基于开发者空间OpenGauss数据库AI特性功能
从2015年,ORACLE公司提出让数据库自动化运维,即数据库中常见的问题,并且已经存在一套统一规范的处理解决方案的场景,应该让数据库在监控检测到此类问题,自动处理解决该问题,以减少运维工作人员人力的参与(因为Oracle的运维人力相对昂贵)。现如今,人工智能的高速发展,在行业各个领域辅助人们的决策和高效工作,故数据库研发人员也想把AI能力融入数据库中,让其自学习数据库常见故障的运维解决方案,并使
目录
2.4.2 OpenGaussDB在昇腾AI芯片下的技术应用
1. 概述
1.1 案例介绍
从2015年,ORACLE公司提出让数据库自动化运维,即数据库中常见的问题,并且已经存在一套统一规范的处理解决方案的场景,应该让数据库在监控检测到此类问题,自动处理解决该问题,以减少运维工作人员人力的参与(因为Oracle的运维人力相对昂贵)。现如今,人工智能的高速发展,在行业各个领域辅助人们的决策和高效工作,故数据库研发人员也想把AI能力融入数据库中,让其自学习数据库常见故障的运维解决方案,并使数据库自我修复。
本案例选择OpenGauss数据库作为载体,并借助开发者空间云主机提供的免费EulerOS环境和OpenGaussDB研发的AI功能,直观地展示AI决策在日常数据库的开发与优化能力和实际应用开发中为开发者带来的便利。
通过实际操作,让大家深入了解如何利用 OpenGaussDB开发并优化项目中业务应用的SQL语句等功能。在这个过程中,大家将学习到从AI函数的引用、AI功能的原理以及分析AI能力等一系列关键步骤,从而掌握 OpenGaussDB-AI的基本使用方法,体验其在应用开发中的优势。
1.2 适用对象
- 企业
- 个人开发者
- 高校学生
1.3 案例时间
本案例总时长预计60分钟。
1.4 案例流程
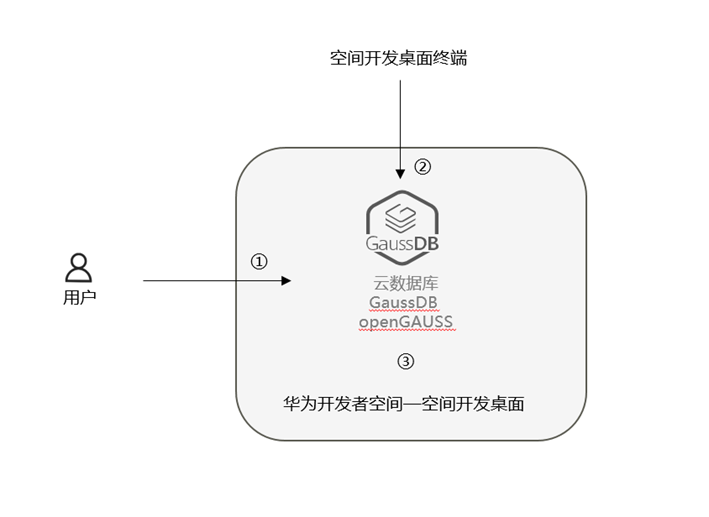
说明:
- 领取空间开发桌面,登录云主机;
- 在云主机终端进入OpenGaussDB;
- 进入开发者空间进行OpenGaussDB数据库之AI特性功能使用;
1.5 资源总览
|
资源名称 |
规格 |
单价(元) |
时长(分钟) |
|
ARM架构, | 4 vCPUs | 8 GB | OpenEuler 22.03 Server定制版 (40GB) |
免费 |
60 |
2. 鲲鹏和OpenGaussDB架构融合与AI特性
2.1 开发者空间配置
面向广大开发者群体,华为开发者空间提供一个随时访问的“开发桌面云主机”、丰富的“预配置工具集合”和灵活使用的“场景化资源池”,开发者开箱即用,快速体验华为根技术和资源。
如果还没有领取开发者空间云主机,可以参考免费领取云主机文档领取。
领取云主机后可以直接进入华为开发者空间工作台界面,点击打开云主机 > 进入桌面连接云主机。

2.2 启动OpenGaussDB实例并登录
本案例中,使用OpenGaussDB开发平台,完成SQL的编程和自定义函数等多种功能。
基于之前案例《基于开发者空间部署OpenGauss主备集中式数据库系统》。在云主机部署OpenGaussDB实例。并启动数据库服务。
进入OpenGaussDB的安装目录的bin文件,该案例云主机环境中安装目录在环境变量$GAUSSHOME中,读者根据自己云主机安装目录进行操作修改。
cd $GAUSSHOME/bin初始化数据库实例,初始化数据库目录在当前目录下data,设置节点名称和初始化用户密码。如下所示
./gs_initdb -D data --nodename=n1 -w GaussDB@123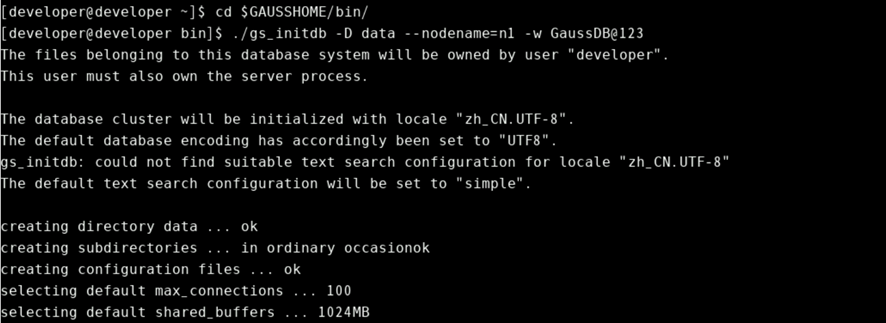
以单节点模式启动数据库实例,并在当前目录下输出日志文件logfile。
./gs_ctl start -D data -Z single_node -l logfile
用gsql客户端工具,进入OpenGaussDB数据库。参数 -a表示追加、-r表示使用readline。
./gsql -d postgres -ar
2.3 鲲鹏CPU与OpenGaussDB面临的问题
为了提升数据库系统对处理器的有效利用率,保证数据库系统提供的面向客户的SLA(服务水平协议),针对Intel X86与鲲鹏CPU处理器之间的差异,面向鲲鹏处理器的数据库系统遇到很多挑战,特别是在面向事务处理的环境下。
- 事务处理时锁冲突的比例会大幅增加。在事务处理环境下,由于有更多数量的处理线程同时在运行不同事务处理,对于系统中全局结构的修改将产生更大的冲突,而该冲突将导致处理器资源无法被充分使用,进而限制了数据库系统的可扩展能力和吞吐性能。
- 事务处理的时延将在比较大的范围内波动,无法很好地满足面向客户的SLA。由于在鲲鹏处理器环境下,NUMA特性更加显著,导致内存访问的时延波动,特别是对一些原子操作(如CAS、FAA等),时延也会有较大的波动。最后导致单个事务处理的时延有较大波动,这给保证客户的SLA带来了一定的难度和挑战。
- 处理器内部以及处理器核间通信能力提供了新的线程间同步机制。为了有效使用核间通信能力(POE),需要重新架构数据库内部的通信机制,包括通信原语(如spin lock、lock等)的实现以及数据库内部线程间的协作机制
面向鲲鹏处理器的OpenGaussDB系统的架构
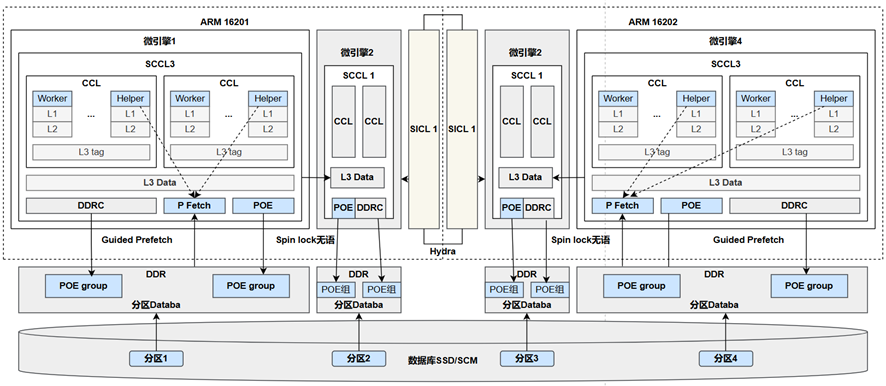
在OpenGaussDB系统的架构中包含如下创新内容:
- 基于核间通信能力实现了全新的并发原语机制,特别是自旋锁(spin lock)、读写锁(read/write lock)的实现。全新的并发原语操作与传统的使用原子操作(CAS、FAA等)实现的自旋锁,包括票据锁(ticket lock)、MCS锁(John M. Mellor-Crummey and Michael L. Scott lock等)不同。全新的并发原语直接通过核间通信能力,而无须通过内存变量的原子性修改来达成协同一致,从而大幅提升了性能。
- 异步流水线机制。数据库系统在执行事务时,可以根据任务的特点,切分成很多个子任务,这些子任务可以由特定线程执行,并绑定在特定处理核上,另一方面,这些子任务之间的协同处理可以通过核间通信能力来实现。进而实现异步流水线的调度/执行机制。
但是在鲲鹏芯片中,CPU访问本地内存的速度将远远高于访问远端内存(系统内其他节点的内存)的速度。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同CPU模块之间的信息交互。
为了高效发挥鲲鹏芯片的优势,OpenGaussDB在设计时考虑以下特点:
-
类似于多节点并行计算,计算和存储会在特定核上执行,即数据划分到不同的CPU模块和对应的内存,并在一个模块内考虑负载均衡的问题。
-
为了支持共享数据结构的全局访问,例如LSN(Log Sequence Number日志序列号),XID(Transaction ID事务唯一标识)等数据类型,OpenGaussDB指派单独的核来进行处理,减少数据访问冲突。
- 为了提高CPU模块内资源的利用率和多核的并发能力,设计新型的NUMA事务处理方法,如基于数据进行事务分发,减少核间冲突等。
2.4 OpenGaussDB在昇腾AI芯片的技术应用
2.4.1 昇腾AI芯片简介
为了原生支持人工智能技术,大量 AI 算法(如回归、聚类、深度学习等)和底层算子(如张量计算)在落地中普遍存在3个问题:
- 存在大量矩阵运算,CPU 计算粒度较低,处理这类运算的效率较差。
