MindSpore学习实践——基于MindNLP的Roberta Prompt Turning
昇思打卡营第四期——基于MindNLP的Roberta Prompt Turning
·
MindSpore学习实践——基于MindNLP的Roberta Prompt Turning
前言
之前我们学过,GPT主要是预测下一个单词,也就是类似文字接龙的方式,而BERT模型只要是类似于完形填空的运作方式。这两个模型都是通过模型微调去完成特定的下游任务,不过当前预训练+微调还是存在一些挑战,比如说数据稀缺;参数量大带来的训练成本和存储空间要求高;少样本学习能力差、容易过拟合等问题。在模型体量越来越大的时候,模型的微调不再是一个高性价比的方案。所以带来了Prompt方法。
Prompt——提示词
为了让模型调用其训练中获得的特定知识,我们可以使用提示词将指示模型按照我们所想的方法去推理。最简单的方法就是完形填空,比如将若需要的答案挖空让模型去生成答案。
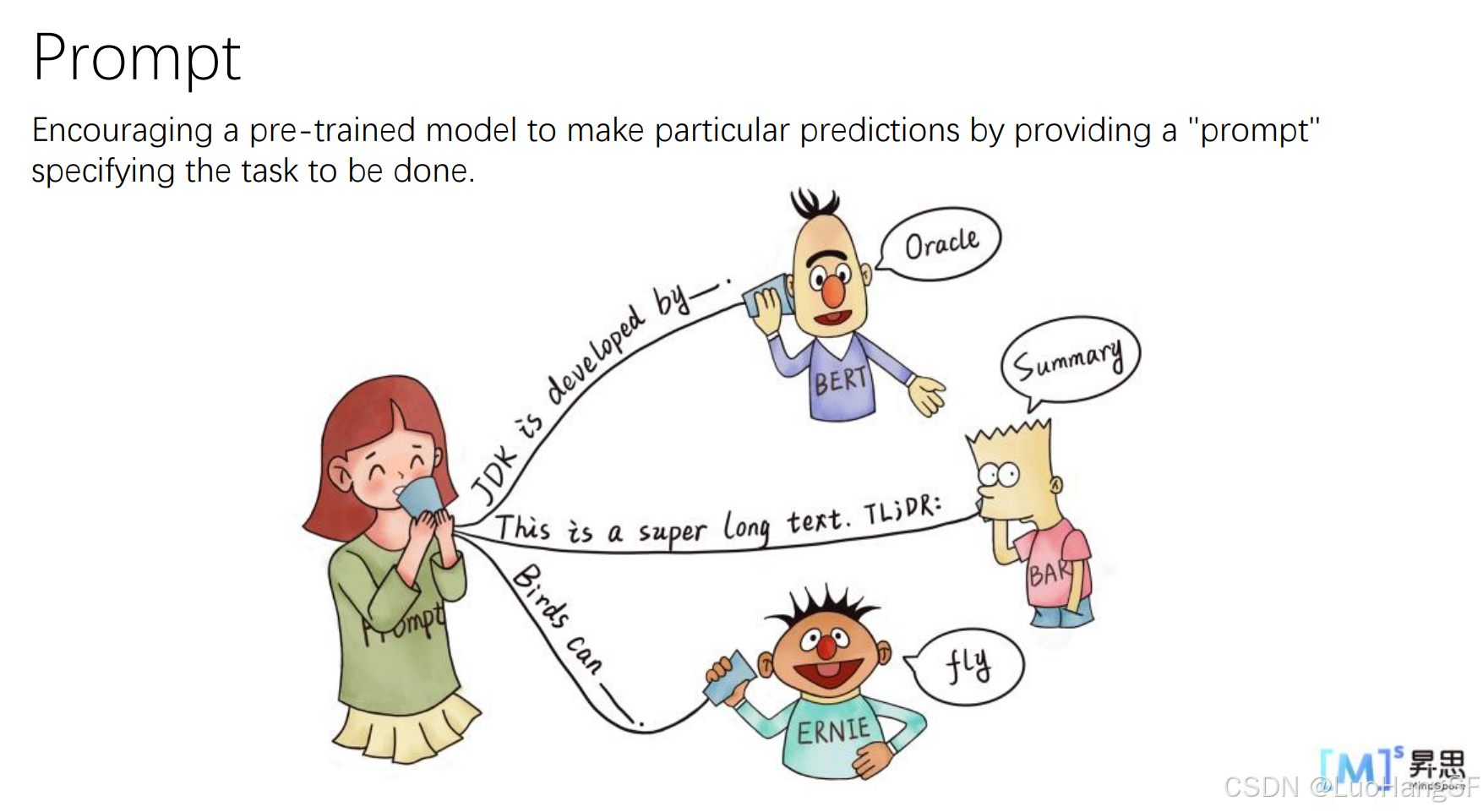
- 情景训练,可以给模型一个情景,再给出一些例子,最后再让模型基于上面的例子去完成任务,根据例子的数量可以分为Zero-shot、one-shot、few-shot等。这样我们对模型并没有发生什么改变但还是完成了既定目标,可以节约训练成本。

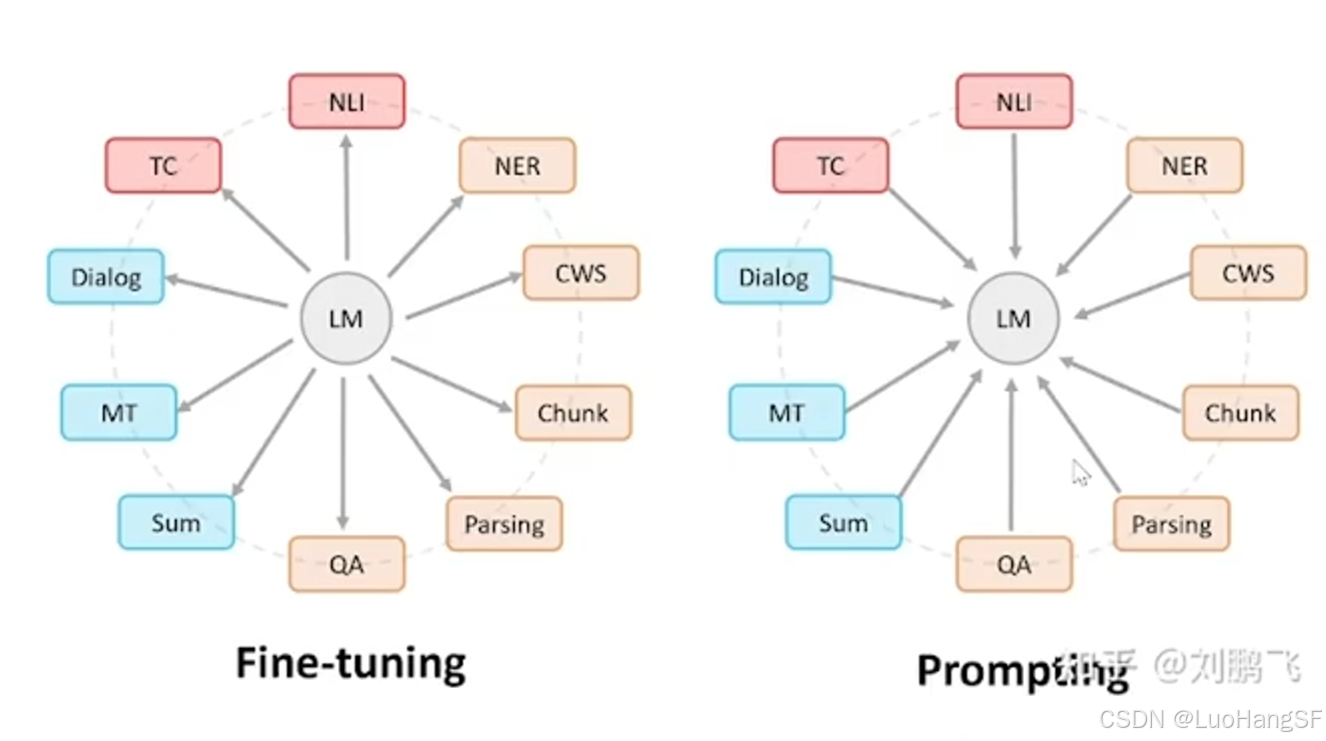
- 微调和提示词学习有什么区别?
