241118_MindTorch学习-torch代码快速迁移到mindspore
在一个torch做的项目中直接在最开始,在import torch之前,代码执行的主入口文件中,添加一行(需设置ENABLE_BACKWARD,看后面微分接口适配块)就行了,就能跑了,没错。人傻了。其他的代码都不用改。
MindTorch学习
在一个torch做的项目中
直接在最开始,在import torch之前,代码执行的主入口文件中,添加一行(需设置ENABLE_BACKWARD,看后面微分接口适配块)
from mindtorch.tools import mstorch_enable
就行了,就能跑了,没错。人傻了。其他的代码都不用改

MindTorch优化器和学习率适配
在打印学习率中,mindtorch中的学习率是一个对象,不能直接打印出数值,需要加一个float转换成数值

修改时也是一样的,由于其本身是一个对象,不能直接赋值,需要调用函数进行赋值

在前向计算时的区别

自定义优化器(我现在还没到这水平,先留个图)

自定义LRScheduler

MindTorch微分接口适配
就是前向计算及反向传播过程,因为mindpore是函数式编程,所以不能实现像pytorch那样的一句话就实现了一个功能,在mindspore里面需要我们自己写前向计算、反向梯度、单步训练等方法,如下图

我们先前的迁移工作多是用上述方式实现的,但是MindTorch现在也在开发对标Pytorch中这样简洁化训练的功能,真正实现不用修改代码。默认情况下ENABLE BACKWARD=0,默认不开启此功能,自己迁移的时候可以试试
方法二使用过程中可能会出现问题,此时可以手动把梯度计算部分修改为mindspore的函数式计算的方法

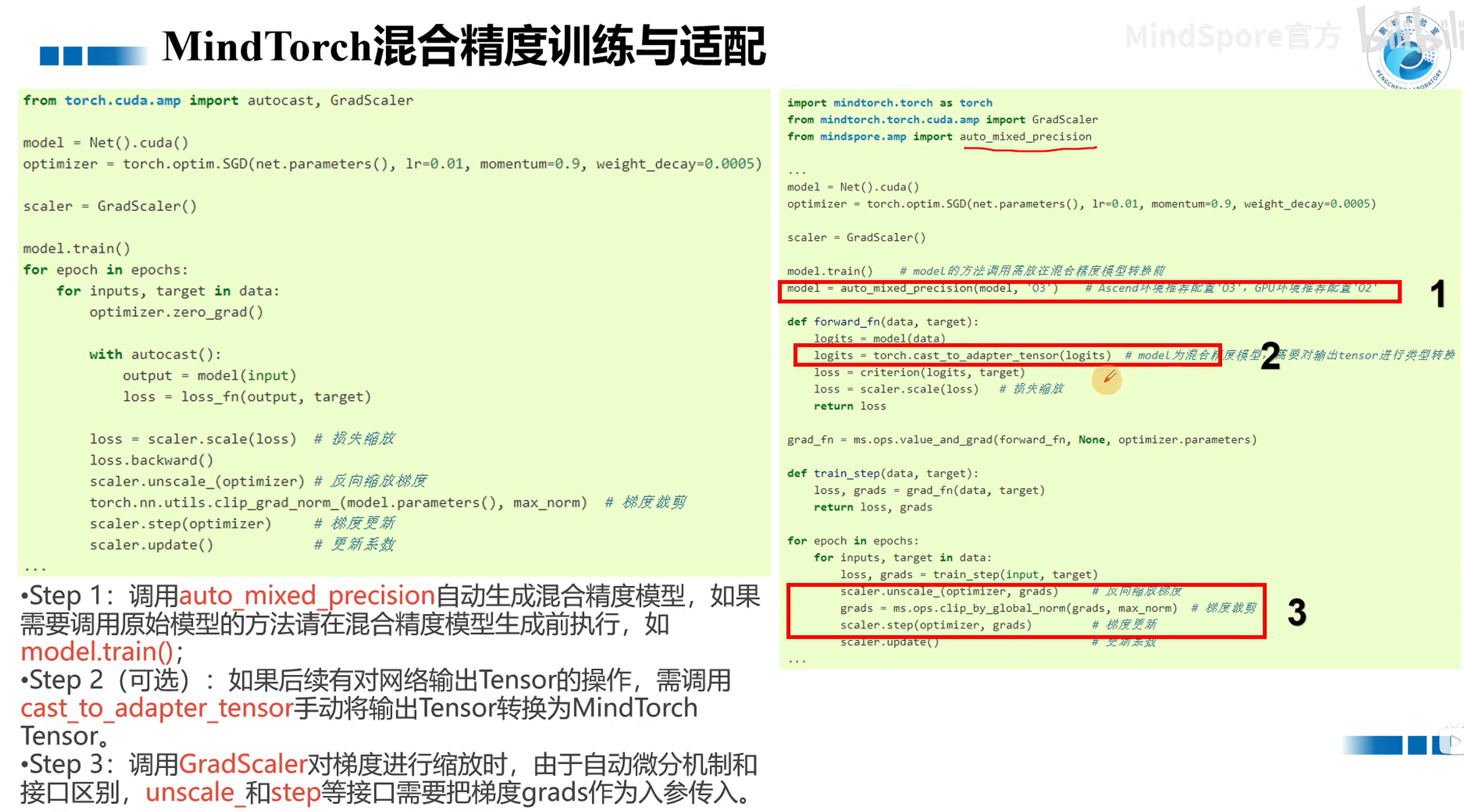
可以直接调用mindspore.amp中的auto_mixed_precision实现混合精度的训练
注意在使用混合精度之后,返回的数据类型是MindSpore.Tensor,但我们在前向计算的过程中需要的是MindTorch.Tensor,所以在forward_fn方法中需要进行类型转换
MindTorch静态图加速
使用@ms.jit是仅把当前装饰到的方法转为静态图编译
方法二是全局静态图模式

