【昇思MindSpore版】快速入门:手写数字识别 (CPU即可)
通过本文的讲解,你应该已经掌握了使用 MindSpore 完成一个深度学习模型的训练全过程,包括网络构建、数据处理、训练逻辑以及常见问题的解决方法。在实际开发中,遇到问题时可以通过逐步检查数据、网络和训练逻辑来定位错误并解决。hello,我是是Yu欸。原文链接 👉,⚡️更新更及时。欢迎大家点开下面名片,添加好友交流。
【昇思MindSpore版】《动手学深度学习》可运行课程代码

写在最前面
版权声明:本文为原创,遵循 CC 4.0 BY-SA 协议。转载请注明出处。
基于MindSpore的API来快速实现一个简单的深度学习模型,完成手写数字识别的任务。
学习资料
- 官网教程:https://www.mindspore.cn/tutorials/zh-CN/r2.0/index.html
- MidnSpore版《动手学深度学习》:https://openi.pcl.ac.cn/mindspore-courses/d2l-mindspore
- 【昇思MindSpore版】《动手学深度学习》可运行课程代码https://openi.pcl.ac.cn/mindspore-courses/d2l-mindspore
- 【2023.04.17 - 2023.05.14】“我为开源打榜狂” 第八期
https://openi.org.cn/index.php?a=lists&c=index&catid=233&m=content - 快速入门:手写数字识别
https://www.mindspore.cn/tutorials/zh-CN/r1.7/beginner/quick_start.html
环境配置
- MindSpore 2.3及以上, 安装教程:https://www.mindspore.cn/install
也可以直接看我的历史博客。https://blog.csdn.net/WTYuong/article/details/144581893 - download,可使用命令
pip install download安装 - pip install ipykernel
如本练习以Notebook运行时,完成安装后需要重启kernel才能执行后续代码。
使用 MindSpore 搭建深度学习模型并完成训练过程
在本篇博客中,我们将介绍如何使用 MindSpore 搭建深度学习网络模型,并完成一个完整的训练过程。通过梳理常见问题及其解决方案,你将掌握以下内容:
- 搭建深度学习网络。
- 数据预处理与批处理操作。
- 模型训练的完整步骤(正向计算、反向传播、参数优化)。
- 常见训练错误的解决方法。
一、准备工作
环境设置
在开始之前,我们需要确保 MindSpore 的运行环境已正确配置,同时设置动态图模式(PYNATIVE_MODE),以便动态调试和快速开发。
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
fr
om mindspore import context
# 设置动态图模式
context.set_context(mode=context.PYNATIVE_MODE, device_target="CPU")
数据集处理
处理数据集
MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。
在本次练习中,我们使用Mnist数据集,自动下载完成后,使用mindspore.dataset提供的数据变换进行预处理。
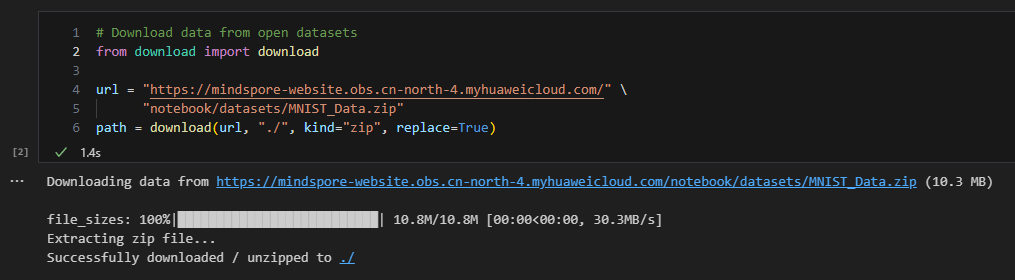
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
二、构建网络模型
在 MindSpore 中,nn.Cell 是所有网络的基类。通过继承 nn.Cell,可以自定义网络结构,并重写 __init__ 和 construct 方法:
__init__定义网络层。construct定义数据的前向计算流程。
示例网络
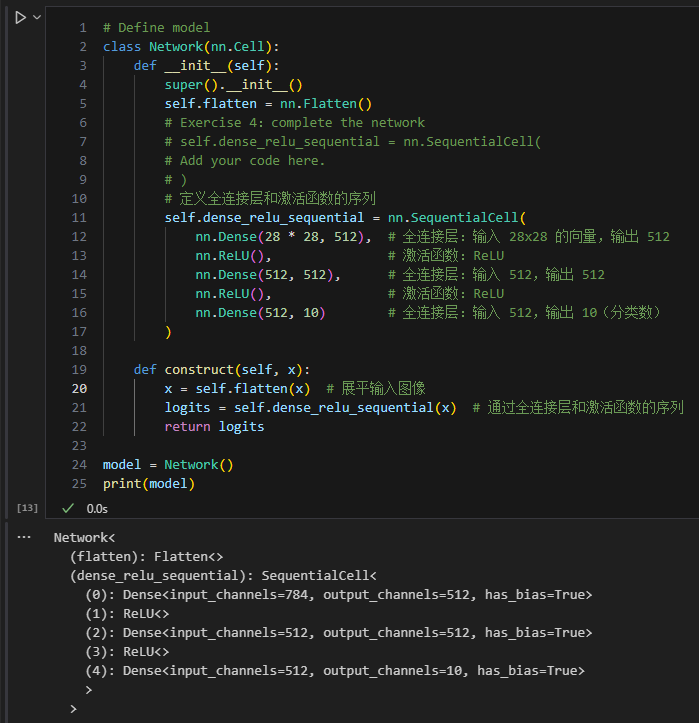
以下代码定义了一个简单的全连接神经网络,用于 MNIST 数据集的分类任务:
import mindspore.nn as nn
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28 * 28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
# 实例化模型
model = Network()
print(model)
输出网络结构
运行代码后,打印的网络结构如下:
Network<
(flatten): Flatten<>
(dense_relu_sequential): SequentialCell<
(0): Dense<input_channels=784, output_channels=512, has_bias=True>
(1): ReLU<>
(2): Dense<input_channels=512, output_channels=512, has_bias=True>
(3): ReLU<>
(4): Dense<input_channels=512, output_channels=10, has_bias=True>
>
>
