PDF-Extract-Kit部署指南:国产化平台适配方案
本文详细介绍了在飞腾、鲲鹏、龙芯等国产CPU平台的基础环境搭建从CUDA依赖转向ONNX Runtime多后端支持的技术路径利用CPU或国产AI加速卡(如昇腾)实现模型推理WebUI服务的稳定运行与功能验证实践表明,该工具箱在去除NVIDIA依赖后,仍可在统信UOS、银河麒麟等系统上正常运行,满足基本的PDF内容提取需求。
PDF-Extract-Kit部署指南:国产化平台适配方案
1. 引言
1.1 技术背景与业务需求
随着国内信创产业的快速发展,越来越多的企业和科研机构开始将关键系统迁移至国产化软硬件平台。在文档智能处理领域,PDF作为最通用的电子文档格式之一,其内容提取能力直接影响知识管理、信息抽取和自动化办公效率。
然而,主流的PDF解析工具大多依赖于x86架构和国外操作系统生态,在龙芯、飞腾、鲲鹏等国产CPU以及统信UOS、麒麟OS等国产操作系统上存在兼容性差、性能低下甚至无法运行的问题。
在此背景下,PDF-Extract-Kit 应运而生。该项目由开发者“科哥”基于开源技术栈二次开发构建,定位为一个高精度、模块化、可扩展的PDF智能提取工具箱,支持布局分析、公式识别、表格解析、OCR文字提取等核心功能,并通过WebUI提供友好的交互界面。
更重要的是,该项目已在多个国产化平台上完成初步验证与适配,具备良好的跨平台移植潜力,是当前少数能较好支持信创环境的文档智能处理解决方案之一。
1.2 方案价值与适用场景
本部署指南聚焦于如何在国产化软硬件平台上成功部署并优化运行 PDF-Extract-Kit,解决以下关键问题:
- 如何绕过对CUDA和NVIDIA驱动的强依赖(因多数国产GPU不支持)
- 如何在ARM64或LoongArch架构下编译安装Python依赖
- 如何调整模型推理后端以适配昇腾(Ascend)、昆仑芯等国产AI加速卡
