MindSpore模型迁移实践——简单的MNIST分类器
昇思打卡营第四期学习手册(启智特辑)专题一:MindSpore模型迁移零烦恼
MindSpore模型迁移实践——简单的MNIST分类器
本次实践将迁移一个简单的MNIST分类器的训练任务到MindTorch上
-
创建一个项目,上传相应训练代码以及数据集(也可以后续在数据集栏目上传,不过本次迁移项目中本人已经将需要的数据集上传故暂时不需要再自备数据集)
-
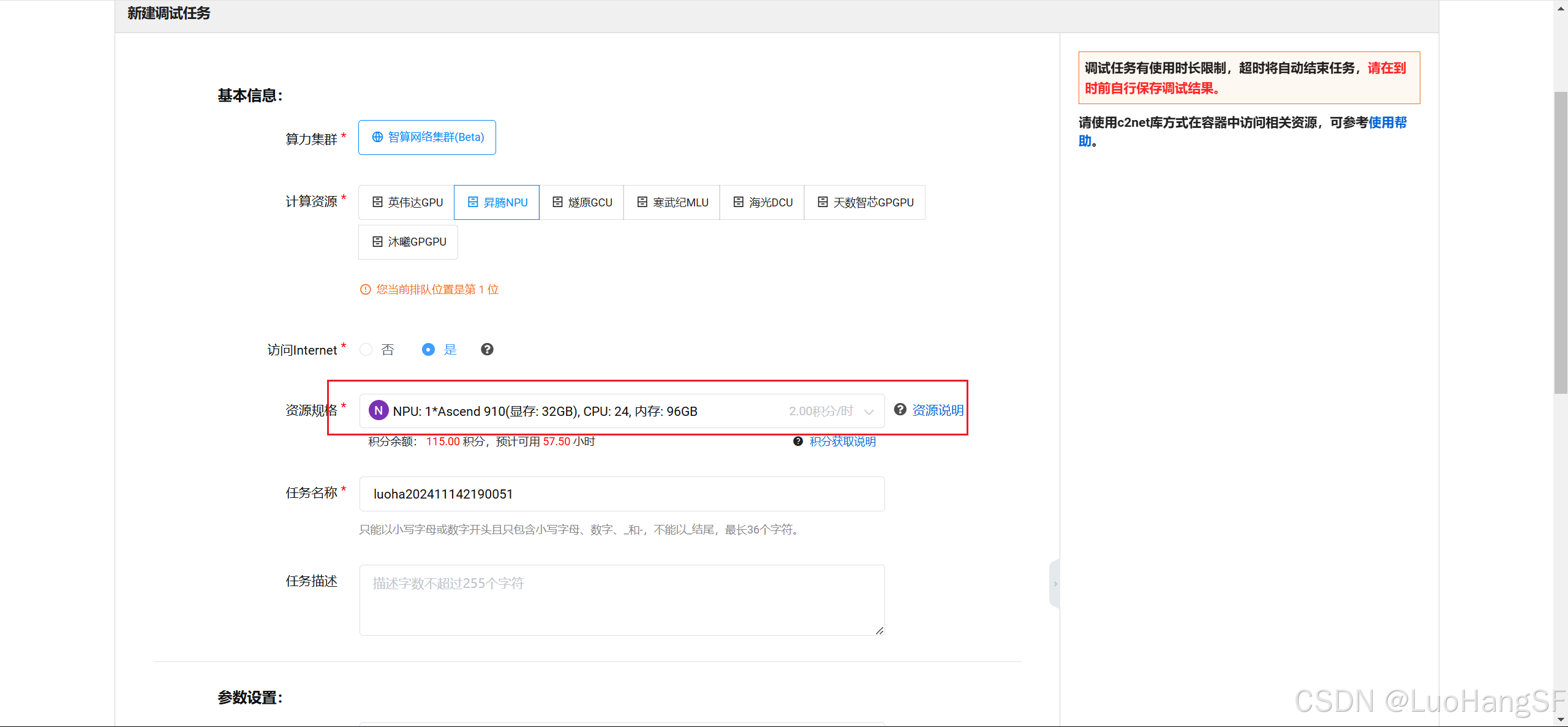
准备好相应训练代码以及数据集后,选择菜单界面的云脑选项,然后选择新建调试任务,在这里面我们选择昇腾NPU并在资源规格上保持默认(只有默认的有MindTorch镜像),下划选项中选择镜像为MindTorch然后在其它选项保持默认的情况下点击新建任务
-
新建的任务加载需要较长时间,完成初始化后点击右侧调试进入调试

-
进入后是一个jupyter notebook,打开一个终端,并在逐行输入下面的命令初始化:
bash
cd /tmp/code/
ll
完成初始化后终端输入“unzip master.zip”以解压调试代码以及数据集
最后再输入以下命令以安装所需要的MindSpore模块包(此命令参考于“OpenI/mindtorch_tutorial/course_code/requirements.sh”详情见:https://openi.pcl.ac.cn/OpenI/mindtorch_tutorial)
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.3.1/MindSpore/unified/aarch64/mindspore-2.3.1-cp39-cp39-linux_aarch64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
-
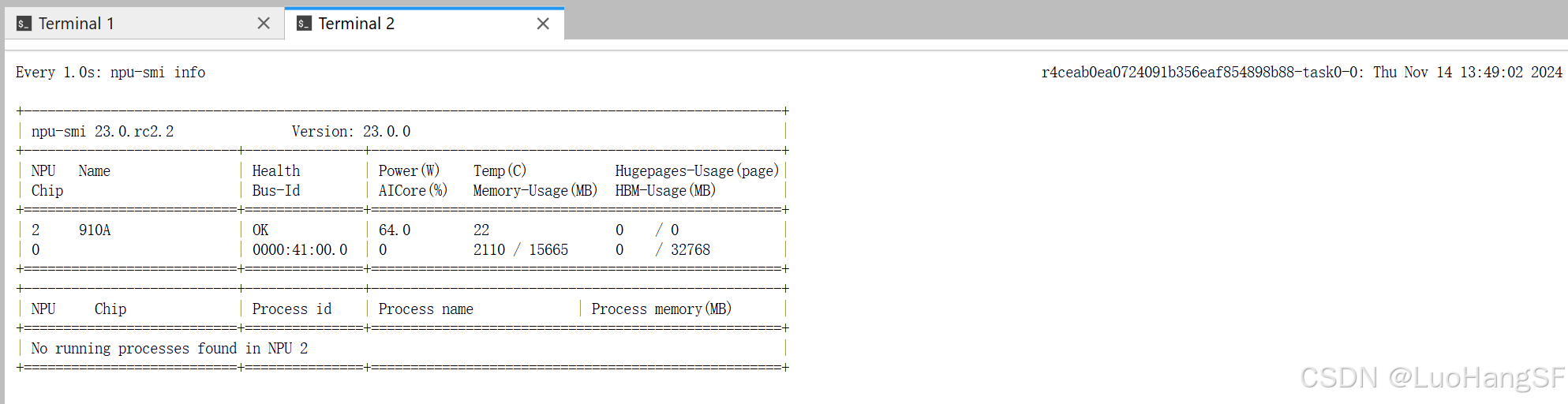
再打开一个新的终端页面,输入
watch -n 1 npu-smi info用于打开NPU资源监测页面,成功后页面应该显示如下: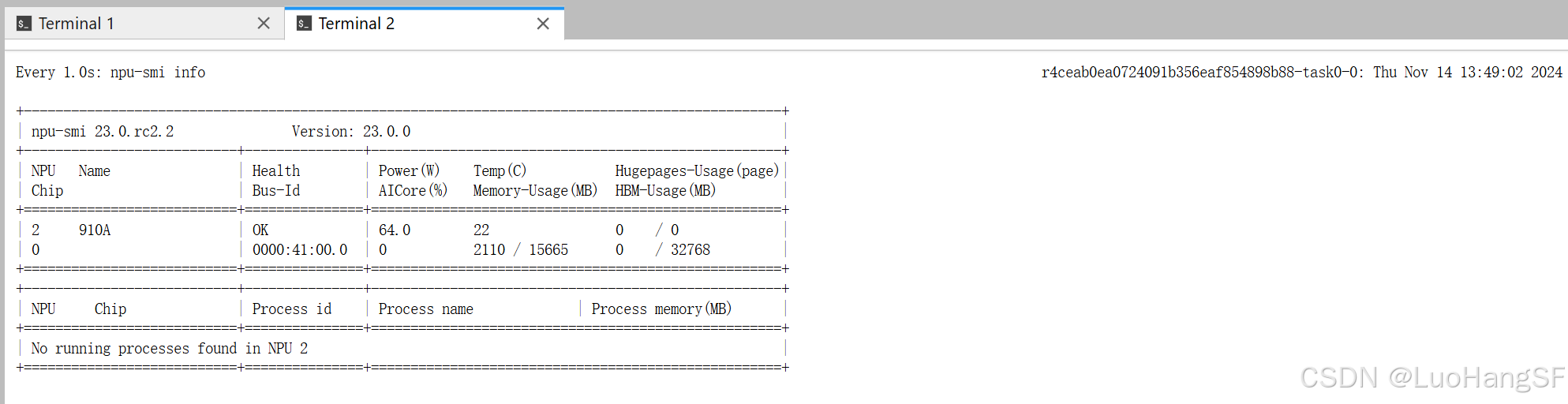
-
打开
MNIST_classification.py文件,这是一个使用Pytorch训练简单MNIST分类器并保存相应模型参数的训练代码。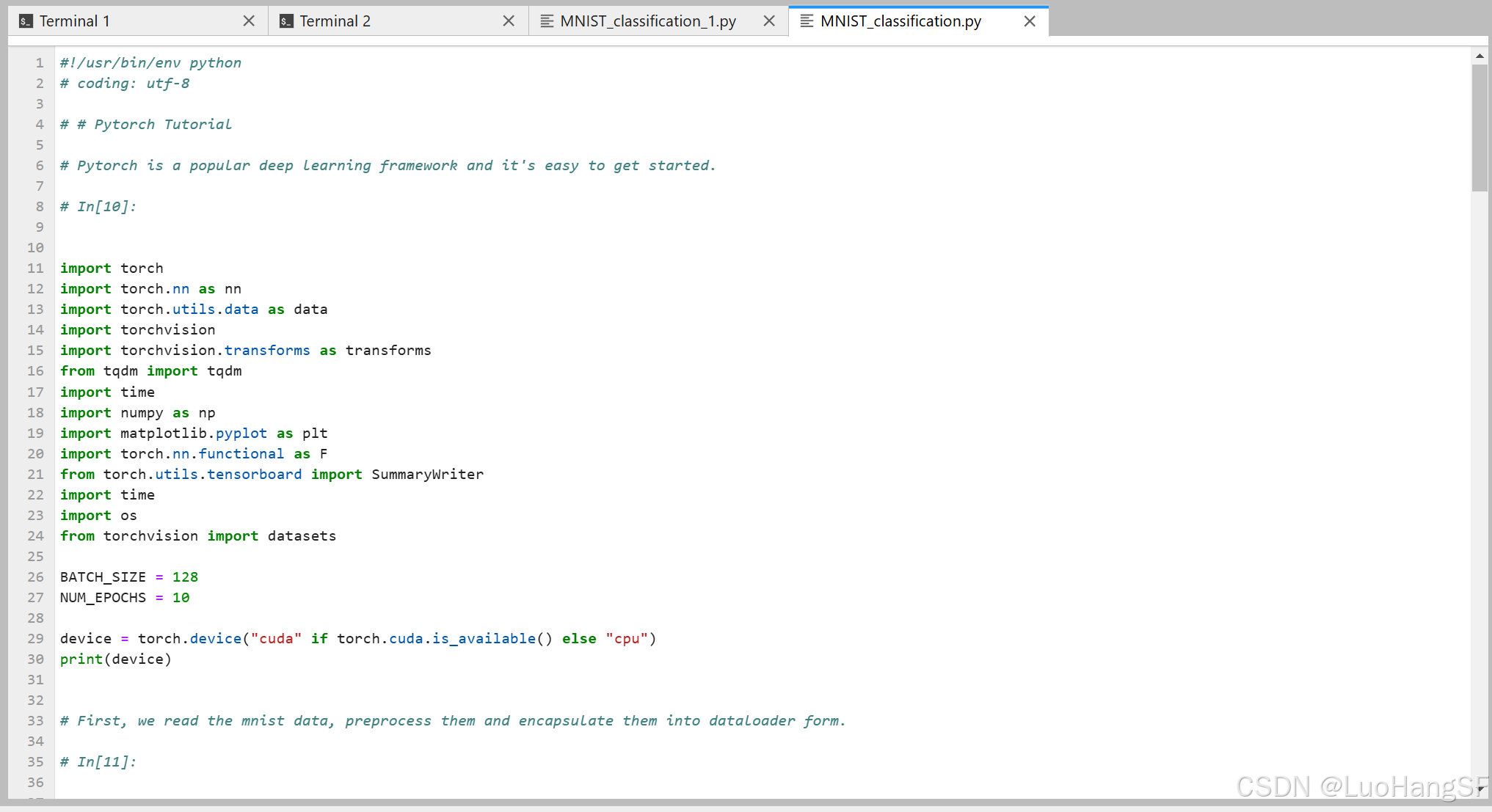
