MindSpore学习实践——文本解码原理(以MindNLP为例)
昇思打卡营第四期——文本解码
MindSpore学习实践——文本解码原理(以MindNLP为例)
前言
回顾当下decoder结构的大模型(例如GPT-3),输入提示词然后获得输出。现阶段encoder&decoder模型当前主要还是自回归语言模型,它是根据前文预测下一个单词(任务形态为next token prediction)。这种不断预测下一个单词的方式是文本解码,不同的解码方式对于模型文本生成的效果的影响非常大。本次课主要学习文本解码的原理,包括调整temperature等参数的效果以及探讨如何调整可以使模型的文本生成效果更好。
学习内容归纳
-
自回归语言模型
- 一个文本序列的概率分布可以分解为每个词基于其上文的条件概率的乘积如下:
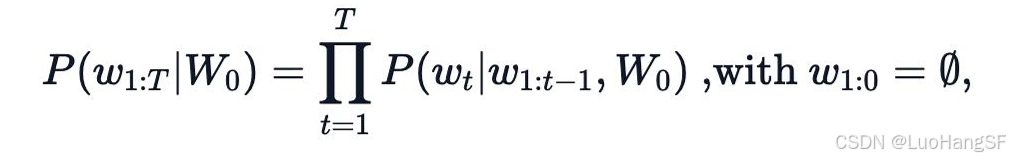
- 其中,W0为初始上下文单词序列,T为时间步,当生成EOS(End of Sequence)标签时,停止生成
-
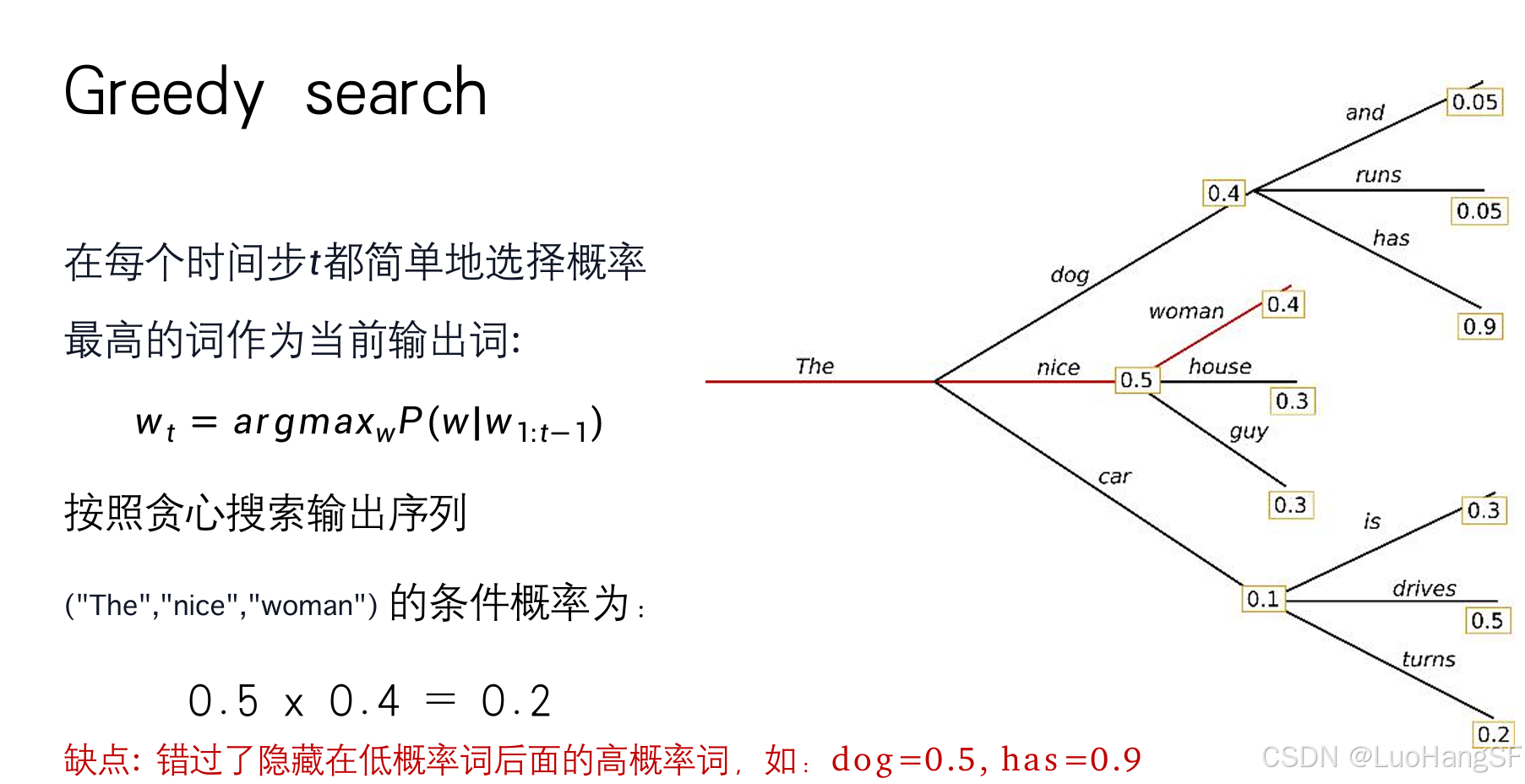
Greedy search(贪心搜索)
- 实现策略:生成token时只会考虑当前token的概率,不会考虑哪个全局生成的最好,即直接取argmax,哪个token的概率最高就预测哪个。
- 如下图,若按照Greedy Search“
The nice house”会被生成,但是纵观全局,会发现“The dog has ...”的概率为0.4 * 0.9 = 0.36,比前者的0.4 * 0.5 = 0.2的概率更高。可见该策略会忽视低概率后面的高概率的词被忽视。也就说说虽然生成的文本没问,但不是最好的,所以一般不使用。
- Beam search(束检索)
- 这个算法通过在每个时间步保留最可能的
