昇思25天学习打卡营第21天|xkd007|LLM原理和实践(4)文本解码原理--以MindNLP为例
根据前文预测下一个单词。(本文介绍几种选取预测词的方法,及其优缺点)一个文本序列的概率分布可以分解为每个词基于其上文的条件概率的乘积MindNLP/huggingface Transformers提供的文本生成方法在每个时间步𝑡都简单地选择概率最高的词作为当前输出词:按照贪心搜索输出序列("The","nice","woman") 的条件概率为:0.5 x 0.4 = 0.2缺点: 错过了隐藏在
自回归语言模型
1 原理
根据前文预测下一个单词。(本文介绍几种选取预测词的方法,及其优缺点)
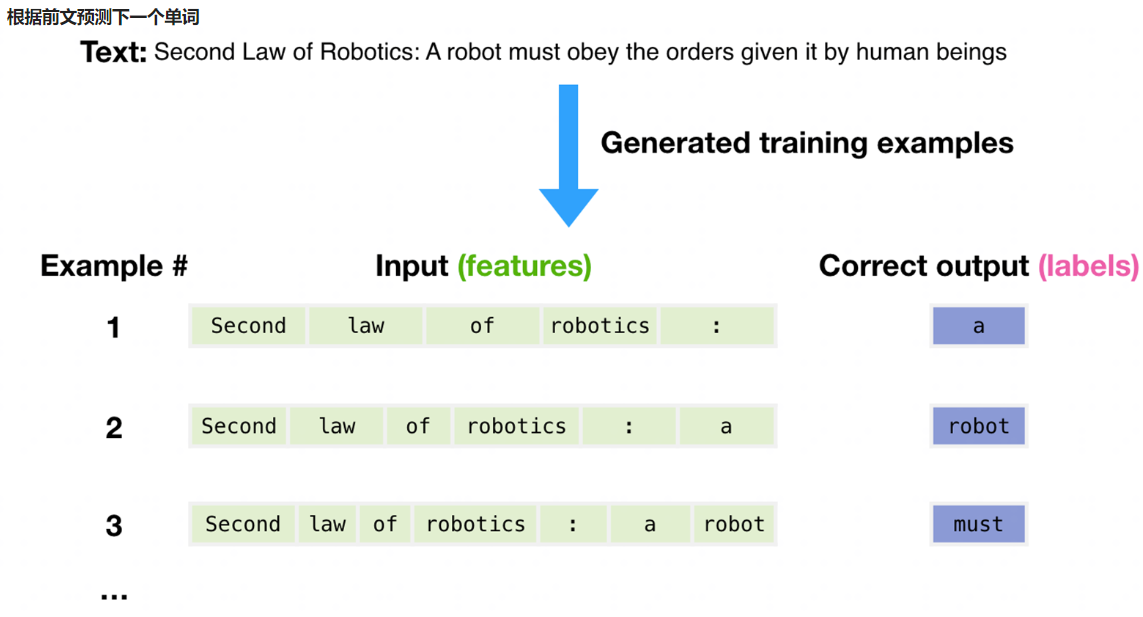
一个文本序列的概率分布可以分解为每个词基于其上文的条件概率的乘积
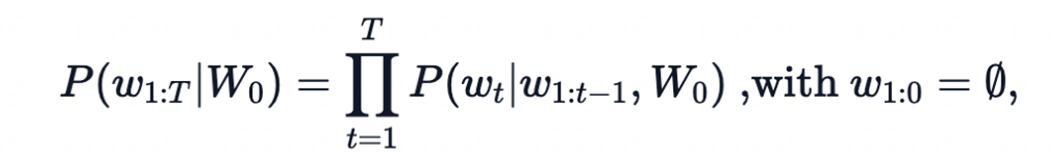
