MindSpore学习实践——通过GPT实现情感分类
昇思打卡营第四期——基于MindSpore通过GPT实现情感分类
MindSpore学习实践——基于MindSpore通过GPT实现情感分类
承上启下
在上节课讲的BERT模型中,我们提到GPT-1等预训练语言模型主要用于文本生成类任务,需要通过prompt(提示词工程?)方法来应用于下游任务,指导模型生成特定的输出,这个和BERT模型有一定的类似性,它也是基于大量未标注语料进行预训练(无监督预训练,没错就是BooksCorpus,听说参数数量为1.2亿 !还是挺大的),然后基于少量的标注数据进行微调(有监督预训练1)。
GPT介绍
- 输入(GPT Input)
与BERT相似,GPT-1的输入同样为句子或句子对组成,并添加special tokens。如下图所示:
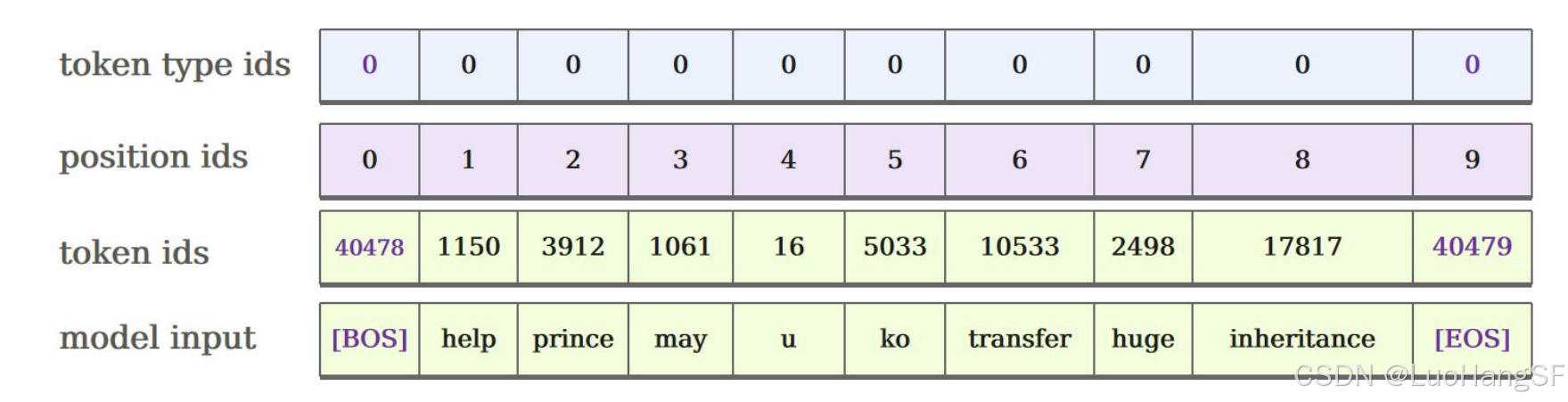
唉?这是什么?