num_beams个词,并从中最终选择出概率最高的序列来降低丢失潜在的高概率序列的风险(只是部分解决了Greedy search的问题,由于分支很多,词库体积庞大,分别依次计算不现实)。 - 但它也不是完美的,因为它本身采取search的方式,会导致其无法解决重复问题(使用Beam search它每一个beam生成出来的最后一个结果都是一样的,而greedy search则是每次结果都是一样的),以及开放域生成差的问题(开放域是指让模型生成个故事或一首诗,具有一定创造性的内容,而开放域生成差主要是每次输入输出的结果都一模一样)。
- 这个算法通过在每个时间步保留最可能的
-
Repeat problem(重复问题)的解决方法
- 解决方式简单粗暴:惩罚机制——将上一次出现过的词在下一次生成时的概率强制压低。
- 例如:n-gram惩罚:将前面出现过的候选词的概率设置为0(连续出现几个词就是
几-gram) - 但是实际文本生成还是需要重复出现(比如新闻),所以不能一棒子打死。因此可以让前面生成过的词的概率稍微降低,然后重新进行归一化之后,以后还可以继续生成,不过是在相对远的上下文而不是进的上下文中生成。
-
开放域生成差的问题
- 无论采用greedy search还是beam search预测的结果比较集中,相比之下人类手写的文本波动大、有概率极低的文字出现,缺乏了多样性。
- 可以使用采样的方式得到多样化的结果:不选择概率最高的那一个,而是随机从分布上取值。其优点及其明显:文本生成的多样性高,只要随机的种子不同就可以保证生成出来的文本不一样。但是其生成的文本可能有问题:比如大模型可能一本正经地胡说八道,这个是在于大模型计算的时候会非常地准确,其生成的结果看起来是人话,但内容可能有不准确的问题。
-
Temperature
- 我们可以通过降低softmax的tempreature使得 P(W∣w1:t−1)P(W | w_{1:t-1})P(W∣w1:t−1) 的分布更陡峭,使得高概率的似然并降低低概率单词的似然。由于采样存在随机性,但是有时候我们往往期望得到概率高的。显示生活中,我们需要文本的生成具有一定的随机性,但又不完全随机。这时我们就要调用temperature来调整,当temperature较大时,随机性较高;而temperature接近0的时候,采样会变成跟greedy search相同的效果。一般情况下,temperature会被设成0.7或0.8 。
