专注视觉加速:CANN ops-cv 库让图像处理与CV模型“飞”起来
ops-cv 库是 CANN 生态中“视觉计算的性能引擎”,它通过 CV 场景感知的算子优化与硬件亲和实现,让图像处理与视觉模型推理的瓶颈从“预处理/后处理”转移到“核心计算”,充分发挥 CANN AI Core 的算力优势。与 的文本与多模态加速、pyasc 的设备控制、 的部署方案形成互补,ops-cv 完善了 CANN 在 CV 领域的全栈加速能力。未来,随着多模态模型(如 CLIP、
在计算机视觉(Computer Vision,CV)领域,从图像分类、目标检测、分割到超分辨率、图像生成,各类模型都离不开大量专用的视觉算子:Resize、Crop、Rotate、ColorConvert、GaussianBlur、NMS(非极大值抑制)、ROIAlign、GridSample 等。这些算子在通用数学库(如 ops-math)中往往只有基础实现,缺乏对 CV 场景特定数据布局、硬件特性与性能模式的深度优化。
华为 CANN 生态中的 ops-cv 库(全称 CANN Computer Vision Operators,计算机视觉算子库),正是为弥补这一空缺而生。它是一套 面向 CANN 硬件的 CV 专用高性能算子集合,覆盖从图像预处理、几何变换、滤波增强到检测后处理的全链路视觉计算需求,让 ResNet、YOLO、Mask R-CNN、ViT 等 CV 模型在 CANN 上获得开箱即用的极致性能。如果说 ops-math 是“通用数学工具箱”,那么 ops-cv 就是专为视觉任务打磨的“专业影像车间”。
一、ops-cv 是什么?为什么需要它?
ops-cv 是 CANN 中专为 计算机视觉任务优化 的算子库,核心定位是:提供针对图像数据特性(如 HWC/NCHW 布局、像素连续性、批量并行性)和 CANN 硬件算力(AI Core 向量单元、DMA 引擎)深度优化的 CV 算子,减少数据搬运与格式转换开销,提升视觉模型端到端性能。
核心痛点与解决方案
在 CV 任务中,通用算子或手写实现常遇到以下问题:
-
数据布局不匹配:图像通常以 HWC(Height-Width-Channel)存储,而 AI Core 更擅长 NCHW(Batch-Channel-Height-Width),频繁转换增加内存与计算开销;
-
预处理瓶颈:Resize、Normalize、Pad 等预处理在 CPU 上执行会成为推理时延的主要来源(尤其在高帧率视频流场景);
-
后处理开销大:目标检测中的 NMS、ROIAlign 等算子涉及大量小规模计算与条件分支,通用实现难以并行;
-
硬件特性利用不足:CV 算子的内存访问模式(如连续行扫描)未针对 CANN 的 DMA 与缓存策略优化,带宽利用率低。
ops-cv 的解决方案是 “CV 场景感知优化+硬件亲和实现+预处理/后处理融合”:
-
原生布局支持:算子直接支持 HWC/NCHW/NHWC 等多种图像布局,避免不必要的数据转置;
-
预处理加速:将 Resize、Crop、ColorConvert、Normalize 等融合为单一 kernel,利用 AI Core 向量单元批量处理像素;