- 微调:以模型为出发点,通过改变模型结构,牺牲模型的部分参数,使模型适配下游任务。
- 提示词学习:以不同下游任务为出发点,模型结构不变,通过重构任务描述,使下游任务适配模型。
- 在提示学习中,最重要的就是编写或获得一个好的提示,在这个过程中发展出了两个概念:硬提示(hard prompt)、软提示(soft prompt)。
- 硬提示(hard prompt)是由具体的中文或英文词汇组成的文本提示,包含离散的输入标记。它们通常由人类专门为解决特定任务而精心设计。其优点在于人类可读,可解释,灵活性强。但是也有缺点:它需要大量人工精力来设计出好的提示,对于复杂任务来说非常困难。
- 软提示(soft prompt)通过hard prompt方式初始化(即用人工可阅读的单词序列初始化),然后通过向量空间连续优化得到新的提示。其优点使无需人工设计,可自动优化以适应不同任务,计算效率高而且支持多任务学习。但是缺点也非常显而易见:软提示不可读,我们无法解释为何模型选择这些向量。
- Prompt Template(提示词模板):提示词模板的设计要根据任务以及预训练模型来决定
- 完形填空:适用于使用掩码语言模型的下游任务。
- 前缀提示:适用于文本生成任务。
代码实训
- 环境安装
#安装mindnlp 0.4.0套件
!pip install mindnlp==0.4.0
!pip uninstall soundfile -y
!pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.3.1/MindSpore/unified/aarch64/mindspore-2.3.1-cp39-cp39-linux_aarch64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
%env HF_ENDPOINT=https://hf-mirror.com
- 模型与数据集加载
- 本次实训将对roberta-large模型基于GLUE基准数据集进行prompt tuning
import argparse
import os
import mindspore
from mindnlp.core.optim import AdamW
from tqdm import tqdm
import evaluate
from mindnlp.dataset import load_dataset
from mindnlp.engine import set_seed
from mindnlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
from mindnlp.transformers.optimization import get_linear_schedule_with_warmup
from mindnlp.peft import (
get_peft_config,
get_peft_model,
get_peft_model_state_dict,
set_peft_model_state_dict,
PeftType,
PromptTuningConfig,
)
from mindnlp.dataset import BaseMapFunction
batch_size = 32
model_name_or_path = "AI-ModelScope/roberta-large"
task = "mrpc"
peft_type = PeftType.PROMPT_TUNING
# num_epochs = 20
num_epochs = 5
# 我们对prompt tuning配置,任务类型选为"SEQ_CLS", 即序列分类。
# peft config
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
# learning rate
lr = 1e-3