- 𝑊_0:初始上下文单词序列
- 𝑇: 时间步
- 当生成EOS标签时,停止生成。
MindNLP/huggingface Transformers提供的文本生成方法
2、Greedy search
在每个时间步𝑡都简单地选择概率最高的词作为当前输出词:
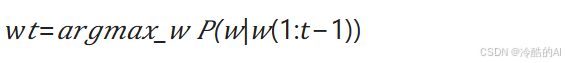
按照贪心搜索输出序列("The","nice","woman") 的条件概率为:0.5 x 0.4 = 0.2
缺点: 错过了隐藏在低概率词后面的高概率词,如:dog=0.5, has=0.9 
3、Beam search
Beam search 是一种启发式搜索算法,常用于自然语言处理任务,如机器翻译、文本摘要和语言模型的解码阶段。它通过扩展最有前途的节点来探索搜索空间。
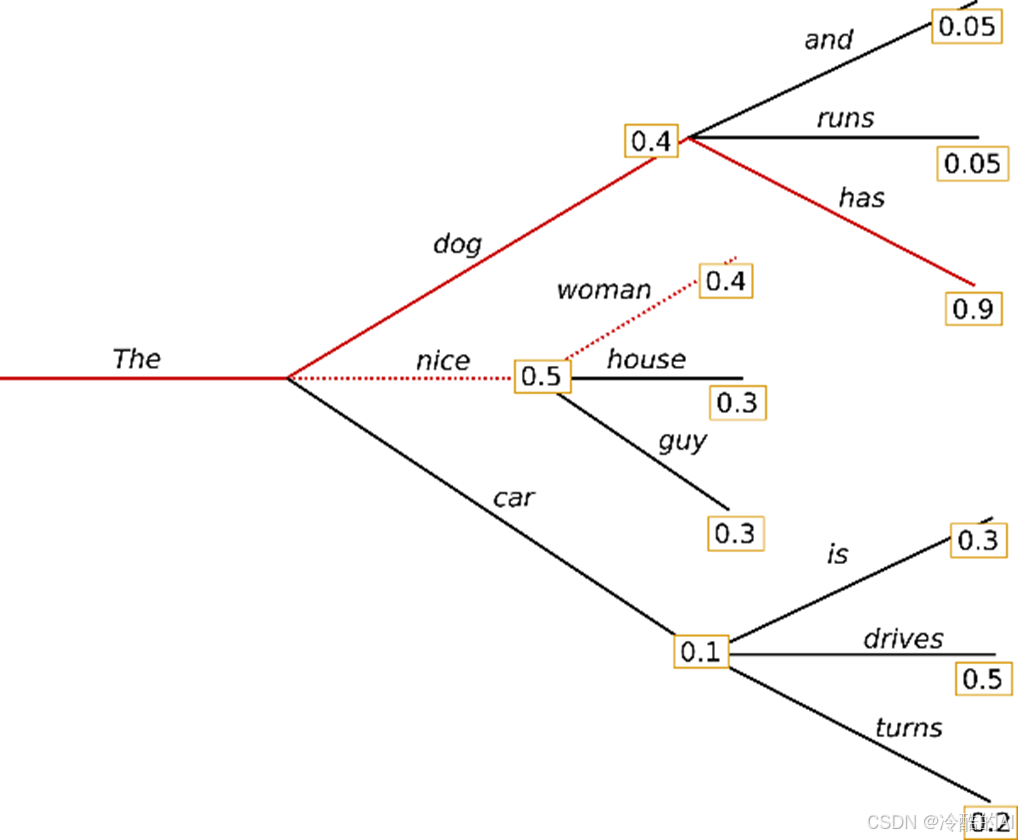
