昇思25天学习打卡营第22天|Pix2Pix实现图像转换
Pix2Pix利用条件生成对抗网络(cGAN),通过生成器和判别器的相互博弈,实现从输入图像到目标图像的转换。生成器根据输入图像生成对应的输出图像,而判别器则评估生成的图像的真实性。在训练过程中,生成器和判别器进行博弈,生成器不断尝试生成更加逼真的图像以迷惑判别器,而判别器则不断提高区分真实图像和生成图像的能力。判别器使用PatchGAN结构,将输入的图像分成小块进行判别,每个小块独立地被判断为真
应用背景
Pix2Pix是基于条件生成对抗网络(cGAN, Condition Generative Adversarial Networks)的一种深度学习图像转换模型,由Phillip Isola等人在2017年CVPR上提出。它能够实现多种图像转换任务,例如将语义标签转换为真实图片、将灰度图转换为彩色图、将航空图转换为地图、将白天场景转换为夜晚场景,以及将线稿图转换为实物图。Pix2Pix的通用性极高,通过相同的架构和目标函数,仅需不同的数据训练即可实现这些任务。
算法原理
Pix2Pix的核心是条件生成对抗网络(cGAN),其中包含一个生成器和一个判别器。生成器根据输入图像生成对应的输出图像,而判别器则评估生成的图像的真实性。在训练过程中,生成器和判别器进行博弈,生成器不断尝试生成更加逼真的图像以迷惑判别器,而判别器则不断提高区分真实图像和生成图像的能力。最终,生成器能够生成非常逼真的图像,而判别器难以辨别真假。
生成器采用U-Net结构,这是一种由卷积和降采样操作组成的压缩路径以及由卷积和上采样操作组成的扩展路径构成的全卷积网络。通过skip connections连接编码层和解码层,U-Net能够更好地保留图像细节。
判别器使用PatchGAN结构,将输入的图像分成小块进行判别,每个小块独立地被判断为真实或生成的图像,这种方式能够有效地提升生成图像的质量。
代码实现
1. 数据准备
首先,下载并处理用于训练的图像数据集。
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/dataset_pix2pix.tar"
download(url, "./dataset", kind="tar", replace=True)
2. 数据加载与展示
使用MindSpore的数据加载接口读取并展示数据。
from mindspore import dataset as ds
import matplotlib.pyplot as plt
dataset = ds.MindDataset("./dataset/dataset_pix2pix/train.mindrecord", columns_list=["input_images", "target_images"], shuffle=True)
data_iter = next(dataset.create_dict_iterator(output_numpy=True))
plt.figure(figsize=(10, 3), dpi=140)
for i, image in enumerate(data_iter['input_images'][:10], 1):
plt.subplot(3, 10, i)
plt.axis("off")
plt.imshow((image.transpose(1, 2, 0) + 1) / 2)
plt.show()
3. 生成器构建
定义U-Net生成器,并实现带有skip connections的结构。
import mindspore.nn as nn
import mindspore.ops as ops
class UNetSkipConnectionBlock(nn.Cell):
def __init__(self, outer_nc, inner_nc, in_planes=None, dropout=False,
submodule=None, outermost=False, innermost=False, alpha=0.2, norm_mode='batch'):
super(UNetSkipConnectionBlock, self).__init__()
down_norm = nn.BatchNorm2d(inner_nc)
up_norm = nn.BatchNorm2d(outer_nc)
use_bias = False
if norm_mode == 'instance':
down_norm = nn.BatchNorm2d(inner_nc, affine=False)
up_norm = nn.BatchNorm2d(outer_nc, affine=False)
use_bias = True
if in_planes is None:
in_planes = outer_nc
down_conv = nn.Conv2d(in_planes, inner_nc, kernel_size=4,
stride=2, padding=1, has_bias=use_bias, pad_mode='pad')
down_relu = nn.LeakyReLU(alpha)
up_relu = nn.ReLU()
if outermost:
up_conv = nn.Conv2dTranspose(inner_nc * 2, outer_nc,
kernel_size=4, stride=2,
padding=1, pad_mode='pad')
down = [down_conv]
up = [up_relu, up_conv, nn.Tanh()]
model = down + [submodule] + up
elif innermost:
up_conv = nn.Conv2dTranspose(inner_nc, outer_nc,
kernel_size=4, stride=2,
padding=1, has_bias=use_bias, pad_mode='pad')
down = [down_relu, down_conv]
up = [up_relu, up_conv, up_norm]
model = down + up
else:
up_conv = nn.Conv2dTranspose(inner_nc * 2, outer_nc,
kernel_size=4, stride=2,
padding=1, has_bias=use_bias, pad_mode='pad')