- AI算法中存在较复杂的标量运算,需要更高性能的CPU来处理。
- 随着计算粒度要求的提升,芯片需要缓存更多的数据,数据宽度增加。传统数据库大多只是基于通用的 CPU 处理操作。
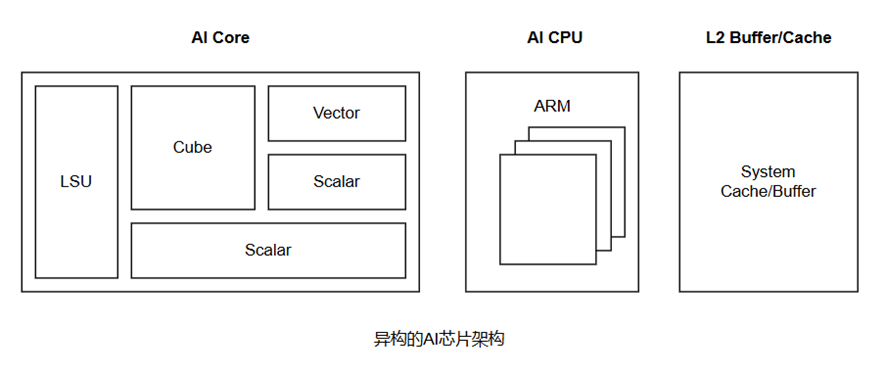
因此对于专门处理各类机器学习算法(如统计学习、深度学习、强化学习等)设计 的昇腾芯片,能够为智能数据处理和计算提供硬件支撑。以华为开发的昇腾芯片310/910为例,其核心部件包括 AI Core、AI CPU(ARM)、SVM(支持向量机)大规模缓存,因此需要从5个方面对不同机器学习算子的计算能力进行优化:
- 卷积、全连接操作:利用 3D Cube 引擎提供矩阵乘法的核心算力。
- 池化(Pooling)、ReLU、BatchNorm、Softmax、RPN等张量运算:通过 Vector 运算单元覆盖剩下的向量运算操作。
- 标量运算:用 Scalar 运算单元完成控制和基础的标量运算,并集成专门的 AICPU,计算更复杂的标量运算。
- 数据宽度:数据宽度增加,丰富片上存储单元,用大数据通路保证 Cube/Vector 运算单元 的数据供应。
- 协同运算:增加协同运算,对算法和软件进行协同优化。
此外,昇腾 AI Core 统一架构 Davinci Core 的核心部件包括:
- Cube 运算单元(矩阵乘);
- Vector 运算单元(向量运算);
- Scalar 运算单元(标量运算);
- MTE(数据传输管理);
- Buffer(高速数据传输);
- 指令和控制系统。
面对全场景中不同的企业和产品,这套架构能够提供丰富的接口,支持灵活扩展和多种形态下AI 加速板卡的设计,有效应对多样化客户数据中心侧的算力挑战,加速 AI 算法在数据库系统中的落地。昇腾310芯片架构,如图所示。
2.4.2 OpenGaussDB在昇腾AI芯片下的技术应用
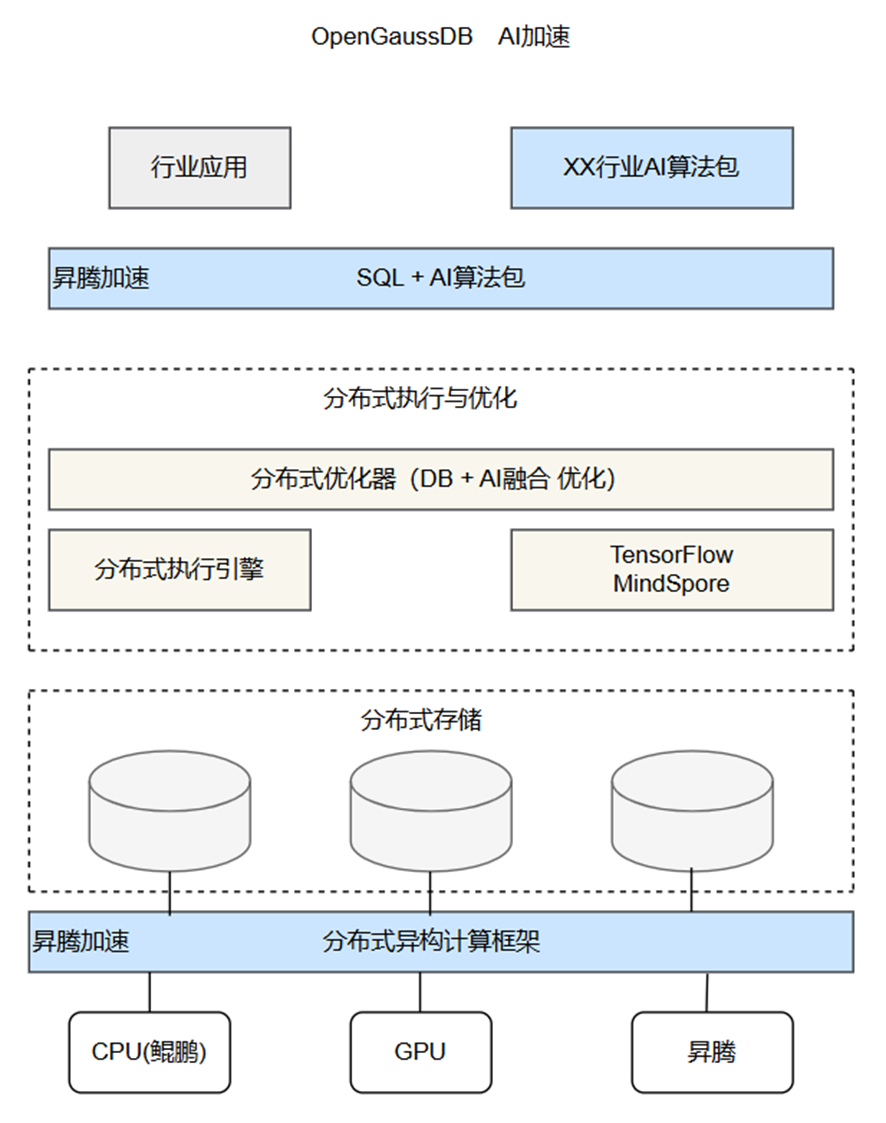
OpenGaussDB内核除了具备传统数据库SQL能力,同时还能将 AI 推理、训练等操作集成到数据库内完成,通过扩展SQL语法来实现数据库内AI的训练和推理,结合昇腾 AI 芯片对训练和推理过程的加速释放昇腾 AI 计算能力,降低 AI 开发成本,实现训练、推理和管理数据一体化。DB4AI 有如下特点:
- 库内集成 TensorFlow/MindSpore 机器学习深度框架,在数据库内部实现 CNN(Convolutional Neural Network,卷积神经网络)、DNN(Deep Neural Network,深度神经网络)等算法,并探索基于昇腾芯片的对接与加速。
- 基于具体行业领域(如电信、智能驾驶业务场景)实现数据库的内置行业AI算法包,数据分析由“DB + BI”向“DB + AI”转变。探索数据库与机器学习算法的融合优化技术,利用数据库优化器索引、剪枝等技术实现机器学习模型训练与推理过程的加速。
- 数据库充分利用昇腾AI芯片对 Vector、Cube 等计算模型的加速能力,实现传统数据库内聚集操作(Aggregation)、关联操作(Join)的加速。
OpenGaussDB与昇腾结合的AI加速与计算加速架构如图所示:
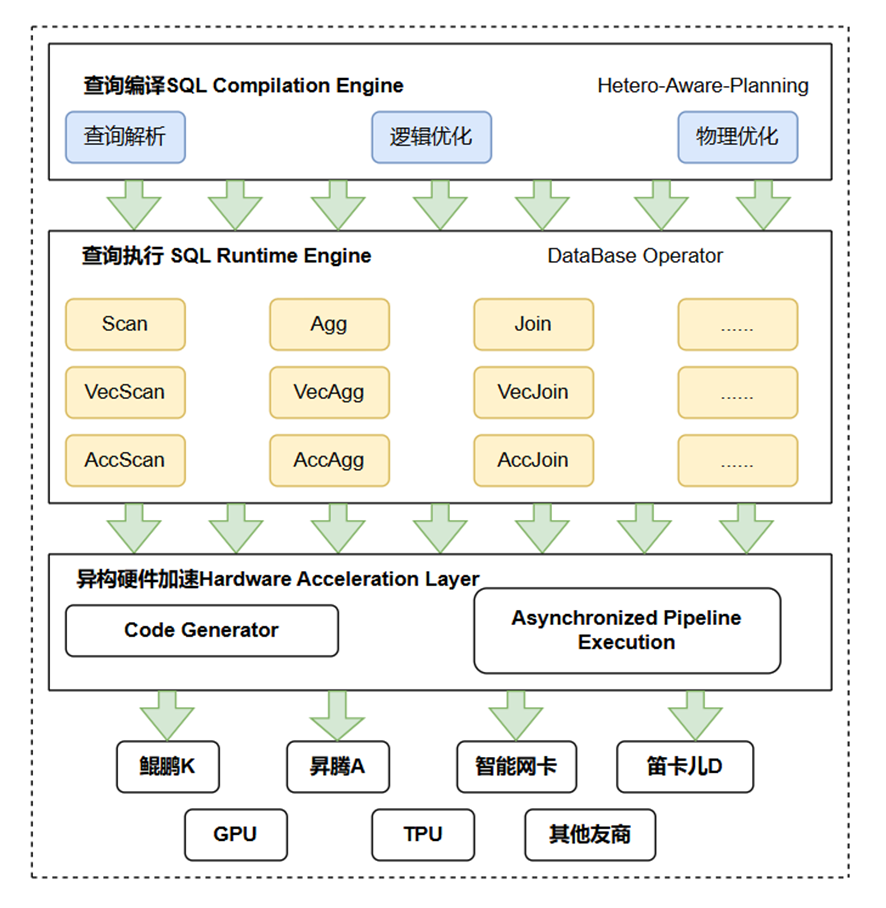
2.5 智能芯片群调度模块
通过提供弹性的数据和系统资源访问接口,OpenGaussDB 同时支持通用 CPU(x86架构,SMP)、鲲鹏(ARM架构,NUMA)、昇腾(异构计算)等多类芯片。为更好地发挥不同芯片群的优势,OpenGaussDB 可以根据业务类型智能调度指定的芯片处理不同事务。比如:对于常规数据库查询,OpenGaussDB 使用通用 CPU 组处理;对于大规模数据分析任务,OpenGaussDB 根据访问的数据分布情况使用指定的鲲鹏 CPU 组处理;对于数据库运行中使用的 AI 模型,昇腾芯片组分别负责逻辑判断(AICPU)、模型训练和大规模数据计算(Vector计算单元)。
2.6 OpenGaussDB-AI特性简介
OpenGauss数据库在AI领域主要发为两个方向:
- AI4DB(AI For DataBase)指用AI使能数据库,从而获得数据库更好的执行表现,实现数据库系统的自治、免运维等,主要包括自调优、自诊断、自安全、自运维 、自愈等子领域。
- DB4AI(DataBase For AI)指打通数据库到 AI 应用的端到端流程,统一 AI 技术栈,达到AI应用的开箱即用、高性能、低成本等目的。例如:通过类 SQL 语句使用推荐系统、图像检索、时序预测等功能,充分发挥 openGauss 高并行、列存储等优势,提高机器学习任务的执行效率。同时,在数据侧实现 AI 计算,还可以降低数据的网络传输成本,实现本地化计算。
DB4AI里主要包含DeepSQL特性,由于该功能偏于内核,故本案例不做详细讲解。请读者自学DeepSQL。在源码目录路径openGauss-server/src/gausskernel/dbmind/deepsqlt 和openGauss-server/src/gausskernel/dbmind/db4ai里。
3. AI For OpenGaussDB功能
3.1 索引智能推荐
数据库的索引管理是一期非常普遍且重要的事情,任何数据库的性能优化都需要考虑索引的选择。openGauss支持原生的索引推荐功能,可以通过系统函数等形式进行使用。
3.1.1 使用场景
在大型关系型数据库中,索引的设计和优化对SQL语句的执行效率至关重要。一直以来,数据库管理人员往往基于相关理论知识和经验,对索引进行人工设计和调整。这样做消耗了大量的时间和人力,同时人工设计的方式往往不能确保索引是最优的。
openGauss提供了智能索引推荐功能,该功能将索引设计的流程自动化、标准化,可分别针对单条查询语句和工作负载推荐最优的索引,提升作业效率、减少数据库管理人员的运维操作。
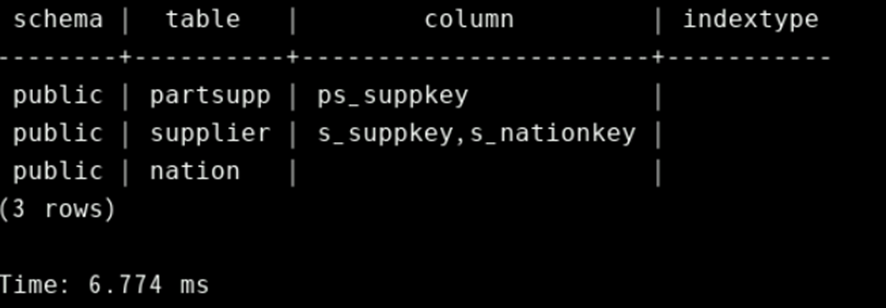
openGauss的智能索引推荐功能可覆盖多种任务级别和使用场景,具体包含以下三个特性。
- 单条查询语句的索引推荐。该特性可基于查询语句的语义信息和数据库的统计信息,对用户输入的单条查询语句生成推荐的索引。
- 虚拟索引。该特性可模拟真实索引的建立,同时避免真实索引创建所需的时间和空间开销,用户可通过优化器评估虚拟索引对指定查询语句的代价影响。
- 基于工作负载的索引推荐。该特性将包含有多条DML语句的工作负载作为任务的输入,最终生成一批可优化整体工作负载执行时间的索引。该功能适用于多种使用场景,例如,当面对一批全新的业务SQL且当前系统中无索引时,本功能将针对该工作负载量身定制,推荐出效果最优的一批索引;当系统中已存在索引时,本功能仍可查漏补缺,对当前生产环境中运行的作业,通过获取日志来推荐可提升工作效率的索引,或者针对个别的慢SQL进行单条索引推荐。
3.1.2 现有技术
按照任务级别划分,索引推荐可分为基于单条查询语句的索引推荐和基于工作负载的索引推荐。对于基于单条查询语句的索引推荐,使用者每次向索引设计工具提供一个井底语句,工具会针对该语句生成最佳的索引。目前的主流算法是首先提取该查询语句的语义信息和数据库中的统计信息,然后基于相关的索引设计和优化理论,对各子句中的谓词进行分析和处理,启发式地推荐最优索引。此类任务主要是针对个别查询时间慢的SQL进行索引优化,应用场景较为有限。