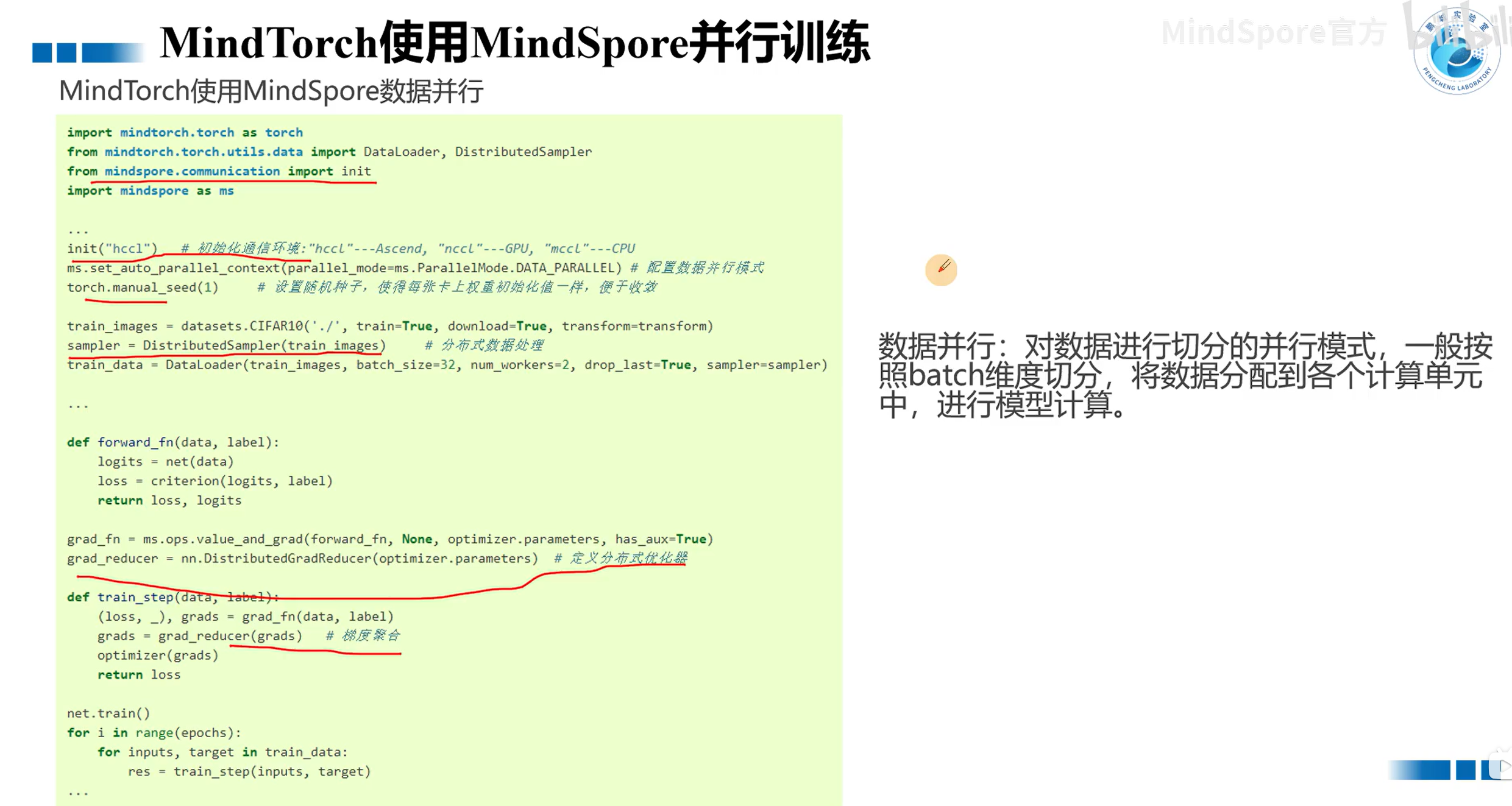
MindTorch使用MindSpore并行训练
数据并行
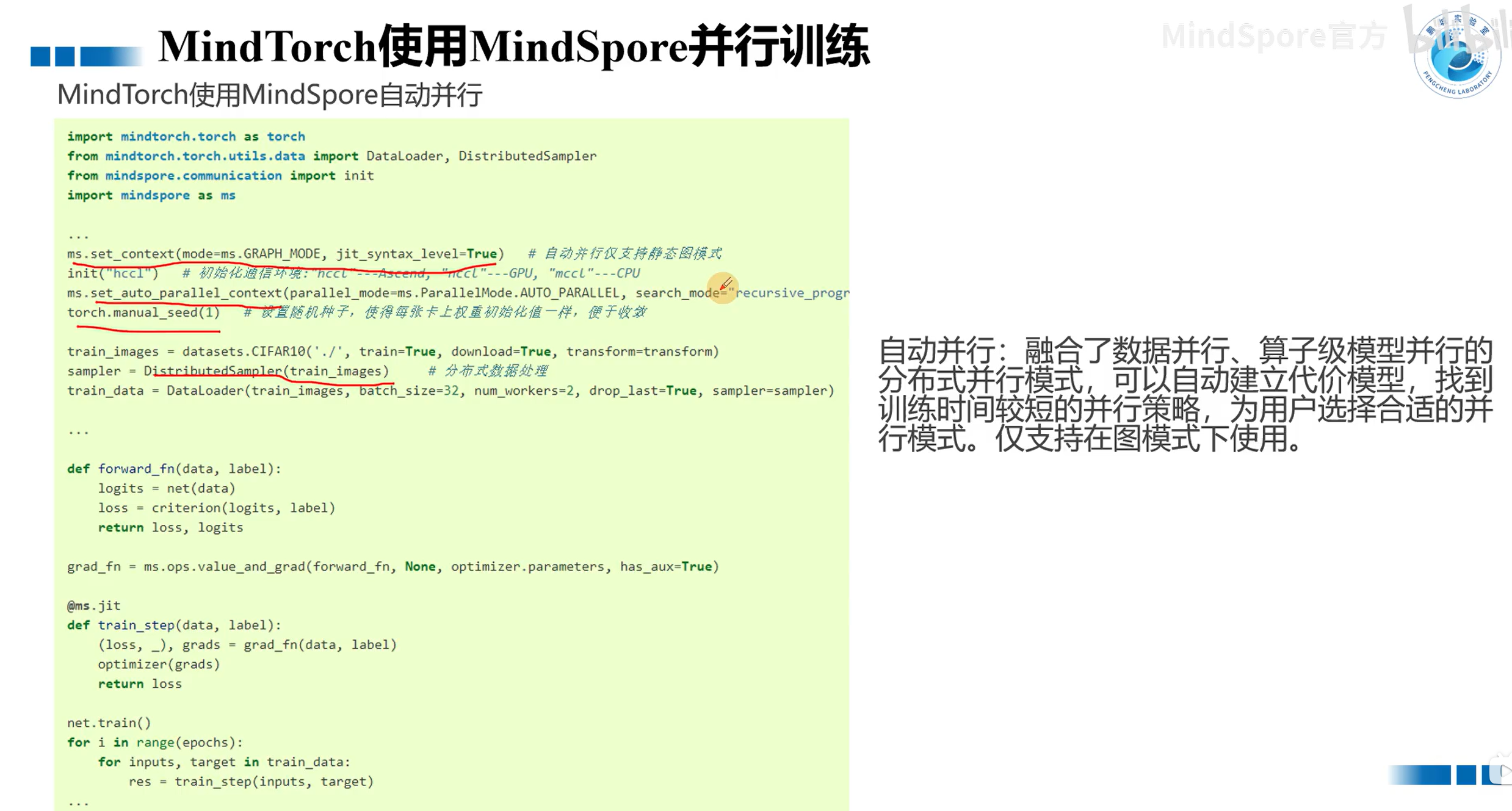
自动并行
就是数据并行+算子级模型并行,仅支持静态图模式,注意上下两个代码中在set_auto_parallel_context中参数不一致
精度调优
在迁移完成之后,我们可能会发现两个框架计算结果不一致,此时就需要调试去看哪里出了错

