CANN:神经网络异构计算架构深度解
本文深入解析神经网络异构计算架构CANN,探讨其如何高效连接AI框架与底层芯片。该架构采用分层设计,包含应用框架层、API层、运行时调度层、算子编译层和驱动固件层,实现软硬件协同优化。其核心优势在于性能优化与开发效率提升,提供强大的图引擎、计算图优化和自定义算子开发能力,支持主流AI框架无缝对接。文章还给出实操建议,包括版本匹配、模型转换优化和资源监控等。CANN通过分层解耦设计降低了AI开发门槛
CANN:神经网络异构计算架构深度解析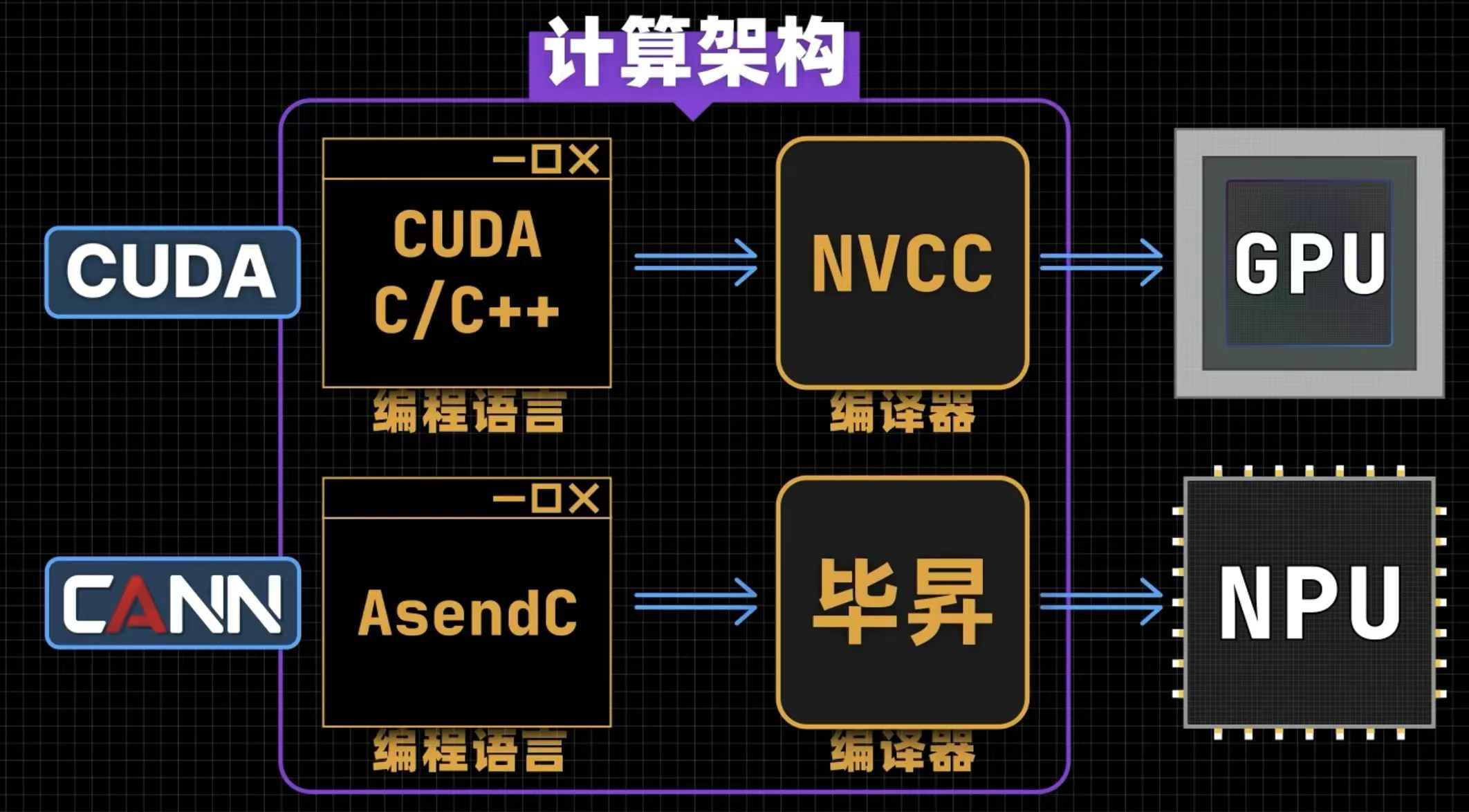
在人工智能技术的迅猛发展浪潮中,如何高效地将算法模型转化为实际生产力,成为了业界关注的焦点。这不仅依赖于强大的硬件算力,更需要一个能够充分释放这种算力的软件栈。本文将深入探讨一种旨在连接上层AI框架与底层AI芯片的神经网络异构计算架构,它通过软硬件协同优化,为AI计算提供了高效、稳定的加速能力。
架构解析:分层设计,协同工作
该计算架构采用了一种典型的分层模型,各层各司其职,共同构建了一个从应用到底层的完整软件栈。其核心设计理念是“一套接口,全系列适配”,旨在屏蔽硬件差异,让开发者能够专注于业务逻辑和算法创新。
- 应用与框架层:这是开发者最直接接触的层面,支持主流的AI框架,如TensorFlow、PyTorch等。通过框架适配层,这些上层框架可以无缝地调用底层的计算资源,无需关心底层硬件的具体实现。
- API层:提供统一的编程接口,是连接上层应用与底层运行时的桥梁。它封装了硬件细节,为开发者提供了简洁、一致的调用方式。
- 运行时与调度层:负责任务的调度、内存管理以及流的同步等核心功能。它确保计算任务能够高效、有序地在硬件上执行。
- 算子库与编译层:包含大量经过高度优化的算子,是性能加速的关键。同时,编译层能够将计算图转换为底层硬件可执行的指令,并进行算子融合、内存复用等深度优化。
- 驱动与固件层:直接与硬件交互,负责设备管理、底层驱动控制等,为上层软件提供稳定、高效的硬件访问能力。
核心特性:性能优化与开发效率并重
该架构的核心价值在于其强大的性能优化能力和对开发效率的提升。它不仅仅是一个简单的设备切换接口,而是一套完整的异构计算解决方案。
强大的图引擎与计算图优化
内置的图引擎能够对计算图进行深度优化,显著提升计算效率。例如,通过算子融合技术,可以将多个连续的算子合并为一个,减少内存访问开销和内核启动次数;通过内存复用技术,可以最大化地利用有限的硬件内存资源。
int min_distance(int dist[], int visited[], int nodes) {
int min = INT_MAX, min_index;
for (int v = 0; v < nodes; v++) {
if (!visited[v] && dist[v] <= min) {
min = dist[v];
min_index = v;
}
}
return min_index;
}
void dijkstra(Graph* graph, int start) {
int dist[MAX_NODES];
int visited[MAX_NODES];
for (int i = 0; i < graph->node_count; i++) {
dist[i] = INT_MAX;
visited[i] = 0;
}
dist[start] = 0;
