241124_基于MindSpore学习GPT2
大语言模型就是输入前一个词预测下一个词。
241124_基于MindSpore学习GPT2
大语言模型就是输入前一个词预测下一个词。
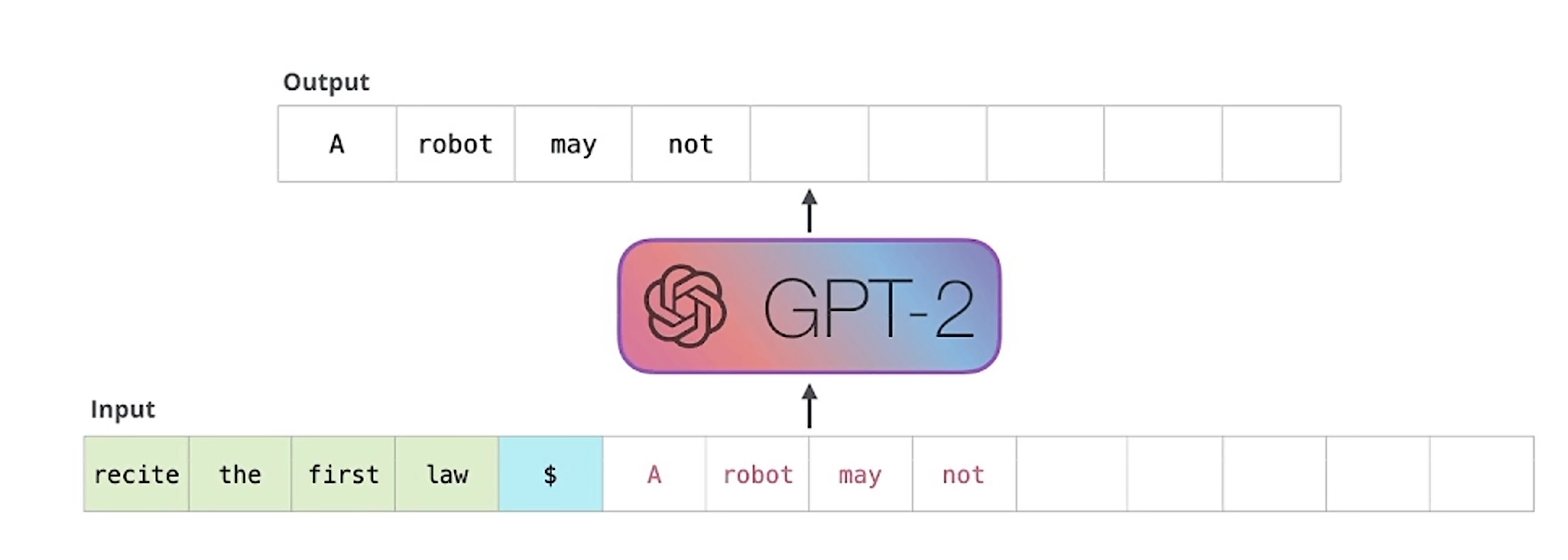
就是先输入recite the first law 预测下一个单词是A,就把A拼接起来,整个句子送进去,然后再预测下一个单词是robot,就再拼接,然后整个句子送进去
GPT2主要有两个点:
Task Conditioning
Zero Shot Learning and Zero Short Task Transfer
Task Conditioning
语言模型就是给定input然后输出output
GPT2和GPT1不一样,GPT2做的是一个小样本甚至零样本的学习,做多种训练。
相比GPT1,在网络结构上没有过多的创新和设计,只是使用了更多的网络参数和更大的数据集
预训练方法:
加了一个针对task的指令instruction然后和数据拼在一起
比如使用大语言模型时,输入一句英文,然后我们要给他翻译成中文,我们的输入可能是:
i love you ,帮我把上面这句翻译成中文
处理流程就是把i love you 识别成一个句子,帮我把上面这句翻译成中文识别成指令,然后拼接我爱你,然后投入训练
Zero Shot Learning and Zero Short Task Transfer
基于前面的task conditioning。给定句子和指令可以完成具体的特定任务,不用针对训练,就可以有较好的效果。
GPT2的目标是使用无监督的预训练模型做有监督的任务
例如当模型训练完“Micheal Jordan is the best basketball player in the history”语料的语言模型之后,便也学会了(question:“who is the best basketball player in the history ?”,answer:“Micheal Jordan”)的Q&A任务。
主要是在大量的无标注的数据集上训练使模型具有举一反三的效果。
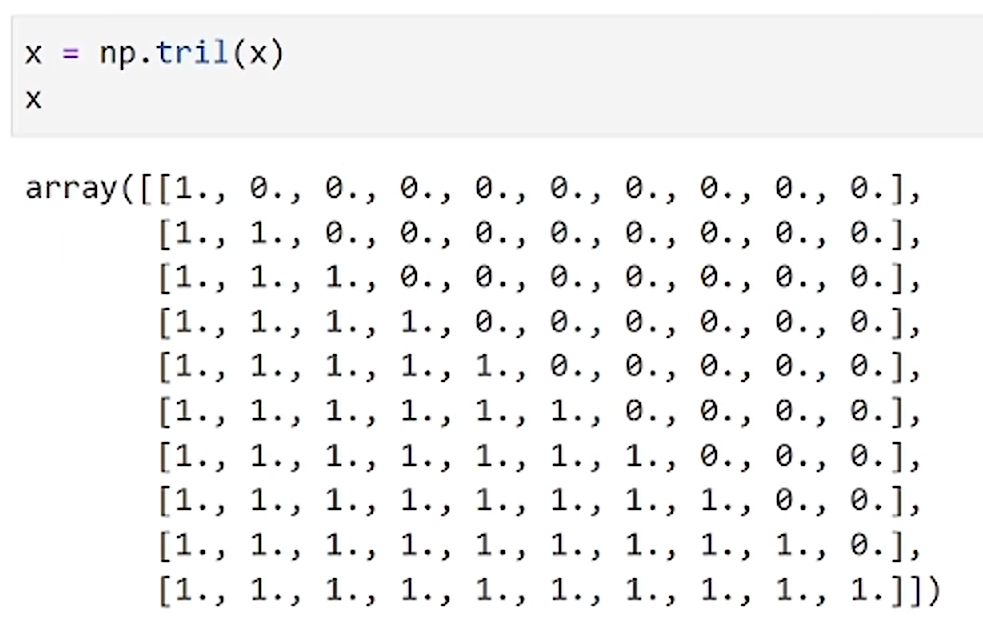
因为gpt是单向任务,不能看到未来的词,所以我们要对未来的词做一个mask操作
使用qk相乘之后会得到一个矩阵,使用np.tril()可以实现mask效果


打卡截图:

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 3
3 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)