#!/usr/bin/env python # coding: utf-8 # # Pytorch Tutorial # Pytorch is a popular deep learning framework and it's easy to get started. # In[10]: from mindtorch.tools import mstorch_enable import torch import torch.nn as nn import torch.utils.data as data import torchvision import torchvision.transforms as transforms from tqdm import tqdm import time import numpy as np import matplotlib.pyplot as plt import torch.nn.functional as F # from torch.utils.tensorboard import SummaryWriter import time import os from torchvision import datasets from mindtorch.tools import debug_layer_info import mindspore as ms ms.set_context(mode=ms.PYNATIVE_MODE) # os.environ['ENABLE_BACKWARD'] = '1' BATCH_SIZE = 128 NUM_EPOCHS = 10 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(device) # First, we read the mnist data, preprocess them and encapsulate them into dataloader form. # In[11]: # preprocessing normalize = transforms.Normalize(mean=[.5], std=[.5]) transform = transforms.Compose([transforms.ToTensor(), normalize]) # # download and load the data train_dataset = torchvision.datasets.MNIST(root='data', train=True, transform=transform, download=True) test_dataset = torchvision.datasets.MNIST(root='data', train=False, transform=transform, download=False) # # 1.Working with data # # Download training data from open datasets. # training_data = datasets.FashionMNIST(root="data", train=True, download=True, transform=ToTensor()) # # Download test data from open datasets. # test_data = datasets.FashionMNIST(root="data", train=False, download=True, transform=ToTensor()) train_data_size = len(train_dataset) test_data_size = len(test_dataset) # encapsulate them into dataloader form train_loader = data.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True) test_loader = data.DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, drop_last=True) # Then, we define the model, object function and optimizer that we use to classify. # In[15]: class SimpleNet(nn.Module): def __init__(self): super(SimpleNet, self).__init__() self.conv1 = nn.Conv2d(1, 16, 5) self.conv2 = nn.Conv2d(16, 16, 5) self.fc1 = nn.Linear(16*4*4, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(-1, self.num_flat_features(x)) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x def num_flat_features(self, x): size = x.size()[1:] num_features = 1 for s in size: num_features *= s return num_features # TODO:define model model = SimpleNet() model = model.to(device) print(model) # TODO:define loss function and optimiter criterion = nn.CrossEntropyLoss() criterion = criterion.to(device) learning_rate = 1e-2 optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate) # Next, we can start to train and evaluate! # In[13]: total_train_step = 0 total_test_step = 0 # try: # os.remove("./train_logs") # except: # print("没有train_logs文件") # writer = SummaryWriter("./train_logs") start_time = time.time() # In[17]: # train and evaluate NUM_EPOCHS = 10 for epoch in range(NUM_EPOCHS): print("-----epoch{}-----".format(epoch)) model.train() for images, labels in tqdm(train_loader): imgs,targets = images.to(device),labels.to(device) outputs = model(imgs) loss = criterion(outputs,targets) #优化器优化模型 optimizer.zero_grad() loss.backward() optimizer.step() total_train_step += 1 if total_train_step % 100 == 0: print("训练次数:{}, loss: {}".format(total_train_step, loss.item())) # .item()作用是将loss从tensor中取出 end_time = time.time() print(end_time - start_time) # writer.add_scalar("train_loss", loss.item(), total_train_step) # TODO:forward + backward + optimize # evaluate # TODO:calculate the accuracy using traning and testing dataset model.eval() total_test_loss = 0 total_accuracy = 0 with torch.no_grad(): for images, labels in tqdm(test_loader): imgs,targets = images.to(device),labels.to(device) outputs = model(imgs) loss = criterion(outputs,targets) total_test_loss += loss.item() accuracy = (outputs.argmax(1) == targets).sum() total_accuracy += accuracy.item() print("整体测试集上的loss: {}".format(total_test_loss)) print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size)) # writer.add_scalar("test_loss", total_test_loss, total_test_step) # writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step) total_test_step += 1 # torch.save(model, "MNIST_{}.pth".format(epoch + 1)) torch.save(model.state_dict(), "MNIST_{}.pth".format(epoch + 1)) print("第{}轮模型已保存".format(epoch + 1)) # writer.close()
-
本次训练不使用tensorboard查看训练相关的细节,故有关tensorboard的代码将会被注释。再者我们将数据集的位置定位到data文件夹中,以便不用重复下载数据集直接开始训练。
-
- 我们先尝试在不使用MindTorch直接运行代码,在刚开始打开的终端输入
cd mnist_ms将位置改为训练代码所在的文件夹,然后输入python MNIST_classification.py - 发现调试环境缺失torchvision等模块,使用pip安装即可
- 我们先尝试在不使用MindTorch直接运行代码,在刚开始打开的终端输入
-
再次运行代码,这次成功运行了,可以发现使用的是cpu运行,训练效率较低
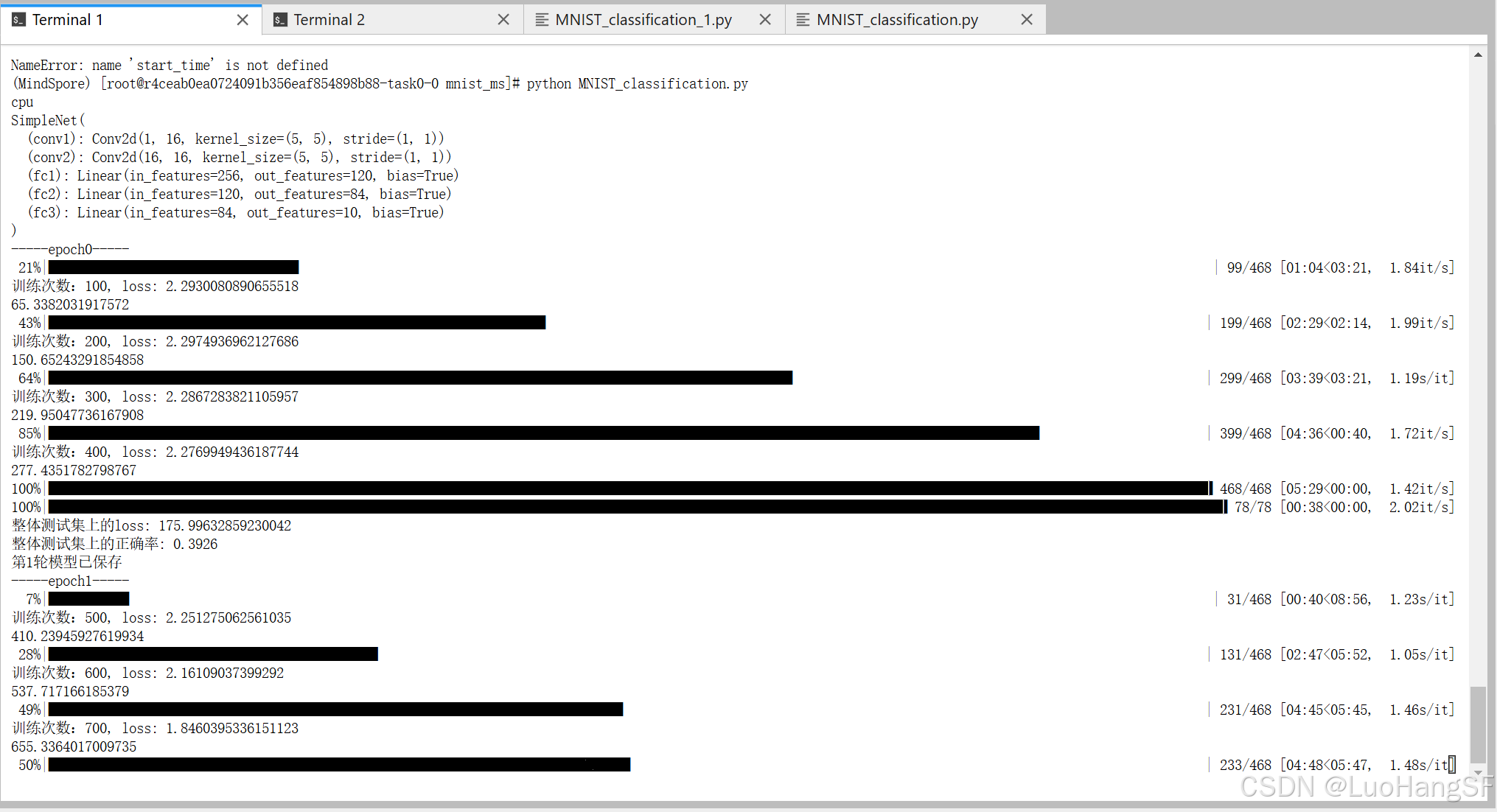
- 尝试将模型迁移至Mindtorch上训练,在代码前面输入
