kimi-2.5部署记录
本文介绍了基于Ascend NPU的Kimi-K2.5-W4A8大模型分布式部署方案。采用两台配备910B显卡(64G*8)的服务器,通过vllm-ascend容器部署。详细说明了模型下载、镜像配置、docker-compose.yml文件编写和启动脚本设置,包括网络配置、环境变量调整等关键参数。部署完成后可通过8004端口进行推理验证,并提供了多模态测试脚本示例,支持文本和图像输入。该方案实现了
1、基本信息
显卡:910B(64G*8) 2台
驱动:npu-smi 25.2.0
推理工具:vllm-ascend
容器部署:docker+docker-compose
2、部署准备
模型下载:https://modelscope.cn/models/Eco-Tech/Kimi-K2.5-W4A8
镜像下载:docker pull quay.io/ascend/vllm-ascend:v0.17.0rc1
3、部署
模型下载到/data/model/Kimi-K2.5-w4a8-deploy,两台分别在该目录创建docker-compose.yml和kimi-model.sh,目录如下

节点node0:
cat docker-compose.yml
services:
kimi-k2-5-node00:
image: quay.io/ascend/vllm-ascend:v0.17.0rc1
container_name: kimi-k2.5-node00
restart: unless-stopped
network_mode: "host"
ipc: host
stdin_open: true
tty: true
privileged: true
shm_size: 1g
devices:
- "/dev/davinci0:/dev/davinci0"
- "/dev/davinci1:/dev/davinci1"
- "/dev/davinci2:/dev/davinci2"
- "/dev/davinci3:/dev/davinci3"
- "/dev/davinci4:/dev/davinci4"
- "/dev/davinci5:/dev/davinci5"
- "/dev/davinci6:/dev/davinci6"
- "/dev/davinci7:/dev/davinci7"
- "/dev/davinci_manager:/dev/davinci_manager"
- "/dev/devmm_svm:/dev/devmm_svm"
- "/dev/hisi_hdc:/dev/hisi_hdc"
volumes:
- "/usr/local/dcmi:/usr/local/dcmi"
- "/usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool"
- "/usr/local/bin/npu-smi:/usr/local/bin/npu-smi"
- "/usr/local/Ascend/driver/lib64:/usr/local/Ascend/driver/lib64"
- "/usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info"
- "/etc/ascend_install.info:/etc/ascend_install.info"
- "/root/.cache:/root/.cache"
- "${PWD}:/data/models"
environment:
- PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:256
- VLLM_USE_MODELSCOPE=True
command: ["/bin/bash", "/data/models/kimi-model.sh"]
logging:
driver: "json-file"
options:
max-size: "300m"
max-file: "3"
volumes:
base_model:
driver: local
cat kimi-model.sh
#!/bin/sh
# this obtained through ifconfig
# nic_name is the network interface name corresponding to local_ip of the current node
nic_name="eno0"
local_ip="192.168.23.4"
# The value of node0_ip must be consistent with the value of local_ip set in node0 (master node)
node0_ip="192.168.23.4"
# [Optional] jemalloc
# jemalloc is for better performance, if `libjemalloc.so` is installed on your machine, you can turn it on.
# export LD_PRELOAD=/usr/lib/aarch64-linux-gnu/libjemalloc.so.2:$LD_PRELOAD
export HCCL_IF_IP=$local_ip
export GLOO_SOCKET_IFNAME=$nic_name
export TP_SOCKET_IFNAME=$nic_name
export HCCL_SOCKET_IFNAME=$nic_name
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=1
export HCCL_BUFFSIZE=1024