-
主流的方法之一:TopK
- 之前采样都是在所有词的词表中,这个表中一部分单词的概率较高,其余的词概率则非常小,若在这个词中采样,则有可能使得模型的生成效果不好(胡说八道)。
- TopK方法是将所有词softmax之后选出概率最大的K个词,然后再在这K个词中采样,可以使得模型的生成会在相对理想的范围内而又不失创造性。
- 但是其在将采样池限制为固定大小时存在局限性:在分布比较平坦的时候会限制模型的创造力,但是在分布比较尖锐的时候又会产生胡言乱语的问题。
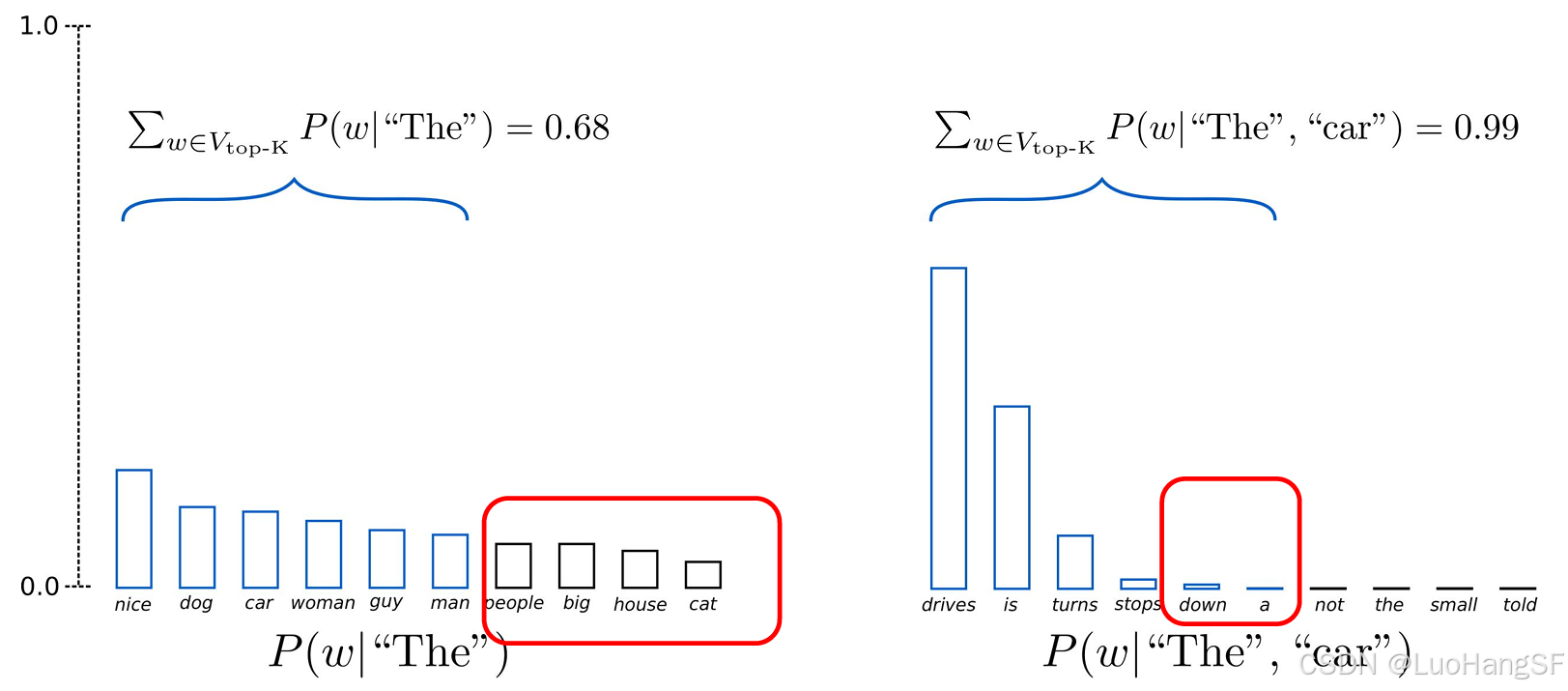
- 所以只使用TopK生成的文本效果比后面讲得TopP差一些。
-
主流的方法之二:TopP
- 采用累计概率的方法,即取累计概率大于某个值p的词进入采样池来采样。这样情况下在分布比较平坦的情况下采样池会取尽可能多的词,而分布比较尖锐的时候就会取概率比较高的几个词。每次预测token的时候,采样池取词的数量是可以变化的(根据下一个词的概率分布动态增加和减小)。这是一个效果比较好的采样方式。
- 一般情况下p会设置得比较大(0.9、0.95甚至0.99),这样可以尽量使得想要拿到的概率较大的词都进入采样池,让其多样性变得更佳。若本身的预测比较平坦时,可以让p设置得小一些降低其多样性而增加其确定性。
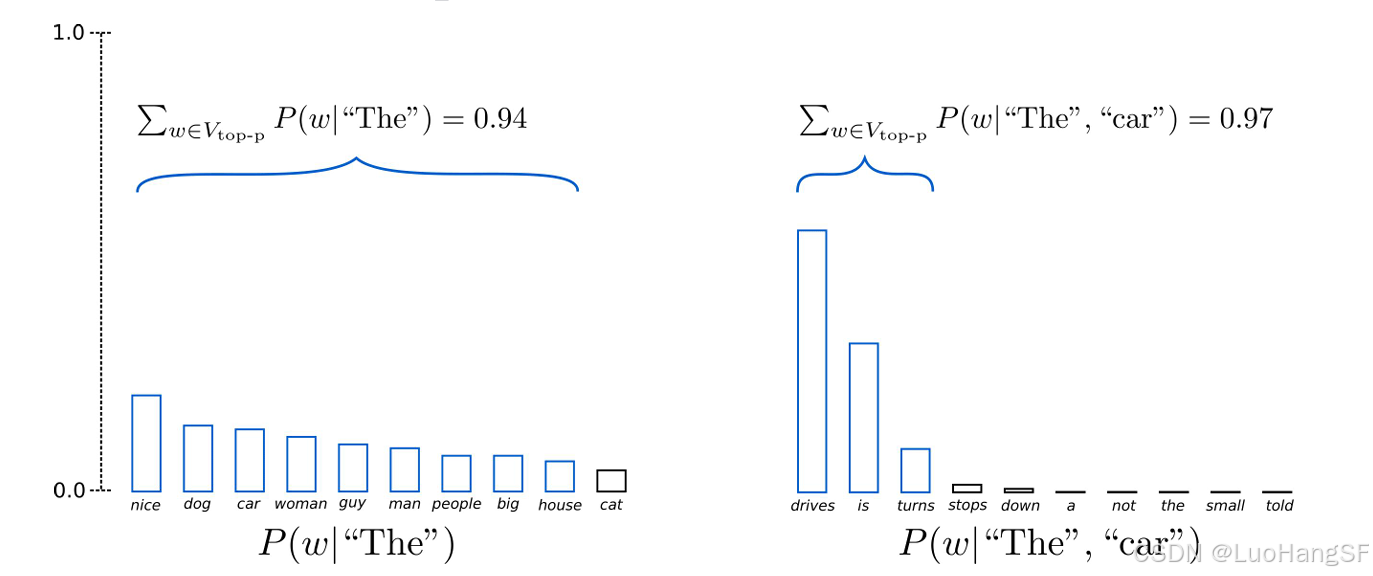
- 实际上我们会将TopP和TopK一起联合使用,根据实际状况调整。
-
一般情况下我们需要根据具体的情况去调整,如果想要生成唯一解(比如翻译或者解数学题)时就需要使用search保证确定性;而想要文本生成时使用采样可以确保多样性。
-
指定文本生成内容
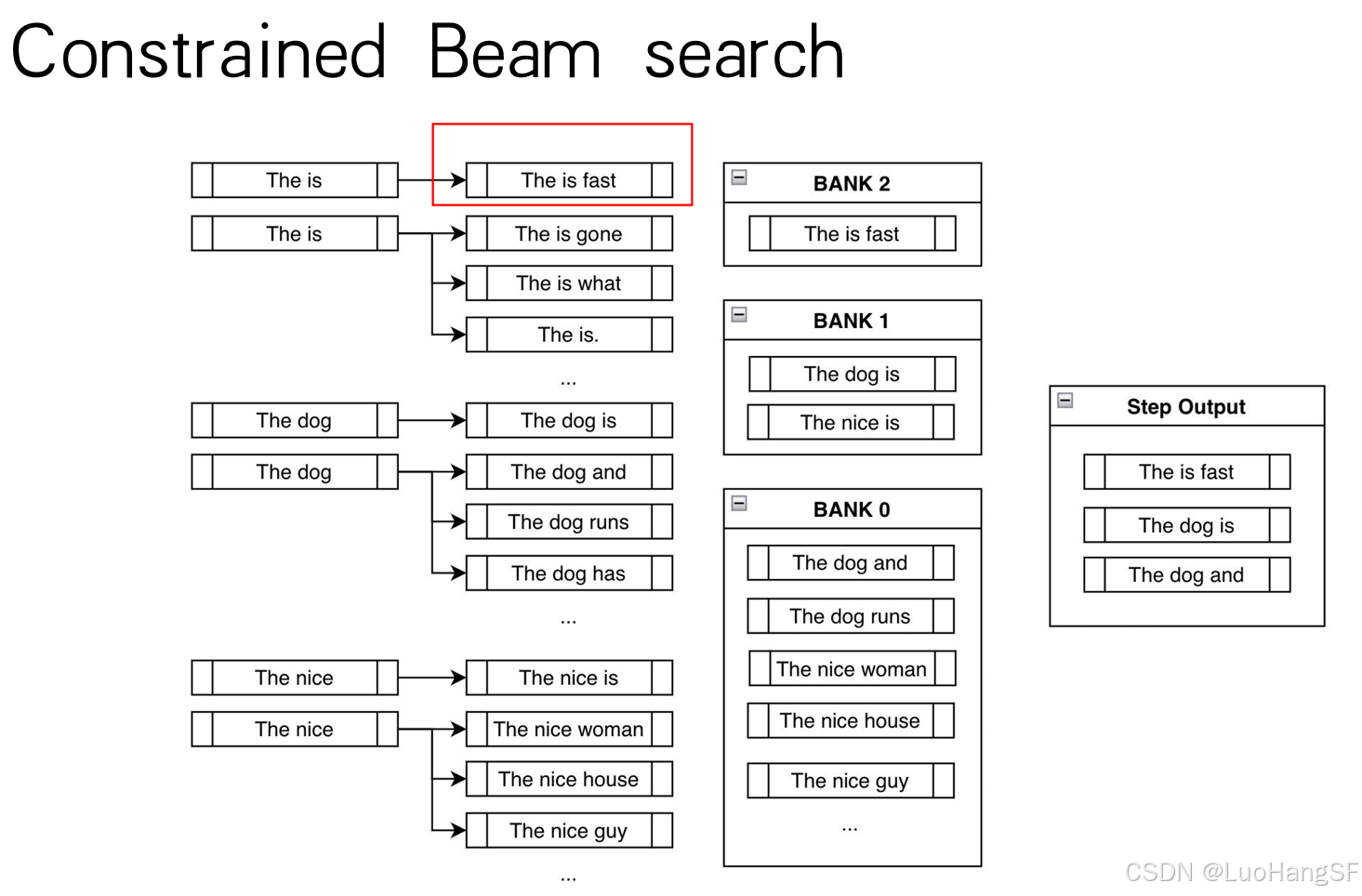
- 当你需要模型生成的文本需要以特定的格式或词生成时(比如专业术语的词汇),即当遇到这个词的时候需要将其转化成特定的词而不是概率最高的那个词的情况,该使用什么方法呢?