from mindtorch.tools import mstorch_enable用于迁移至MindTorch上使用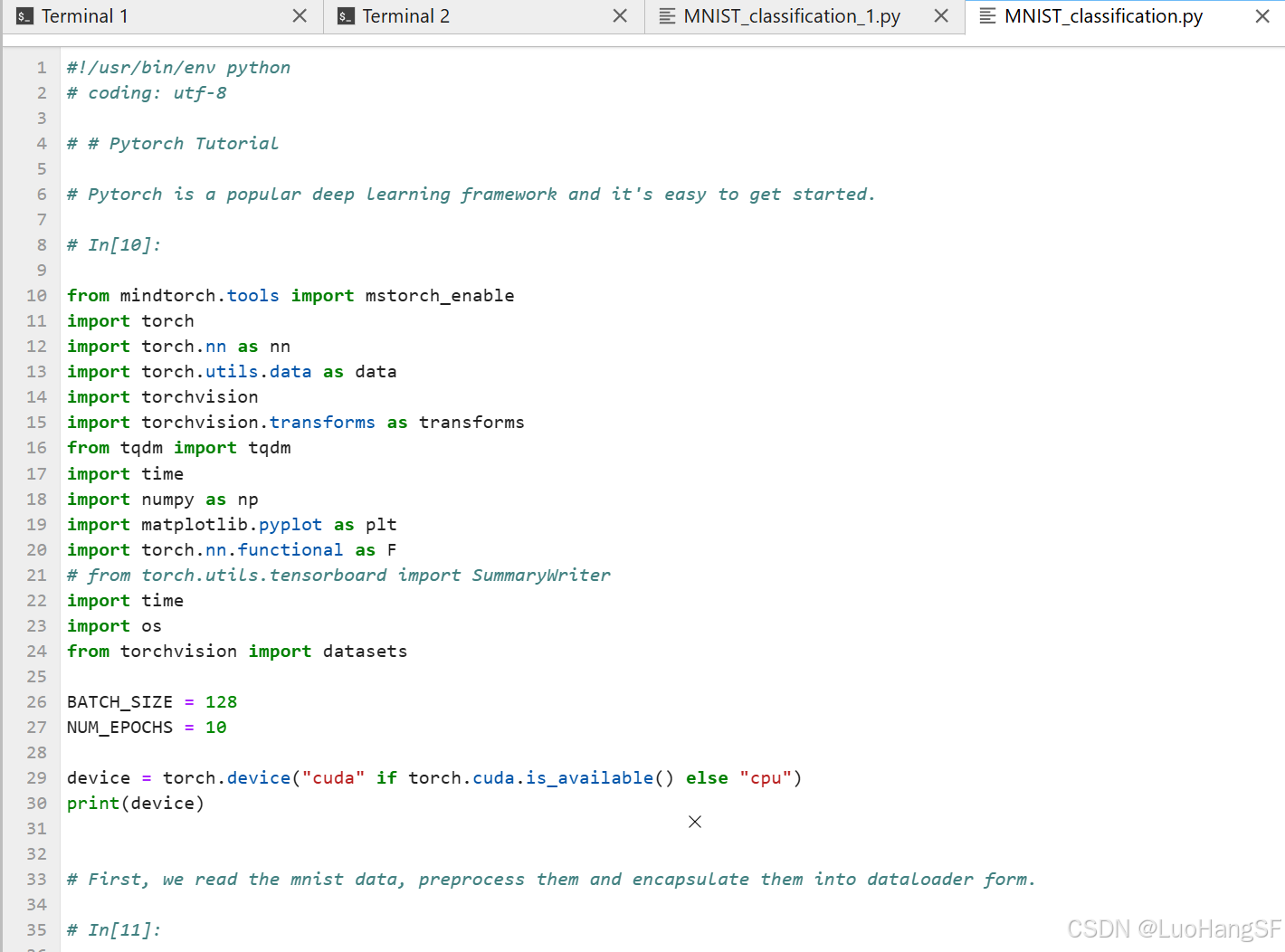
-
-
再次运行代码,发现可以使用cuda,昇腾的NPU此时有负载,且训练的效率得到提升,但是再次发生了报错:当前使用的
torch.save(model, "MNIST_{}.pth".format(epoch + 1))方法不支持保存整个模型。需要使用torch.save(model.state_dict(), "MNIST_{}.pth".format(epoch + 1))来保存模型参数。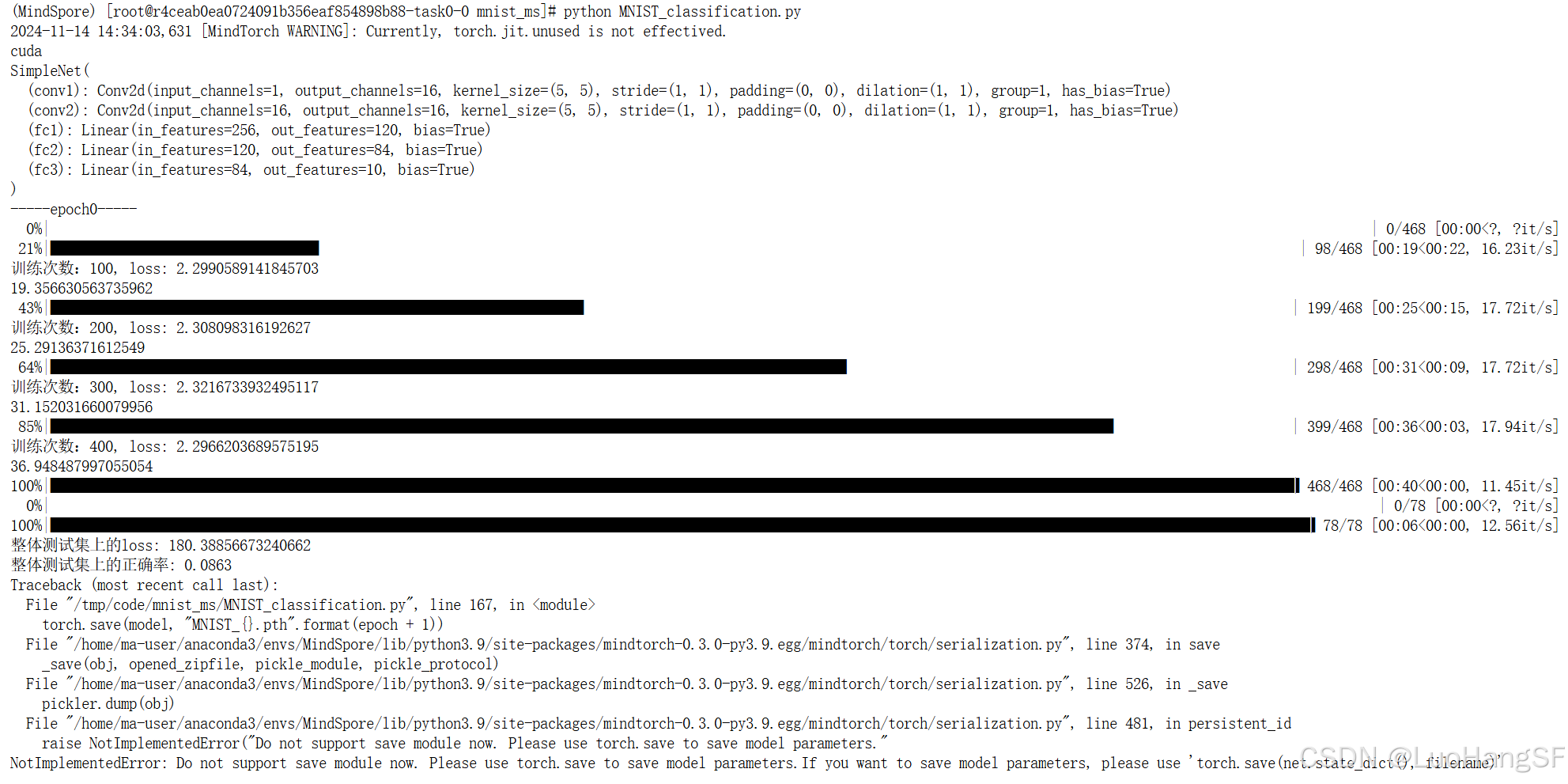
-
修改之后再次运行,这下模型可以训练了
- 但是又遇到了问题,发现训练时不收敛,即每次训练的loss以及测试集上的正确率都保持不变
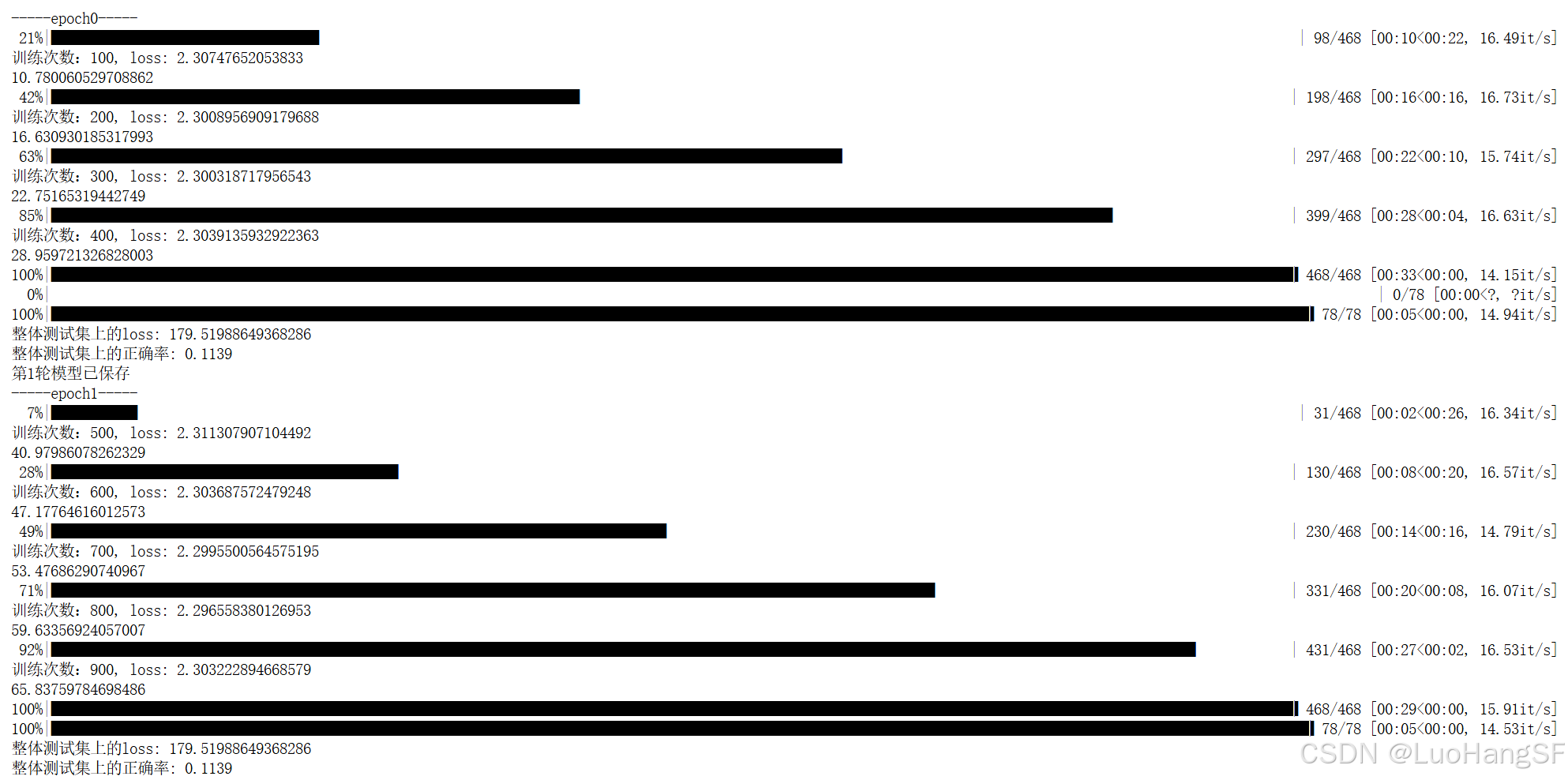
推测是优化器的问题,于是重新去看课程视频发现在模型训练过程中发现代码的训练有两种方式,第一种使用MindSpore的微分,第二种就是保留tensor backward并直接迁移。

但最后测试发现采用第二种方式无法将模型收敛,于是决定修改训练方式为MindSpore微分,修改后训练部分的代码如下:
-
# train and evaluate
NUM_EPOCHS = 10
# 定义前向传播函数
def forward_fn(imgs, label):
logits = model(imgs)
loss = criterion(logits, label)
return loss, logits
# 定义计算损失和梯度的函数
grad_fn = ms.ops.value_and_grad(forward_fn, None, model.trainable_params(), has_aux=True)
for epoch in range(NUM_EPOCHS):
print("-----epoch{}-----".format(epoch))
model.train()
for images, labels in tqdm(train_loader):
imgs, labels = images.to(device),labels.to(device)
# 计算损失和梯度
(loss, _), grads = grad_fn(imgs, labels)
# 更新参数
optimizer(grads)
#===========================================================