一般来说,更广泛使用的任务场景是基于工作负载的索引推荐,即给定一个包含多种类型SQL语句的工作负载,生成使得系统在该工作负载下的运行时间降至最低的索引集合。在索引选择算法中,核心是量化和估计索引对于工作负载的收益,这里的收益是指,当该索引应用于指定工作负载时,工作负载的总代价的减少量。根据代价估计方式的不同,目前的算法可分为两大类。
- 基于优化器的代价估计的方法。采用优化器的代价模型来对索引进行代价估计是较为准确的,因为优化器负责查询计划和索引的选择。同时,一些数据库系统支持虚拟索引的功能,虚拟索引并没有在存储空间中创建物理上的索引,而是通过模拟索引的效果来影响优化器的代价估计。目前的主流数据库产品均采用了该方法,如SQL Server的AutoAdmin、DB2的DB2 Advisor等。
- 基于机器学习的方法。上一种方法由于优化顺的局限性,会导致索引收益的估计发生偏差,例如选择度的错误估算或者代价估计模型不准确。一些方法采用了机器学习算法来预测和分类哪种查询计划更加有效,或者是采用基于神经网格的代价模型来缓解传统模型带来的问题。但是此类方法往往需要大量的训练数据,并不适用于全部的业务环境。
3.1.3 实现原理
3.1.3.1 针对单条查询语句的索引推荐
单条查询语句的索引推荐是以数据库的系统函数形式提供的,用户可以通过调用gs_index_advise()命令使用。其原理是利用在SQL引擎、优化器等处获取到的信息,使用启发式算法进行推荐。该功能可以用来对因索引配置不当而导致的慢SQL进行优化。
单条查询语句的索引推荐流程图如下
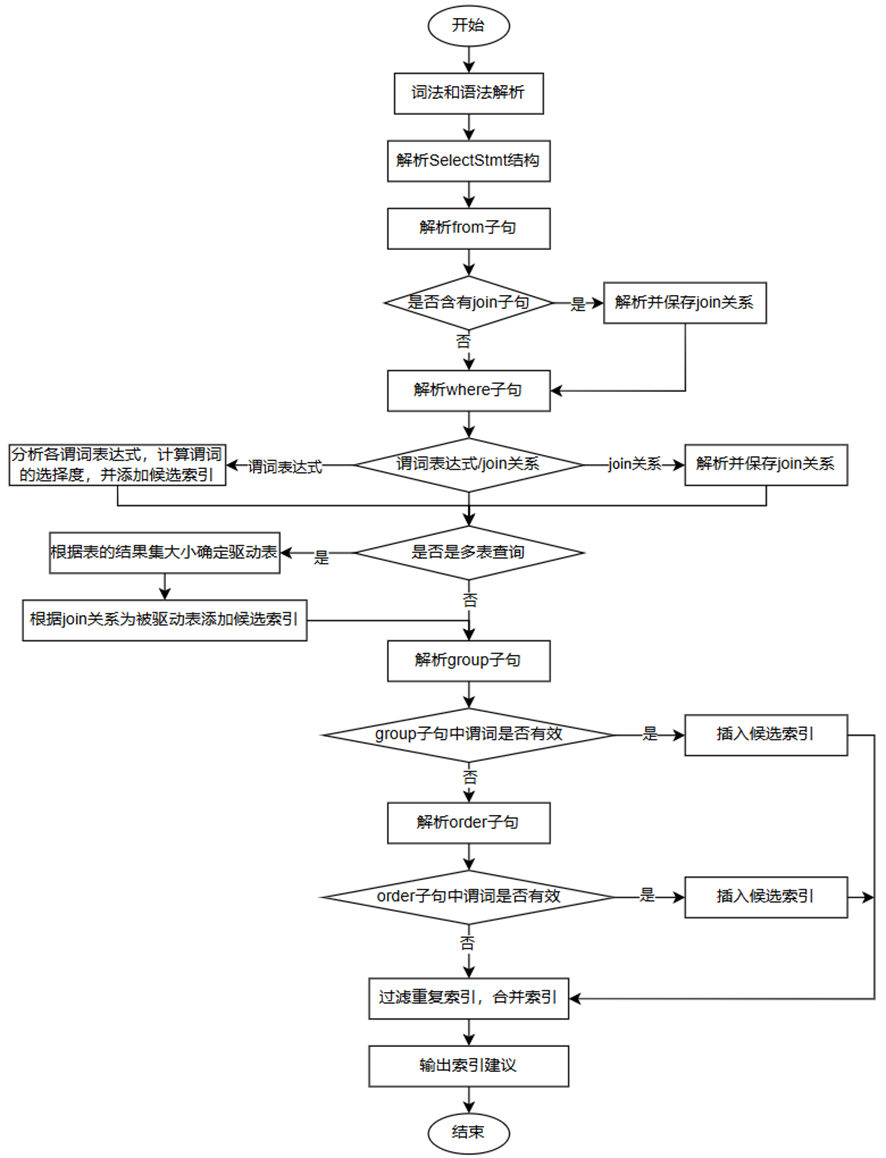
- 对给定的查询语句进行词法和语法解析,得到解析树。
- 依次对解析树中的单个或多个查询子句的结构进行分析
- 整理查询条件,分析各个子句中的谓词。
- 解析from子句,提取其中的表信息,如果其中含有join子句,则解析并保存join关系。
- 解析where子句,如果是谓词表达式,则计算各谓词的选择度,并将各谓词根据选择度的大小进行倒序排列,依据最左匹配原则添加候选索引,如果是join关系,则解析并保存join关系。
- 如果是多表查询,即该语句中含有join关系,则将结果集最小的表作为驱动表,根据前述过程中保存的join关系和连接谓词为其他被驱动表添加候选索引。
- 解析group和order子句,判断其中的谓词是否有效,如果有效则插入候选索引的合适位置,group子句中的谓词优于order子句,且两者只能同时存在一个。这里候选索引的排列优先级为:join中的谓词 > where等值表达式中的谓词 > group或order中的谓词 > where非等值表达式中的谓词。
- 检查该索引是否在数据库中已存在,若存在则不再重复推荐。
- 输出最终的索引推荐建议。
3.1.3.2 虚拟索引
通过虚拟索引功能实现对待创建索引的效果和代价进行估计。对于给定的索引表名和列名,可以在数据库内部建立虚拟索引,该虚拟索引只具有待创建索引的元信息,而不会真正创建物理索引文件,因此避免了真实索引的创建开销。这些元信息包括待创建索引的表名、列名和其他统计信息。虚拟索引仅用于通过EXPLAIN语句显示优化器的可能执行路径,不能提供真正的索引扫描。
因此,对某条SQL语句执行EXPLAIN命令,可以查看到创建索引前后优化器规划出的执行计划、检验该待创建索引是否被数据库采用及是否有性能提升。虚拟索引主要是基于数据库中的hook(钩子机制)实现的,即使用全局的函数指针get_relation_info_hook和explain_get_index_name_hook,来干预和改变查询计划的估计过程,让优化器在规划路径时考虑到可能出现的索引扫描。
3.1.3.3 基于工作负载的索引推荐
基于工作负载的索引推荐功能的主要模块如图所示
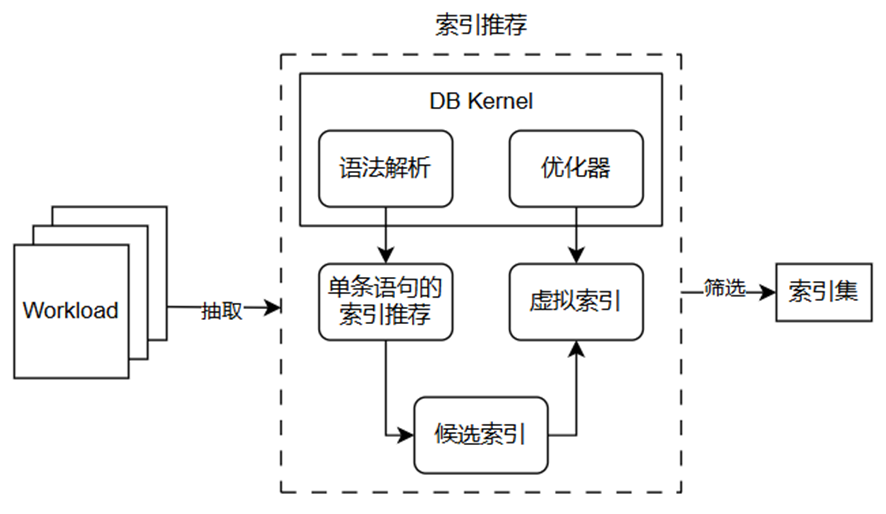
- 对于给定的工作负载,首先对工作负载进行压缩。由于工作负载中通常存在大量相似的语句,为了减少数据库功能的调用次数,对工作负载中的SQL语句进行模板化和采样。
- 对压缩后的工作负载,调用单条查询语句的索引推荐功能为每条语句生成推荐索引,作为候选索引集合。
- 对候选索引集合中的每个索引,在数据库中创建对应的虚拟索引,根据优化器的代价估计来计算该索引对整个负载的收益。
- 在候选索引集合的基础上,基于索引代价和收益进行索引的选择。openGauss实现了两种算法进行索引优选:一种是在限定索引集大小的条件下,根据索引的收益进行排序,然后选取靠前的候选索引来最大化索引集的总收益,最后采用微调策略,基于索引间的相关性进行调整和去重,得到最终的推荐索引集合;另一种方法是采用贪心算法来迭代地进行索引集合的添加和代价推断,最终生成推荐的索引集合。两种算法各有优势,第一种方法未充分考虑索引间的相互关系,而第二种方法会伴随较多的迭代过程。
- 输出最终的索引推荐建议。
3.1.3.4 关键源码解析
对应的gs_index_advise函数和虚拟索引列功能在源码目录路径openGauss-server/src/gausskernel/dbmind/kernel;

读者感兴趣,自行阅读hypopg_index.cpp和index_advisor.cpp。
3.1.4 使用示例
- 单条SQL的索引推荐
单条查询语句的索引推荐功能支持用户在数据库中直接进行操作,本功能基于查询语句的语义信息和数据库的统计信息,对面用户输入的单条查询语句生成推荐的索引。本功能涉及的函数接口如下所示
| 函数名 | 参数 | 返回值 | 功能 |
|---|---|---|---|
| gs_index_advise | SQL语句字符串 | 无 | 针对单条查询语句生成推荐索引(只支持B树索引) |
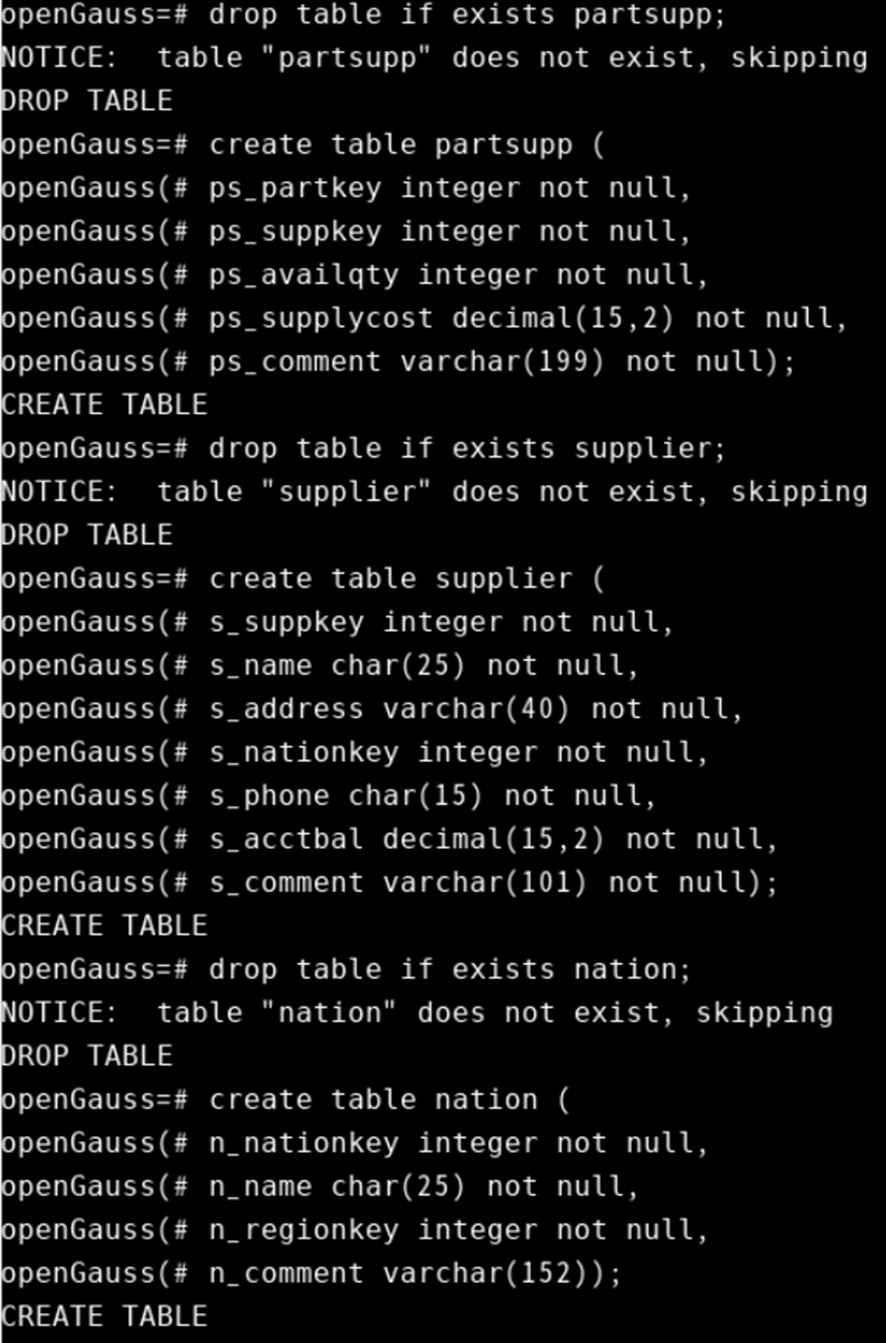
创建测试表结构:
drop table if exists partsupp;
create table partsupp (
ps_partkey integer not null,
ps_suppkey integer not null,
ps_availqty integer not null,
ps_supplycost decimal(15,2) not null,
ps_comment varchar(199) not null);
drop table if exists supplier;
create table supplier (
s_suppkey integer not null,
s_name char(25) not null,
s_address varchar(40) not null,
s_nationkey integer not null,
s_phone char(15) not null,
s_acctbal decimal(15,2) not null,
s_comment varchar(101) not null);
drop table if exists nation;
create table nation (
n_nationkey integer not null,
n_name char(25) not null,
n_regionkey integer not null,
n_comment varchar(152));
表数据文件(CSV),将3个表的csv文件放在$GAUSSHOME/bin目录下:
CSV数据文件从云主机浏览器中访问下面三个链接下载到云主机。