- 这时就要使用到Contrained Beam search了,相比于传统Beam search,Contrained Beam search预埋了一些词(即条件限制),一定程度上让其概率变得很高,让其一定能生成出来。
-
对比解码
-
对于现有的解码方法,使用确定性方法(Greedy search以及Beam search)时,会存在生成的文本不自然且包含不必要的重复的问题;而使用不确定性方法(Top-K&Top-P)时,会产生生成文本的语义一致性问题。
-
我们引入Contrative Search(对比搜索):

-
-
LLM快速文本生成
- 我们每次生成token时,算力成本非常高,但是我们存储的文本却不高。但是可能在同时或者未来有人给予了模型同样一个问题并且希望获得相同的答案。显然,多次重复处理同一个问题是浪费算力资源的。
- 我们引入辅助预测模型(assistant model,一种小模型):加入另外一个文本时先去识别一下是否与先前生成的结果匹配,若匹配,则直接将先前生成的结果交付;若不匹配,则让大模型走生成流程去生成。
- 这样可以提高生成效率并提高降低使用成本。
代码实训
- 环境准备
#安装mindnlp 0.4.0套件
!pip install mindnlp==0.4.0
!pip uninstall soundfile -y
!pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.3.1/MindSpore/unified/aarch64/mindspore-2.3.1-cp39-cp39-linux_aarch64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