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export VLLM_ASCEND_BALANCE_SCHEDULING=1
export HCCL_INTRA_PCIE_ENABLE=1
export HCCL_INTRA_ROCE_ENABLE=0
export TASK_QUEUE_ENABLE=1
export VLLM_ASCEND_ENABLE_MLAPO=1
vllm serve /data/models/Kimi-K2.5-w4a8 \
--host 0.0.0.0 \
--port 8004 \
--data-parallel-size 4 \
--data-parallel-size-local 2 \
--data-parallel-address $node0_ip \
--data-parallel-rpc-port 13389 \
--tensor-parallel-size 4 \
--quantization ascend \
--seed 1024 \
--served-model-name kimi_k25 \
--enable-expert-parallel \
--async-scheduling \
--max-num-seqs 16 \
--max-model-len 16384 \
--max-num-batched-tokens 4096 \
--trust-remote-code \
--no-enable-prefix-caching \
--gpu-memory-utilization 0.9 \
--compilation-config '{"cudagraph_capture_sizes":[1,2,4,8,16], "cudagraph_mode": "FULL_DECODE_ONLY"}' \
--additional-config '{"multistream_overlap_shared_expert":true}' \
--mm-processor-cache-type shm \
--mm-encoder-tp-mode data
节点node1:
cat docker-compose.yml
services:
kimi-k2-5-node01:
image: quay.io/ascend/vllm-ascend:v0.17.0rc1
container_name: kimi-k2.5-node01
restart: unless-stopped
network_mode: "host"
stdin_open: true
tty: true
ipc: host
privileged: true
shm_size: 1g
devices:
- "/dev/davinci0:/dev/davinci0"
- "/dev/davinci1:/dev/davinci1"
- "/dev/davinci2:/dev/davinci2"
- "/dev/davinci3:/dev/davinci3"
- "/dev/davinci4:/dev/davinci4"
- "/dev/davinci5:/dev/davinci5"
- "/dev/davinci6:/dev/davinci6"
- "/dev/davinci7:/dev/davinci7"
- "/dev/davinci_manager:/dev/davinci_manager"
- "/dev/devmm_svm:/dev/devmm_svm"
- "/dev/hisi_hdc:/dev/hisi_hdc"
volumes:
- "/usr/local/dcmi:/usr/local/dcmi"
- "/usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool"
- "/usr/local/bin/npu-smi:/usr/local/bin/npu-smi"
- "/usr/local/Ascend/driver/lib64:/usr/local/Ascend/driver/lib64"
- "/usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info"
- "/etc/ascend_install.info:/etc/ascend_install.info"
- "/root/.cache:/root/.cache"
- "${PWD}:/data/models"
environment:
- PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:256
- VLLM_USE_MODELSCOPE=True
command: ["/bin/bash", "/data/models/kimi-model.sh"]
logging:
driver: "json-file"
options:
max-size: "300m"
max-file: "3"
volumes:
base_models:
driver: local
cat kimi-model.sh
#!/bin/sh
# this obtained through ifconfig
# nic_name is the network interface name corresponding to local_ip of the current node
nic_name="eno0"
local_ip="192.168.23.13"
# The value of node0_ip must be consistent with the value of local_ip set in node0 (master node)
node0_ip="192.168.23.4"