-
后处理优化:NMS、ROIAlign 等算子采用并行排序与向量化比较,减少分支与同步开销;
-
视频流友好:支持多帧批量预处理与异步 DMA,适配高帧率视频推理场景。
二、ops-cv 的核心架构与功能模块
ops-cv 的架构围绕 “图像预处理→几何变换→滤波与增强→检测后处理→视频流优化” 构建,核心模块可分为五大组件(如图 1 所示),覆盖 CV 模型从输入到输出的全链路计算。
(一)图像预处理模块(Image Preprocessing)
目标:高效完成模型推理前的图像准备工作,减少 CPU 干预与数据拷贝。
核心算子:
-
Resize:支持双线性/最近邻插值,针对目标尺寸与硬件 tile 大小优化内存访问(如 32×32 块读取);
-
Crop/Pad:支持任意矩形裁剪与对称/常数填充,融合边界检查与填充值写入,减少分支;
-
ColorConvert:RGB↔BGR、RGB↔NV12/YUV 等格式转换,利用向量指令并行处理多个像素;
-
Normalize/Standardize:融合减均值、除标准差操作,支持 per-channel 参数,单指令完成批量像素归一化。
优化亮点:
-
预处理算子可直接在 AI Core 上与模型推理异步并行(通过 DMA 双缓冲);
-
支持动态输入分辨率(如视频流中不同尺寸的帧),运行时自动调整 tile 大小。
(二)几何变换模块(Geometric Transformations)
目标:高效实现图像的旋转、翻转、仿射变换、透视变换等空间操作。
核心算子:
-
Rotate:支持任意角度旋转(通过坐标映射+双线性插值),利用 AI Core 的矩阵运算单元加速坐标变换;
-
Flip/HorizontalVertical:水平/垂直翻转,直接内存地址重映射或向量反转指令,零计算开销;
-
AffineTransform:仿射矩阵变换(平移、缩放、剪切),融合坐标计算与插值,减少内存往返;
-
WarpPerspective:透视变换,适用于视角校正与图像拼接。
优化亮点:
-
坐标计算与插值在同一 kernel 内完成,避免中间结果写回全局内存;
-
对常见角度(90°、180°、270°)提供专用路径,直接内存重排,速度提升 5~10 倍。
(三)滤波与增强模块(Filtering & Enhancement)
目标:提供 CV 常用的图像质量提升与特征提取算子,优化卷积类操作的硬件利用率。
核心算子:
-
GaussianBlur:分离式高斯模糊(先水平后垂直卷积),利用 AI Core 的向量乘加指令并行计算卷积核;
-
MedianFilter:中值滤波,采用滑动窗口+双缓冲策略,避免重复排序;
-
Sobel/Sharpen:边缘检测与锐化,融合 Sobel 核与增益计算,单指令完成梯度幅值计算;
-
HistogramEqualization:直方图均衡化,并行统计与累积分布计算,适配不同位深(8bit/16bit)。
优化亮点:
-
卷积类滤波器支持任意奇数尺寸核,自动分解为可向量化的子任务;
-
针对图像边界提供多种模式(零填充、镜像、复制),硬件友好实现。
