【深度解析】多模态MoE模型训练策略:LLaVA-MoE与Kimi-VL
本文对比分析了两种多模态混合专家模型(MoE)的训练策略。LLaVA-MoE采用三阶段渐进式训练:1)视觉-语言对齐(冻结ViT和LLM,训练投影器);2)指令遵循能力训练(解冻LLM);3)MoE结构优化(训练路由器和专家)。Kimi-VL则采用四阶段训练:1)单独预训练ViT和LLM;2)图文理解训练;3)联合冷却;4)长内容扩展训练,特别强化了128K长文本和高分辨率图像处理能力。两种策略各
作者:昇腾实战派 * Ming-L
公众号:AI模力圈
1. 背景概述
随着多模态大模型的快速发展,如何在有限的计算资源下提升模型性能成为关键挑战。混合专家模型(MoE,Mixture of Experts)通过稀疏激活机制,在保持模型容量的同时显著降低推理成本,为多模态任务提供了高效解决方案。
本文将结合实践案例,深入分析两种典型的多模态MoE模型(LLaVA-MoE和Kimi-VL)的训练策略,为相关研究和应用提供参考。
推荐资源:昇腾MindSpeed加速库对Llava等多模态模型都做了适配,具有很好的效果和性能收益。
官方代码仓库:MindSpeed-MM
2. LLaVA-MoE训练策略
LLaVA-MoE采用经典的三阶段训练流程,逐步实现视觉-语言对齐、指令遵循能力和MoE结构优化。
2.1 训练流程图
阶段1: 视觉-语言对齐 → 阶段2: 指令遵循能力训练 → 阶段3: MoE结构优化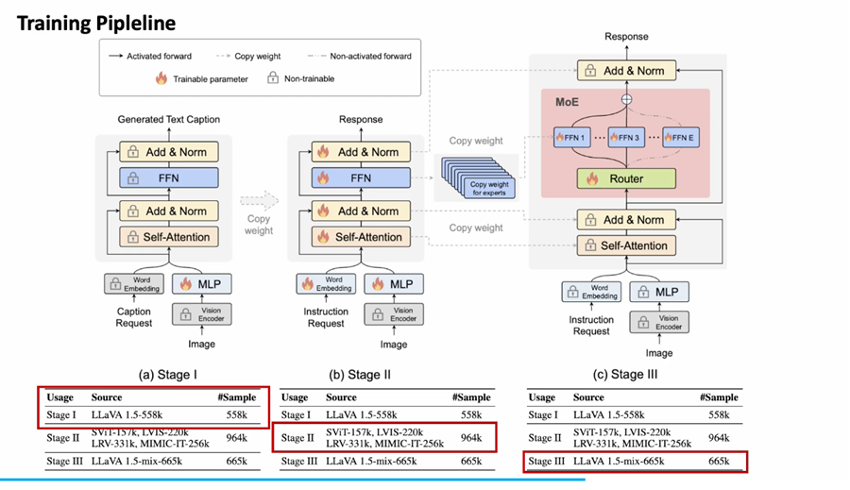
LLaVA-MoE训练流程
2.2 阶段划分与实施细节
阶段1: 视觉-语言对齐
• 主要目标: 建立视觉编码器与语言模型的有效连接,使语言模型能够正确理解图像内容
• 实施方法:
◦ 冻结ViT(Vision Transformer)参数
◦ 冻结LLM参数
◦ 仅训练MLP Projector模块
• 模型配置: 使用标准的Dense结构作为基础LLM
阶段2: 指令遵循能力训练
• 主要目标: 提升模型对复杂指令的理解和执行能力
• 实施方法:
◦ 继承第一阶段权重
◦ 解冻并训练LLM和Projector
◦ 保持ViT冻结
◦ 使用高质量的指令遵循数据集
阶段3: MoE结构优化
• 主要目标: 将Dense FFN转换为MoE结构并优化专家分工
• 实施方法:
◦ 复制预训练的FFN形成多个专家
◦ 初始化MoE参数
◦ 仅训练router和expert
◦ 保持ViT和Projector参数冻结
2.3 训练策略总结表
|
阶段 |
主要目的 |
冻结的部分 |
训练的部分 |
|
第一阶段 |
链接VIT和LLM,让LLM看懂图像 |
LLM-dense、VIT |
Projector |
|
第二阶段 |
训练模型的指令遵循能力 |
VIT |
LLM-Dense、Projector |
|
第三阶段 |
MoE训练 |
VIT、Projector |
LLM-MoE-FFN |
3. Kimi-VL-Moe训练策略
3.1 模型简介
月之暗面基于MoE架构的高效多模态模型Kimi-VL,它具有先进的多模态推理、长文本理解以及强大的agent能力。
模型参数:
• 模型总参数: 16B
• 推理时激活参数: < 3B
• 上下文窗口: 128K扩展上下文
性能表现:
|
测试集 |
得分 |
|
LongVideoBench |
64.5 |
|
MMLongBench-Doc |
35.1 |
|
InfoVQA |
83.2 |
|
ScreenSpot-Pro |