# [Optional] jemalloc
# jemalloc is for better performance, if `libjemalloc.so` is installed on your machine, you can turn it on.
# export LD_PRELOAD=/usr/lib/aarch64-linux-gnu/libjemalloc.so.2:$LD_PRELOAD
export HCCL_IF_IP=$local_ip
export GLOO_SOCKET_IFNAME=$nic_name
export TP_SOCKET_IFNAME=$nic_name
export HCCL_SOCKET_IFNAME=$nic_name
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=1
export HCCL_BUFFSIZE=1024
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export VLLM_ASCEND_BALANCE_SCHEDULING=1
export HCCL_INTRA_PCIE_ENABLE=1
export HCCL_INTRA_ROCE_ENABLE=0
export TASK_QUEUE_ENABLE=1
export VLLM_ASCEND_ENABLE_MLAPO=1
vllm serve /data/models/Kimi-K2.5-w4a8 \
--host 0.0.0.0 \
--port 8004 \
--headless \
--data-parallel-size 4 \
--data-parallel-size-local 2 \
--data-parallel-start-rank 2 \
--data-parallel-address $node0_ip \
--data-parallel-rpc-port 13389 \
--tensor-parallel-size 4 \
--quantization ascend \
--seed 1024 \
--served-model-name kimi_k25 \
--enable-expert-parallel \
--async-scheduling \
--max-num-seqs 16 \
--max-model-len 16384 \
--max-num-batched-tokens 4096 \
--trust-remote-code \
--no-enable-prefix-caching \
--gpu-memory-utilization 0.9 \
--compilation-config '{"cudagraph_capture_sizes":[1,2,4,8,16], "cudagraph_mode": "FULL_DECODE_ONLY"}' \
--additional-config '{"multistream_overlap_shared_expert":true}' \
--mm-processor-cache-type shm \
--mm-encoder-tp-mode data
分别在两台启动服务,docker-compose up -d ,并查看日志
node0节点docker-compose logs -f 出现下列日志即成功,需要多等一会儿
4、验证
验证推理
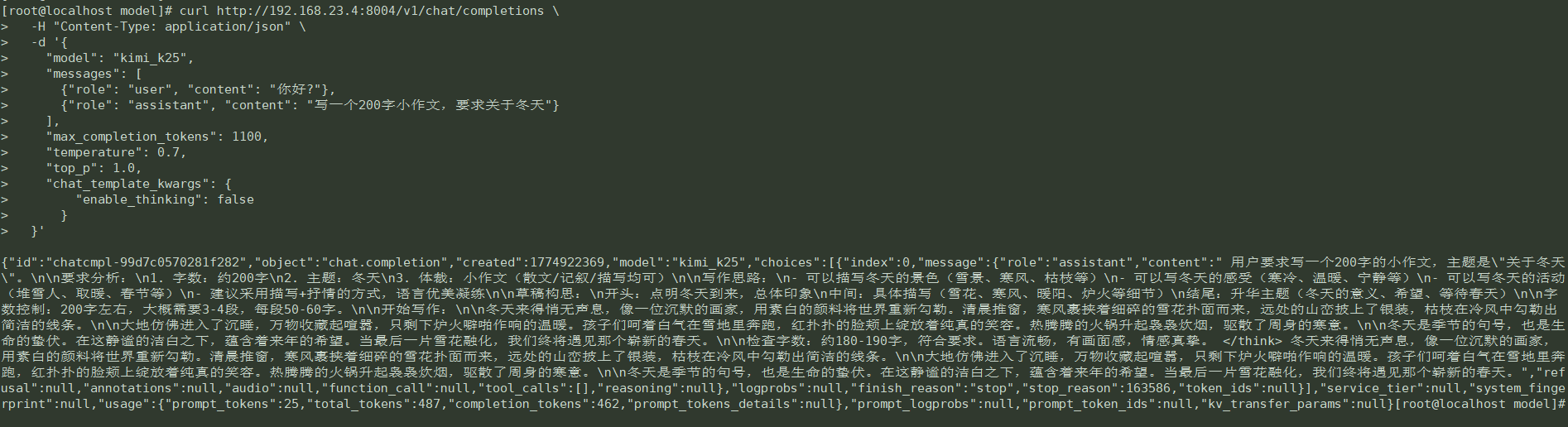
验证多模态
python3脚本
import base64
import requests
import json
# 配置区域
URL = "http://192.168.23.4:8004/v1/chat/completions"
MODEL_ID = "kimi_k25"
IMAGE_PATH = "./receipt.png" # 请修改为你的图片路径
QUESTION = "请描述这张图片。"
def encode_image(image_path):
try:
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode('utf-8')
except FileNotFoundError:
print(f"错误: 找不到图片 {image_path}")
return None
def main():
print(f"读取图片: {IMAGE_PATH}")
img_base64 = encode_image(IMAGE_PATH)
if not img_base64: return
payload = {
"model": MODEL_ID,
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": QUESTION},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img_base64}"}}
]
}]
}
print("发送请求中...")
try:
resp = requests.post(URL, json=payload, timeout=60)
if resp.status_code == 200:
print("\n回复:", resp.json()['choices'][0]['message']['content'])
else:
print(f"失败 {resp.status_code}: {resp.text}")
except Exception as e:
print(f"错误: {e}")
if __name__ == "__main__":
main()
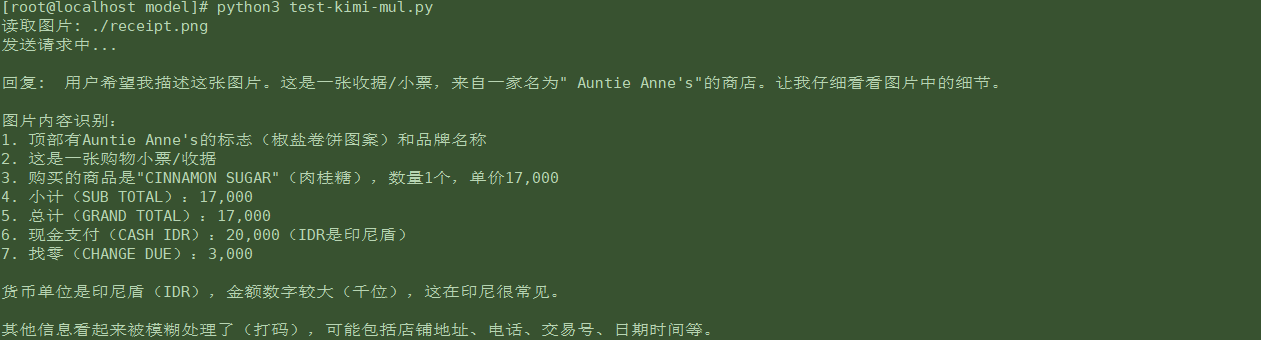
执行脚本python3 test-kimi-mul.py

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)