- 如何提升整体处理速度以弥补国产平台算力短板
典型应用场景包括: - 国家机关/国企内部文档数字化 - 高校科研论文中的公式与图表批量提取 - 教育行业试卷扫描件的内容结构化解析 - 涉密单位本地化部署的无网环境使用
2. 环境准备与基础配置
2.1 支持的国产化平台清单
| 类别 | 已验证平台 | 备注 |
|---|---|---|
| CPU架构 | 飞腾FT-2000+/64、鲲鹏920、龙芯3A5000 | LoongArch指令集需特殊编译 |
| 操作系统 | 统信UOS V20、银河麒麟V10 SP2 | 均为基于Linux内核的发行版 |
| AI加速卡 | 昇腾310/910、寒武纪MLU270 | 可选,用于替代GPU推理 |
| 容器环境 | iSulad(替代Docker) | 华为开源轻量级容器引擎 |
⚠️ 注意:目前项目默认依赖PyTorch + CUDA,若目标平台无NVIDIA GPU,请务必切换至CPU或国产AI芯片推理模式。
2.2 基础软件依赖安装
在国产Linux系统中,推荐使用apt或yum包管理器安装基础组件:
# 统信UOS / 麒麟OS 使用 apt
sudo apt update
sudo apt install -y python3 python3-pip git build-essential libgl1 libglib2.0-0
# 若需图像处理支持
sudo apt install -y libsm6 libxext6 libxrender-dev libfontconfig1
# 升级pip至最新版本
python3 -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
2.3 Python虚拟环境创建
建议使用venv隔离项目依赖:
# 创建虚拟环境
python3 -m venv pdf_env
# 激活环境
source pdf_env/bin/activate
# 升级pip
pip install --upgrade pip
3. 项目部署与国产化适配实践
3.1 源码获取与目录结构
从GitHub克隆项目源码(假设已同步至内网Git服务器):
git clone https://your-intranet-git-server.com/kege/PDF-Extract-Kit.git
cd PDF-Extract-Kit
主要目录结构如下:
PDF-Extract-Kit/
├── webui/ # Web前端与Flask服务
├── models/ # 预训练模型文件(YOLO、CRNN等)
├── utils/ # 工具函数库
├── requirements.txt # Python依赖声明
├── start_webui.sh # 启动脚本
└── outputs/ # 输出结果存储(自动生成)
3.2 依赖安装适配策略
原始requirements.txt包含大量仅适用于x86+GPU的包,需进行裁剪与替换。
修改后的国产化适配依赖(部分)
Flask==2.3.3
numpy==1.24.3
opencv-python-headless==4.8.0.76
Pillow==9.5.0
torch==1.13.1+cpu # 使用CPU版本PyTorch
torchaudio==0.13.1+cpu
torchvision==0.14.1+cpu
pyyaml==6.0
tqdm==4.65.0
paddlepaddle==2.5.0 # PaddleOCR依赖
paddleocr==2.7.0.3
onnxruntime==1.15.1 # 支持多后端推理