https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0043/nation.csv
https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0043/partsupp.csv
https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0043/supplier.csv
把csv数据文件,移动到主目录下。
mv *.csv ~
cd ~

导入数据(/home/developer/partsupp.csv是本案例当前的文件路径,请根据各自情况修改路径):
登录gsql客户端
cd $GAUSSHOME/bin
./gsql -d postgres -ar

执行下列SQL语句:
\copy partsupp from '/home/developer/partsupp.csv' with ( FORMAT 'csv', DELIMITER ',', ENCODING 'utf8');
\copy supplier from '/home/developer/supplier.csv' with ( FORMAT 'csv', DELIMITER ',', ENCODING 'utf8');
\copy nation from '/home/developer/nation.csv' with ( FORMAT 'csv', DELIMITER ',', ENCODING 'utf8');
select count(*) from partsupp;
select count(*) from supplier;
select count(*) from nation;
打开执行时间统计:
\timing
执行要测试的SQL查询语句:
select
ps_partkey,
sum(ps_supplycost * ps_availqty) as value
from
partsupp,
supplier,
nation
where
ps_suppkey = s_suppkey
and s_nationkey = n_nationkey
and n_name = 'GERMANY'
group by
ps_partkey having
sum(ps_supplycost * ps_availqty) > (
select
sum(ps_supplycost * ps_availqty) * 0.0001000000
from
partsupp,
supplier,
nation
where
ps_suppkey = s_suppkey
and s_nationkey = n_nationkey
and n_name = 'GERMANY'
)
order by
value desc;
执行结果耗时如下所示
![]()
使用gs_index_advise()智能推荐索引。
select * from gs_index_advise('select
ps_partkey,
sum(ps_supplycost * ps_availqty) as value
from
partsupp,
supplier,
nation
where
ps_suppkey = s_suppkey
and s_nationkey = n_nationkey
and n_name = ''GERMANY''
group by
ps_partkey having
sum(ps_supplycost * ps_availqty) > (
select
sum(ps_supplycost * ps_availqty) * 0.0001000000
from
partsupp,
supplier,
nation
where
ps_suppkey = s_suppkey
and s_nationkey = n_nationkey
and n_name = ''GERMANY''
)
order by
value desc');
结果如下:
根据索引推荐的结果,创建对应的索引
create index ps_suppkey_index on partsupp(ps_suppkey);
create index sl_suppkey_nationkey_index on supplier(s_suppkey, s_nationkey);

再执行上面的查询,查看耗时结果

可以明显看出SQL执行时间从1471.799ms降到了585.621ms,速度提升了接近61%。
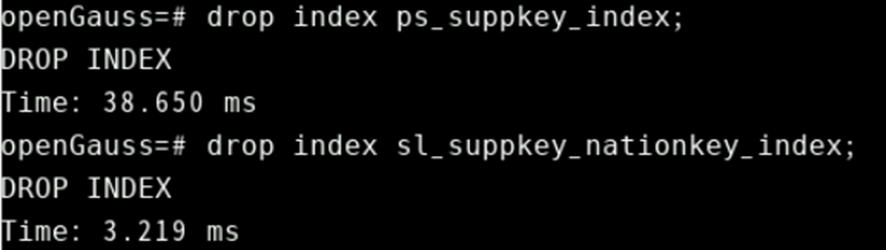
再删除刚才创建的索引:
drop index ps_suppkey_index;
drop index sl_suppkey_nationkey_index;
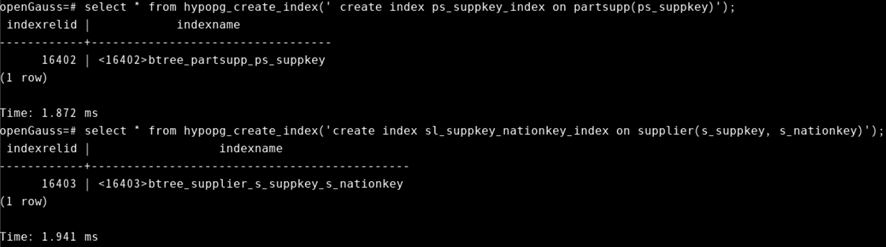
创建虚拟索引:
select * from hypopg_create_index(' create index ps_suppkey_index on partsupp(ps_suppkey)');
select * from hypopg_create_index('create index sl_suppkey_nationkey_index on supplier(s_suppkey, s_nationkey)');
删除索引虚拟列:
select * from hypopg_drop_index(indexrelid);根据本案例在上面的查询结果,indexrelid是16402,16403。
select * from hypopg_drop_index(16402);
select * from hypopg_drop_index(16403);
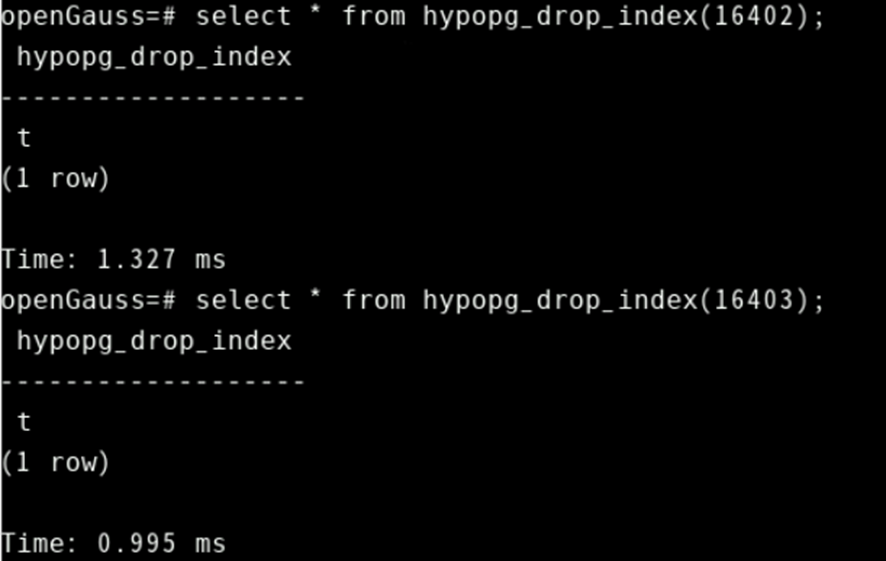
查看虚拟索引列:
select * from hypopg_display_index();再删除该虚拟索引:
select * from hypopg_drop_index(16401);
select * from hypopg_display_index();
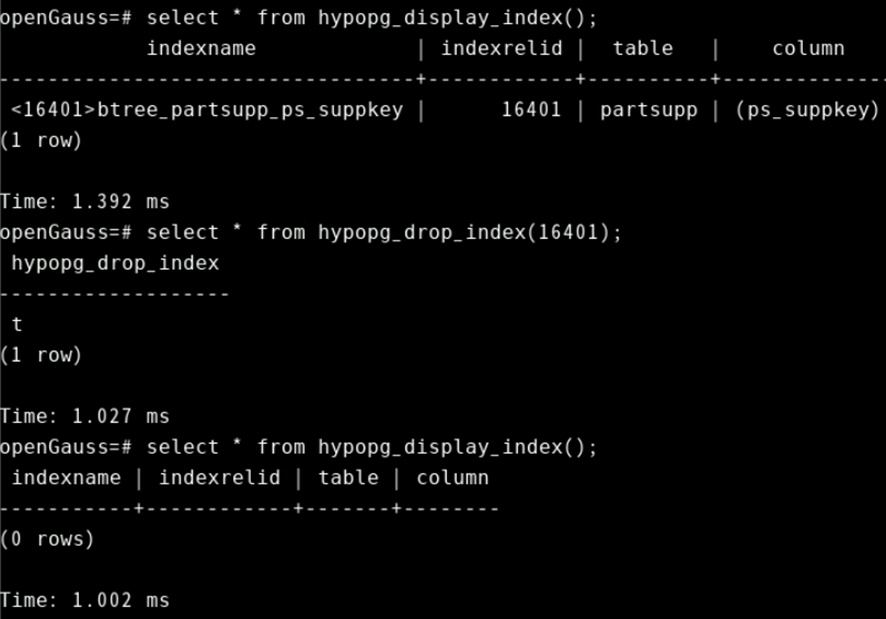
再创建之前的虚拟索引:
select * from hypopg_create_index(' create index ps_suppkey_index on partsupp(ps_suppkey)');获取索引虚拟列大小结果
select * from hypopg_estimate_size(indexrelid);根据上面返回的indexrelid结果,则为
select * from hypopg_estimate_size(16404);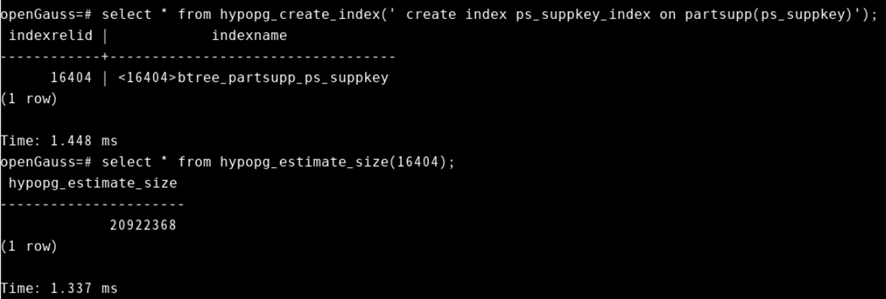
删除所有索引虚拟列:
select * from hypopg_reset_index();再查看虚拟列索引,确认所有虚拟列索引都已经被删除了。
select * from hypopg_display_index();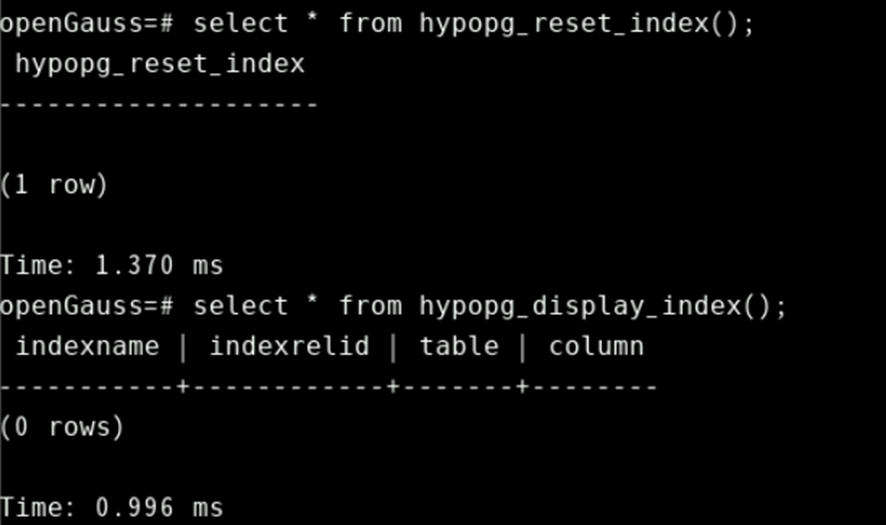
3.2 自调优
数据库自调优技术是一个较大范畴,通常包括对数据库参数配置、自身代价优化模型的调优等。本案例主要介绍对数据库参数配置进行自动调优的功能。
3.2.1 参数自调优的使用场景