# imgs,targets = images.to(device),labels.to(device)
# outputs = model(imgs)
# loss = criterion(outputs,targets)
# #优化器优化模型(原本代码,已弃置)
# optimizer.zero_grad()
# loss.backward()
# optimizer.step()
#===========================================================
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{}, loss: {}".format(total_train_step, loss.asnumpy())) # .item()作用是将loss从tensor中取出
end_time = time.time()
print(end_time - start_time)
# TODO:forward + backward + optimize
# evaluate
# TODO:calculate the accuracy using traning and testing dataset
model.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for images, labels in tqdm(test_loader):
imgs,targets = images.to(device),labels.to(device)
outputs = model(imgs)
loss = criterion(outputs,targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy.item()
print("整体测试集上的loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size))
total_test_step += 1
# torch.save(model, "MNIST_{}.pth".format(epoch + 1))
torch.save(model.state_dict(), "MNIST_{}.pth".format(epoch + 1))
print("第{}轮模型已保存".format(epoch + 1))
再次运行代码后发现第一次训练准确率就达到了0.9往上,且看到后续训练时也有所收敛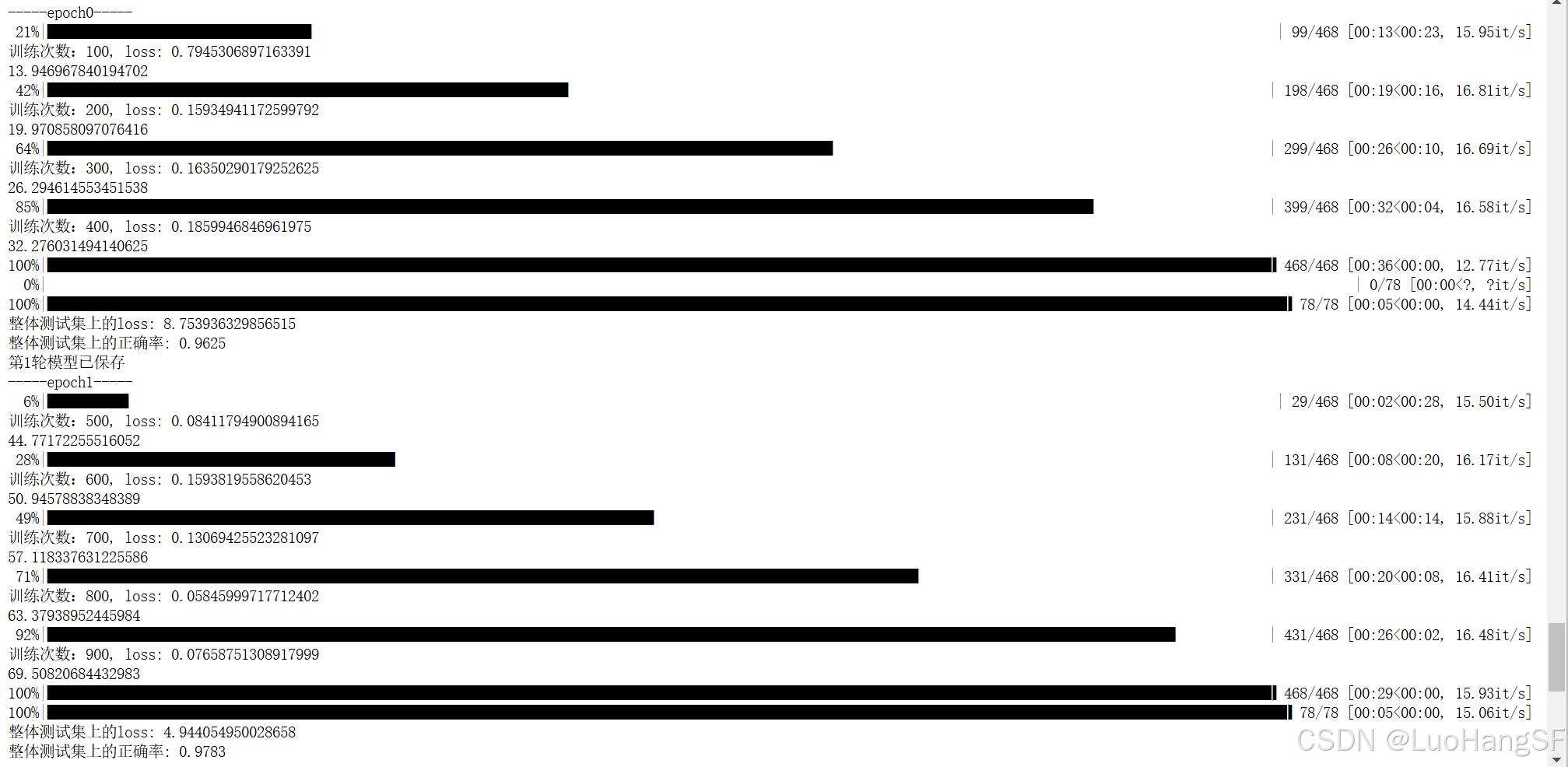
后来向主讲老师询问得知tensor backward在MindSpore2.3.1版本时已经被移除,新版本推荐使用mindspore的写法迁移,还挺有意思的。
最终完整的迁移代码:
#!/usr/bin/env python
# coding: utf-8
# # Pytorch Tutorial
# Pytorch is a popular deep learning framework and it's easy to get started.
# In[10]:
from mindtorch.tools import mstorch_enable
import torch
import torch.nn as nn
import torch.utils.data as data
import torchvision
import torchvision.transforms as transforms
from tqdm import tqdm
import time
import numpy as np
import matplotlib.pyplot as plt
import torch.nn.functional as F
# from torch.utils.tensorboard import SummaryWriter
import time
import os
from torchvision import datasets
from torchvision.transforms.functional import InterpolationMode
import mindspore as ms
import argparse
BATCH_SIZE = 128
NUM_EPOCHS = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# First, we read the mnist data, preprocess them and encapsulate them into dataloader form.
# In[11]:
# preprocessing
normalize = transforms.Normalize(mean=[.5], std=[.5])
transform = transforms.Compose([transforms.ToTensor(), normalize])
# # download and load the data
train_dataset = torchvision.datasets.MNIST(root='data', train=True, transform=transform, download=True)
test_dataset = torchvision.datasets.MNIST(root='data', train=False, transform=transform, download=False)
# # 1.Working with data
# # Download training data from open datasets.
# training_data = datasets.FashionMNIST(root="data", train=True, download=True, transform=ToTensor())
# # Download test data from open datasets.
# test_data = datasets.FashionMNIST(root="data", train=False, download=True, transform=ToTensor())
train_data_size = len(train_dataset)
test_data_size = len(test_dataset)
# encapsulate them into dataloader form
train_loader = data.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
test_loader = data.DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, drop_last=True)
# Then, we define the model, object function and optimizer that we use to classify.
# In[15]:
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.conv1 = nn.Conv2d(1, 16, 5)
self.conv2 = nn.Conv2d(16, 16, 5)
self.fc1 = nn.Linear(16*4*4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:]
num_features = 1
for s in size:
num_features *= s
return num_features
# TODO:define model
model = SimpleNet()
model = model.to(device)
print(model)
# TODO:define loss function and optimiter
criterion = nn.CrossEntropyLoss()
criterion = criterion.to(device)
learning_rate = 1e-2
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate, momentum = 0.9, weight_decay = 0.0005)
# momentom 是为动量项,weight_decay 是L2正则化项,防止过拟合
# Next, we can start to train and evaluate!
# In[13]:
total_train_step = 0
total_test_step = 0
# try:
# os.remove("./train_logs")
# except:
# print("没有train_logs文件")
# writer = SummaryWriter("./train_logs")
start_time = time.time()
# In[17]:
# train and evaluate
NUM_EPOCHS = 10
# 定义前向传播函数
def forward_fn(imgs, label):
logits = model(imgs)
loss = criterion(logits, label)
return loss, logits
# 定义计算损失和梯度的函数
grad_fn = ms.ops.value_and_grad(forward_fn, None, model.trainable_params(), has_aux=True)
for epoch in range(NUM_EPOCHS):
print("-----epoch{}-----".format(epoch))
model.train()
for images, labels in tqdm(train_loader):
imgs, labels = images.to(device),labels.to(device)
# 计算损失和梯度
(loss, _), grads = grad_fn(imgs, labels)
# 更新参数
optimizer(grads)
#===========================================================
# imgs,targets = images.to(device),labels.to(device)
# outputs = model(imgs)
# loss = criterion(outputs,targets)
# #优化器优化模型(原本代码,已弃置)
# optimizer.zero_grad()
# loss.backward()
# optimizer.step()
#===========================================================
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{}, loss: {}".format(total_train_step, loss.asnumpy())) # .item()作用是将loss从tensor中取出
end_time = time.time()
print(end_time - start_time)
# TODO:forward + backward + optimize
# evaluate
# TODO:calculate the accuracy using traning and testing dataset
model.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for images, labels in tqdm(test_loader):
imgs,targets = images.to(device),labels.to(device)
outputs = model(imgs)
loss = criterion(outputs,targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy.item()
print("整体测试集上的loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size))
total_test_step += 1
# torch.save(model, "MNIST_{}.pth".format(epoch + 1))
torch.save(model.state_dict(), "MNIST_{}.pth".format(epoch + 1))
print("第{}轮模型已保存".format(epoch + 1))
至此,历尽曲折,从无到有,完成了一次模型的迁移,虽然过程中遇到了许多困难,但还是收获颇丰,感谢老师的指导。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 48
48 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)