GB/s | - |
| 云燧i20 | - | 256T | - | 128T | - | - | - |
评估:
- ❌ 资料匮乏
- ❌ 生态建设不成熟
- ❌ 不推荐选用
2.8 昆仑芯
| 型号 | 显存 | INT4 OPs | INT8 OPs | INT16 OPs | FP16 BF16 FLOPs | FP32 FLOPs | 显存带宽 | 互联带宽 | 功耗 w |
|---|---|---|---|---|---|---|---|---|---|
| M3000 | - | - | - | - | - | - | - | - | - |
| M1000 | - | - | - | - | - | - | - | - | - |
| P800 | - | - | - | - | - | - | - | - | - |
| R480-X8 | 32GB GDDR6 | × | 256T | 128T | 128T | 32T | 512 GB/s | 200 GB/s | - |
| RG800 | - | - | - | - | - | - | - | - | - |
| R200 | - | - | - | - | - | - | - | - | - |
| R100 | - | - | - | - | - | - | - | - | - |
| K200 818-300(训练卡) | 16GB HBM | √ | 256T | × | 64T | 16T | 512 GB/s | - | 150-200 |
| K100 818-100(推理卡) | 8GB HBM | √ | 128T | × | 32T | 8 |
评估:
- ❌ 公开资料极少
- ❌ 不推荐选用
2.9 砺算科技
| 型号 | 显存 | INT8 OPs | FP16 BF16 FLOPs | TF32 OPs | FP32 FLOPs | 显存带宽 | 功耗 w |
|---|---|---|---|---|---|---|---|
| 7G105 专业级 | 24GB GDDR6 | - | - | - | 24T | - | - |
| 7G06 消费级 | 12GB GDDR6 | - | - | - | - | - | - |
评估:
- ❌ 公开资料缺失
- ❌ 主要面向消费级市场
- ❌ 不推荐选用
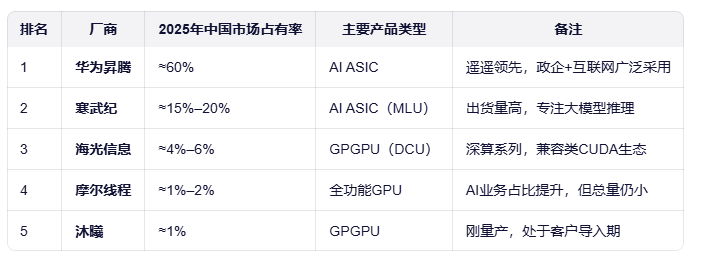
三、市场格局
市场占有率排名
💡 市场占有率越高,通常意味着生态更完善、开源资料更丰富、踩坑成本更低。
四、性价比对比分析
主流产品价格与性能对比
| 品牌 | 型号 | 显存 | FP16/BF16 FLOPS | 单卡价格 (人民币) |
|---|---|---|---|---|
| 寒武纪 | MLU370-S4 | 24GB LPDDR5 | 72 TFLOPS | 约 1.0 万元 |
| 寒武纪 | MLU370-X4 | 24GB LPDDR5 | 96 TFLOPS | 约 1.2 万元 |
| 寒武纪 | MLU370-X8 | 48GB LPDDR5 | 96 TFLOPS | 约 1.46 万元 |
| 沐曦 | C500 (PCIe 版) | 64GB | 240 TFLOPS | 6.6 万元 |
| 海光 DCU | K100 (标准版) | 64GB HBM2e | 299 TFLOPS | 约 2 万元 |
| 海光 DCU | K100 AI 版 | 64GB HBM2e | 196 TFLOPS | 约 2.7 万元 |
| 摩尔线程 MTT | S4000 | 48G GDDR6 | 31.6 TFLOPS | 约 7 万元 |
| 摩尔线程 MTT | S3000 | 32G GDDR6 | 31 TFLOPS | 约 2.2 万元 |
| 英伟达 | A100 80GB | 80GB HBM2e | 312 TFLOPS | 7-10 万元 |
| 英伟达 | RTX 4090 | 24GB GDDR6X | 82.58 TFLOPS | 1.3-1.4 万元 |
五、综合评估与推荐
推荐等级
| 等级 | 厂商 | 推荐理由 |
|---|---|---|
| ⭐⭐⭐⭐⭐ | 寒武纪 | 性价比最高,生态完善,vllm官方支持,社区活跃 |
| ⭐⭐⭐⭐ | 海光DCU | 文档完善,兼容性好,适配广泛,价格适中 |
| ⭐⭐⭐ | 沐曦 | 高性能产品线,有vllm支持,但价格较高 |
| ⭐⭐⭐ | 摩尔线程 | 有官方PyTorch支持,但安装复杂,性价比一般 |
| ⭐⭐ | 璧仞科技 | 硬件参数亮眼,但生态待完善 |
| ❌ | 天数智芯、燧原、昆仑芯、砺算 | 资料匮乏,不推荐 |
采购建议
-
预算有限,追求性价比:首选 寒武纪 MLU370系列
- MLU370-S4(24GB)约1万元
- MLU370-X8(48GB)约1.46万元
- 生态最完善,社区资源丰富
-
稳定性优先,中等预算:选择 海光DCU K100
- K100标准版约2万元
- 基于成熟架构,兼容性好
-
高性能需求,预算充足:考虑 沐曦C500 或 海光K100 AI版
- 大显存+高带宽,适合大模型训练/推理
六、总结
当前国产GPU/DCU市场格局初步形成,但整体生态仍在建设中。从实际可用性角度:
- 寒武纪和海光DCU是目前生态最完善的两家,建议优先考虑
- 沐曦和摩尔线程有一定潜力,但需关注后续发展
- 其他厂商由于资料匮乏、生态不完善,暂不建议作为主要选项
在选型时,建议优先通过Gitee AI算力租用等渠道进行实际测试验证,降低采购风险。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)