三、数据预处理
MindSpore 提供强大的数据处理模块,可以轻松完成数据加载、预处理和批处理操作。
1. 数据加载
使用 MnistDataset 加载 MNIST 数据集:
from mindspore.dataset import MnistDataset
train_dataset = MnistDataset('MNIST_Data/train')
test_dataset = MnistDataset('MNIST_Data/test')
2. 数据预处理
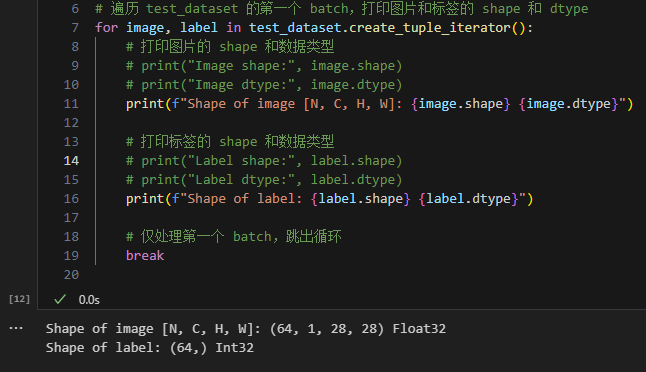
对图像和标签进行如下预处理:
- 将图像像素值归一化到 [0, 1]。
- 按照指定的均值和标准差对图像进行归一化。
- 调整图像形状为
[C, H, W]。 - 将标签转换为整型。
import mindspore.dataset.transforms as transforms
import mindspore.dataset.vision as vision
def datapipe(dataset, batch_size):
# 图像预处理操作
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=0.1307, std=0.3081),
vision.HWC2CHW()
]
# 标签预处理操作
label_transform = transforms.TypeCast(mindspore.int32)
# 应用预处理
dataset = dataset.map(operations=image_transforms, input_columns="image")
dataset = dataset.map(operations=label_transform, input_columns="label")
dataset = dataset.batch(batch_size)
return dataset
train_dataset = datapipe(train_dataset, 64)
test_dataset = datapipe(test_dataset, 64)
四、训练过程
1. 正向计算
定义正向计算函数,用于计算预测值(logits)和损失(loss):
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean")
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
2. 梯度计算
通过 mindspore.value_and_grad 获取梯度计算函数:
from mindspore import value_and_grad
optimizer = nn.Adam(model.trainable_params(), learning_rate=0.001)
grad_fn = value_and_grad(forward_fn, grad_position=None, params=optimizer.parameters, has_aux=True)
3. 单步训练
完成单步训练(正向计算、梯度计算、参数优化):
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
4. 训练函数
完成一个完整的训练过程:
def train(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0:
print(f"loss: {loss.asnumpy():.4f} [{batch}/{size}]")
五、测试过程
def test(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
model.set_train(False)
total, test_loss, correct = 0, 0, 0
for data, label in dataset.create_tuple_iterator():
pred = model(data)
total += len(data)
test_loss += loss_fn(pred, label).asnumpy()
correct += (pred.argmax(1) == label).asnumpy().sum()
test_loss /= num_batches
correct /= total
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
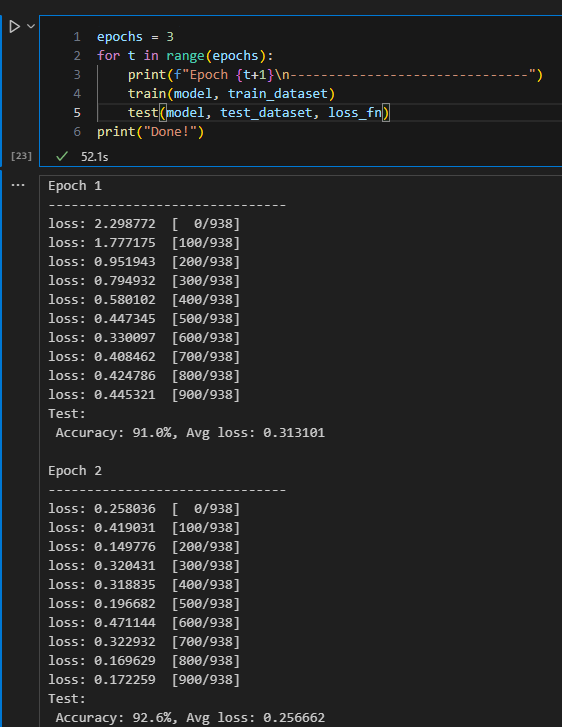
训练过程需多次迭代数据集,一次完整的迭代称为一轮(epoch)。在每一轮,遍历训练集进行训练,结束后使用测试集进行预测。打印每一轮的loss值和预测准确率(Accuracy),可以看到loss在不断下降,Accuracy在不断提高。
epochs = 3
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(model, train_dataset)
test(model, test_dataset, loss_fn)
print("Done!")
六、常见问题及解决方法
1. 动态图模式问题