实验部分
实验过程中我们可以通过注释掉第一行代码
from mindtorch.tools import mstorch_enable
来实现使用pytorch框架在cpu上训练以及使用mindtorch在NPU上训练
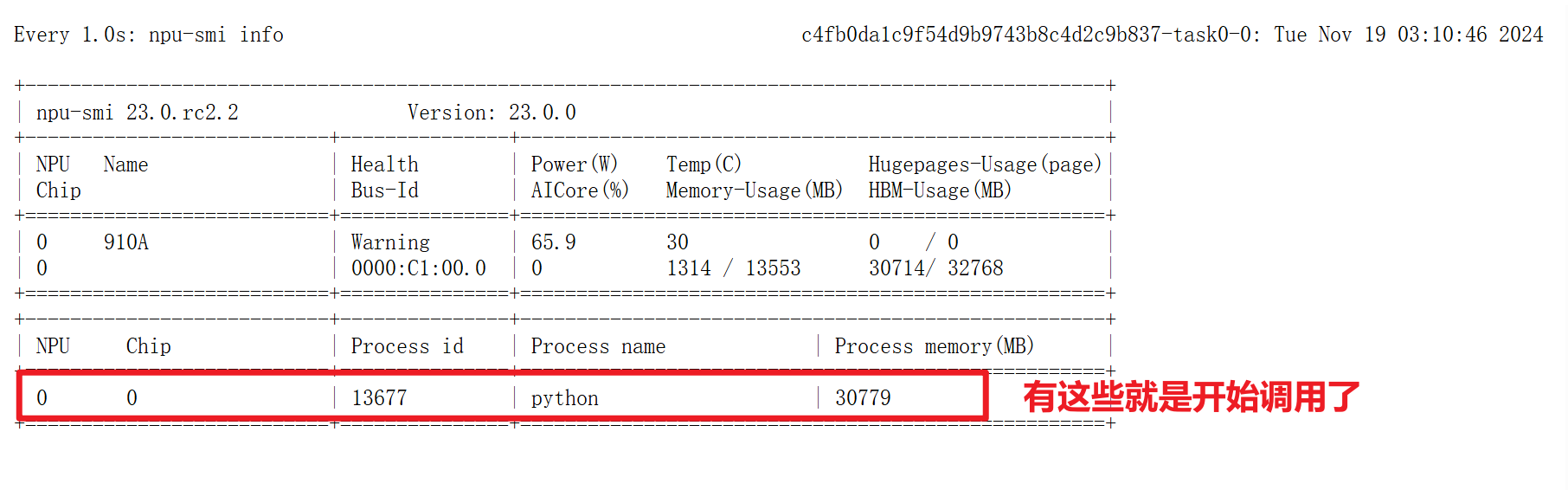