#安装NLP
!pip install mindnlp-0.4.0-py3-none-any.whl # 将安装mindnlp版本更换为mindnlp-0.4.0-py3-none-any.whl(daily版本)
- Greedy search
#greedy_search
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# encode context the generation is conditioned on
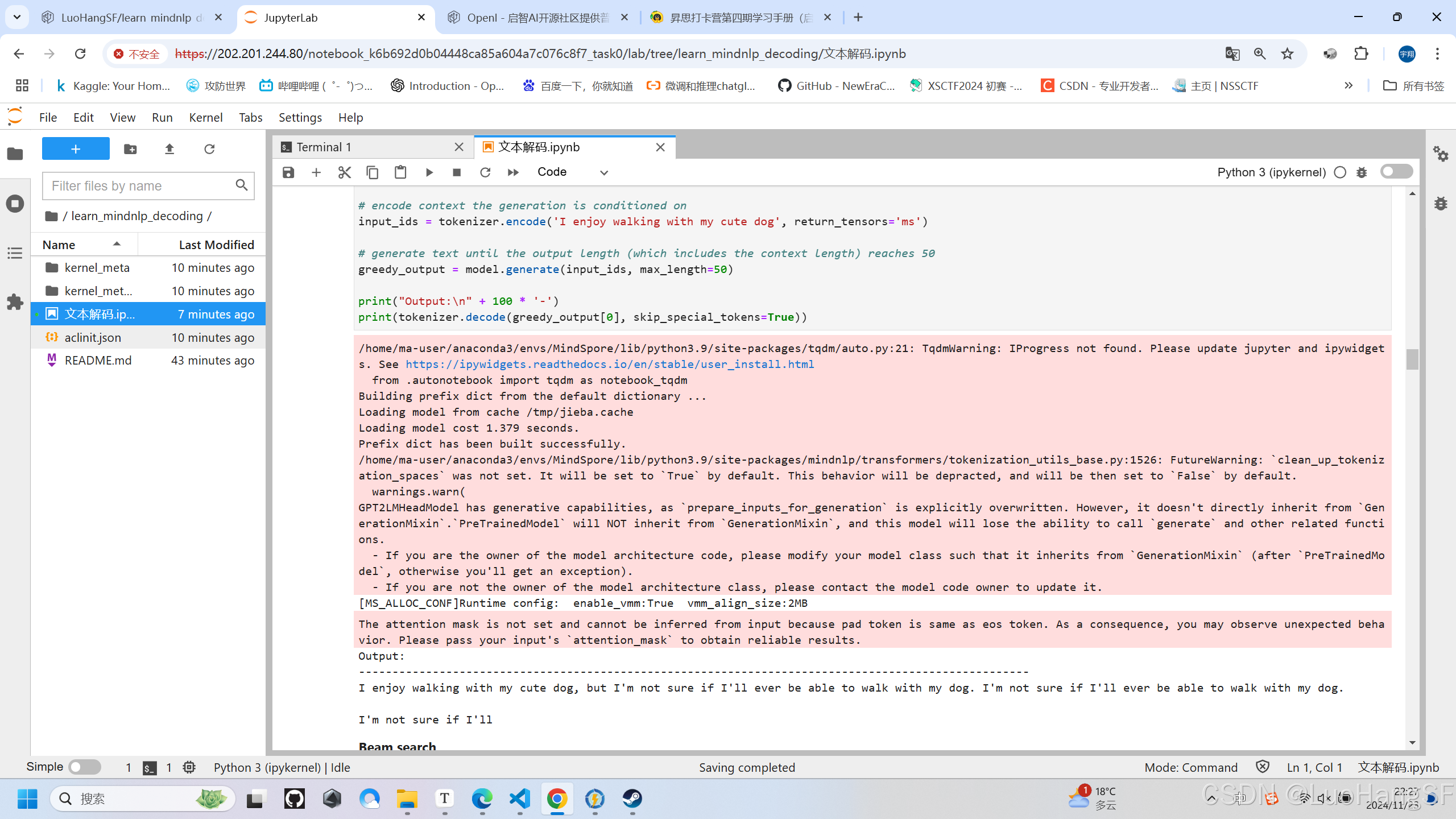
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
# generate text until the output length (which includes the context length) reaches 50
greedy_output = model.generate(input_ids, max_length=50)
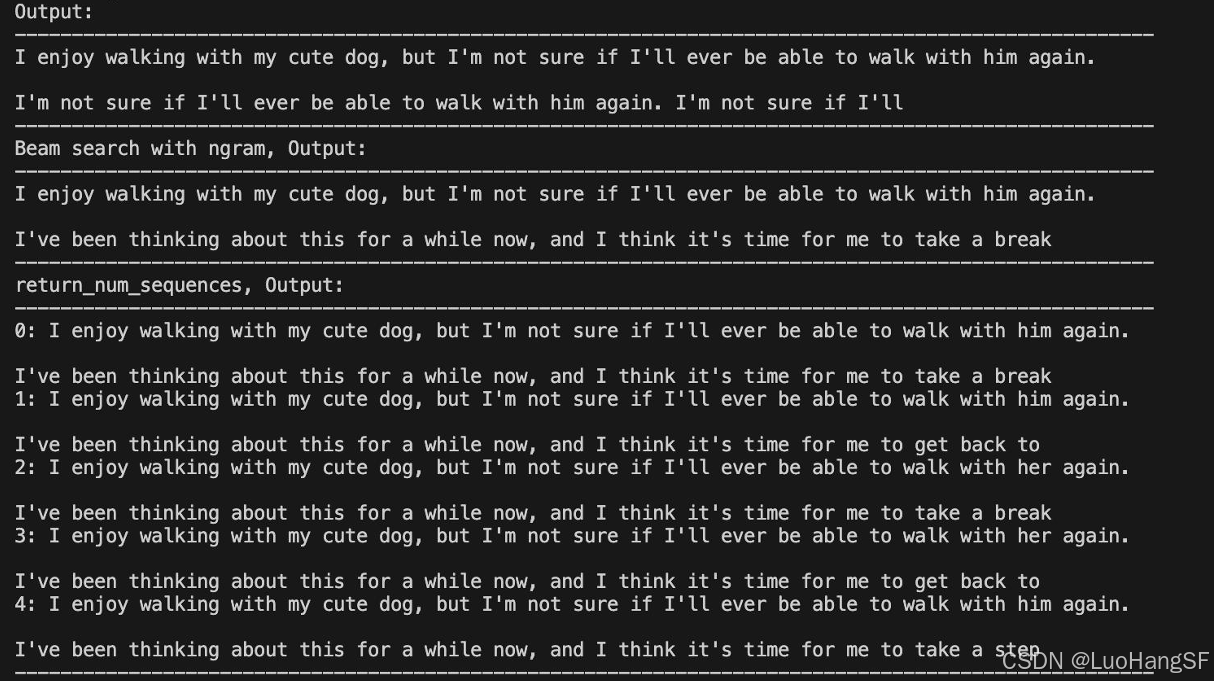
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
实训结果:(结果与课程课件相同,开始重复,直到最大文本生成长度)
- Beam Search
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