(四)检测后处理模块(Detection Post-processing)
目标:加速目标检测与实例分割模型的后处理步骤,减少推理尾时延。
核心算子:
-
NMS(Non-Maximum Suppression):并行排序+向量化 IoU 计算,支持多类别独立 NMS 与 soft-NMS;
-
ROIAlign/RoIPool:高精度区域特征抽取,避免量化误差,支持双线性插值;
-
DecodeBoxes:将模型输出的偏移量解码为实际 bounding box 坐标,融合 sigmoid/softmax 与坐标变换;
-
NonMaxSuppressionV8:针对 YOLOv8 等新模型的定制 NMS,支持多尺度特征图融合。
优化亮点:
-
NMS 采用 warp-level 并行排序,减少线程同步开销;
-
ROIAlign 的坐标映射与插值融合为单次内存访问,降低带宽压力。
(五)视频流优化模块(Video Stream Optimization)
目标:针对高帧率视频推理场景,提供批量预处理与流水线并行能力。
核心特性:
-
BatchFramePreprocess:将多帧图像的 Resize+Crop+Normalize 融合为批量 kernel,提升 DMA 与计算并行度;
-
AsyncPipeline:预处理(CPU/DMA)→推理(AI Core)→后处理(NMS)三级流水线,隐藏各环节延迟;
-
DynamicResolutionAdapt:运行时检测视频帧尺寸变化,自动切换最优 tile 与插值参数。
三、代码示例:用 ops-cv 实现端到端图像预处理+推理
下面以 ResNet50 图像分类为例,演示 ops-cv 在 Python 中完成预处理并与模型推理无缝衔接的过程(结合 pyasc 控制设备)。
import pyasc
import ops_cv as cv_ops
import numpy as np
# 初始化设备
dev = pyasc.device.init(0)
stream = dev.create_stream()
# 加载 ResNet50 OM 模型
model = pyasc.runtime.load_model('resnet50.om', device_id=0)
# 读取原始图像(HWC, uint8)
raw_image = cv_ops.imread('cat.jpg') # shape: (480, 640, 3), dtype: uint8
# 预处理流水线(融合为单一 kernel)
preprocessed = cv_ops.preprocess(
raw_image,
resize=(224, 224),
crop=None,
normalize={'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]},
layout='NCHW', # 输出 NCHW 布局,直接送模型
dtype='float16',
stream=stream # 异步执行
)
# 推理
output = model.infer([preprocessed], stream=stream)
