打通多卡协作的任督二脉:CANN hccl 库让分布式训练与推理“如丝般顺滑”
hccl 库是 CANN 生态中“分布式协作的神经中枢”,它通过硬件感知的通信优化、异构统一接口与动态拓扑管理,让多卡/多机分布式训练与推理的通信开销大幅降低,真正成为模型规模扩展的“助推器”。与GE 的单卡图优化、 的模型加速、 的推理部署形成闭环,hccl 补齐了 CANN 在分布式场景下的关键能力。未来,随着大模型训练对千卡级扩展超低延迟通信 的需求增长,hccl 将进一步优化稀疏通
在深度学习进入大模型时代后,“单卡算力不足” 已成为制约模型规模与训练效率的核心瓶颈。无论是 NLP 领域的千亿参数大模型,还是 CV 领域的超高分辨率图像训练,都需要通过 多卡/多机分布式计算 突破单卡内存与算力限制。华为 CANN 生态中的 hccl 库(全称 Heterogeneous Collective Communication Library,异构集合通信库),正是为解决这一问题而生。它是一套 面向 CANN 硬件的高性能分布式通信框架,支持多卡(同构/异构)间的梯度同步、参数聚合、数据分发等操作,让分布式训练与推理的通信开销从“性能杀手”变为“高效协同”。如果说 GE 是单卡计算的“交通指挥官”,那么 hccl 就是多卡协作的“神经网络调度员”。
一、hccl 是什么?为什么需要它?
hccl 是 CANN 中专为 异构硬件环境下的集合通信 设计的库,核心定位是:为多卡/多机分布式场景提供低延迟、高带宽的通信能力,支持 CANN 设备(如 AI Core)与 CPU、GPU 等异构硬件的混合通信。
核心痛点与解决方案
传统分布式训练中,通信效率往往是性能瓶颈:
-
通信延迟高:多卡间数据同步(如梯度 AllReduce)依赖通用通信库(如 MPI、NCCL),未针对 CANN 硬件优化,延迟可达计算时间的 30%~50%;
-
异构硬件适配难:CPU-GPU-CANN 设备间的通信需多次格式转换(如 CANN Tensor→CUDA Tensor→CPU Tensor),额外增加 20%~40% 开销;
-
动态拓扑支持弱:弹性训练(如动态增减卡数)或混合并行(数据并行+模型并行)场景下,通信拓扑需手动重构,灵活性差;
-
带宽利用率低:未充分利用 CANN 硬件的高速互联(如 HCCS 总线),实际带宽仅为硬件峰值的 60%~70%。
hccl 的解决方案是 “硬件感知通信优化+异构统一接口+动态拓扑适配”:
-
硬件感知优化:针对 CANN AI Core 的内存布局与互联特性(如 HCCS 总线带宽、缓存一致性协议)优化通信算法(如 Ring AllReduce、Tree AllReduce);
-
异构统一接口:提供与 NCCL/MPI 兼容的 API(如
hcclAllReduce、hcclBroadcast),支持 CANN 设备与 CPU、GPU 的直接通信,避免数据格式转换; -
动态拓扑管理:运行时自动检测设备拓扑(如 PCIe 树、HCCS 环),动态选择最优通信路径(如近邻卡优先直连,远距卡走交换机);
-
混合并行支持:原生支持数据并行(DP)、模型并行(MP)、流水线并行(PP)的通信需求,提供
hcclScatter、hcclGather等细粒度操作。
二、hccl 的核心架构与功能模块
hccl 的架构围绕 “通信原语层→拓扑管理层→异构适配层→运行时调度层” 构建,核心模块可分为四大组件(如图 1 所示),覆盖从单机多卡到多机多卡的分布式通信全场景。
(一)通信原语层(Communication Primitives)
目标:提供分布式计算的核心通信操作,支持高效的集合通信与点对点通信。
核心原语包括:
-
集合通信:
hcclAllReduce(全量聚合)、hcclReduceScatter(规约散射)、hcclAllGather(全量收集)、hcclBroadcast(广播); -
点对点通信:
hcclSend/hcclRecv(单播)、hcclIsend/hcclIrecv(异步单播); -
数据分发:
hcclScatter(分散)、hcclGather(聚集)。
