本地跑大模型?5000-3 万预算,显卡怎么选不踩坑?适配 Llama 3/GPT 开源模型,实测方案直接抄
本地跑大模型?5000-3 万预算,显卡怎么选不踩坑?适配 Llama 3/GPT 开源模型,实测方案直接抄
先搞懂:大模型硬件选型的 3 个核心指标
01
对个人用户来说,不用纠结企业级集群的复杂参数,抓住 3 个核心指标就能避坑:
-
显存:决定能跑多大模型。比如 70 亿参数模型(Llama 2-7B)需 10GB 以上显存,200 亿参数模型(gpt-oss-20B)至少要 16GB 显存,4bit 量化后可省一半显存。
-
算力:影响推理 / 训练速度。FP16 算力越高,跑模型越流畅,RTX 4090 的 82.6 TFLOPS 比 RTX 4060 Ti 快 3 倍以上。
-
能效比:关系电费和散热。昇腾 310B 单卡功耗仅 150W,比同性能 GPU 省 40% 电费,适合长期开机。
企业级硬件可作参考:像 Meta 用 8960 颗 TPU v5p 训万亿参数模型,核心逻辑和个人用户一致 —— 显存够大、算力匹配、成本可控,只是规模不同。

3 类芯片怎么选?个人用户看这张表就够了
02

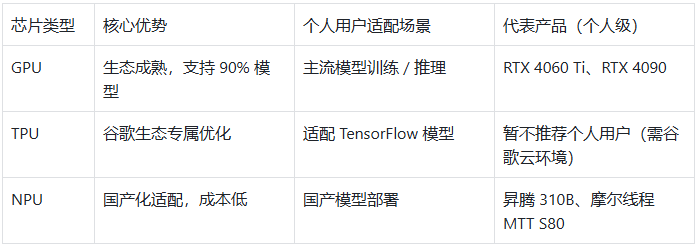
通俗解释:
-
GPU(如英伟达显卡):万能适配,新手首选,缺点是贵;
-
NPU(如昇腾):适合想支持国产、预算有限的用户,需适配特定模型;
-
TPU:个人用户几乎用不上,主要是谷歌自家生态专用。

5000-3 万预算,4 套方案实测推荐
03
入门尝鲜档(5000-8000 元)
核心配置:RTX 4060 Ti(16GB)+ Ryzen 5 7600X + 32GB 内存
能跑的模型:Llama 2-7B、Qwen3-7B(全量),Llama 3-13B(4bit 量化)
实测表现:
-
文本生成速度:200 tokens/s(约每秒 200 字)
-
功耗:满载 155W,每天开机 8 小时,月电费约 25 元
避坑点:别买 8GB 显存版,跑 7B 模型都会卡顿
- 进阶性价比档(10000-15000 元)
核心配置:RTX 4070 Ti(16GB)+ Ryzen 7 7800X + 64GB 内存
能跑的模型:Llama 3-13B(全量)、DeepSeek-16B(INT8 量化)、gpt-oss-20B(4bit 量化)
-
微调速度:50 tokens/s(微调 10 万条数据约 6 小时)
-
多任务能力:同时跑文本生成 + 代码补全,延迟 < 1 秒
- 高端发烧档(20000-30000 元)

核心配置:RTX 4090(24GB)+ Ryzen 9 9950X + 128GB 内存
能跑的模型:gpt-oss-20B(全量)、Qwen3-32B(INT8 量化)
-
推理速度:500 tokens/s(比 4070 Ti 快 2.5 倍)
-
多卡扩展:支持 2 卡并联,可跑 65B 参数模型
- 国产方案档(8000-12000 元)

核心配置:昇腾 310B + 鲲鹏 920 + 16GB 内存
能跑的模型:盘古 α-13B(量化版)、紫东太初 - 7B
-
国产化适配:完美运行银河麒麟系统,支持政务 / 涉密场景
-
成本优势:硬件成本比同性能 GPU 低 30%

实操指南:3 步搞定模型部署(附代码 + 量化对比)
04
- 环境搭建(以 RTX 显卡为例)
# 安装依赖pip install torch==2.3.0 transformers vllm# 验证CUDA是否可用python -c "import torch; print(torch.cuda.is_available())" # 输出True即成功
- 快速部署 Llama 3-13B
from vllm import LLM, SamplingParams# 加载模型(首次运行会自动下载)llm = LLM(model="meta-llama/Llama-3-13b-hf", tensor_parallel_size=1)sampling_params = SamplingParams(temperature=0.7, max_tokens=200)# 生成文本outputs = llm.generate(["写一段关于AI硬件的科普"], sampling_params)for output in outputs:print(output.outputs[0].text)
- 显存优化技巧( 量化对比表)
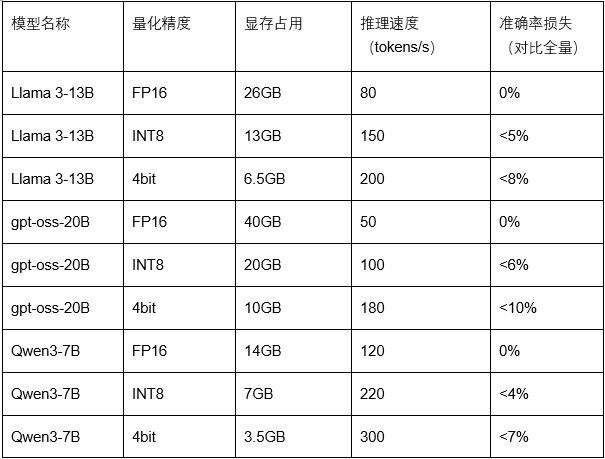
-
4bit 量化:用 bitsandbytes 库,显存占用减 75%
-
关闭冗余功能:禁用 gradient_checkpointing,推理速度提升 20%

未来趋势:个人用户该关注哪些新技术?
05
-
存算一体芯片:2026 年商用后,显存瓶颈将突破,16GB 显卡能跑千亿参数模型,功耗降 90%。
-
光计算:Lightmatter 等公司的光芯片,推理延迟可低至 1ms,适合实时对话场景
-
国产生态:华为 CANN 框架与 PyTorch 兼容性已达 85%,昇腾芯片明年将支持更多开源模型。

总结:个人选型 5 条铁律
06
-
显存优先:宁可选低算力大显存(如 16GB RTX 4060 Ti),不选高算力小显存(8GB RTX 4070)。
-
模型适配:跑 GPT 开源模型优先英伟达,跑国产模型可试昇腾,避免 “买了用不了”。
-
预算分配:显卡占总预算 60%(如 1 万元预算,显卡 6000 元),内存至少 32GB。
-
避坑指南:别买 “矿卡”(二手高负载显卡),优先选支持个人送保的品牌(如华硕、微星)。
-
长远考虑:预留升级空间,比如电源选 650W 以上,方便未来换更高配显卡。
一点建议:
新手从 7B 模型 + RTX 4060 Ti 起步,熟悉后再升级;国产方案适合有国产化需求的用户,生态正在快速完善。收藏这篇,下次买硬件不用再查资料!

想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)