- [BOS] 表示序列的开始,添加到序列的前面
- [EOS] 表示序列的结束,添加到序列最后,在进行分类任务时,会将special token对应的输出接入输出层,也就是说,改token可以学到整个句子的语义信息
- [SEP] 用于间隔句子对中的句子
- 查了一下资料,special token能帮助模型区分输入序列的不同部分,进而更好地理解和处理文本数据,类似的还有:[PAD]用于填充、[CLS]用于表示该序列的分类结果 、[UNK]用于标记未知或词汇外的单词等
- 嵌入(GPT Embedding )
分为三类:token Embedding、Position Embedding、Segment Embedding,三类向量会直接相加。
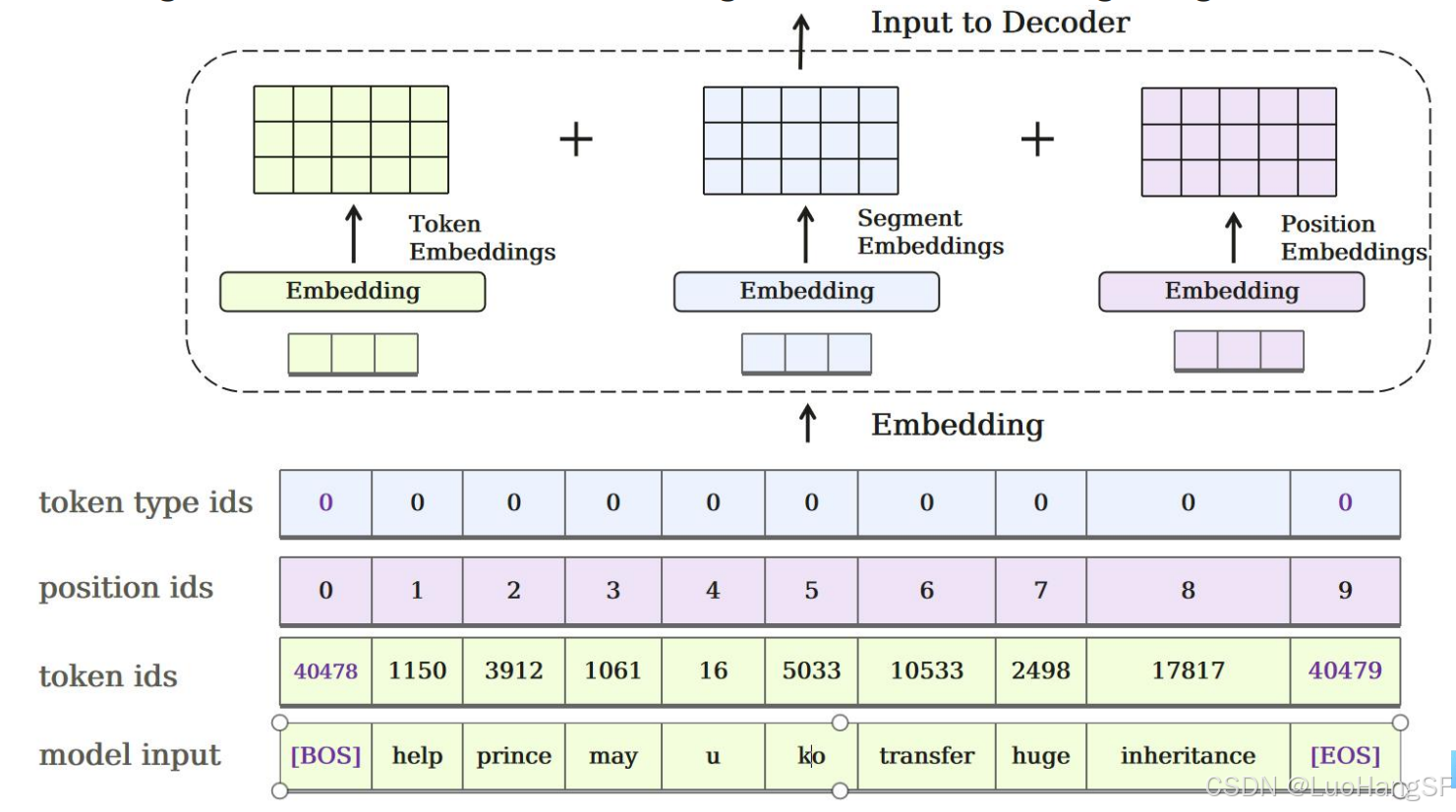
- Token Embedding是词向量,也就对应了transformer中的词嵌入部分
- Position Embedding加在词向量层之后,补充位置信息,注意这里加入位置编码的方式不是拼接,而是直接向量相加
- Segment Embedding用于表示长文本中句子以及段落之间可能存在的一些关联或者差异
- GPT的模型结构
GPT由decoder层堆叠而成,Decoder层组成与Transformer中的Decoder层相似,只不过没有了计算encoder输出和decoder输入之间注意力分数的多头注意力机制multi-head attention(顺便回顾了第一节学习的transformer)。
- GPT的输出
GPT侧重的是语句生成,即基于之前的文本序列,预测下一个词语以及句子(此前学习的BERT主要用于文本理解)也就是因此,GPT在生成式(NLG)的下游任务中表现良好,可以用于文本摘要、机器翻译、问答等。
实践:基于MindSpore通过GPT实现情感分类
- 环境配置
#安装mindnlp 0.4.0套件
!pip install mindnlp==0.4.0
!pip uninstall soundfile -y
!pip install download
!pip install jieba
!pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.3.1/MindSpore/unified/aarch64/mindspore-2.3.1-cp39-cp39-linux_aarch64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