安装命令:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
💡 提示:对于无法直接安装的包(如
onnxruntime在龙芯平台),可尝试从源码编译或联系社区获取预编译wheel包。
3.3 推理后端切换:从CUDA到ONNX Runtime
为摆脱对CUDA的依赖,建议将YOLO和公式识别模型转换为ONNX格式,并使用ONNX Runtime作为统一推理引擎。
示例:YOLO模型导出为ONNX
import torch
from models.common import DetectMultiBackend
# 加载原模型
model = DetectMultiBackend('models/yolo_layout.pt', device='cpu')
# 导出为ONNX
dummy_input = torch.randn(1, 3, 1024, 1024)
torch.onnx.export(
model.model,
dummy_input,
"models/yolo_layout.onnx",
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {0: "batch"}, "output": {0: "batch"}},
opset_version=13
)
在代码中加载ONNX模型
import onnxruntime as ort
# 使用CPU执行
session = ort.InferenceSession("models/yolo_layout.onnx", providers=['CPUExecutionProvider'])
# 推理
outputs = session.run(None, {"input": input_tensor})
支持的Provider列表: - 'CPUExecutionProvider':通用CPU - 'AscendExecutionProvider':华为昇腾 - 'CambriconExecutionProvider':寒武纪MLU
4. WebUI服务启动与访问
4.1 启动脚本修改(start_webui.sh)
原始脚本可能硬编码了CUDA设备,需改为强制使用CPU:
#!/bin/bash
export CUDA_VISIBLE_DEVICES=-1 # 禁用GPU
export PYTORCH_ENABLE_MPS=0 # 禁用Apple MPS(非必要)
python webui/app.py --host 0.0.0.0 --port 7860 --device cpu
4.2 启动服务
# 赋予执行权限
chmod +x start_webui.sh
# 运行
./start_webui.sh
预期输出日志片段:
INFO:root:Starting WebUI on http://0.0.0.0:7860
INFO:layout_detector:Loaded ONNX model from models/yolo_layout.onnx
INFO:formula_recognizer:PaddleOCR initialized with CPU mode
4.3 浏览器访问
在客户端浏览器输入:
http://<国产服务器IP>:7860
即可进入Web操作界面,功能模块与原版一致,包含: - 布局检测 - 公式检测与识别 - OCR文字提取 - 表格解析
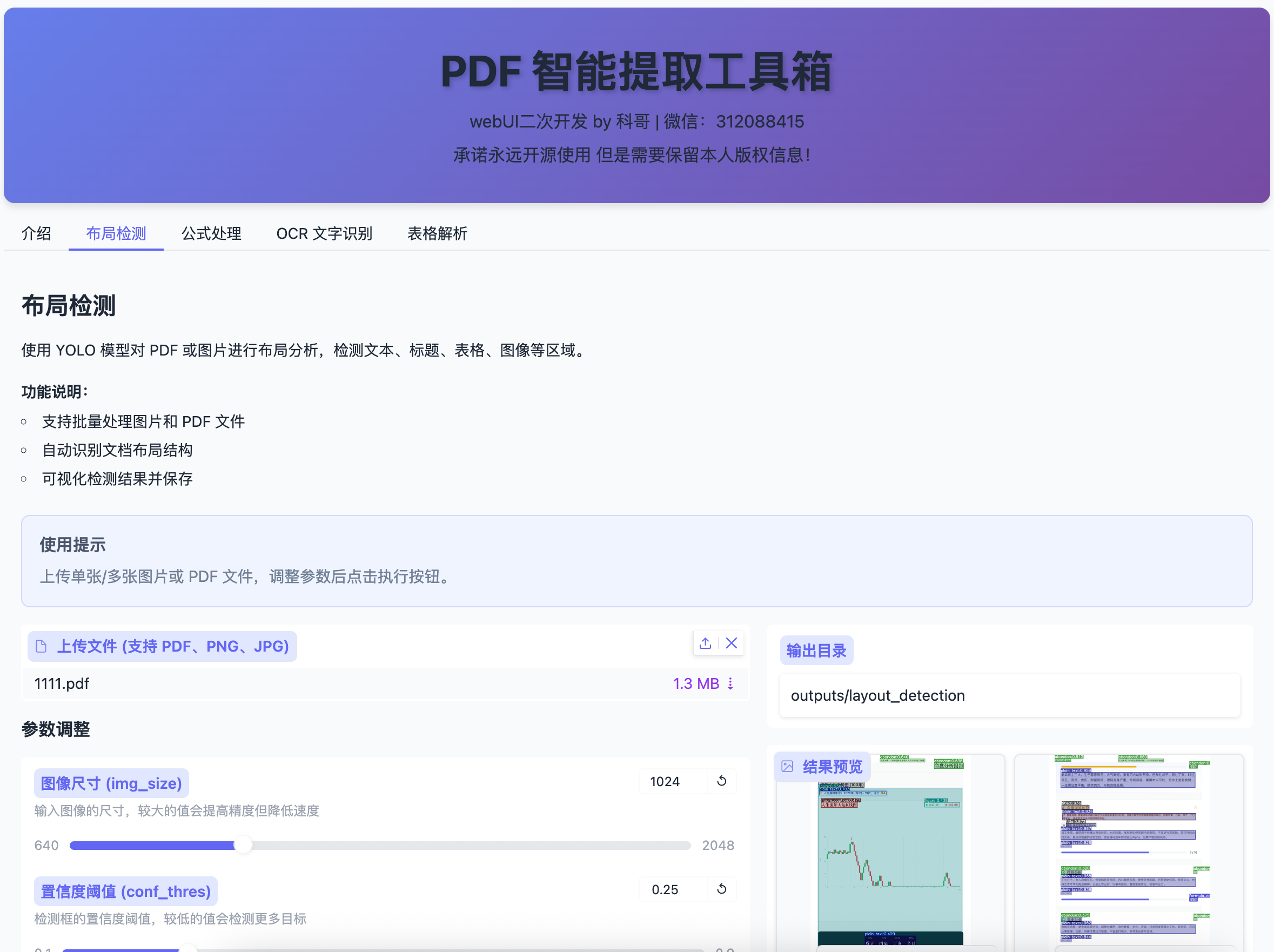
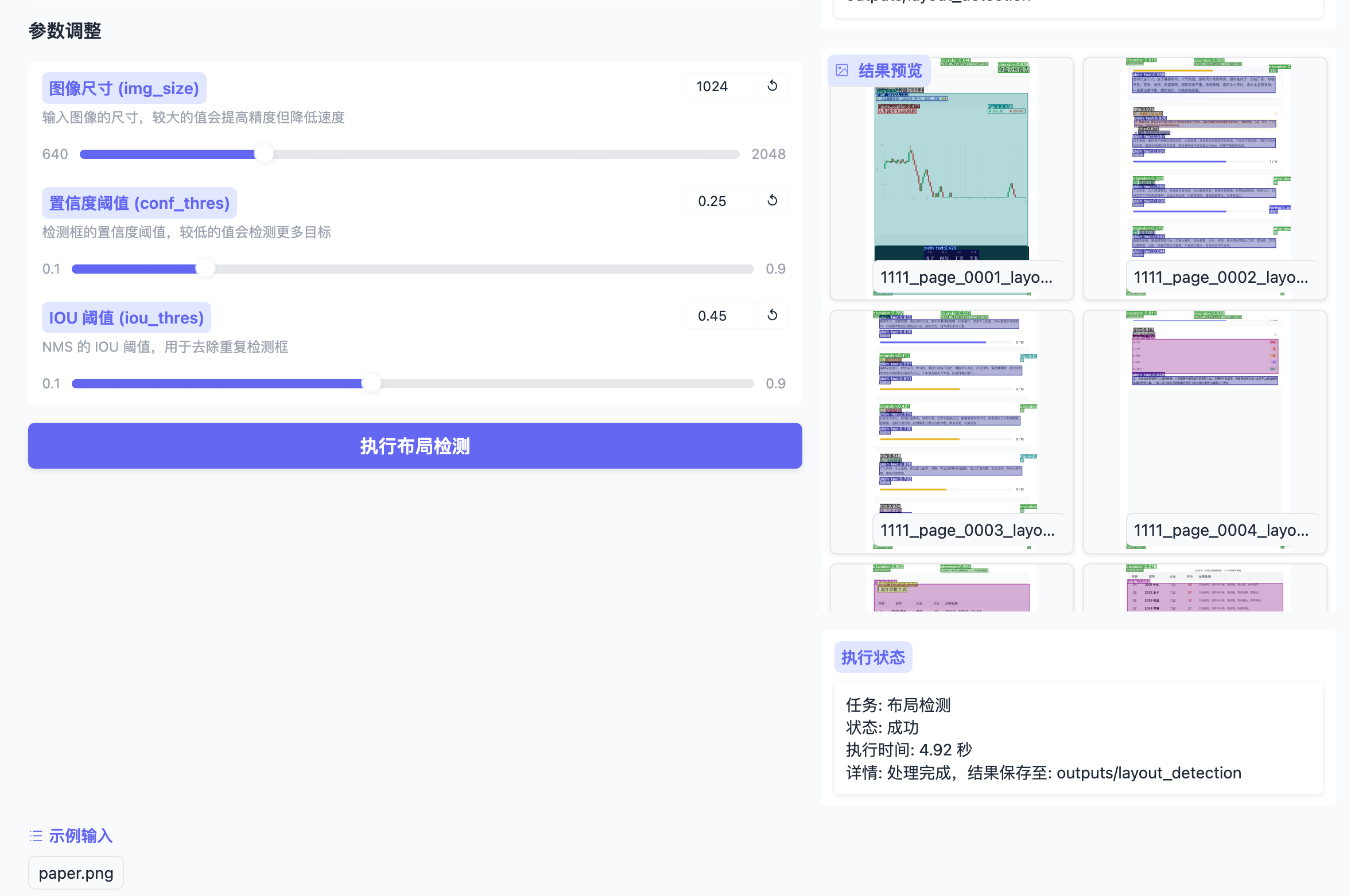
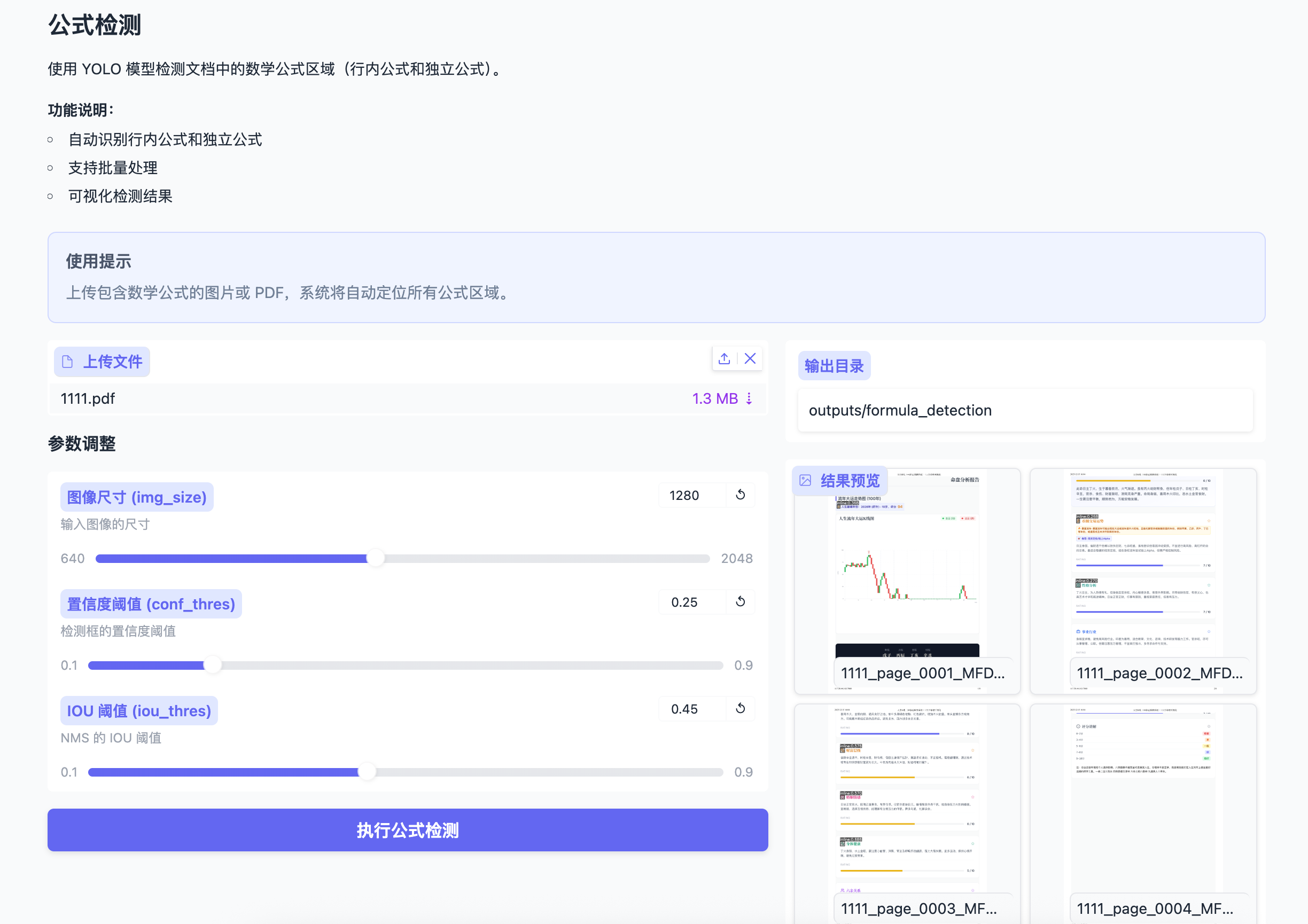