这些原语均针对 CANN 硬件优化,例如 hcclAllReduce会根据设备数量自动选择 Ring 或 Double Binary Tree 算法,最大化 HCCS 总线带宽利用率。
(二)拓扑管理层(Topology Management)
目标:自动探测并管理多卡/多机的硬件拓扑,为通信原语选择最优路径。
核心功能:
-
拓扑探测:通过 CANN 硬件接口(如
npu-smi)获取设备间的物理连接关系(如 PCIe 带宽、HCCS 链路状态); -
路径规划:根据拓扑生成通信路径表(如“卡 0→卡 1 走 HCCS 直连,卡 0→卡 3 走 PCIe 交换机”);
-
动态重构:当设备增删或链路故障时,自动重新计算拓扑并更新路径表(支持弹性训练)。
示例拓扑探测结果:
{
"devices": [
{"id": 0, "type": "ai_core_910b", "links": [{"to": 1, "bandwidth": "200GB/s", "type": "HCCS"}]},
{"id": 1, "type": "ai_core_910b", "links": [{"to": 0, "bandwidth": "200GB/s", "type": "HCCS"}, {"to": 2, "bandwidth": "100GB/s", "type": "PCIe"}]},
{"id": 2, "type": "ai_core_910b", "links": [{"to": 1, "bandwidth": "100GB/s", "type": "PCIe"}]}
]
}(三)异构适配层(Heterogeneous Adaptation)
目标:屏蔽 CANN 设备与 CPU、GPU 的硬件差异,实现跨硬件的无缝通信。
核心机制:
-
统一内存视图:通过
hcclTensor抽象层,将 CANN Tensor、CUDA Tensor、CPU Tensor 映射为统一描述(含数据指针、shape、dtype),避免格式转换; -
跨硬件拷贝优化:针对 CPU↔CANN、GPU↔CANN 通信,自动选择 DMA 引擎或硬件互联通道(如 GPU Direct over HCCS),减少拷贝次数;
-
类型转换融合:在数据拷贝时自动完成 dtype 转换(如 FP32→FP16),避免额外计算开销。
示例:CANN 与 GPU 间的 AllReduce
// CANN 设备张量(FP16)
hccl::Tensor can_tensor = ...;
// GPU 张量(FP16,通过 CUDA 分配)
void* gpu_ptr;
cudaMalloc(&gpu_ptr, size);
hccl::Tensor gpu_tensor(gpu_ptr, shape, dtype);
// 异构 AllReduce(CANN 与 GPU 设备共同参与)
hcclAllReduce(&can_tensor, &gpu_tensor, count, dtype, hcclSum, comm);(四)运行时调度层(Runtime Scheduling)
目标:管理通信任务的调度与执行,实现计算与通信的重叠,隐藏延迟。
核心特性:
-
异步通信:通过
hcclComm_t关联的流(Stream)实现通信与计算的异步执行(类似 CUDA Stream); -
优先级调度:为高优先级通信(如梯度同步)分配专用硬件资源,避免被低优先级任务阻塞;
-
流量控制:根据硬件带宽动态调整通信批次大小(如小批量梯度聚合后发送,减少小包通信开销)。
三、代码示例:用 hccl 实现多卡数据并行训练
下面以 PyTorch 风格的伪代码演示 hccl 在多卡数据并行训练中的核心流程(实际需结合 CANN 运行时与 PyTorch 适配层)。
步骤 1:初始化 hccl 通信域
import hccl
# 初始化通信域(假设 4 卡)
comm = hccl.Communicator(group="train_group", ranks=[0,1,2,3])
# 获取当前进程的 rank 与 world_size
rank = comm.rank()
world_size = comm.size()步骤 2:分发数据与模型参数