# 加载tokenizer。如模型为GPT、OPT或BLOOM类模型,从序列左侧添加padding,其他情况下从序列右侧添加padding。
# load tokenizer
if any(k in model_name_or_path for k in ("gpt", "opt", "bloom")):
padding_side = "left"
else:
padding_side = "right"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side, mirror="modelscope")
if getattr(tokenizer, "pad_token_id") is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
datasets = load_dataset("glue", task)
print(next(datasets['train'].create_dict_iterator()))
class MapFunc(BaseMapFunction):
def __call__(self, sentence1, sentence2, label, idx):
outputs = tokenizer(sentence1, sentence2, truncation=True, max_length=None)
return outputs['input_ids'], outputs['attention_mask'], label
def get_dataset(dataset, tokenizer):
input_colums=['sentence1', 'sentence2', 'label', 'idx']
output_columns=['input_ids', 'attention_mask', 'labels']
dataset = dataset.map(MapFunc(input_colums, output_columns),
input_colums, output_columns)
dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id),
'attention_mask': (None, 0)})
return dataset
train_dataset = get_dataset(datasets['train'], tokenizer)
eval_dataset = get_dataset(datasets['validation'], tokenizer)
print(next(train_dataset.create_dict_iterator()))
metric = evaluate.load("glue", task)
# 我们使用从model_name_or_path加载了预训练模型,并使用modelscope作为镜像源。
# load model
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True, mirror="modelscope")
model = get_peft_model(model, peft_config)
# print number of trainable parameters
model.print_trainable_parameters()
- 模型微调
# 我们指定优化器和学习率调整策略
optimizer = AdamW(params=model.trainable_params(), lr=lr)
# Instantiate scheduler
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0.06 * (len(train_dataset) * num_epochs),