数据库系统会提供大量参数供DBA进行调优,OpenGauss提供了500多个参数。很多参数都与数据库的表现密切相关,如负载调度、资源控制、WAL机制等。
数据库参数调优的目的是满足用户对性能的期望,保障数据库系统的稳定可靠。大部分场景中,数据库参数调优依赖DBA去识别和调整,但DBA调优存在很多限制。主要包括三个方面:
- DBA要花费大量时间,在测试环境中参考所要部署的业务进行调优;而每次上线新业务,调优过程需要重新进行一 ,对于企业来说,人力成本巨大。
- DBA通常仅关注少部分关键调优参数,使得调优过程不能完全匹配业务,而且资源利用率及数据库性能并不一定是最优的,而且其他次优参数与数据库表现的隐式关系也没有被充分挖掘出来。
- DBA通常只精通某一个特定的数据库调优,譬如擅长调优A数据库的DBA很可能不擅长调优B数据库,因为二者的底层实现存在很大差异,不可以使用同一套经验进行调优。同时,若硬件环境发生了变化,DBA的经验不一定能发挥作用,多业务混合负载场景下也是如此。
针对上述调优限制,实现一种数据库参数自动调优的方法,从而减少DBA运维代价、提升数据库的整体性能就显得尤为重要。
3.2.2 现有的参数调优技术
参数调优在各领域是一项通用的技术,该技术在各领域不断取得进展。与很多领域一样,数据库中也包含各种各样的参数用于调优,这些参数往往随着业务的变化需要不断进行调整。总体来看,数据库的参数调优主要有以下几种方法。
- 基于规则
基于规则的参数调优是比较简单、通用的方法,通过对人工调优的经验进行整理,编写成各式各样的规则来对数据库系统进行调优。该方法的优点是速度快、可解释性好、稳定性高,缺点是规则随着系统的变化可能会不再适用,推荐的参数往往不是最优的。常见的采用该 的工具为MySQKTuner-perl。
- 基于搜索算法
假设数据库系统只需要调一个参数,且这个参数与性能之间的关系又非常简单(如二者呈线性相关、变化曲线呈二次函数关系),则可以通过二分搜索算法查找出最优的参数值。那么如果系统需要调整多个参数,这些参数彼此之间又互相影响,这时应该如何去调优呢?显示不能再通过二分法就可以解决了,这在数学上属于一个组合优化问题,即在有限的对象集(此处指所有参数自由组合后的可能结果集)中找出最优对象(最优参数配置)的问题。对于组合优化问题,一般的解法包括近似算法(approximation algorithm)、启发式算法(heuristic algorithm)、遗传算法等。由于启发式算法实现相对简单,结果比较稳定,因而被广泛应用,如参数优化方法bestconf就属于此类。基于启发式算法的参数调优方法具有应用场景普遍、优化效果稳定的特点,一般不需要根据系统的变化而进行算法的重新适配,但是每次启动都需要重新探索,不能够重复利用历史探索经验,而且往往容易陷入局部最优。相关搜索算法在其他参数调优领域也有较多的实践,如AutoML中对机器学习算法超参数的调优。
- 基于监督学习
监督学习(supervised learning)是一种通过显式地输入我看下向量和结果标签,寻找二者之间映射关系的一种机器学习算法。它可以根据训练数据学习或建立一个模型,并基于此模型推测新的实例。如果监督学习模型的输出是连续的值则称为回归分析,如果预测一个分类标签则称为分类。
如果可以人为地建立数据库系统的特征(如workload特征、使用环境特征等),并提供在该特征下的最优参数,那么就可以通过上述数据拟合出一个模型,并据此推测出新的数据库系统上的最优参数。
该方法的优点是,一旦训练好模型,推荐新参数的过程将非常快,缺点是训练模型比较复杂(需要收集大量的数据,这些数据本身不容易获取),且模型的输入特征选择比较困难,如果系统发生变化则该模型需要重新训练。例如,学术界比较著名的成果OtterTune就采用了类似的方法。
- 基于强化学习
强化学习(Reinforcement Learning,RL)在近些年发展迅速,基于深度学习的强化学习算法 如DQN(Deep Q-Networks,深度Q学习)、DDPG(Deep Deterministic Policy Gradient,深度确定性策略梯度算法)与PPO(Proximal Policy Optimization,近端策略优化)等先后诞生,该类算法在游戏领域取得了比较好的效果,能够实现自动打游戏,甚至游戏操作优于大多数的人类选手。与此同时,强化学习与监督学习不同,强化学习并不需用户给定一个数据集,而是通过与环境进行交互,通过奖惩机制来学习哪些应该做,哪些不能做,从而给出更优决策。
显然,强化学习能够应用到游戏领域,因为游戏结果的好坏有比较明显的奖惩机制。输赢本身就是一个很好的价值导向,甚至能够不断获得经验值的游戏过程还能够得到连续不断的奖励,这就更容易让算法学到如何获取更多的经验。而反观数据库的调优过程,其实与游戏过程类似。数据库性能的好坏是比较明显的价值导向,数据库的参数配置就相当于游戏过程中的动作,数据库的状态信息也是可以获得的。因此,通过强化来进行数据库参数的优是一个比较好的方案,该方法能够模仿DBA的调优过程,通过数据库性能的高低来激励好的参数配置。该方法的特点是能够从历史经验中进行学习,用训练后的模型进行参数推荐的过程也比较快,而且并不需要用户给定大量的训练数据,缺点是训练过程比较复杂,算法中的奖励机制、数据库系统的状态等都需要精心设计,强化学习训练过程也比较慢。采用该类方法的代表性项目是由清华大学提出的QTune。
通过上述介绍可以得出,似乎并没有一种非常完美的方法能够覆盖到所有的应用场景。严格地讲,每类方法本身并没有优劣之分,只有更加 业务场景的方法才能够称为最优方法。接下来将介绍openGauss开源的数据库参数调优工作X-Tuner,该工具综合了上述多种调优策略的优势。
3.2.3 X-Tuner的调优策略
对数据库进行参数调优可以分为两类模式,分别是离线参数调优和在线参数调优,X-Tuner同时支持上述两类调优模式。
- 离线参数调优是指在数据库脱离生产环境的基础上进行调优,一般是在上线真实业务前进行压力测试,并通过压力测试的反馈结果进行参数调优。
- 在线参数没去优是指不阻塞数据库的正常运行,在数据库运行中进行参数调优或推荐的过程。
具体来说,调优程序X-Tuner包含三种运行模式。
- recommend:获取当前正在运行的workload特征信息,根据该特征信息生成参数推荐报告。报告当前数据库中不合理的参数配置和潜在风险等;输出当前正在运行的workload行为和特征;输出推荐的参数配置。该模式是秒级的,不涉及数据库的重启操作,其他模式可能需要反复重启数据库。
- train:通过用户提供的benchmark信息,迭代地进行参数修改和benchmark(一种用于测量硬件或软件性能的测试程序)执行过程,训练强化学习模型。通过反复的迭代过程,训练强化学习模型,以便用户在后面通过tune模式加载该模型进行调优。
- tune:使用优化算法进行数据库参数的调优,当前支持两大类算法,一种是深度强化学习,另一种是全局搜索算法(全局优化算法)。深度强化学习模式要求先运行train模式,生成训练后的调优模型,而使用全局搜索算法则不需要提前进行训练,可以直接进行搜索调优。如果在tune模式下使用深度强化学习算法,要求必须有一个训练好的模型,且训练该模型时的参数与进行调优时的参数列表(包括max与min)必须一致。
无论是离线参数调优还是在线参数调优,X-Tuner都是支持的,它们的基本结构也是共用的。X-Tuner的结构示意图及交互形式如图所示。
X-Tuner的结构示意图及交互形式:
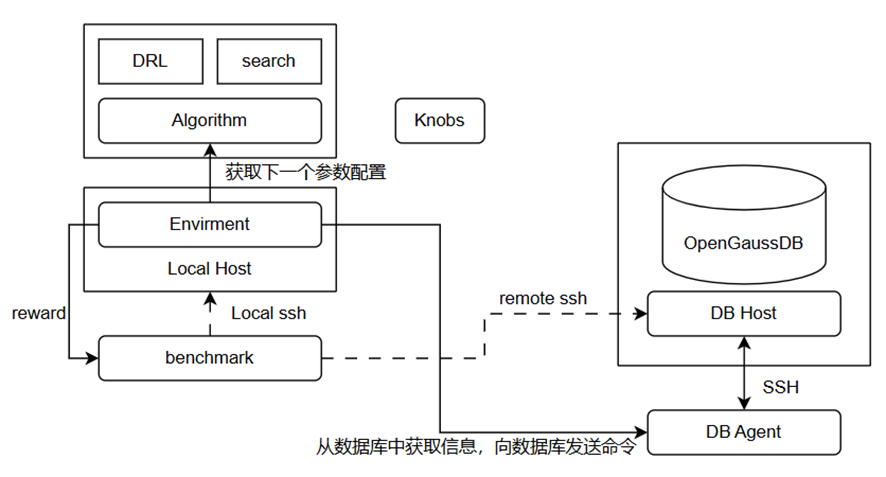