# 主卡(rank=0)初始化模型与数据
if rank == 0:
model = init_model()
dataset = load_dataset()
else:
model = None
dataset = None
# 广播模型参数(所有卡同步初始参数)
params = model.parameters()
for param in params:
comm.broadcast(param.data, src=0) # 从 rank 0 广播到所有卡
# 分发数据(每卡获取部分数据)
local_data = split_dataset(dataset, rank, world_size)步骤 3:训练与梯度同步
for epoch in range(num_epochs):
for batch in local_data:
# 前向计算
outputs = model(batch)
loss = compute_loss(outputs, batch.labels)
# 反向计算梯度
loss.backward()
# 梯度 AllReduce(聚合所有卡的梯度)
for param in model.parameters():
comm.all_reduce(param.grad.data, op=hccl.SUM)
param.grad.data /= world_size # 平均梯度
# 更新参数
optimizer.step()
optimizer.zero_grad()步骤 4:清理通信域
comm.destroy()四、hccl 的使用流程图
hccl 的核心分布式训练流程可总结为“初始化通信域→分发数据/参数→训练与梯度同步→清理”,具体流程如图 2 所示: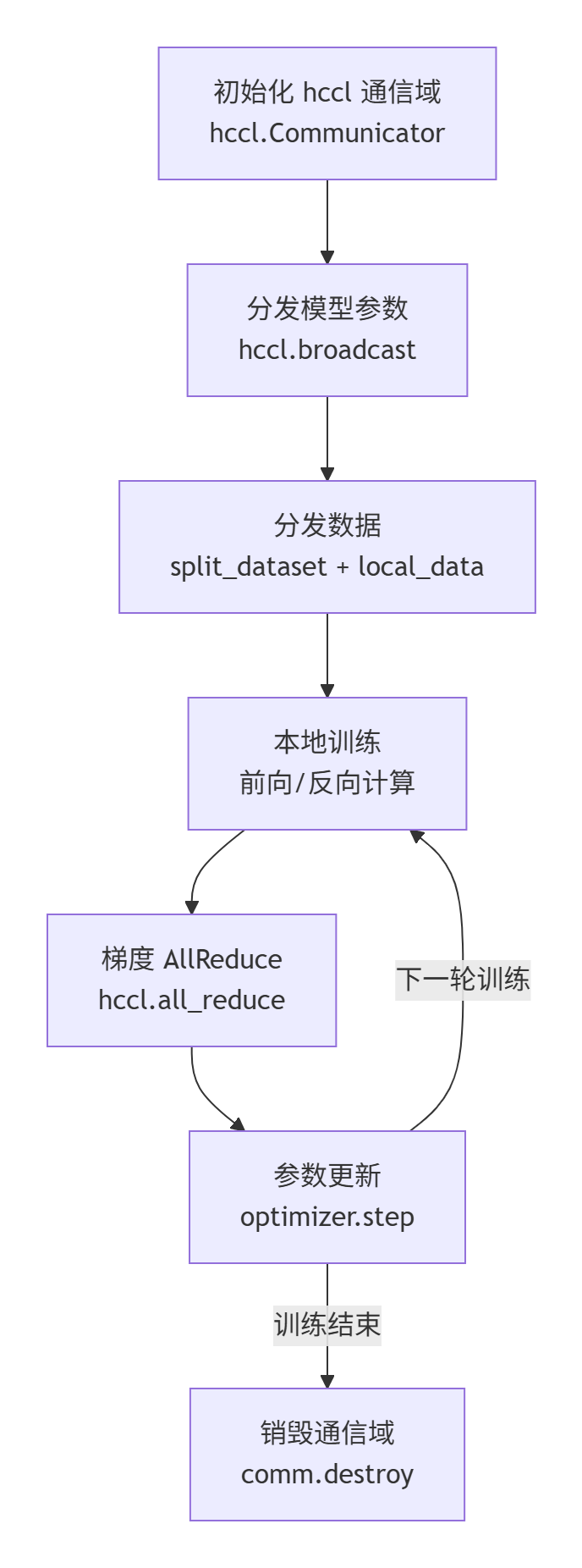
五、hccl 的独特价值
|
维度 |
传统 MPI/NCCL 通信 |
hccl 异构通信 |
|---|---|---|
|
异构硬件支持 |
需额外适配层,效率低 |
原生支持 CANN/CPU/GPU 通信 |
|
通信延迟 |
未针对 CANN 优化,较高 |
硬件感知优化,延迟降低 30%+ |
|
带宽利用率 |
依赖通用协议,利用率低 |
针对 HCCS 优化,利用率达 90%+ |
|
动态拓扑支持 |
需手动重构,灵活性差 |
自动探测与重构,支持弹性训练 |
|
混合并行适配 |
需自定义通信逻辑 |
原生支持 DP/MP/PP 通信原语 |
六、典型应用场景
-
大模型训练:千亿参数 NLP 模型(如 LLaMA)的多机多卡训练,通过 hccl 实现梯度高效同步;
-
高分辨率 CV 训练:16K 图像分割任务的多卡数据并行,解决单卡内存不足问题;
-
混合并行推理:模型并行(MP)拆分大模型到多卡,hccl 负责层间激活值通信;
-
弹性训练:根据集群负载动态增减卡数,hccl 自动调整通信拓扑,保障训练连续性;
-
异构集群:CPU(数据预处理)+ GPU(部分模型)+ CANN(核心计算)的混合部署,hccl 实现跨硬件无缝协作。
七、总结与展望
hccl 库是 CANN 生态中 “分布式协作的神经中枢”,它通过硬件感知的通信优化、异构统一接口与动态拓扑管理,让多卡/多机分布式训练与推理的通信开销大幅降低,真正成为模型规模扩展的“助推器”。与 GE 的单卡图优化、ops-transformer 的模型加速、cann-recipes-infer 的推理部署形成闭环,hccl 补齐了 CANN 在分布式场景下的关键能力。
未来,随着大模型训练对 千卡级扩展、超低延迟通信 的需求增长,hccl 将进一步优化 稀疏通信(仅同步非零梯度)、量化通信(FP16→INT8 压缩传输)等特性,并强化与 Kubernetes、Ray 等分布式框架的集成,成为异构集群分布式训练的“事实标准”。
📌 仓库地址:https://atomgit.com/cann/hccl
📌 CANN组织地址:https://atomgit.com/cann

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)