num_training_steps=(len(train_dataset) * num_epochs),
)
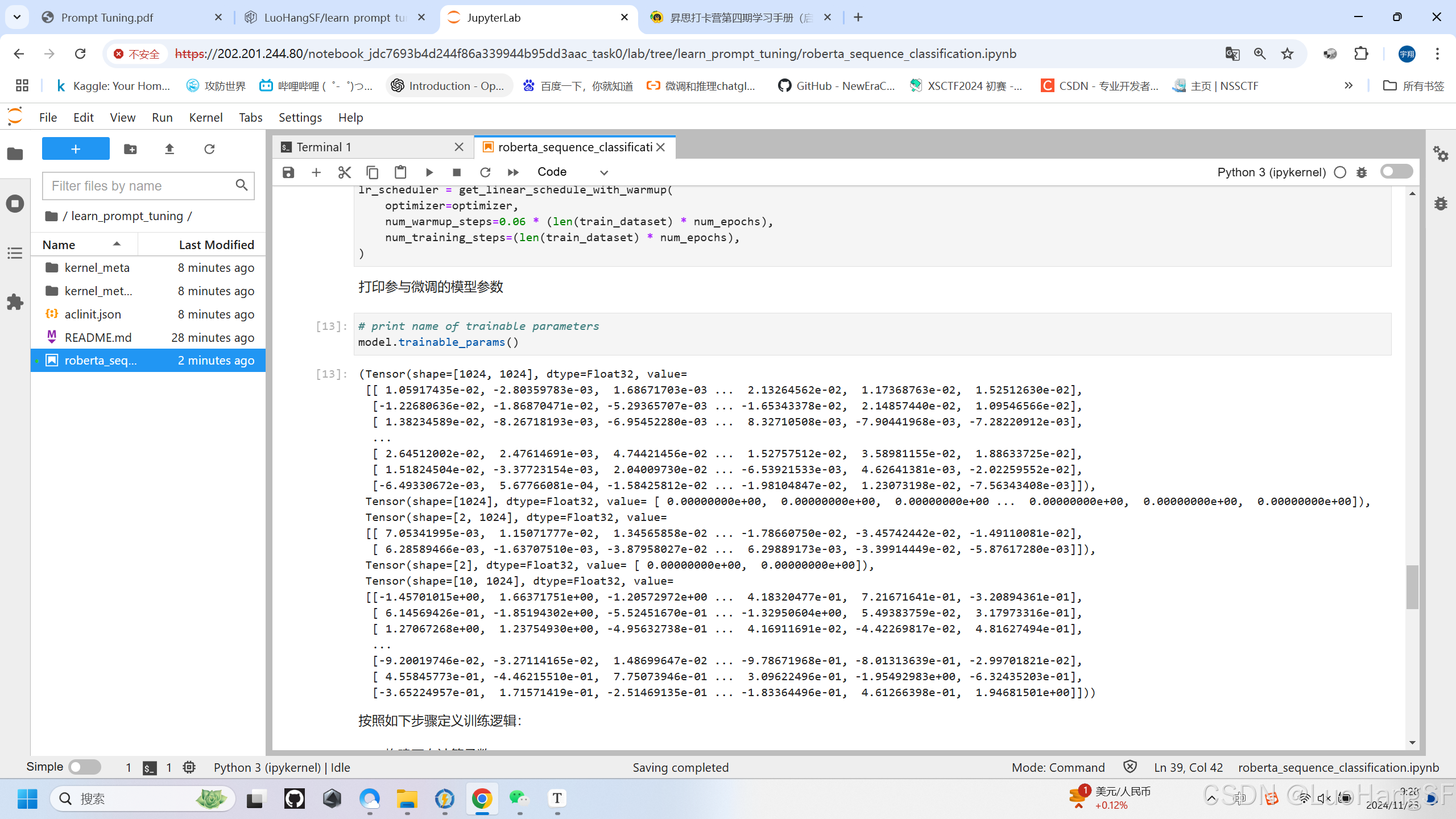
# 打印参与微调的模型参数
# print name of trainable parameters
model.trainable_params()
参与微调的模型参数
"""
训练逻辑:
1. 构建正向计算函数
2. 函数变换,获取微分函数
3. 定义训练一个step的逻辑
4. 遍历训练数据集进行模型训练,同时每一个epoch后,遍历验证数据集获取当前的评价指标(accuracy、f1 score)
"""
# define forward function
def forward_fn(**batch):
outputs = model(**batch)
loss = outputs.loss
return loss
# Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, model.trainable_params())
# Define function of one-step training
def train_step(**batch):
loss, grads = grad_fn(**batch)
optimizer.step(grads)
return loss
# Start training
for epoch in range(num_epochs):
model.set_train()
train_total_size = train_dataset.get_dataset_size()
# Iterate through the dataset
for step, batch in enumerate(tqdm(train_dataset.create_dict_iterator(), total=train_total_size)):
loss = train_step(**batch)
lr_scheduler.step()
# Evaluate while training
model.set_train(False)
eval_total_size = eval_dataset.get_dataset_size()
for step, batch in enumerate(tqdm(eval_dataset.create_dict_iterator(), total=eval_total_size)):
outputs = model(**batch)
predictions = outputs.logits.argmax(axis=-1)
predictions, references = predictions, batch["labels"]
metric.add_batch(
predictions=predictions,
references=references,
)
# Calculate accuracy and f1 score
eval_metric = metric.compute()
print(f"epoch {epoch}:", eval_metric)
- 实训结果
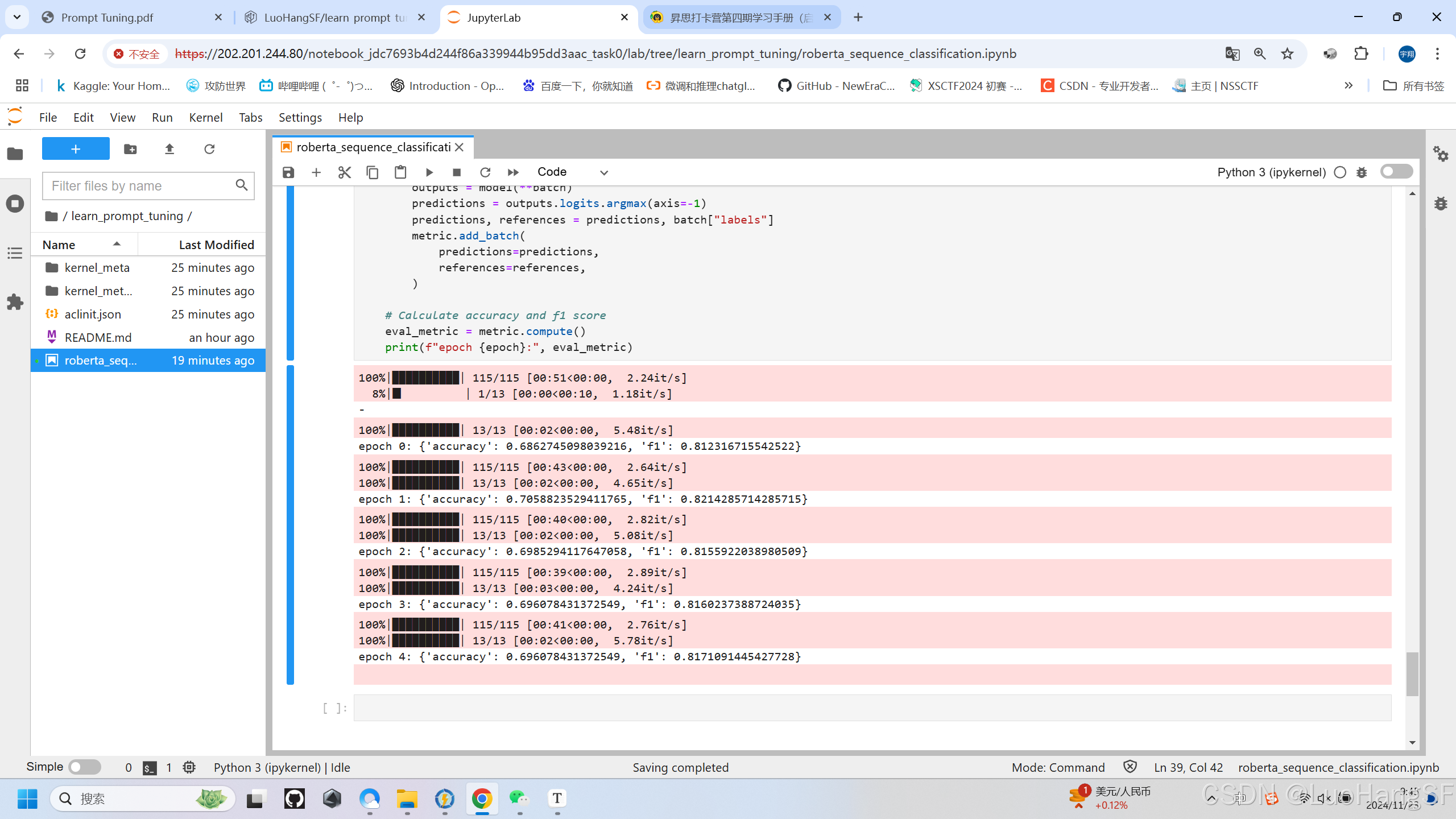
总结
本节课学习了提示词,虽然本人之前在学习使用LangChain调用GPT-3.5-turbo时也简单使用过提示词,不过对其定义分类以及意义的了解不算深刻。本次学习后深化了本人对提示词的了解,尤其是提示词工程在某些情况下能大大减轻训练资源的消耗,这项优点足以让提示词工程有重大意义。不过提示词工程有时也会使模型越狱,带来不良影响,这是个值得深究的问题。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 20
20 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)