X-Tuner大致分为DB侧、算法侧、主体逻辑模块及benchmark,其各部分的功能说明如表所示。
| X-Tuner结构 | 功能说明 |
|---|---|
| DB侧 | 通过DB_Agent模块对数据库实例进行抽象,通过该模块可以获取数据库内部的状态信息、当前数据库参数及设置数据库参数等。DB侧包括登录数据库环境使用的SSH连接 |
| 算法侧 | 用于调优的算法包,包括全局搜索算法(如贝叶斯优化、粒子群算法等)和深度强化学习(如DDPG) |
| 主体逻辑模块 | 通过Enviroment模块进行封装,每个“sleep”就是一次调优过程。整个调优过程通过多个“step”进行迭代 |
| benchmark | 由用户指定的benchmark性能脚本,用于运行benchmark作业,通过跑分结果反映数据库系统性能优劣 |
- 离线参数调
X-Tuner利用长期在openGaussDB上进行参数调优的先验规则,根据系统的workload、环境特征推荐初始参数调优范围,该范围便是待搜索的配置参数空间。利用算法(如强化学习、启发式算法等)在给定的参数空间上不断进行搜索,即可找到最优的参数配置。
常规评价调优效果好坏的方法是运行benchmark,包括TPC-C、TPC-H及用户自定义的benchmark,用户只需要进行少量适配即可。离线参数调优的流程如图所示,
离线参数调优的流程
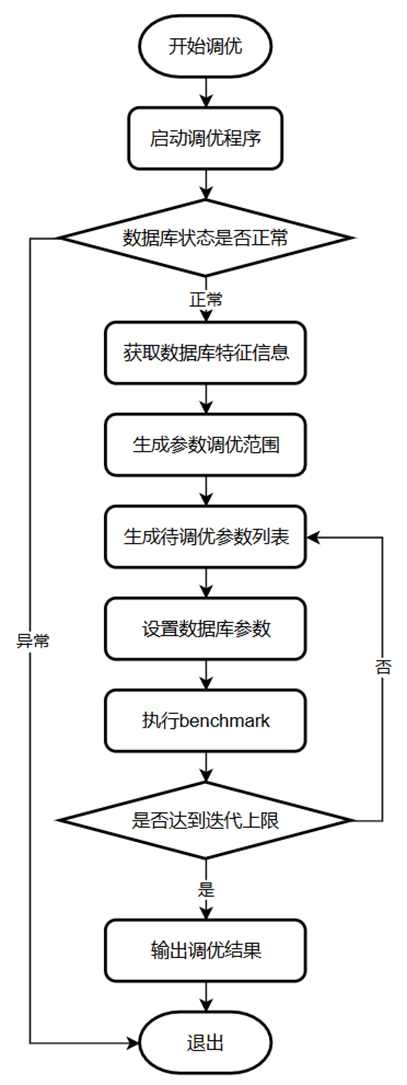
对于离线调优,用户通过benchmark模拟真实环境中的workload,使用调优工具 X-Tuner根据不同参数在benchmark上的表现来判断什么参数能够取得最佳表现。需要注意的是,整个离线调优过程是迭代式的,即设置完一次参数后,执行一次benchmark用于检验本次设置的参数好坏。上述过程称为一次调优过程,那么X-Tuner只需要多次执行上述过程,即可找到一个最佳的参数配置。X-Tuner可以根据上一个调优过程的反馈,决定下一次调优中参数的寻找方向,这个过程也是优化算法的探索过程。
上述过程需要一个初始参数配置,已经训练好的强化学习模型会利用模型初始化这个初始参数配置。若采用搜索算法,则根据先验规则进行初始化。
由于某些数据库参数需要重启后才可生效,因此离线参数调优过程也可能是需要频繁地重启数据库的。离线调优过程与DBA手动调优过程比较相似,都是通过观察—试探—再观察—再试探进行的,只不过这个试探过程不是基于DBA的人工经验,而是通过算法的分析进行的。该过程也是比较耗时的,主要耗在执行benchmark上。
对于一些场景,可以采用EXPLAIN命令替代,这样就可以省掉执行benchmark的间,但是EXPLAIN并不能直接反映参数对缓冲区、WAL等数据库系统内部模块的影响,因此可使用的场景是有限的。业内一个比较前沿的方法,是通过AI的方法,预估数据库的性能表现,一般称之为性能评估模型(performance model),通过该模型,可以省去执行benchmark的时间,从而压缩调优时间。不过该方法主要停留在理论层面,距在普适场景上的应用尚有差距,目前也在openGaussDB的演进方向中。
X-Tuner目前支持的强化学习算法主要为DDPG,支持的搜索算法主要为粒子群算法(Particle Swarm Optimization,PSO)与贝叶斯优化算法(bayesian optimization)。
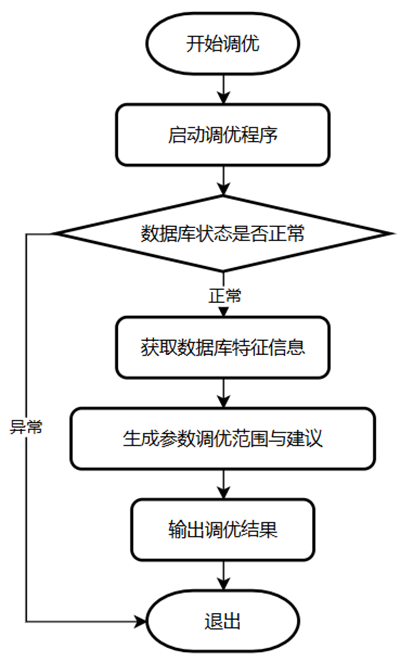
- 在线参数调优
X-Tuner采集操作系统的统计信息和workload特征,根据训练好的监督学习模型或先验规则,推荐给用户对应的参数修改建议。在线参数调优的流程图如下所示。
在线参数调优流程图
3.2.4 OpenGaussDB关键源码说明
X-Tuner的代码,华为开源社区已经从OpenGauss内核源码里脱离出来,形成了一个单独的开源项目DBMind,链接如下:
https://gitee.com/opengauss/openGauss-DBMind
下载DBMind源码
git clone --depth 1 https://gitee.com/opengauss/openGauss-DBMind.git
ls openGauss-DBMind/
chmod +x openGauss-DBMind/gs_dbmind
echo PATH=`pwd`/openGauss-DBMind:'$PATH' >> ~/.bashrc
echo 'export PATH' >> ~/.bashrc
source ~/.bashrc

cd openGauss-DBMind/
python3 -m pip install -r requirements-aarch64.txt

cd openGauss-DBMind/dbmind/components/xtuner
ls -al
share为配置文件示例目录,tuner目录调优程序主代码目录。
ls -al tuner/
|
tuner/algorithms |
算法子模块 |
|
tuner/benchmark |
压力测试驱动脚本存储目录 |
|
tuner/character.py |
获取系统workload特征的模块 |
|
tuner/db_agent.py |
封装数据库操作的模块 |
|
tuner/db_env.py |
离线调优流程控制模块 |
|
tuner/env.py |
保持与强化学习gym库的接口一致 |
|
tuner/exception.py |
定义常见异常 |
|
tuner/knob.py |
定义参数相关类 |
|
tuner/main.py |
入口文件 |
|
tuner/recommend.py |
定义参数推荐的算法与规则 |
|
tuner/recorder.py |
记录调优过程的模块 |
|
tuner/utils.py |
定义一些工具函数 |
|
tuner/xtuner.conf |
默认配置文件 |
|
tuner/xtuner.py |
调优主流程控制模块 |
ls -al tuner/algorithms/
tuner/algorithms/pso.py文件是粒子群算法文件。
ls -al tuner/benchmark/
X-Tuner主要源码文件结构
|
tuner/benchmark/sysbench.py |
sysbench驱动脚本 |
|
tuner/benchmark/template.py |
压力测试驱动脚本的模板 |
|
tuner/benchmark/tpcc.py |
TPC-C驱动脚本 |
|
tuner/benchmark/tpcds.py |
TPC-DS驱动脚本 |
|
tuner/benchmark/tpch.py |
TPC-H驱动脚本 |
注:具体源码本案例不用详解,请读者自行研究。
3.2.5 使用示例
给openGaussDB初始化用户:
cd $GAUSSHOME/bin
./gsql -d postgres -ar
create user dbmind_monitor sysadmin password 'GaussDB_123';
alter user dbmind_monitor monadmin;
进入tuner目录(main.py文件所在路径),添加环境变量PYTHONPATH
cd openGauss-DBMind/dbmind/components/xtuner/tuner
export PYTHONPATH=`pwd`/..