# activate beam search and early_stopping
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
print(100 * '-')
# set no_repeat_ngram_size to 2
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
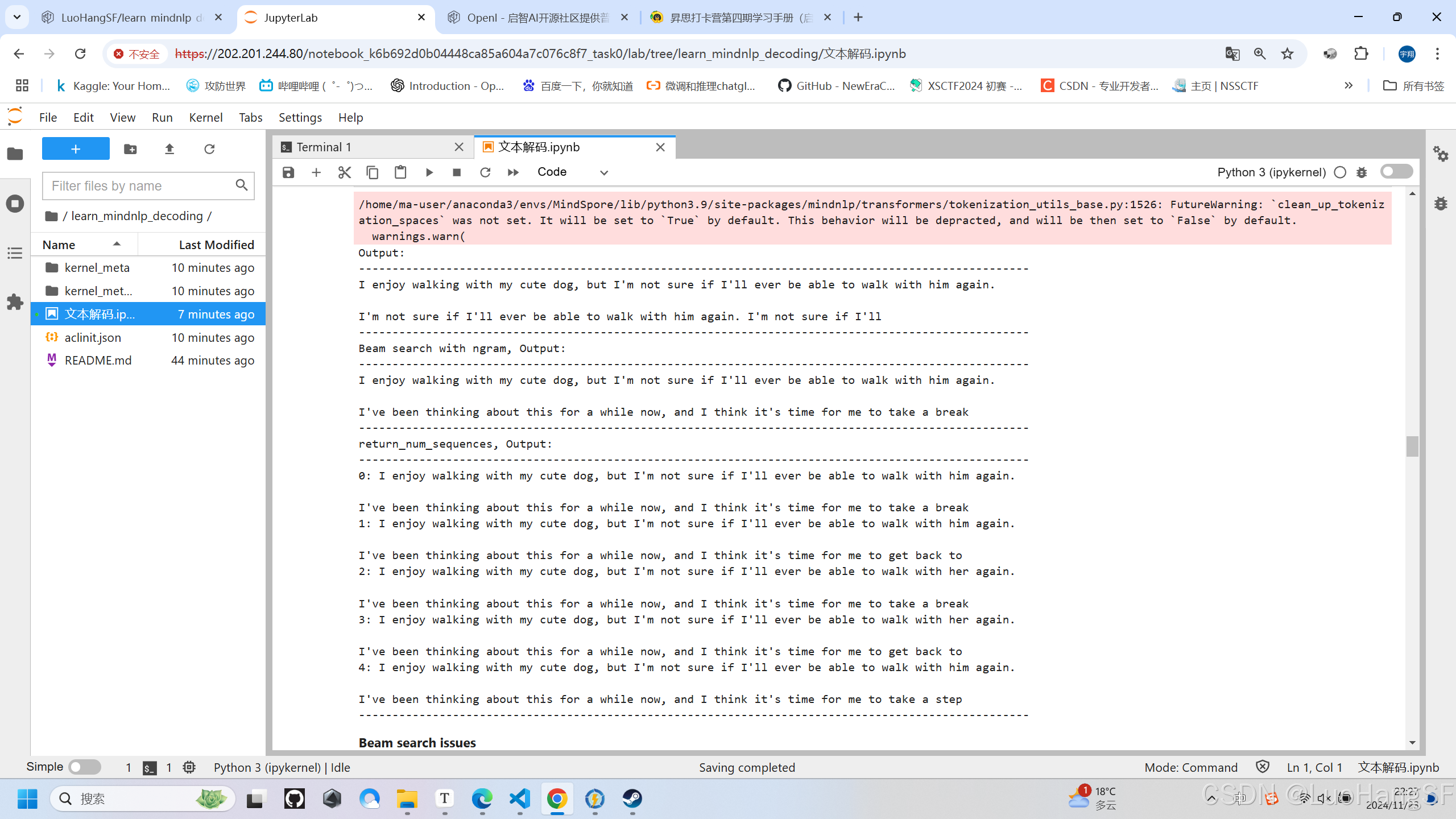
print("Beam search with ngram, Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
print(100 * '-')
# set return_num_sequences > 1
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
# now we have 3 output sequences
print("return_num_sequences, Output:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))
print(100 * '-')
实训结果:(每一个Beam生成的结果都是一样,只有最后一个有略微不同,多样性不足)
- sample方式
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