down = [down_relu, down_conv, down_norm]
up = [up_relu, up_conv, up_norm]
model = down + [submodule] + up
if dropout:
model.append(nn.Dropout(p=0.5))
self.model = nn.SequentialCell(model)
self.skip_connections = not outermost
def construct(self, x):
out = self.model(x)
if self.skip_connections:
out = ops.concat((out, x), axis=1)
return out
4. 判别器构建
定义PatchGAN判别器,用于判断生成图像的真实性。
import mindspore.nn as nn
class ConvNormRelu(nn.Cell):
def __init__(self, in_planes, out_planes, kernel_size=4, stride=2, alpha=0.2, norm_mode='batch', pad_mode='CONSTANT', use_relu=True, padding=None):
super(ConvNormRelu, self).__init__()
norm = nn.BatchNorm2d(out_planes)
if norm_mode == 'instance':
norm = nn.BatchNorm2d(out_planes, affine=False)
has_bias = (norm_mode == 'instance')
if not padding:
padding = (kernel_size - 1) // 2
if pad_mode == 'CONSTANT':
conv = nn.Conv2d(in_planes, out_planes, kernel_size, stride, pad_mode='pad',
has_bias=has_bias, padding=padding)
layers = [conv, norm]
else:
paddings = ((0, 0), (0, 0), (padding, padding), (padding, padding))
pad = nn.Pad(paddings=paddings, mode=pad_mode)
conv = nn.Conv2d(in_planes, out_planes, kernel_size, stride, pad_mode='pad', has_bias=has_bias)
layers = [pad, conv, norm]
if use_relu:
relu = nn.ReLU()
if alpha > 0:
relu = nn.LeakyReLU(alpha)
layers.append(relu)
self.features = nn.SequentialCell(layers)
def construct(self, x):
output = self.features(x)
return output
class Discriminator(nn.Cell):
def __init__(self, in_planes=3, ndf=64, n_layers=3, alpha=0.2, norm_mode='batch'):
super(Discriminator, self).__init__()
kernel_size = 4
layers = [
nn.Conv2d(in_planes, ndf, kernel_size, 2, pad_mode='pad', padding=1),
nn.LeakyReLU(alpha)
]
nf_mult = ndf
for i in range(1, n_layers):
nf_mult_prev = nf_mult
nf_mult = min(2 ** i, 8) * ndf
layers.append(ConvNormRelu(nf_mult_prev, nf_mult, kernel_size, 2, alpha, norm_mode, padding=1))
nf_mult_prev = nf_mult
nf_mult = min(2 ** n_layers, 8) * ndf
layers.append(ConvNormRelu(nf_mult_prev, nf_mult, kernel_size, 1, alpha, norm_mode, padding=1))
layers.append(nn.Conv2d(nf_mult, 1, kernel_size, 1, pad_mode='pad', padding=1))
self.features = nn.SequentialCell(layers)
def construct(self, x, y):
x_y = ops.concat((x, y), axis=1)
output = self.features(x_y)
return output
5. 初始化模型
实例化Pix2Pix生成器和判别器。
import mindspore.nn as nn
from mindspore.common import initializer as init
g_in_planes = 3
g_out_planes = 3
g_ngf = 64
g_layers = 8
d_in_planes = 6
d_ndf = 64
d_layers = 3
alpha = 0.2
init_gain = 0.02
init_type = 'normal'
net_generator = UNetGenerator(in_planes=g_in_planes, out_planes=g_out_planes, ngf=g_ngf, n_layers=g_layers)
for _, cell in net_generator.cells_and_names():
if isinstance(cell, (nn.Conv2d, nn.Conv2dTranspose)):
if init_type == 'normal':
cell.weight.set_data(init.initializer(init.Normal(init_gain), cell.weight.shape))
elif init_type == 'xavier':