可以另开一个终端,使用如下代码观察卡的调用信息
watch watch -n 1 npu-smi info
在调试过程中
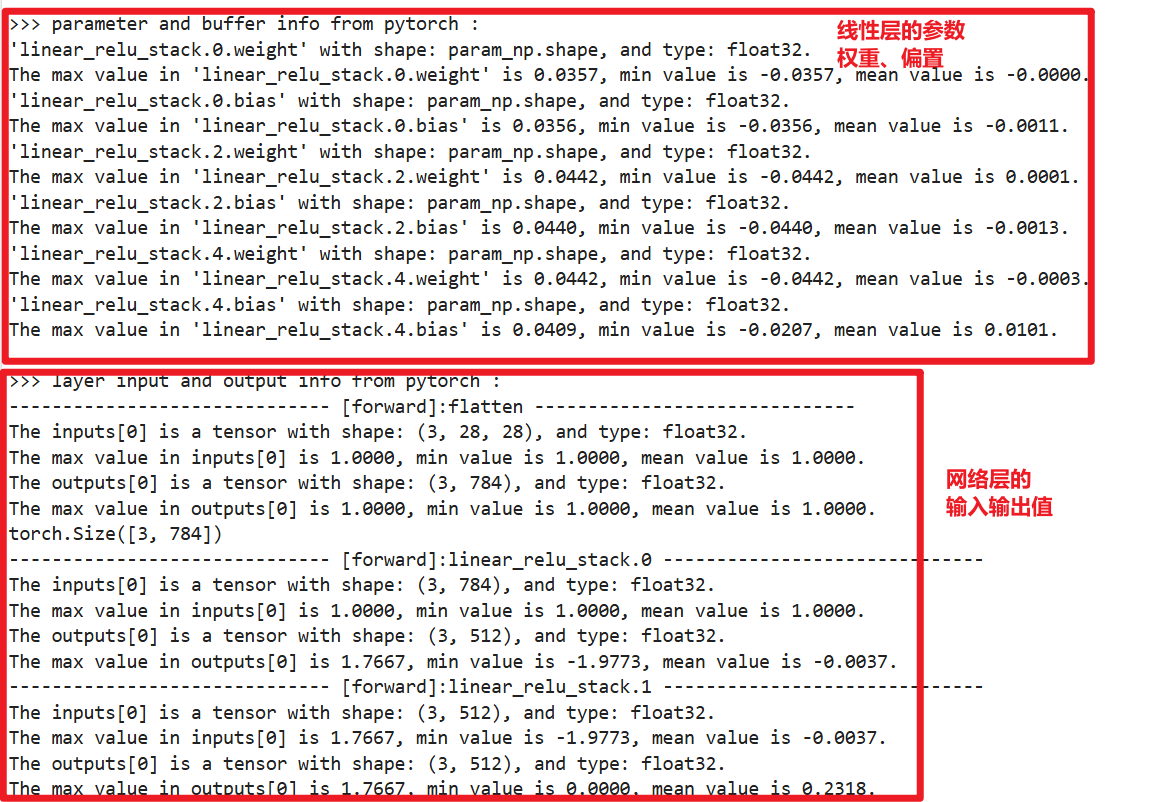
使用如下代码导入包,这个包可以输出每一层的参数
from mindtorch.tools import debug_layer_info