sudo yum install lapack lapack-devel blas blas-devel
pip install paramiko bayesian-optimization ptable
pip install tensorflow>=2.2.0 keras-rl2 keras>=2.4.0
python3 -m pip install -r ~/openGauss-DBMind/requirements-optional.txt
根据openGauss-DBMind/dbmind/components/xtuner/share里的jsoin模板,拷贝对应的josn文件到tuner文件中。其中模板有knobs.json.template,server.json.template,xtuner.conf.template。到~/openGauss-DBMind/dbmind/components/xtuner/tuner目录下对应的knobs.json,server.json,xtuner.conf文件。
cp ~/openGauss-DBMind/dbmind/components/xtuner/share/knobs.json.template ~/openGauss-DBMind/dbmind/components/xtuner/tuner/knobs.json
cp ~/openGauss-DBMind/dbmind/components/xtuner/share/server.json.template ~/openGauss-DBMind/dbmind/components/xtuner/tuner/server.json
cp ~/openGauss-DBMind/dbmind/components/xtuner/share/xtuner.json.template ~/openGauss-DBMind/dbmind/components/xtuner/tuner/xtuner.json
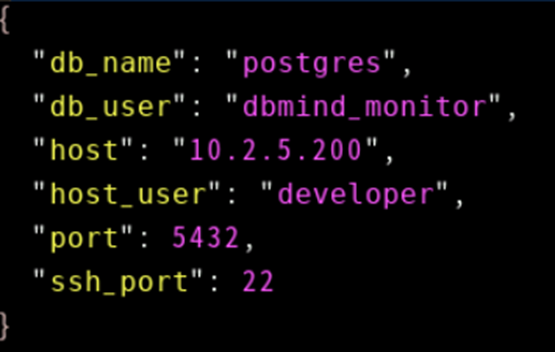
根据各自的环境参数,修改server.json配置文件。
vim ~/openGauss-DBMind/dbmind/components/xtuner/tuner/server.json本案例参数如下,仅做参考:
xtuner.conf里需要修改的是benchmark_path, tuning_list


注:由于运行过程中,需要输入host_user的passwrod,所以如果不清楚云主机developer用户的密码时,可以通过如下命令修改该用户密码:
sudo passwd developer切换到tuner目录,执行如下命令:
cd ~/openGauss-DBMind/dbmind/components/xtuner/tuner
gs_dbmind component xtuner tune -f server.json
本案例由于是openEuler的arm架构环境,故在运行时会报错,根据报错信息自行修改代码。如下:
在openGauss-DBMind/dbmind/components/xtuner/tuner/character.py里的368行处,由于本案例的系统环境,lscpu命令返回的数据库CPU没有' (s) ',所以应该修改代码,如下:

根据本案例云主机环境的实际情况,执行shell命令:
lscpu | grep 'CPU'
根据character.py的代码逻辑,此处应该是返回cpu的核心数量,所以exec_command_on_host()的命令应该做修改处理。
lscpu | grep 'CPU:' | head -1 | awk '{print $2}'
修改源码如下:

再运行命令:
gs_dbmind component xtuner tune -f server.json
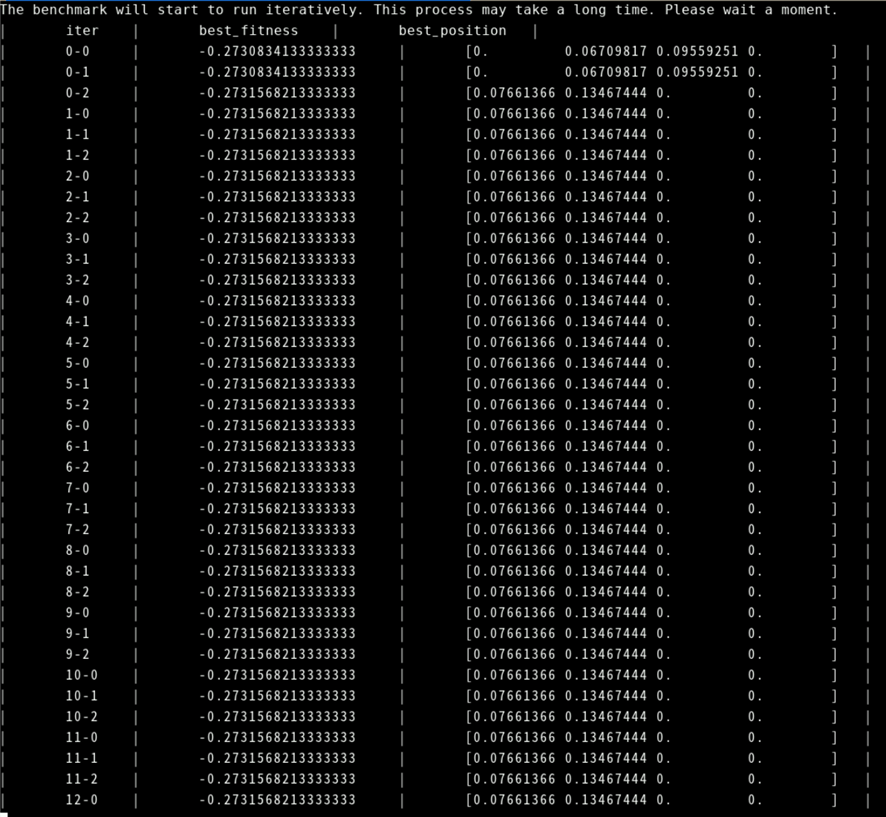
该过程是根据benchmark做性能压力测试,根据数据不停的迭代openGaussDB的配置参数,根据实际测试的性能结果,自学习调优配置参数。该过程耗时较长。
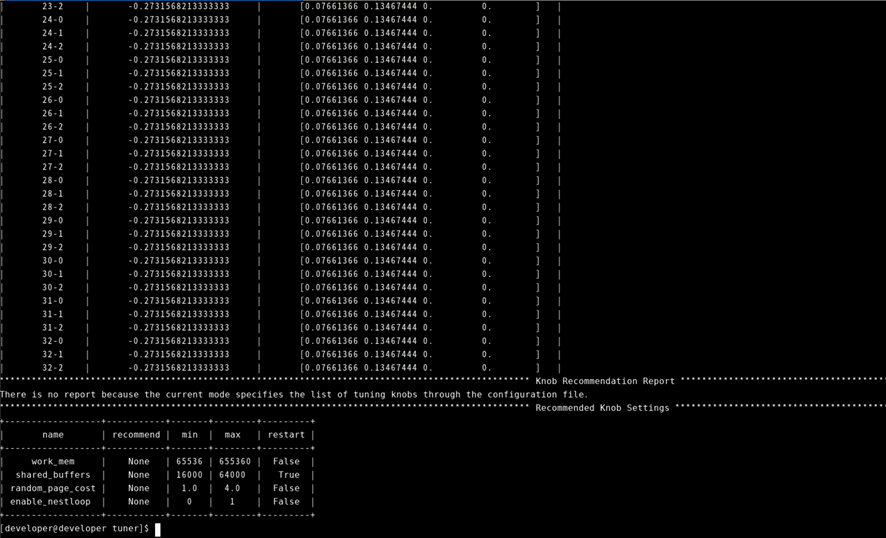
根据结果可知,目前DBMind工具中的xtuner组件功能存在问题,功能不完善,需要后续优化。
3.3 自监控慢SQL
开发者基于历史SQL语句信息进行模型训练,并用训练好的模型进行SQL语句的预测,利用预测结果判断该SQL语句是否是潜在的慢SQL。当发现潜在的慢SQL后,开发者便可以进行针对性优化或者风险评估,以防业务上线后发生问题。
3.3.1 慢SQL监控功能
上线业务预检测:上线一批新业务前,使用SQL诊断功能评估此次上线业务的预估执行时长,便于用户参考是否应该修改上线业务。
workload分析:能够对现有workload进行分析,将现有workload自动分为若干类别,并依次分析此类别SQL语句执行代价,以及各个类别之间的相似程度。
3.3.2 现有技术
首先明确慢SQL发现的几个不同阶段,以及其对应解决的问题。
阶段1:对用户输入的一批业务SQL语句进行分析,推断SQL语句执行时间的快慢,进而可以将评估为慢SQL的语句识别出来。
阶段2:对识别出的潜在慢SQL进行根因诊断,判断这些SQL语句是因为什么慢,例如比较常见的原因可能是数据量过大、SQL语句自身过于复杂、容易产生并发的锁冲突、没有创建索引导致全表扫描等。
阶段3:对于已经识别出的慢SQL语句的可能问题源,给出针对性的解决方案,如可以提示用户进行SQL语句的改写、创建索引等。
目前OpenGauss已经具备阶段1的能力,正在推进阶段2能力,同时发布了部分阶段3的能力,如索引推荐功能。
业内对于上述第一阶段的主要实现方法大部分是通过执行计划进行估计的,第二阶段大多是通过构建故障模式、通过启发式规则来实现的,有了上述前两个阶段的准备,阶段3的实现往往是比较独立的。学术界对于阶段1的研究比较多,阶段2采用常规的构建故障模式库的方法已经能取得比较好的效果了,因此并不是研究的热点,而阶段3的工作又相对独立,可以单独作为一个领域进行研究。因此,这里仅介绍业内是如何评估SQL语句执行时间的,其他两部分暂不详细展开。
3.3.2.1 基于执行计划的在线SVM模型
基于执行计划的在线SVM(Support Vector Machine,支持向量机)模型包含训练模块和测试模块。
基于执行计划的在线SVM模型系统架构
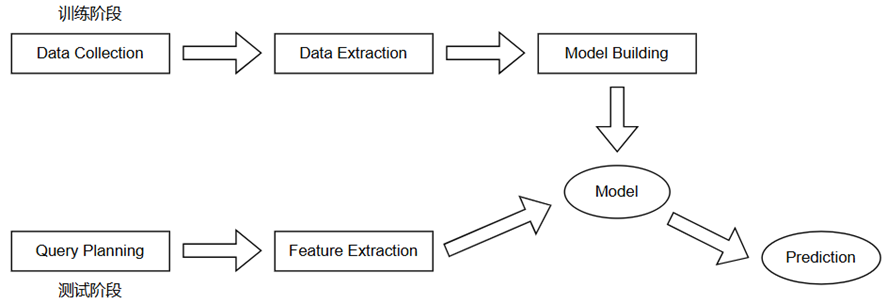