mindspore.set_seed(0)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
实训结果:(从纯随机的sample,5万1千多的中生成,后面开始胡言乱语)
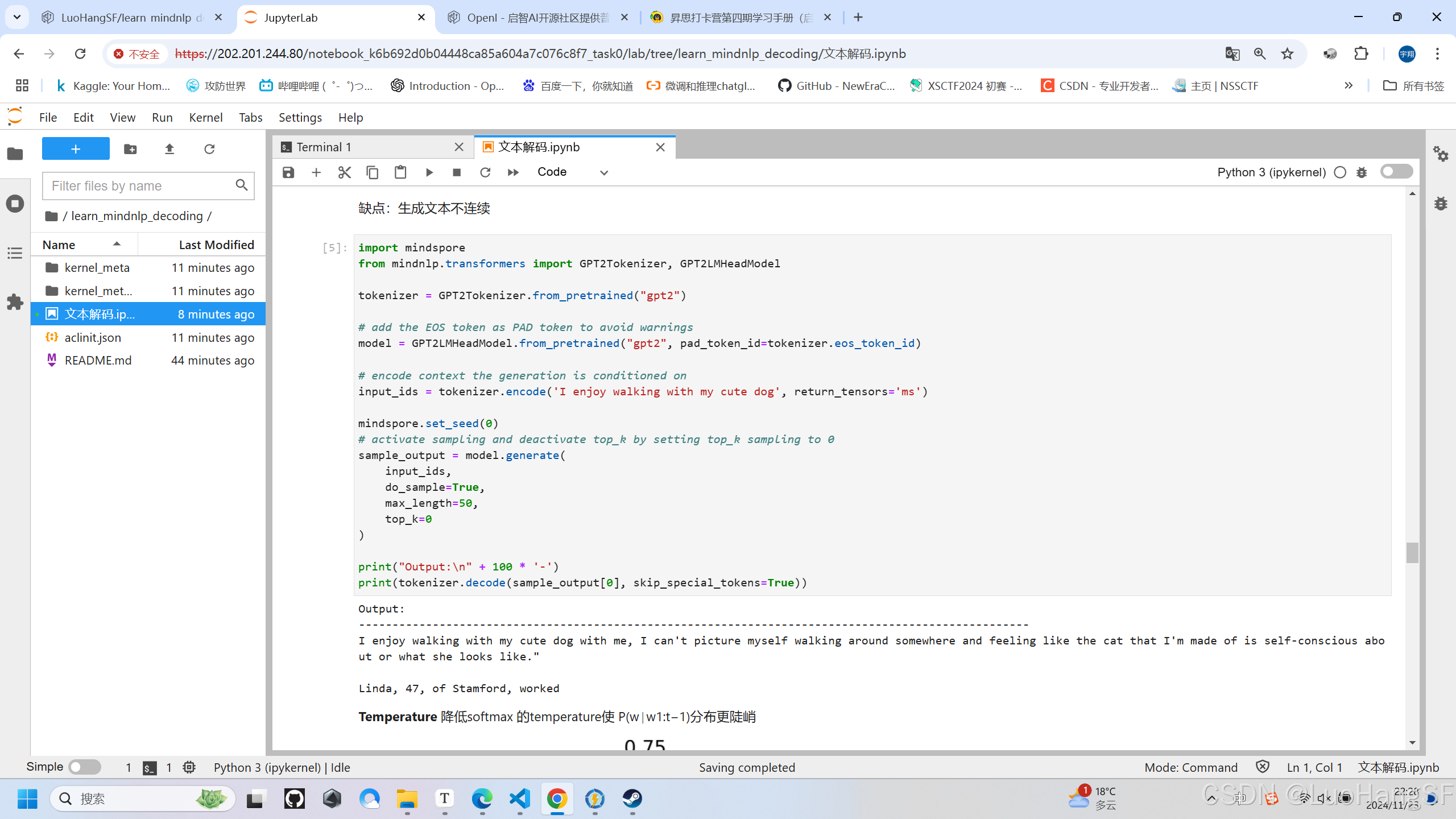
- Temperature
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
mindspore.set_seed(1234)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
实训结果: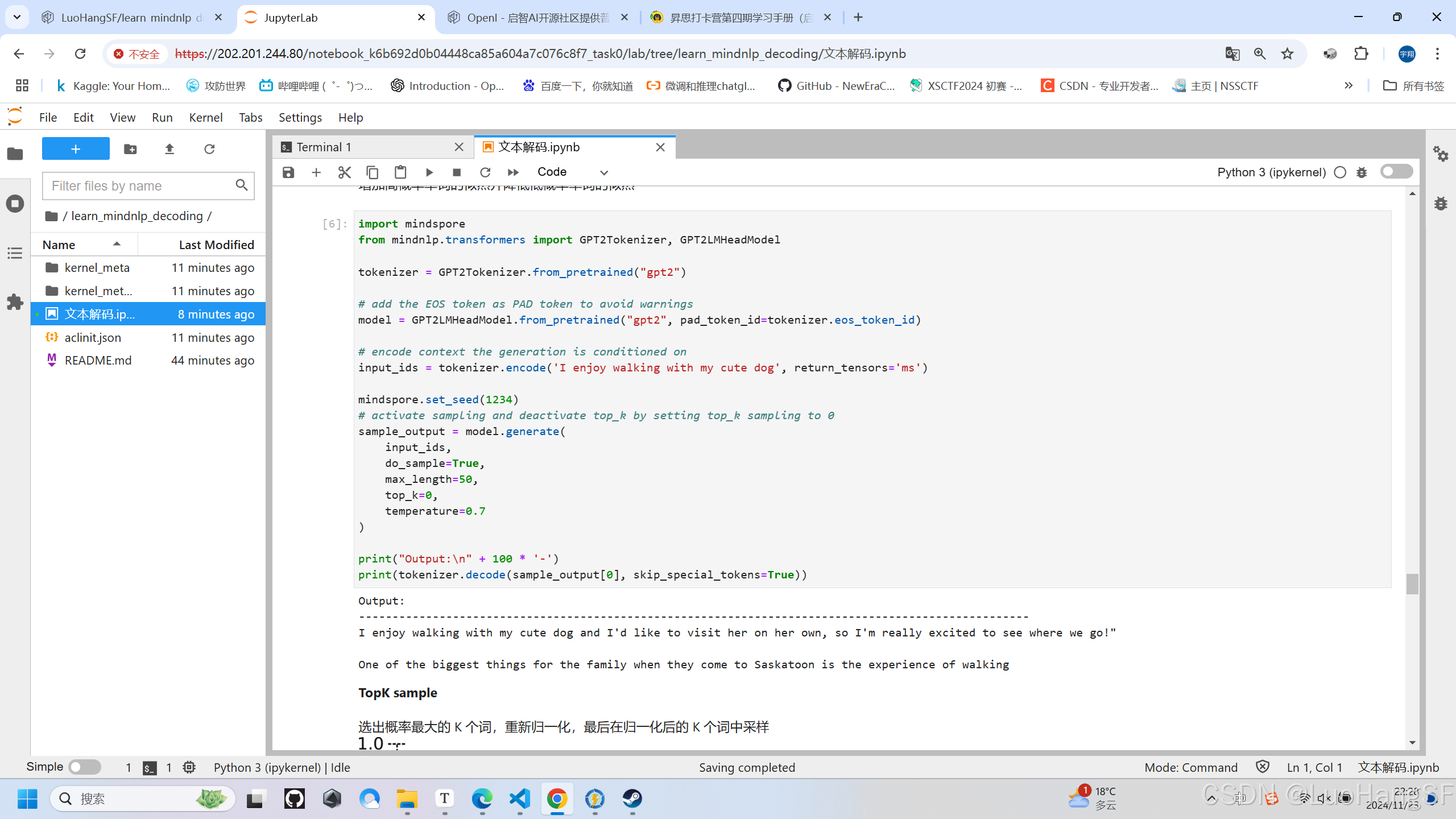
- Top-K方法
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
mindspore.set_seed(0)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
实训结果:(其中Top-K=50,采样起来看起来像人话但效果不佳,主要是把一些该加进去的没加进去,把一些不改加进去的加进去了)
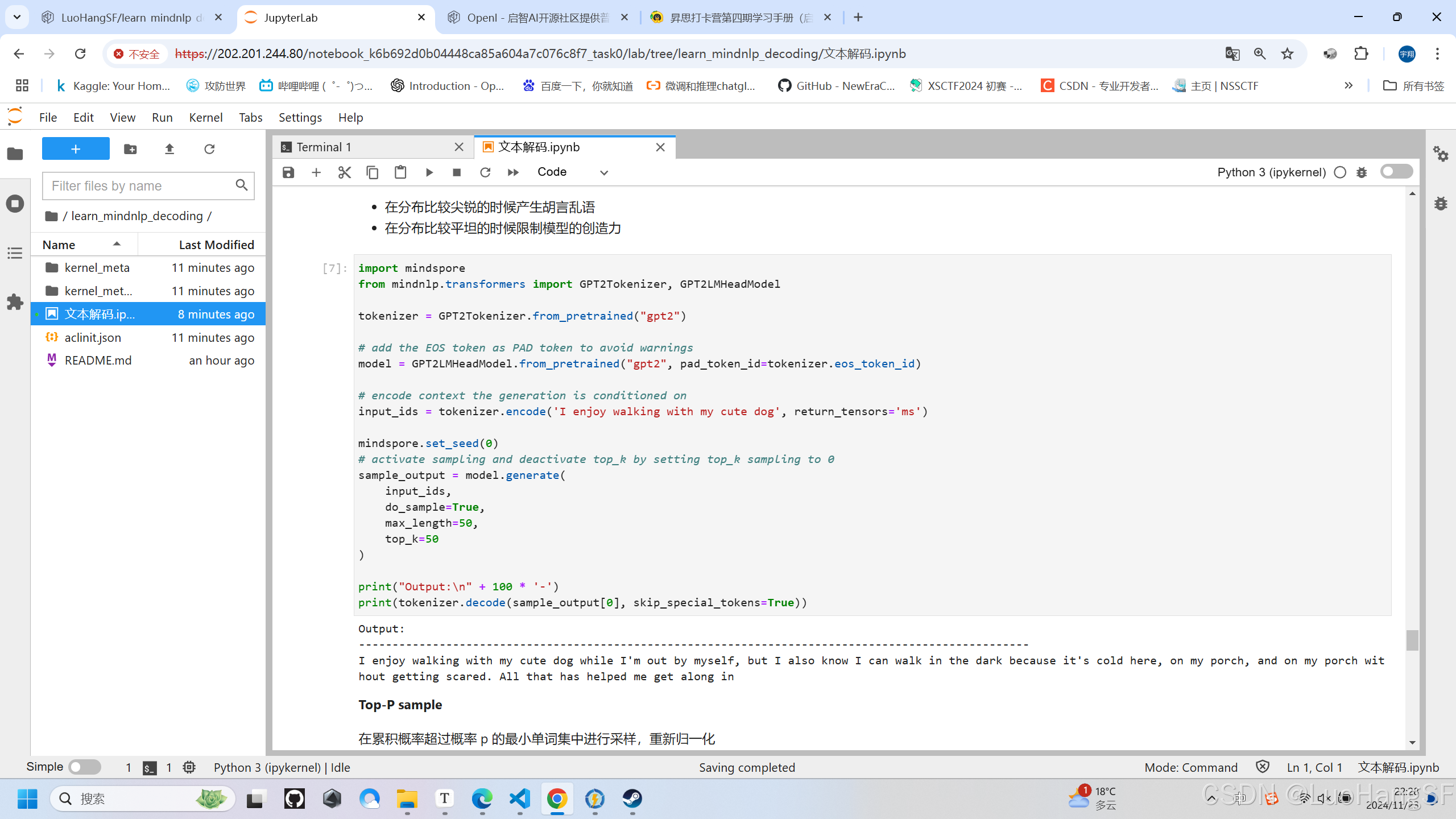
- Top-P方法
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
mindspore.set_seed(0)
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