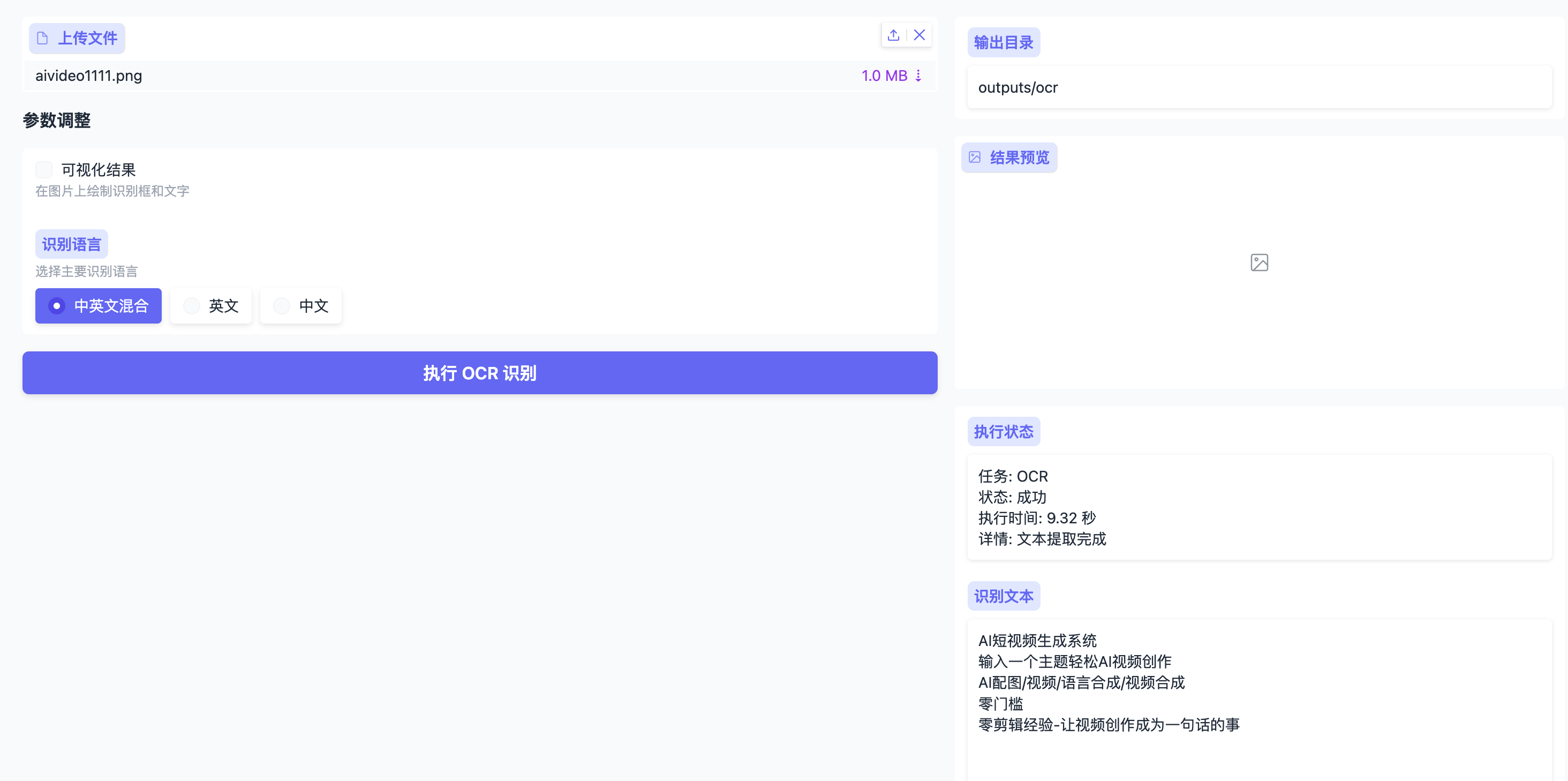
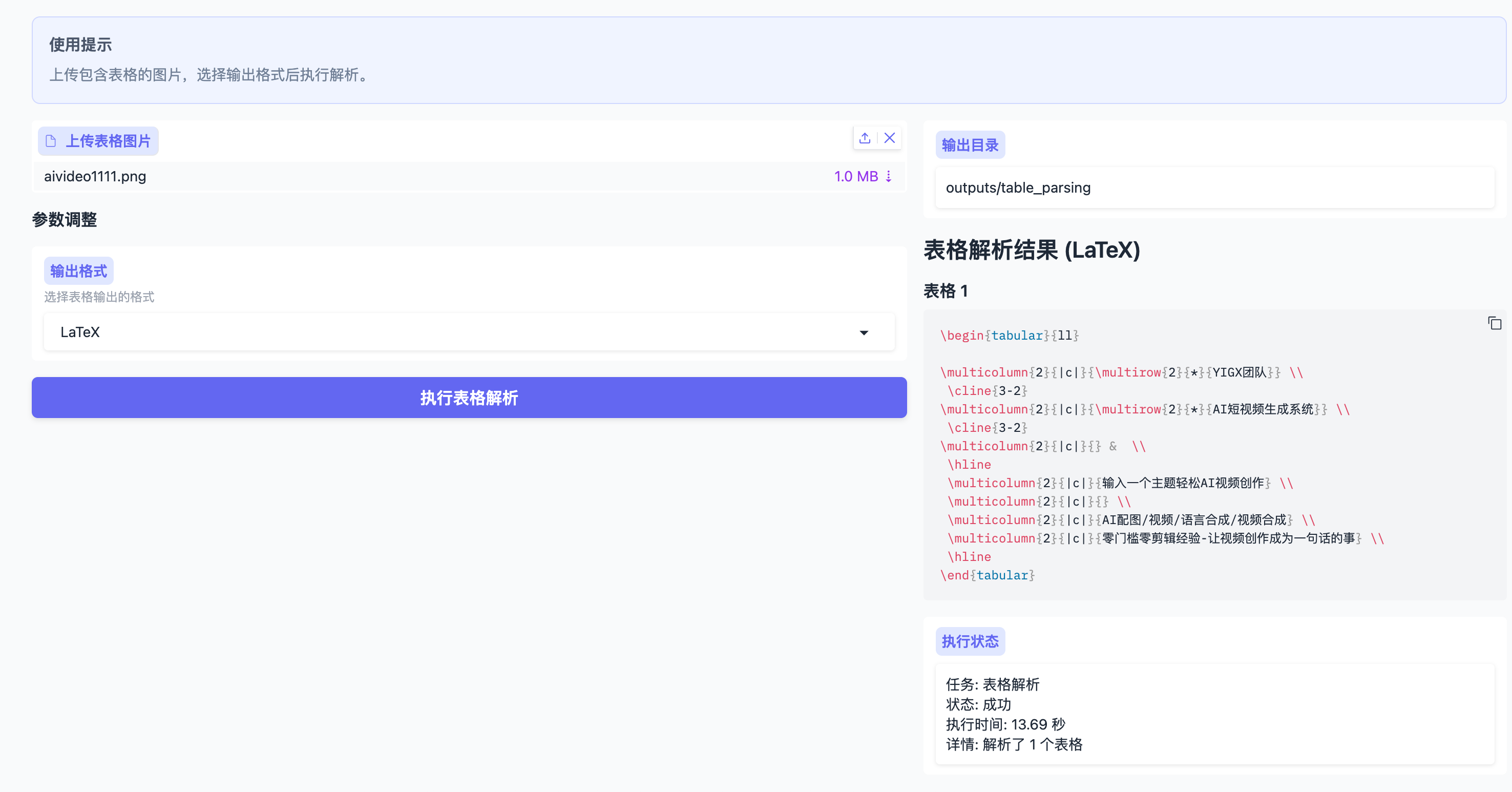
5. 性能优化与调参建议
5.1 国产平台性能瓶颈分析
| 瓶颈点 | 原因 | 解决方案 |
|---|---|---|
| CPU算力不足 | 国产CPU单核性能较弱 | 降低图像分辨率、启用批处理 |
| 内存带宽低 | DDR4频率偏低 | 减少并发请求数 |
| 缺乏专用AI加速 | 无Tensor Core类单元 | 使用量化模型(INT8) |
| 编译器优化不足 | GCC版本较低 | 使用LTO优化编译Python扩展 |
5.2 关键参数调优对照表
| 参数 | 推荐值(国产平台) | 说明 |
|---|---|---|
img_size |
640 ~ 800 | 降低至原默认值的60%,显著提速 |
conf_thres |
0.3 | 提高阈值减少误检,降低后续处理负担 |
batch_size |
1 ~ 2 | 避免内存溢出 |
device |
cpu 或 ascend | 显式指定推理设备 |
5.3 模型轻量化建议
- 使用知识蒸馏压缩原始YOLO模型
- 对PaddleOCR模型启用量化推理(INT8)
- 将LaTeX识别模型转换为TFLite或ONNX Tiny格式
- 预加载所有模型到内存,避免重复加载开销
6. 故障排查与常见问题
6.1 常见错误及解决方案
| 问题现象 | 可能原因 | 解决方法 |
|---|---|---|
启动时报No module named 'torch' |
pip未正确安装PyTorch CPU版 | 手动下载whl文件离线安装 |
| 图像无法显示 | OpenCV缺少GUI支持 | 改用opencv-python-headless |