stream.synchronize()
# 后处理(取 Top-1 类别)
pred_class = cv_ops.topk(output, k=1)
print(f"Predicted class: {pred_class}")亮点:
-
cv_ops.preprocess在 AI Core 上一次性完成 Resize+Normalize+Layout 转换,避免 CPU 参与; -
预处理与推理在同一 stream 中异步执行,隐藏预处理时延。
四、ops-cv 的使用流程图
ops-cv 的核心推理流程可总结为“图像输入→预处理→模型推理→后处理→结果输出”,具体流程如图 2 所示: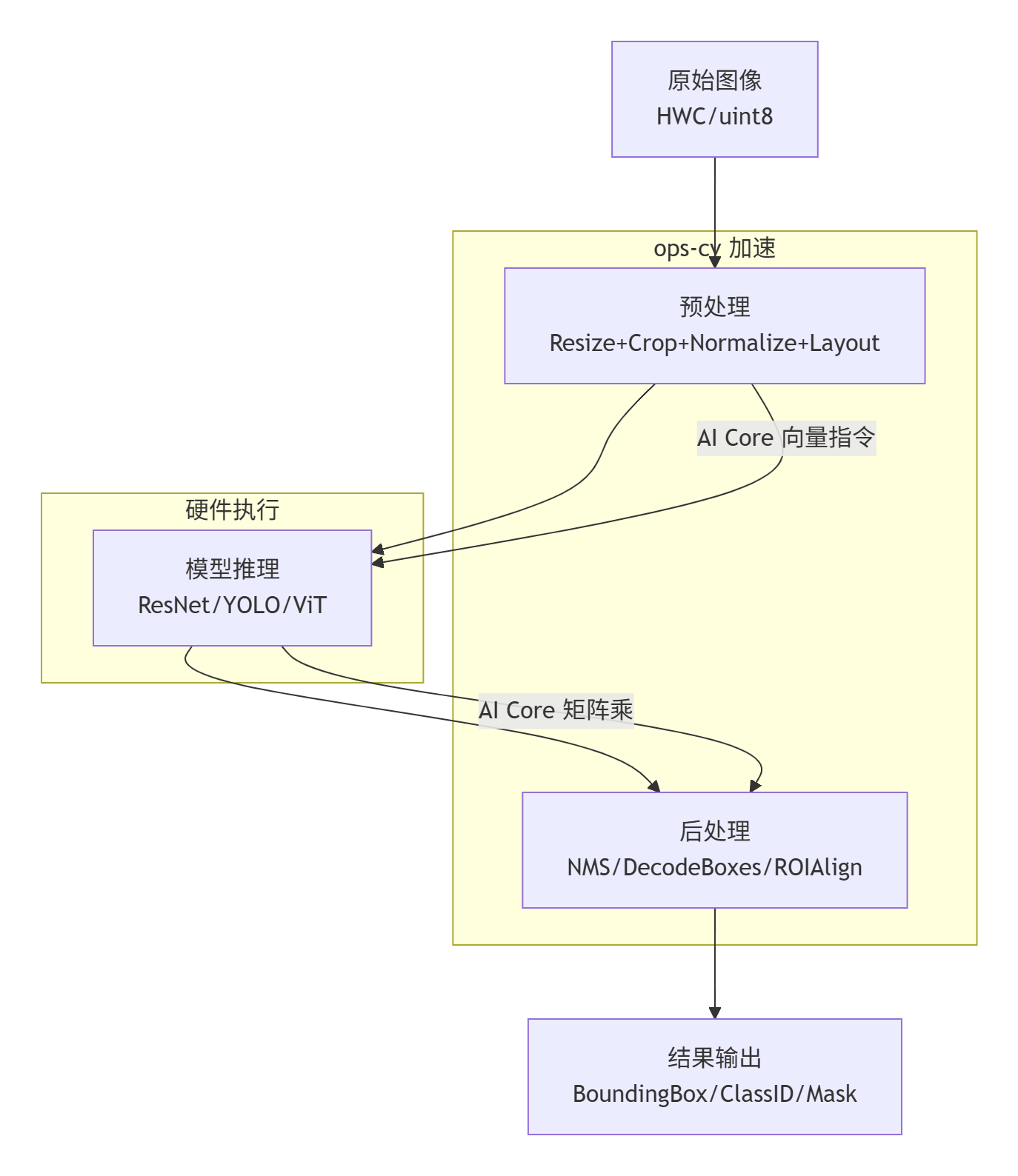
五、ops-cv 的独特价值
|
维度 |
通用算子/CPU 预处理 |
ops-cv 专用优化 |
|---|---|---|
|
预处理时延 |
高(CPU 串行) |
低(AI Core 并行,提速 5~20x) |
|
数据布局适配 |
需多次转置 |
原生支持 HWC/NCHW/NHWC |
|
后处理效率 |
NMS 等串行执行慢 |
并行排序+向量化,提速 3~10x |
|
视频流支持 |
单帧处理,帧率低 |
批量+异步流水线,高帧率适配 |
|
硬件利用率 |
带宽/算力利用率低 |
针对 AI Core 优化,利用率 90%+ |
六、典型应用场景
-
图像分类推理:ResNet、EfficientNet 等模型的端到端加速,预处理+推理一体化;
-
目标检测:YOLOv5/v8、Faster R-CNN 的检测前处理与 NMS 加速,提升 FPS;
-
视频分析:高帧率视频流的实时预处理与推理(如安防监控、自动驾驶感知);
-
图像增强:超分辨率、去噪、色彩校正等前处理,提升模型输入质量;
-
嵌入式视觉:Atlas 200I DK 等边缘设备的轻量化 CV 推理,降低功耗与时延。
七、总结与展望
ops-cv 库是 CANN 生态中 “视觉计算的性能引擎”,它通过 CV 场景感知的算子优化与硬件亲和实现,让图像处理与视觉模型推理的瓶颈从“预处理/后处理”转移到“核心计算”,充分发挥 CANN AI Core 的算力优势。与 ops-transformer 的文本与多模态加速、pyasc 的设备控制、cann-recipes-infer 的部署方案形成互补,ops-cv 完善了 CANN 在 CV 领域的全栈加速能力。
未来,随着多模态模型(如 CLIP、BLIP)与实时 3D 视觉(NeRF、SLAM)的兴起,ops-cv 将进一步扩展对 3D 点云处理、多光谱图像、动态分辨率推理 等算子的支持,并强化与视频编解码引擎的集成,成为 CANN 视觉应用的“标配加速库”。
📌 仓库地址:https://atomgit.com/cann/ops-cv
📌 CANN组织地址:https://atomgit.com/cann

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)