MindSpore学习实践——基于GPT2实现文本摘要
昇思打卡营第四期——基于MindSpore的GPT2实文本摘要
MindSpore学习实践——基于MindSpore的GPT2实现文本摘要
前言
GPT-2由GPT-1的结构改造(其实改造不大,还是transformer的decoder结构)而来并且将将参数量从1亿增加到15亿(和现在比还算小的)。其也是用于文本生成预测,根据输入的句子转换成向量然后再预测各个词的出现频率,最后使用argmax将其转换成argmax。该模型基于大量文本数据进行无监督训练,具备了生成高质量自然语言的能力,适合多种下游任务,包括文本生成、对话系统和文本分类等。
本节课我学到了什么?
- zero shot learning
本次课程讲到了zero-shot learning(零样本学习),本人不太了解,故查了一些资料学习。所谓zero-shot learning,就是根本没有提供任何示例,模型根据给定的指令理解任务。这使模型能够识别、分类或理解在训练过程中未见过的概念或类别。相比之下对于一些罕见或未知类别的样本,传统监督学习方法可能难以处理。也是因此,GPT-2可以在没有特定训练数据的情况下生成高质量的文本,即可以理解和生成从未见过的主题或风格的文本。
- task conditioning
语言模型能够使用相同的无监督模型学习多个任务。在传统的语言模型训练中,训练目标通常被表述为:
P(output∣input) P(\text{output}|\text{input}) P(output∣input)
然而,GPT-2的目标是使用相同的无监督模型学习多个任务。为了实现这一点,学习目标需要被修改为:
P(output∣input,task) P(\text{output}|\text{input}, \text{task}) P(output∣input,task)
其中模型被期望在相同的输入下由于任务的不同产生不同的输出。
task conditioning在GPT-2中的实现可以通过在输入序列的开始添加指示任务类型的标记、将任务信息编码为嵌入向量并注入在模型的某些层中(*可以帮助模型根据不同的任务调整其输出)、在训练过程中让模型学习到不同任务之间的共同点和差异,方便其区分并以及根据任务类型动态调整模型内部的信息流动,使得模型的不同部分专注于不同的任务等方式。
- GPT-2模型的结构方面
GPT-2最高有48层,同样使用了使用字节对(BPE)编码构建字典,字典的大小为50257,滑动窗口大小为1-24,batch_size为512,Layer Normalization移动到了每一块的输入部分,在每个self-attention之后额外添加了一个Layer Normalization。(层规范化(Layer Normalization)是一种在深度学习中常用的规范化技术,它的主要目的是帮助神经网络更快、更稳定地收敛)
代码实训
- 环境配置
#安装mindnlp 0.4.0套件
!pip install mindnlp==0.4.0
!pip uninstall soundfile -y
!pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.3.1/MindSpore/unified/aarch64/mindspore-2.3.1-cp39-cp39-linux_aarch64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
- 数据集的加载与预处理
from mindnlp.utils import http_get
from mindspore.dataset import TextFileDataset
import json
import numpy as np
from mindnlp.transformers import BertTokenizer
# download dataset
url = 'https://download.mindspore.cn/toolkits/mindnlp/dataset/text_generation/nlpcc2017/train_with_summ.txt'
path = http_get(url, './')
# load dataset
dataset = TextFileDataset(str(path), shuffle=False)
dataset.get_dataset_size()
# split into training and testing dataset
mini_dataset, _ = dataset.split([0.001, 0.999], randomize=False)
train_dataset, test_dataset = mini_dataset.split([0.9, 0.1], randomize=False)
# preprocess dataset
def process_dataset(dataset, tokenizer, batch_size=4, max_seq_len=1024, shuffle=False):
def read_map(text):
data = json.loads(text.tobytes())
return np.array(data['article']), np.array(data['summarization'])
def merge_and_pad(article, summary):
# tokenization
# pad to max_seq_length, only truncate the article
tokenized = tokenizer(text=article, text_pair=summary,
padding='max_length', truncation='only_first', max_length=max_seq_len)
return tokenized['input_ids'], tokenized['input_ids']
dataset = dataset.map(read_map, 'text', ['article', 'summary'])
# change column names to input_ids and labels for the following training
dataset = dataset.map(merge_and_pad, ['article', 'summary'], ['input_ids', 'labels'])
dataset = dataset.batch(batch_size)
if shuffle:
dataset = dataset.shuffle(batch_size)
return dataset
# GPT2无中文tokenizer,改用BertTokenizer替代。
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
len(tokenizer)
train_dataset = process_dataset(train_dataset, tokenizer, batch_size=1)
next(train_dataset.create_tuple_iterator())
- 模型构建:构建GPT2ForSummarization模型
from mindnlp.core.nn import functional as F
from mindnlp.transformers import GPT2LMHeadModel
class GPT2ForSummarization(GPT2LMHeadModel):
def forward(
self,
input_ids = None,
attention_mask = None,
labels = None,
):
outputs = super().forward(input_ids=input_ids, attention_mask=attention_mask)
shift_logits = outputs.logits[..., :-1, :]
shift_labels = labels[..., 1:]
# Flatten the tokens
loss = F.cross_entropy(shift_logits.view(-1, shift_logits.shape[-1]), shift_labels.view(-1), ignore_index=tokenizer.pad_token_id)
return (loss,)
- 模型训练
from mindspore import nn
from mindnlp.transformers import GPT2Config, GPT2LMHeadModel
from mindnlp.engine import Trainer
from mindnlp.engine import TrainingArguments
num_epochs = 1
warmup_steps = 100
learning_rate = 1.5e-4
max_grad_norm = 1.0
num_training_steps = num_epochs * train_dataset.get_dataset_size()
config = GPT2Config(vocab_size=len(tokenizer))
model = GPT2ForSummarization(config)
# 记录模型参数数量
print('number of model parameters: {}'.format(model.num_parameters()))
training_args = TrainingArguments(
output_dir="gpt2_summarization",
save_steps=train_dataset.get_dataset_size(),
save_total_limit=3,
logging_steps=1000,
max_steps=num_training_steps,
learning_rate=learning_rate,
max_grad_norm=max_grad_norm,
warmup_steps=warmup_steps
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
)
trainer.train()
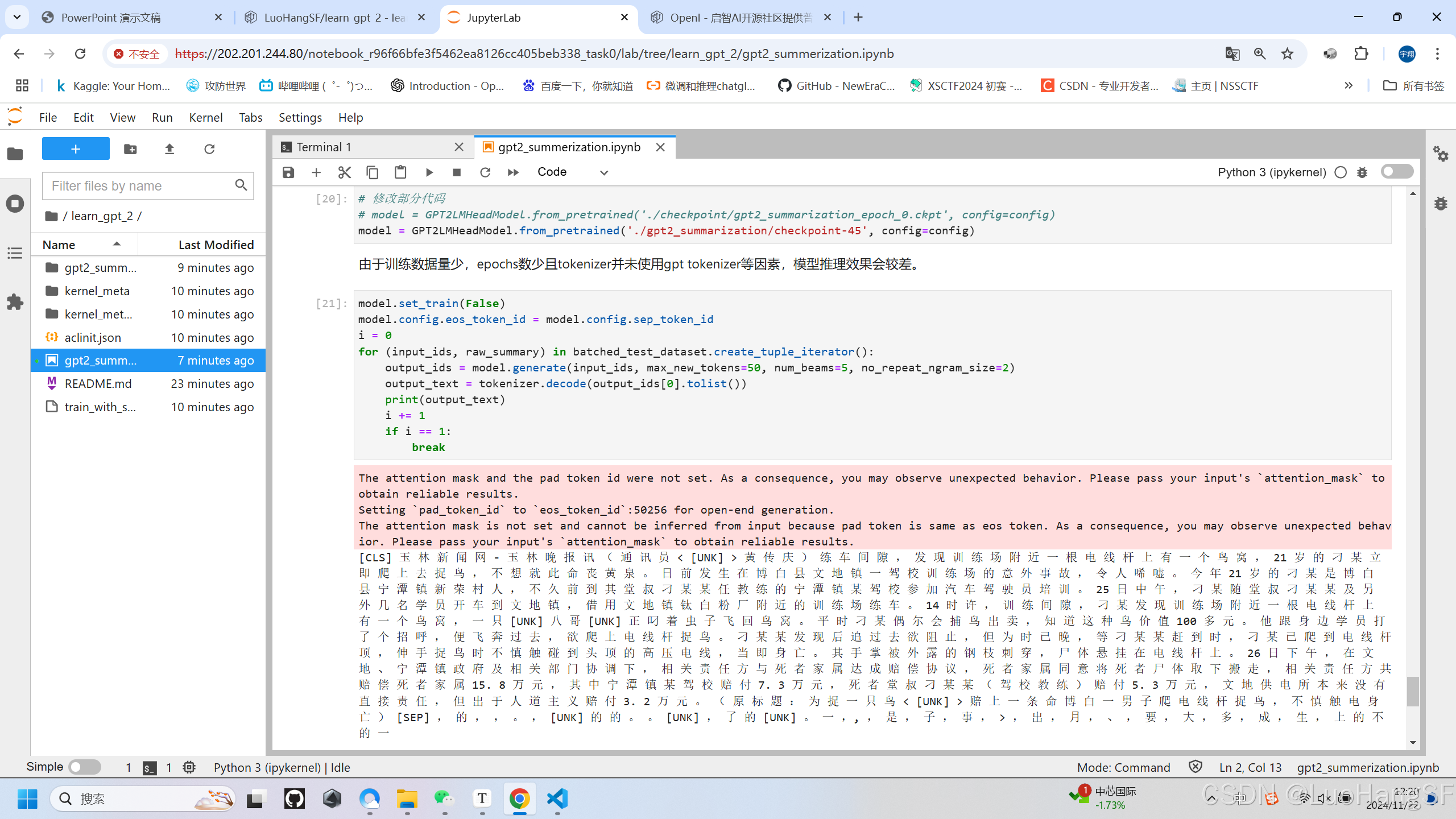
- 模型推理
def process_test_dataset(dataset, tokenizer, batch_size=1, max_seq_len=1024, max_summary_len=100):
def read_map(text):
data = json.loads(text.tobytes())
return np.array(data['article']), np.array(data['summarization'])
def pad(article):
tokenized = tokenizer(text=article, truncation=True, max_length=max_seq_len-max_summary_len)
return tokenized['input_ids']
dataset = dataset.map(read_map, 'text', ['article', 'summary'])
dataset = dataset.map(pad, 'article', ['input_ids'])
dataset = dataset.batch(batch_size)
return dataset
batched_test_dataset = process_test_dataset(test_dataset, tokenizer, batch_size=1)
print(next(batched_test_dataset.create_tuple_iterator(output_numpy=True)))
model = GPT2LMHeadModel.from_pretrained('./gpt2_summarization/checkpoint-45', config=config)
model.set_train(False)
model.config.eos_token_id = model.config.sep_token_id
i = 0
for (input_ids, raw_summary) in batched_test_dataset.create_tuple_iterator():
output_ids = model.generate(input_ids, max_new_tokens=50, num_beams=5, no_repeat_ngram_size=2)
output_text = tokenizer.decode(output_ids[0].tolist())
print(output_text)
i += 1
if i == 1:
break
实训结果:

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)