| 处理卡死无响应 | 内存不足导致OOM | 监控top命令,限制并发数 |
| 表格解析失败 | HTML转Markdown库缺失 | 安装tablepyxl或lxml |
6.2 日志查看路径
所有运行日志输出至控制台,建议重定向保存:
nohup ./start_webui.sh > logs/pdf_extract.log 2>&1 &
关键日志关键词搜索: - "Layout detection completed" - "Formula recognized: $...$" - "OCR result: ..."
7. 总结
7.1 核心成果总结
本文详细介绍了 PDF-Extract-Kit 在国产化平台上的完整部署流程,涵盖:
- 在飞腾、鲲鹏、龙芯等国产CPU平台的基础环境搭建
- 从CUDA依赖转向ONNX Runtime多后端支持的技术路径
- 利用CPU或国产AI加速卡(如昇腾)实现模型推理
- WebUI服务的稳定运行与功能验证
实践表明,该工具箱在去除NVIDIA依赖后,仍可在统信UOS、银河麒麟等系统上正常运行,满足基本的PDF内容提取需求。
7.2 最佳实践建议
- 优先使用CPU推理:在无国产AI卡时,保持
device=cpu设置 - 降低输入分辨率:将
img_size设为640~800以提升响应速度 - 定期清理outputs目录:防止磁盘空间耗尽
- 内网部署镜像站:缓存PyPI和模型文件,提升安装效率
7.3 后续改进方向
- 开发专用的国产芯片插件(如CANN for Ascend)
- 提供预编译的国产化Docker/iSulad镜像
- 增加对WPS PDF文档结构的专项优化
- 支持离线授权验证机制,符合信创安全规范
💡 获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)