34.5 |
Kimi-VL在处理长文本和清晰感知方面推进了多模态模型的帕累托前沿,配备了128K扩展上下文窗口,能够处理长且多样化的输入。其原生分辨率的视觉编码器MoonViT(基于SigLIP-SO-400M微调),进一步使其能够看到并理解超高分辨率的视觉输入,同时在处理常见视觉输入和一般任务时保持较低的计算成本。
3.2 模型架构
Kimi-VL采用了专家混合(MoE)语言模型(之前发布的Moonlight-16B-A3B)、原生分辨率的视觉编码器(MoonViT)以及一个多层感知机(MLP)投影器。
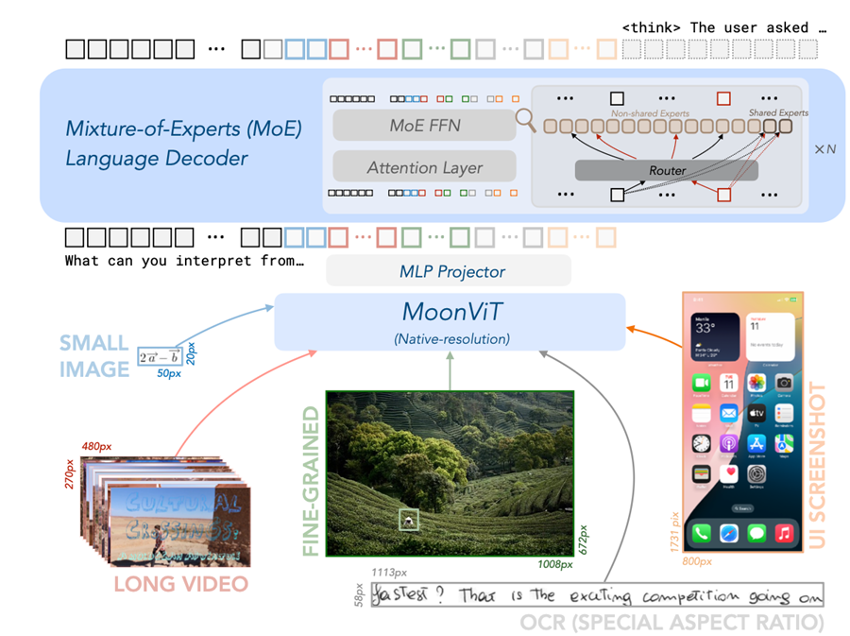
Kimi-VL架构图
3.3 多模态训练策略
在加载语言模型之后,Kimi-VL的预训练总共包括4个阶段,总共训练了4.4T tokens。首先,独立进行ViT训练,以建立一个健壮的原生分辨率视觉编码器,随后是三个联合训练阶段(预训练、冷却和长上下文激活),这些阶段同时增强模型的语言和多模态能力。

Kimi-VL训练流程
阶段详细说明
|
阶段 |
主要目的 |
训练方式 |
冻结的部分 |
训练的部分 |
|
第一阶段 |
单独训练VIT和LLM |
预先训练VIT和LLM |
/ |
VIT、LLM |
|
第二阶段 |
训练模型的图文理解 |
控制图文token数,提供图文混合数据及纯文本数据 |
/ |
VIT、LLM |
|
第三阶段 |
联合冷却 |
使用高质量图文数据联合训练 |
/ |
VIT、LLM |
|
第四阶段 |
联合长内容扩展 |
使用长文本、长视频等长内容进行训练 |
/ |
VIT、LLM |
技术要点:
• 第二阶段中,图的token数要多的多,防止模型看完图忘了怎么写字
• 所有阶段均训练VIT和LLM,没有参数冻结策略
3.4 参考技术报告
• 官方技术报告:Kimi-VL-A3B-Instruct
• GitHub项目:MoonshotAI/Kimi-VL
4. 两种训练策略对比
|
对比维度 |
LLaVA-MoE |
Kimi-VL |
|
训练阶段数 |
3阶段 |
4阶段 |
|
总训练量 |
未公开 |
4.4T tokens |
|
参数冻结策略 |
明确的分层冻结 |
无冻结,全程训练VIT+LLM |
|
核心优势 |
渐进式训练,稳定性高 |
长文本+高分辨率处理能力强 |
|
上下文窗口 |
标准长度 |
128K扩展 |
|
激活参数 |
未公开 |
16B总参,< 3B激活 |
5. 总结
两种多模态MoE模型训练策略各有特色:
1. LLaVA-MoE采用渐进式三阶段训练策略,通过明确的参数冻结策略,逐步实现视觉-语言对齐、指令遵循能力和MoE结构优化,适合需要稳定训练流程的场景。
2. Kimi-VL采用四阶段预训练策略,特别强调长文本和高分辨率视觉处理能力,在图文token配比和长内容训练上有独到设计,适合需要处理长文本和高分辨率图像的应用场景。
6. 参考链接
如果你对多模态大模型、强化学习、昇腾 NPU 部署、模型性能优化感兴趣,欢迎持续关注【AI模力圈】。
我们会持续更新:
1. 多模态模型结构拆解
2. 强化学习算法原理与实践
3. 昇腾 NPU 迁移部署与踩坑复盘
4. 模型训练与推理性能优化
图解版、速读版内容也会同步更新到公众号 / 小红书。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 4
4 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)