直接把训练后的model作为参数传进去
此时直接运行代码就会出现这样的结果,输出了数据在各层的结果

在终端看这个显然不方便,我们可以将其输出到txt中
python code4.py >> torch_out.txt
对mindtorch实现的也做同样的操作
接下来就可以对两个txt文件做数值对比了
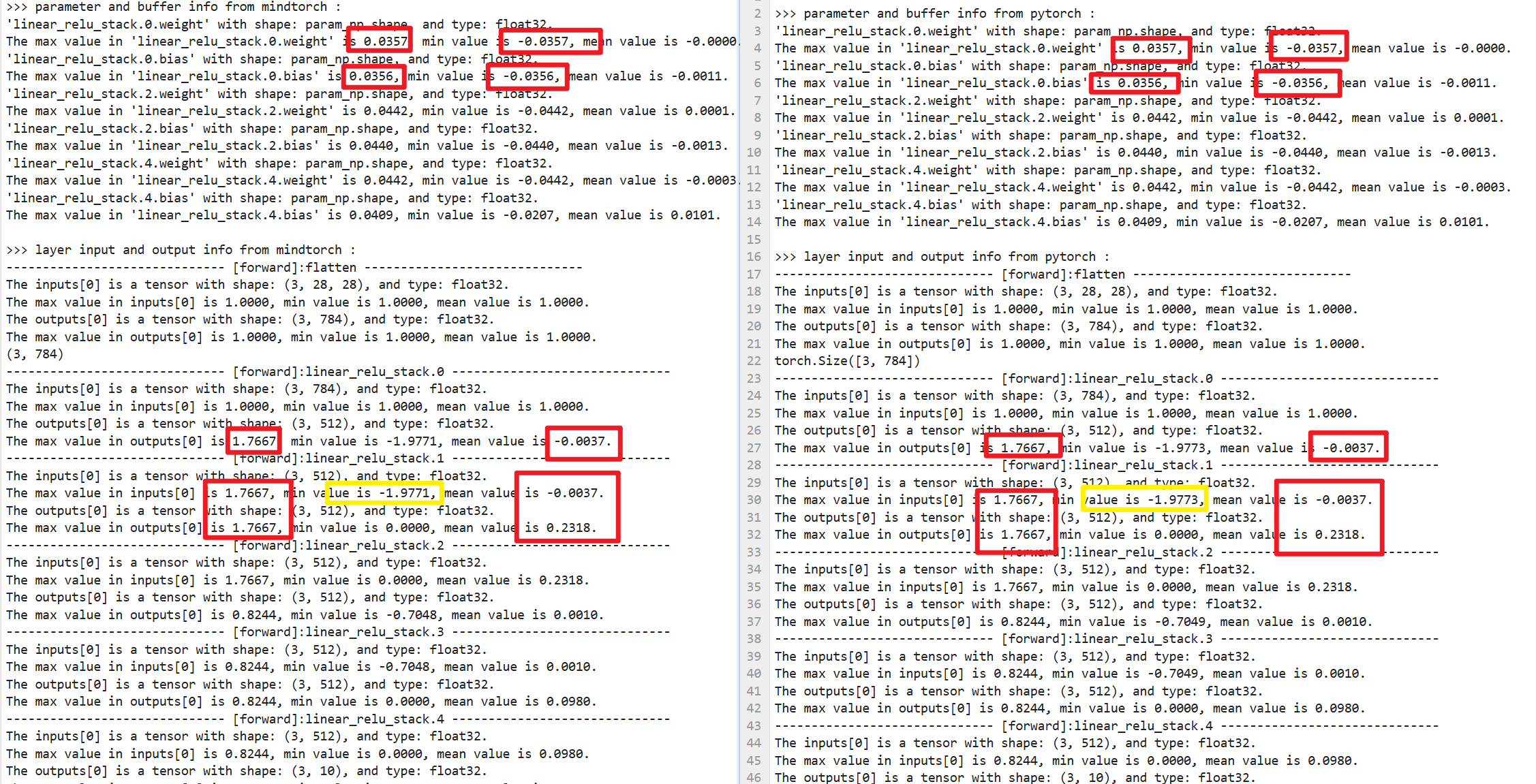
我们可以看到在线性层第二层时(图中黄框位置),输入值的min_value产生了偏差,差了0.0002,这个是不影响的,我们可以容许误差在1e-3的数量级,可以看到就算此时的输入值有偏差,输出值也是一样的,此时没有影响到结果
在实际尝试迁移过程中,貌似还存在部分问题,目前来说还是替换api更加稳定

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 6
6 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)