错误:RuntimeError: The pointer[finded_top_cell_] is null.
解决方法:确保在脚本开头设置动态图模式:
context.set_context(mode=context.PYNATIVE_MODE, device_target="CPU")
2. 数据类型问题
错误:数据类型或格式不匹配导致模型无法训练。
解决方法:在数据加载过程中,显式转换数据类型:
label_transform = transforms.TypeCast(mindspore.int32)
train_dataset = train_dataset.map(operations=label_transform, input_columns="label")
3. 未设置训练模式
错误:未调用 model.set_train() 导致模型训练失败。
解决方法:在训练函数中调用:
model.set_train()
4. 梯度计算错误
错误:ValueError: When has_aux is True, origin fn requires more than one outputs.
解决方法:确保正向计算函数返回两个值(loss 和 logits):
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
七、完整训练代码
将以上所有模块整合后,完整代码如下:
from mindspore import context, nn, value_and_grad
import mindspore.dataset.transforms as transforms
import mindspore.dataset.vision as vision
from mindspore.dataset import MnistDataset
# 设置动态图模式
context.set_context(mode=context.PYNATIVE_MODE, device_target="CPU")
# 数据预处理函数
def datapipe(dataset, batch_size):
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=0.1307, std=0.3081),
vision.HWC2CHW()
]
label_transform = transforms.TypeCast(mindspore.int32)
dataset = dataset.map(operations=image_transforms, input_columns="image")
dataset = dataset.map(operations=label_transform, input_columns="label")
dataset = dataset.batch(batch_size)
return dataset
# 数据加载与预处理
train_dataset = MnistDataset('MNIST_Data/train')
test_dataset = MnistDataset('MNIST_Data/test')
train_dataset = datapipe(train_dataset, 64)
test_dataset = datapipe(test_dataset, 64)
# 模型定义
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28 * 28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean")
optimizer = nn.Adam(model.trainable_params(), learning_rate=0.001)
# 正向计算和梯度函数
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
grad_fn = value_and_grad(forward_fn, grad_position=None, params=optimizer.parameters, has_aux=True)
# 单步训练函数
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
# 训练函数
def train(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0:
print(f"loss: {loss.asnumpy():.4f} [{batch}/{size}]")
八、总结
通过本文的讲解,你应该已经掌握了使用 MindSpore 完成一个深度学习模型的训练全过程,包括网络构建、数据处理、训练逻辑以及常见问题的解决方法。在实际开发中,遇到问题时可以通过逐步检查数据、网络和训练逻辑来定位错误并解决。
hello,我是 是Yu欸 。如果你喜欢我的文章,欢迎三连给我鼓励和支持:👍点赞 📁 关注 💬评论,我会给大家带来更多有用有趣的文章。
原文链接 👉 ,⚡️更新更及时。
欢迎大家点开下面名片,添加好友交流。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 63
63 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)