cell.weight.set_data(init.initializer(init.XavierUniform(init_gain), cell.weight.shape))
elif init_type == 'constant':
cell.weight.set_data(init.initializer(0.001, cell.weight.shape))
else:
raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
elif isinstance(cell, nn.BatchNorm2d):
cell.gamma.set_data(init.initializer('ones', cell.gamma.shape))
cell.beta.set_data(init.initializer('zeros', cell.beta.shape))
net_discriminator = Discriminator(in_planes=d_in_planes, ndf=d_ndf, alpha=alpha, n_layers=d_layers)
for _, cell in net_discriminator.cells_and_names():
if isinstance(cell, (nn.Conv2d, nn.Conv2dTranspose)):
if init_type == 'normal':
cell.weight.set_data(init.initializer(init.Normal(init_gain), cell.weight.shape))
elif init_type == 'xavier':
cell.weight.set_data(init.initializer(init.XavierUniform(init_gain), cell.weight.shape))
elif init_type == 'constant':
cell.weight.set_data(init.initializer(0.001, cell.weight.shape))
else:
raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
elif isinstance(cell, nn.BatchNorm2d):
cell.gamma.set_data(init.initializer('ones', cell.gamma.shape))
cell.beta.set_data(init.initializer('zeros', cell.beta.shape))
class Pix2Pix(nn.Cell):
"""Pix2Pix模型网络"""
def __init__(self, discriminator, generator):
super(Pix2Pix, self).__init__(auto_prefix=True)
self.net_discriminator = discriminator
self.net_generator = generator
def construct(self, reala):
fakeb = self.net_generator(reala)
return fakeb
6. 训练
训练分为两个主要部分:训练判别器和训练生成器。
import numpy as np
import os
import datetime
from mindspore import value_and_grad, Tensor
epoch_num = 3
ckpt_dir = "results/ckpt"
dataset_size = 400
val_pic_size = 256
lr = 0.0002
n_epochs = 100
n_epochs_decay = 100
def get_lr():
lrs = [lr] * dataset_size * n_epochs
lr_epoch = 0
for epoch in range(n_epochs_decay):
lr_epoch = lr * (n_epochs_decay - epoch) / n_epochs_decay
lrs += [lr_epoch] * dataset_size
lrs += [lr_epoch] * dataset_size * (epoch_num - n_epochs_decay - n_epochs)
return Tensor(np.array(lrs).astype(np.float32))
dataset = ds.MindDataset("./dataset/dataset_pix2pix/train.mindrecord", columns_list=["input_images", "target_images"], shuffle=True, num_parallel_workers=1)
steps_per_epoch = dataset.get_dataset_size()
loss_f = nn.BCEWithLogitsLoss()
l1_loss = nn.L1Loss()
def forword_dis(reala, realb):
lambda_dis = 0.5
fakeb = net_generator(reala)
pred0 = net_discriminator(reala, fakeb)
pred1 = net_discriminator(reala, realb)
loss_d = loss_f(pred1, ops.ones_like(pred1)) + loss_f(pred0, ops.zeros_like(pred0))
loss_dis = loss_d * lambda_dis
return loss_dis
def forword_gan(reala, realb):
lambda_gan = 0.5
lambda_l1 = 100
fakeb = net_generator(reala)
pred0 = net_discriminator(reala, fakeb)
loss_1 = loss_f(pred0, ops.ones_like(pred0))
loss_2 = l1_loss(fakeb, realb)
loss_gan = loss_1 * lambda_gan + loss_2 * lambda_l1
return loss_gan