- 导入相关的包
import os
import mindspore
from mindspore.dataset import text, GeneratorDataset, transforms
from mindspore import nn
from mindnlp.dataset import load_dataset
from mindnlp.engine import Trainer
import numpy as np
from mindnlp.transformers import OpenAIGPTTokenizer
from mindnlp.transformers import OpenAIGPTForSequenceClassification
from mindnlp import evaluate
from mindnlp.engine import TrainingArguments
- 数据集准备:
imdb_ds = load_dataset('imdb', split=['train', 'test'])
imdb_train = imdb_ds['train']
imdb_test = imdb_ds['test']
imdb_train.get_dataset_size()
def process_dataset(dataset, tokenizer, max_seq_len=512, batch_size=4, shuffle=False):
is_ascend = mindspore.get_context('device_target') == 'Ascend'
def tokenize(text):
if is_ascend:
tokenized = tokenizer(text, padding='max_length', truncation=True, max_length=max_seq_len)
else:
tokenized = tokenizer(text, truncation=True, max_length=max_seq_len)
return tokenized['input_ids'], tokenized['attention_mask']
if shuffle:
dataset = dataset.shuffle(batch_size)
# map dataset
dataset = dataset.map(operations=[tokenize], input_columns="text", output_columns=['input_ids', 'attention_mask'])
dataset = dataset.map(operations=transforms.TypeCast(mindspore.int32), input_columns="label", output_columns="labels")
# batch dataset
if is_ascend:
dataset = dataset.batch(batch_size)
else:
dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id),
'attention_mask': (None, 0)})
return dataset
- 分词器tokenizer
# tokenizer
gpt_tokenizer = OpenAIGPTTokenizer.from_pretrained('openai-gpt')
# add sepcial token: <PAD>
special_tokens_dict = {
"bos_token": "<bos>",
"eos_token": "<eos>",
"pad_token": "<pad>",
}
num_added_toks = gpt_tokenizer.add_special_tokens(special_tokens_dict)
- 拆分处理数据集:
#这行代码是为了方便体验流程,把原本数据集的十分之一拿出来体验训练和评估,体验该完整的数据集,可以将这行代码注释掉
imdb_train, _ = imdb_train.split([0.1, 0.9], randomize=False)
# split train dataset into train and valid datasets
imdb_train, imdb_val = imdb_train.split([0.7, 0.3])
dataset_train = process_dataset(imdb_train, gpt_tokenizer, shuffle=True)
dataset_val = process_dataset(imdb_val, gpt_tokenizer)