实训结果:(累计概率为0.92,这是一个相对合适的值,在这个值下效果较为正常;概率调高或调低的时候都有可能导致生成效果不好,很多模型的文本生成效果是通过调整这个值改动)
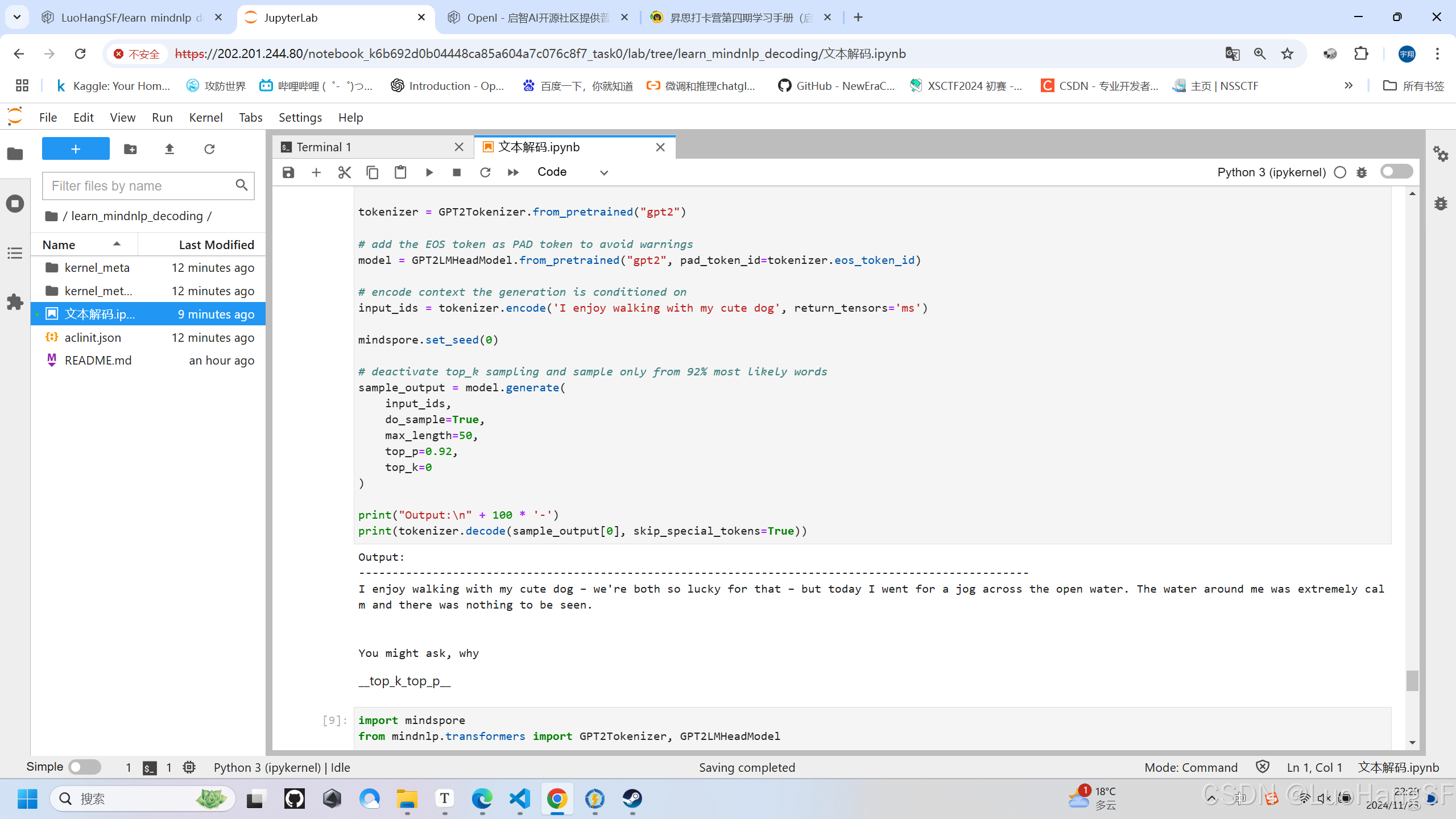
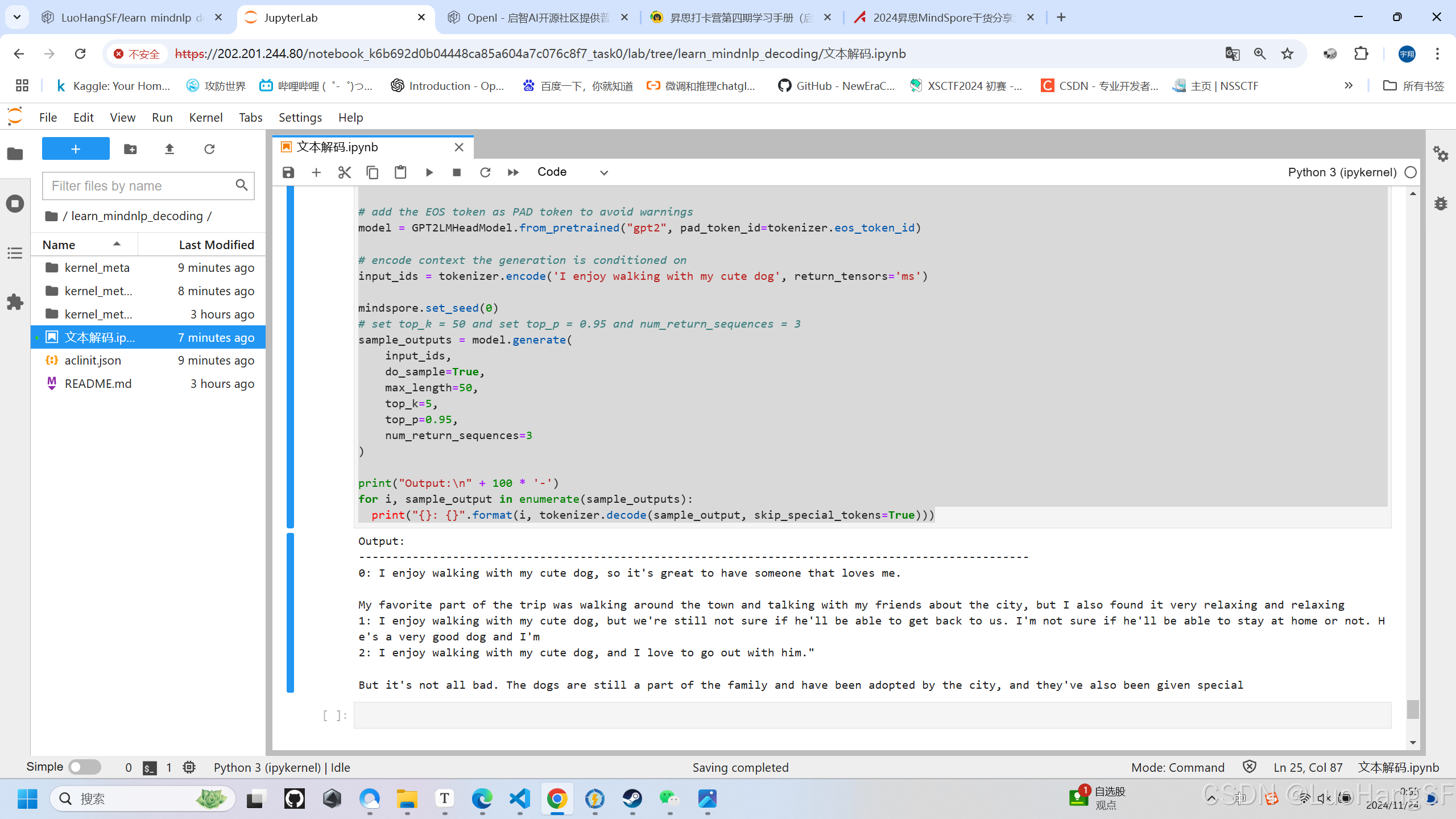
- top-p和top-k联合
import mindspore
from mindnlp.transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='ms')
mindspore.set_seed(0)
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=5,
top_p=0.95,
num_return_sequences=3
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
实训结果:
总结
本节课主要学习了文本解码的原理,包括Greedy search、Beam search、temperature、top-k采样、top-p采样等知识。收获蛮大的,让我对于文本解码有了新的认知。
同时这也是昇思第四期打卡活动的最后一课了,从刚开始的模型迁移到最后的文本解码。我学到了很多,感谢昇思MindSpore能给我这个学习的机会。未来我会继续学习,继续探索昇思MindSpore的开源社区,不断提升自己,早日为开源社区做出自己的贡献。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)