训练阶段:Data Collection模块执行作为训练集的语句;Data Extraction模块收集执行的语句特征及执行时间,包括执行计划及算子级别的信息;Model Building模块基于计划级别特征与算子级别信息分别训练SVM模型,再将两模型通过误差分布结合,生成最终的预测模型。这主要是考虑到计划级别信息具有普适性,而算子级别信息具有更高的精确性,结合两者可以在保持具有普适性的前提下,尽可能地精确预测。
测试阶段:Query Planning模块生成待预测语句的执行计划;Feature Extraction模块抽取这些计划中的特征,整合后投入训练阶段生成的模型中产生预测结果。
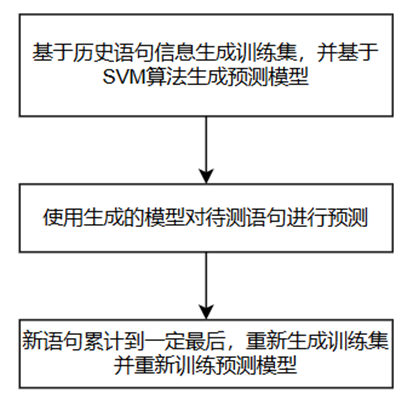
整个功能的流程如图所示。基于执行计划的在线SVM技术的缺点:
- 如果场景不同,当参数发生变化时,系统不能很快感知,预测会有较大误差。
- 预测过程依赖待测语句的执行计划,加重了数据库的负荷,对于OLTP场景格外不适用。
- 每次重启都要重新训练,不能利用历史训练经验。
3.3.2.2 基于执行计划的MART模型
基于执行计划的MART(multiple additive regression trees,多重累加回归树)模型系统架构如图所示,主要包含离线训练阶段和在线预测阶段,它们的功能如下所示。
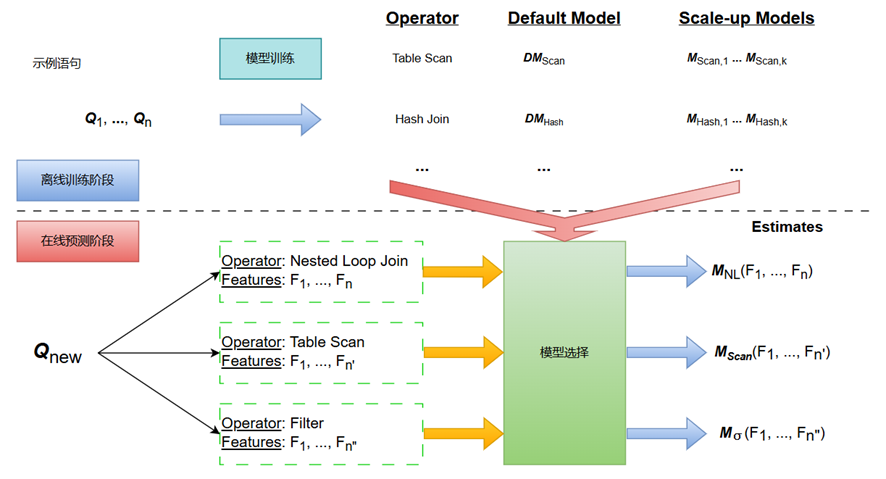
离线训练阶段:针对数据库每种类型的算子(如Table Scan、Merge Join、Sort),分别训练其对应的模型,用于估算此算子的开销。此外,使用单独的训练阶段,可为不同的算子选择适当的缩放函数。最后形成带缩放函数的不同的回归树模型。
在线预测阶段:计算出执行计划中所有算子的特征值,然后使用特征值为算子选择合适的模型,并使用它来估算执行时间。
整个功能的流程图如下所示
基于执行计划的MART模型流程
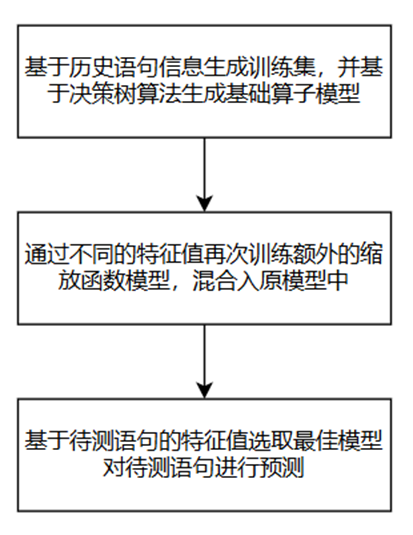
基于执行计划的MART模型调优技术的缺点:
- 泛用性较差,强依赖训练好的算子模型,遇到用户自定义函数的未知语句时,预测效果会较差。
- 缩放函数依赖先验结果,对于超出范围的特征值效果无法保证。
- 预测过程依赖待测语句的执行计划,加重了数据库的负荷,很难推广到OLTP场景中。
3.3.2.3 基于执行计划的DNN模型
该技术方案的系统架构图与SVN模型架构图类似,区别在于SVN模型的Model Building模块中选择的算法不同。基于执行计划的DNN模型的算法架构如图所示。
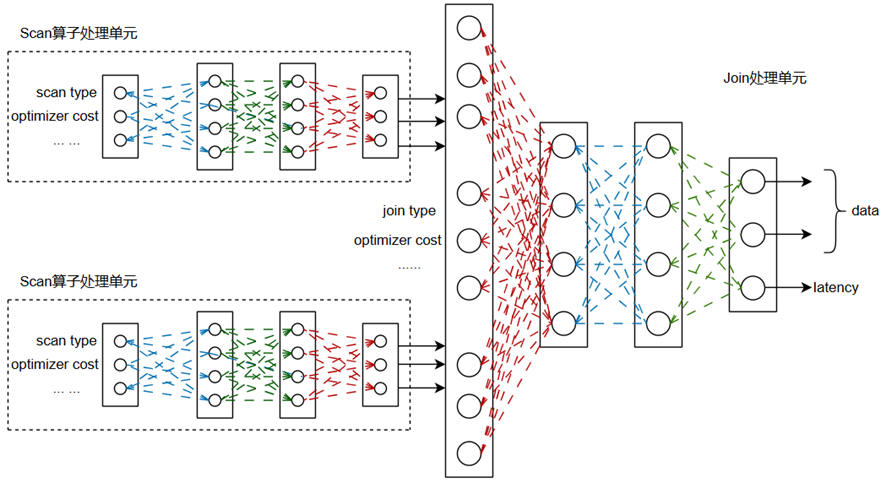
该算法依然是将执行计划中的算子信息输入深度学习网格中,从而对执行时间进行预测。对于每个算子,收集左右子树的向量化特征、优化器代价及执行时间,输入与之对应的模型中,预测该算子的向量化特征及执行时间等。上述图显示了一个join操作的预测过程,其左右子树均为Scan算子,将两个Scan算子通过对应的模型预测出的向量化特征、执行时间及该join算子的优化器评估代价作为入参,输出join算子模型得到该操作的向量化特征及预测出的执行时间。上述过程是个自底向上的过程。
整个功能的流程如图所示:
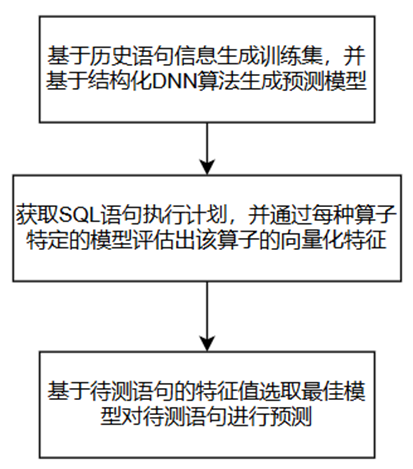
基于执行计划的DNN模型技术的缺点:
- 需要通过已预测算子不断修正模型,预测过程会较慢。
- 对环境变化感知差,如数据库参数变化会使得原模型几乎完全失效。
- 预测过程依赖待测语句的执行计划,加重了数据库的负荷,对于OLTP场景格外不适用。
3.3.3 慢SQL发现采取的策略
慢SQL发现工具SQL Drag的执行过程
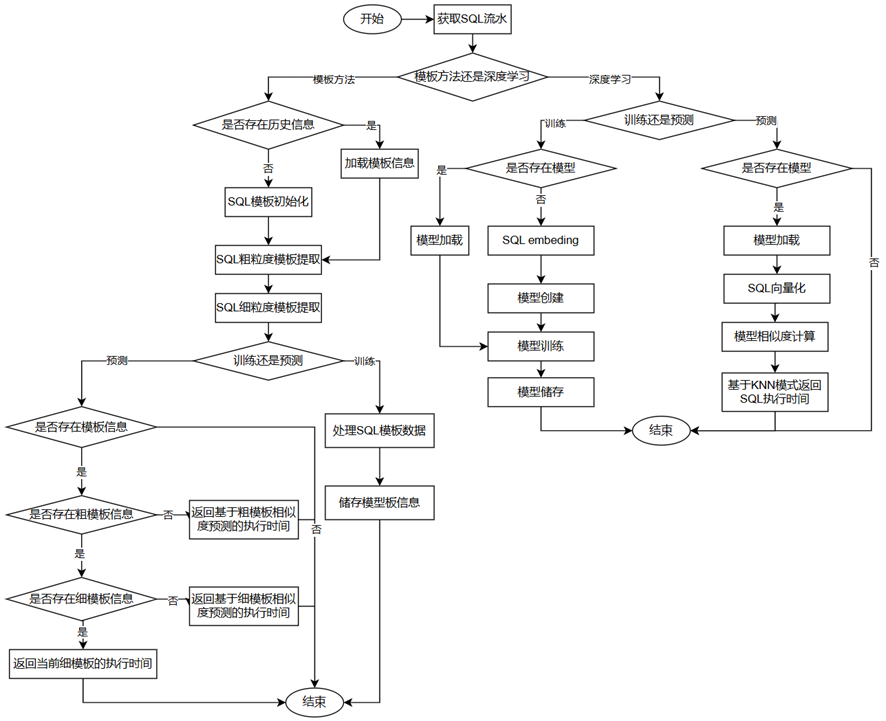
慢SQL发现工具SQL Diag的执行流程如图所示,该过程可以分为从部分,分别是基于模板化的流程和基于深度学习的流程,下面分别介绍这两部分。
3.3.3.1 基于模板化的流程
- 获取SQL流水数据。
- 检测本地是否存在对应实例的历史模板信息,如果存在,则加载该模板信息,如果不存在,则对该模板进行初始化。
- 基于SQL数据,提取SQL的粗粒度模板信息。粗粒度模板表示将SQL中表名、列名和其他敏感信息去除之后的SQL语句模板,该模板只保留最基本的SQL语句骨架。
- 基于SQL数据,提取SQL细粒度的模板信息。细粒度模板是在粗粒度模板信息的基础上保留表名、列名等关键信息的SQL语句模板。细粒度模板相对粗粒度模板保留了更多SQL语句的信息。
- 执行训练过程时,首先构造SQL语句的基于粗粒度模板和细粒度模板信息,例如粗粒度模板ID、执行平均时间、细模板执行时间序列、基于滑动窗口计算出的平均执行时间等。最后将上述模板信息进行储存。
- 执行预测过程时,首先导入对应实例的模板信息,如果不存在该模板信息,如果不存在该模板信息,则直接报错退出,否则继续检测是否存在该SQL语句的粗粒度模板信息,如果不存在,则基于模板相似度计算方法在所有粗粒度模板里面寻找最相似的N条模板,之后基于KNN(K邻近)算法预测出执行时间;如果存在粗粒度模板,则接着检测是否存在近似的细粒度模板,如果不存在,则基于模板相似度计算方法在所有细粒度模板里面寻找最相似的N条模板,之后基于KNN预测出执行时间;如果存在 匹配的细粒度模板,则于当前模板数据直接返回对应的执行时间。
3.3.3.2 基于深度学习的执行流程
- 获取SQL流水。
- 在训练过程中,首先判断是否存在历史模型,如果存在,则导入模型进行增量训练;如果不存在历史模型,则首先利用word2vector算法对SQL语句进行向量化,即上图中的SQL embeding过程。然后创建深度学习模型,将该SQL语句向量化的结果作为输入特征。基于训练数据进行训练,并将模型保存到本地。值得一提的是,该深度学习模型的最后一个全连接层网络的输出结果作为该SQL语句的特征向量。
- 在预测过程中,首先判断是否存在模型,如果模型不存在,则直接报错退出;如果存在模型,则导入模型,并利用word2vector算法将待预测的SQL语句进行向量化,并将该向量输入深度学习网络中,获取该神经网络的最后一个全连接层的输出结果,即为该SQL语句的特征向量。最后,利用余弦相似度在样本数据集中进行寻找,找到相似度最高的SQL语句。当然,如果是基于最新SQL语句执行时间数据集训练出的深度学习模型,则模型的回归预测结果也可以作为预估执行时间。
3.3.4 使用示例
案例测试用例见如下链接:
本案例不再做过多说明。感兴趣的读者自行学习。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)