for (int count = 0; count < graph->node_count - 1; count++) {
int u = min_distance(dist, visited, graph->node_count);
visited[u] = 1;
Edge* edge = graph->edges[u];
while (edge != NULL) {
int v = edge->dest;
if (!visited[v] && dist[u] != INT_MAX &&
dist[u] + edge->weight < dist[v]) {
dist[v] = dist[u] + edge->weight;
}
edge = edge->next;
}
}
printf("Vertex\tDistance from %d\n", start);
for (int i = 0; i < graph->node_count; i++) {
printf("%d\t\t%d\n", i, dist[i]);
}
}
自定义算子开发:释放硬件潜能
尽管提供了丰富的内置算子库,但为了应对特定的业务需求或实现极致的性能优化,开发者可能需要开发自定义算子。该架构为此提供了完备的开发链路,其中核心是其原生支持的C/C++扩展编程语言。通过这种编程语言,开发者可以高效地实现自定义的创新算法,同时利用其提供的多层接口抽象和自动并行计算等关键技术,极大地提高了开发效率。
多框架无缝对接与模型加速
支持与主流AI框架的无缝集成,无论是动态图还是静态图,都能通过其转换工具自动转换为底层硬件可执行的模型格式。这使得开发者几乎可以无感地从其他硬件平台迁移到本架构上,实现模型的零成本迁移与高性能执行。
实操指南:从环境部署到任务加速
对于希望在实际项目中应用该架构的开发者来说,遵循一些关键的实践建议至关重要。
版本匹配与环境准备
在部署之前,必须严格遵循驱动、工具包与AI框架之间的版本匹配关系。不兼容的版本组合可能导致部署失败或运行时错误。建议在开始之前,查阅官方文档中的兼容性列表,确保所有组件的版本协调一致。
模型转换与优化
在将训练好的模型转换为底层硬件可执行的格式时,可以利用转换工具提供的多种优化参数。例如,可以根据任务需求选择不同的精度模式,或开启特定的算子融合选项,以进一步提升推理性能。
资源监控与问题排查
在大规模任务运行时,实时监控硬件状态至关重要。可以通过提供的监控工具(如npu-smi)来查看设备的使用情况,避免资源过载。如果遇到部署或运行问题,应首先查看默认路径下的日志文件,并结合开发者社区的问题库来快速定位和解决问题。
结语:开启AI开发新纪元
作为异构计算架构的核心代表,该计算架构通过其分层解耦的设计、强大的图优化引擎以及对自定义算子开发的全面支持,为AI任务提供了高效、稳定的加速能力。它降低了AI基础设施的使用门槛,无论是进行技术验证的开发者,还是搭建生产级AI系统的企业,都能从中获益。随着其生态的持续完善和版本的迭代,它有望成为更多AI项目的首选软件支撑方案,推动AI技术的普及与落地。
我写了一篇AIGC跟ops-nn的仓库有关,那我在本篇文章内需体现\ncann组织链接:https://atomgit.com/cann\nops-nn 仓库链接:https://atomgit.com/cann/ops-nn

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)