dataset_test = process_dataset(imdb_test, gpt_tokenizer)
next(dataset_train.create_tuple_iterator())
- 准备训练
# set bert config and define parameters for training
model = OpenAIGPTForSequenceClassification.from_pretrained('openai-gpt', num_labels=2)
model.config.pad_token_id = gpt_tokenizer.pad_token_id
model.resize_token_embeddings(model.config.vocab_size + 3)
training_args = TrainingArguments(
output_dir="gpt_imdb_finetune",
evaluation_strategy="epoch",
save_strategy="epoch",
logging_strategy="epoch",
load_best_model_at_end=True,
num_train_epochs=1.0,
learning_rate=2e-5
)
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset_train,
eval_dataset=dataset_val,
compute_metrics=compute_metrics
)
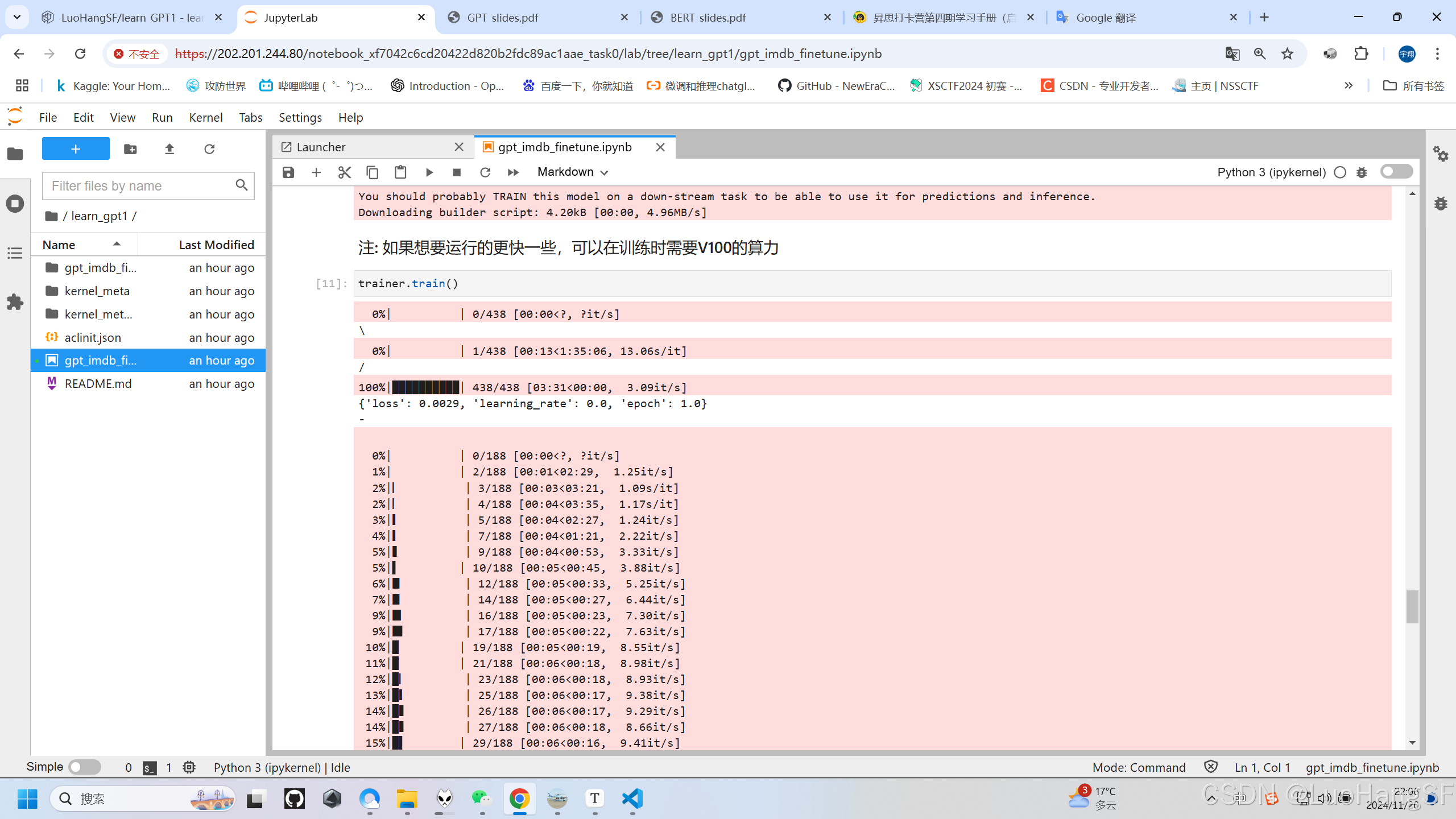
- 开始训练(V100的算力可以使其更快)
trainer.train()
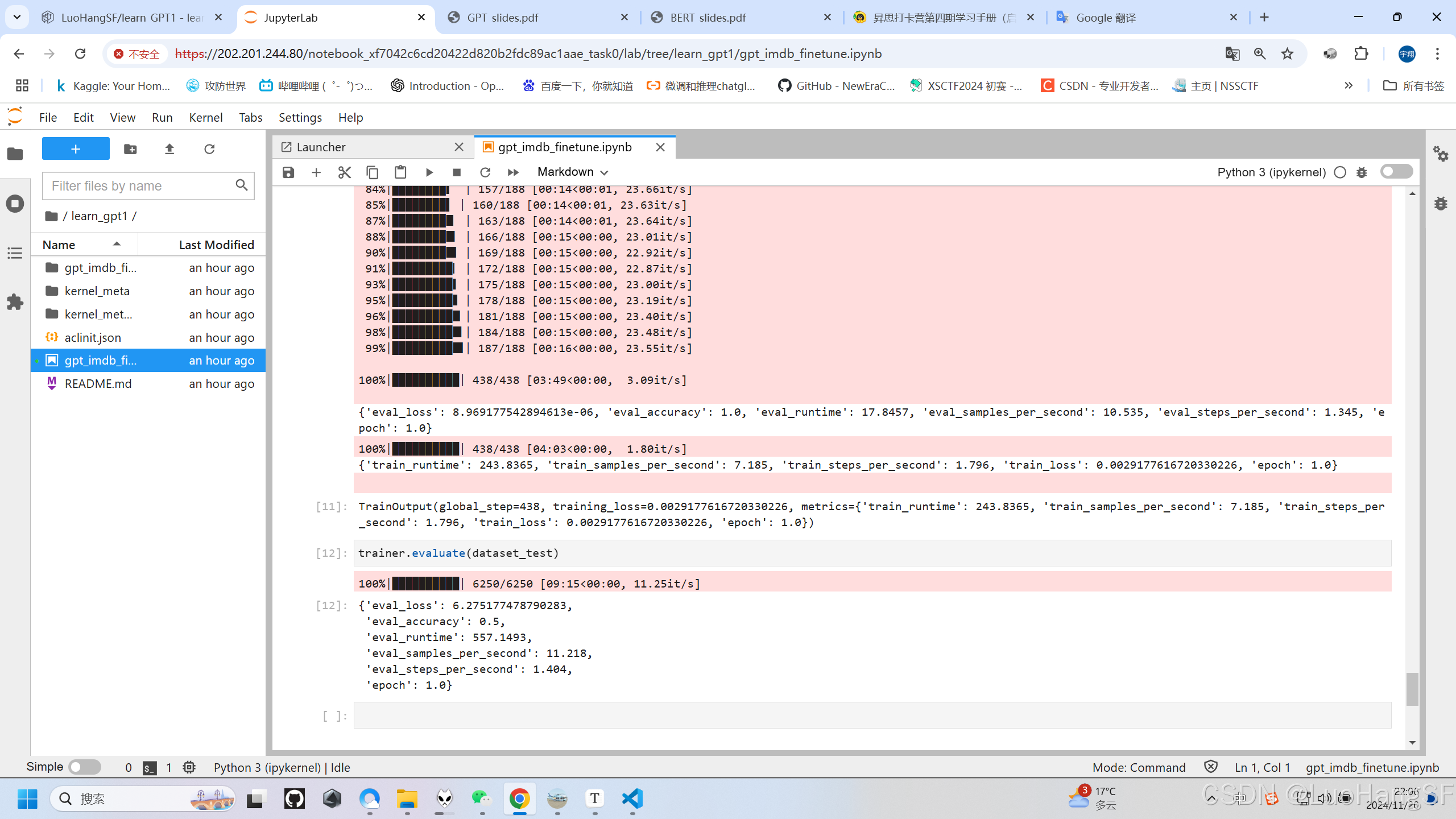
- 模型评估
trainer.evaluate(dataset_test)
实践结果:
总结
本节课学习了GPT-1相关的知识,GPT-1与BERT有一定的相似之处,但是在任务的适配性以及结构上与BERT还是有很大的差别。GPT-1的文本生成能力的潜力在其后辈GPT-3和GPT-4得以显现,还是挺有意思的。本人在大模型方面的基础还是较差,课程还是有些许听不懂之处,如果本文有什么谬误之处还请大佬指教,我也将继续学习,争取尽快掌握这方面的知识。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)