d_opt = nn.Adam(net_discriminator.trainable_params(), learning_rate=get_lr(), beta1=0.5, beta2=0.999, loss_scale=1)
g_opt = nn.Adam(net_generator.trainable_params(), learning_rate=get_lr(), beta1=0.5, beta2=0.999, loss_scale=1)
grad_d = value_and_grad(forword_dis, None, net_discriminator.trainable_params())
grad_g = value_and_grad(forword_gan, None, net_generator.trainable_params())
def train_step(reala, realb):
loss_dis, d_grads = grad_d(reala, realb)
loss_gan, g_grads = grad_g(reala, realb)
d_opt(d_grads)
g_opt(g_grads)
return loss_dis, loss_gan
if not os.path.isdir(ckpt_dir):
os.makedirs(ckpt_dir)
g_losses = []
d_losses = []
data_loader = dataset.create_dict_iterator(output_numpy=True, num_epochs=epoch_num)
for epoch in range(epoch_num):
for i, data in enumerate(data_loader):
start_time = datetime.datetime.now()
input_image = Tensor(data["input_images"])
target_image = Tensor(data["target_images"])
dis_loss, gen_loss = train_step(input_image, target_image)
end_time = datetime.datetime.now()
delta = (end_time - start_time).microseconds
if i % 2 == 0:
print("ms per step:{:.2f} epoch:{}/{} step:{}/{} Dloss:{:.4f} Gloss:{:.4f} ".format((delta / 1000), (epoch + 1), (epoch_num), i, steps_per_epoch, float(dis_loss), float(gen_loss)))
d_losses.append(dis_loss.asnumpy())
g_losses.append(gen_loss.asnumpy())
if (epoch + 1) == epoch_num:
mindspore.save_checkpoint(net_generator, ckpt_dir + "Generator.ckpt")
7. 推理
训练完成后,加载模型并进行推理。
from mindspore import load_checkpoint, load_param_into_net
param_g = load_checkpoint(ckpt_dir + "Generator.ckpt")
load_param_into_net(net_generator, param_g)
dataset = ds.MindDataset("./dataset/dataset_pix2pix/train.mindrecord", columns_list=["input_images", "target_images"], shuffle=True)
data_iter = next(dataset.create_dict_iterator())
predict_show = net_generator(data_iter["input_images"])
plt.figure(figsize=(10, 3), dpi=140)
for i in range(10):
plt.subplot(2, 10, i + 1)
plt.imshow((data_iter["input_images"][i].asnumpy().transpose(1, 2, 0) + 1) / 2)
plt.axis("off")
plt.subplots_adjust(wspace=0.05, hspace=0.02)
plt.subplot(2, 10, i + 11)
plt.imshow((predict_show[i].asnumpy().transpose(1, 2, 0) + 1) / 2)
plt.axis("off")
plt.subplots_adjust(wspace=0.05, hspace=0.02)
plt.show()
结果
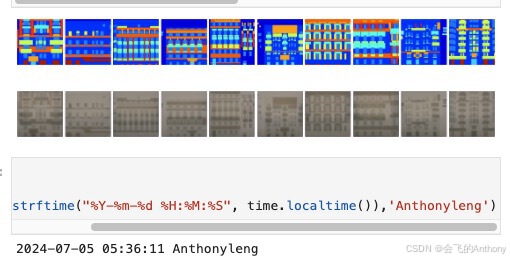
学习心得:通过这次学习和实现Pix2Pix模型,我对生成对抗网络(GAN)及其在图像转换任务中的应用有了更深入的理解。Pix2Pix利用条件生成对抗网络(cGAN),通过生成器和判别器的相互博弈,实现从输入图像到目标图像的转换。U-Net结构通过skip connections保留了图像的细节信息,使生成的图像更为逼真。PatchGAN判别器通过将图像分成小块进行判别,提升了图像生成的质量和效率。
参考文献:Phillip Isola,Jun-Yan Zhu,Tinghui Zhou,Alexei A. Efros. Image-to-Image Translation with Conditional Adversarial Networks.[J]. CoRR,2016,abs/1611.07004.
如果你觉得这篇博文对你有帮助,请点赞、收藏、关注我,并且可以打赏支持我!
欢迎关注我的后续博文,我将分享更多关于深度学习、计算机视觉和自然语言处理的精彩内容。
谢谢大家的支持!

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 15
15 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)