Beam search通过在每个时间步保留最可能的 num_beams 个词,并从中最终选择出概率最高的序列来降低丢失潜在的高概率序列的风险。如图以 num_beams=2 为例:
("The","dog","has") : 0.4 * 0.9 = 0.36
("The","nice","woman") : 0.5 * 0.4 = 0.20
优点:一定程度保留最优路径;
缺点:1. 无法解决重复问题;2. 开放域生成效果差。
原理如下图:(通过扩展最有前途的节点来探索搜索空间,在每个时间步保留最可能的 num_beams 个词,并从中最终选择出概率最高的一条路径)
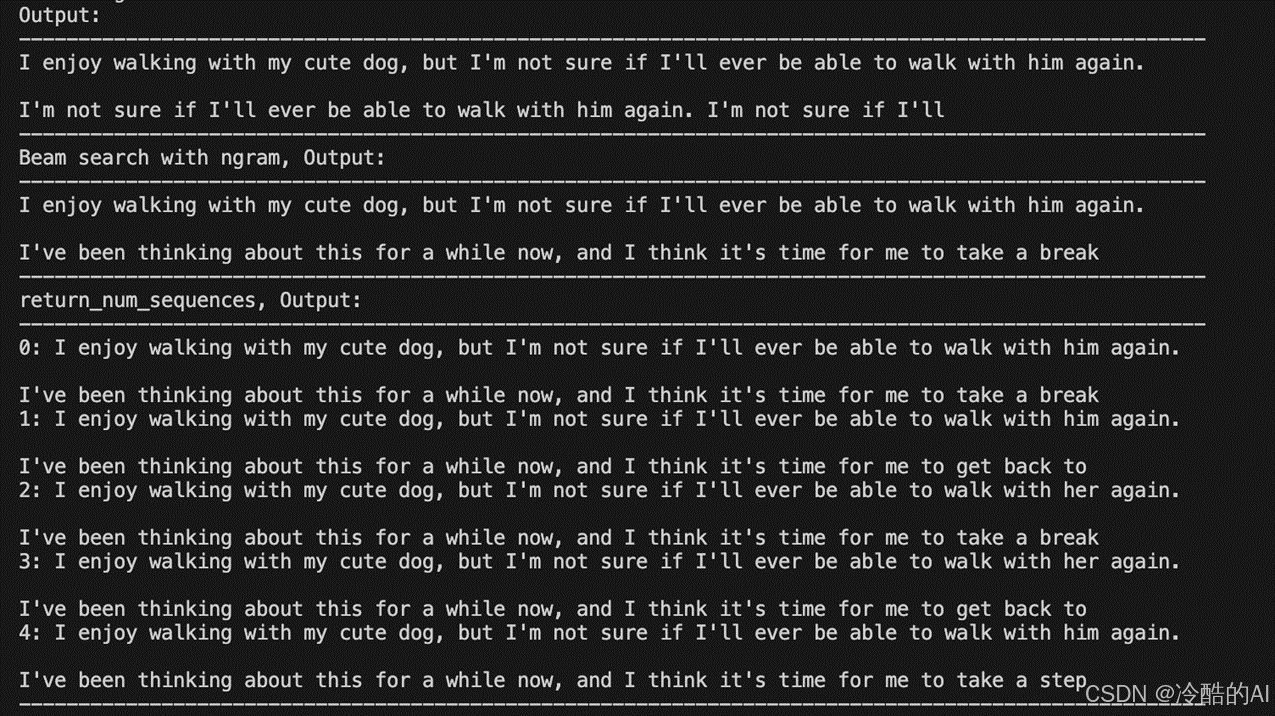
错误如下图:(回答出现错误、回答缺少创意)
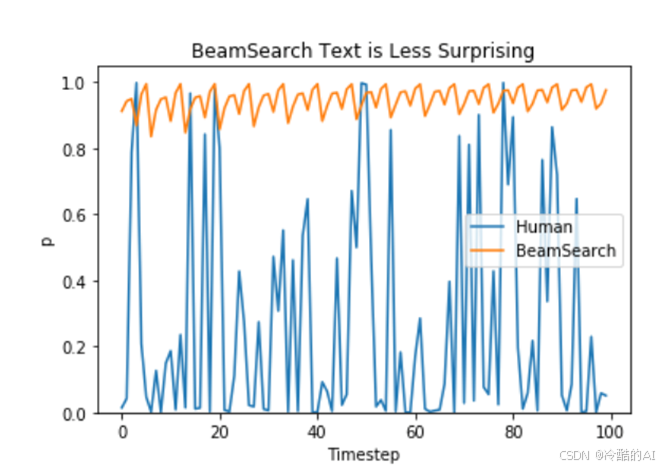


解决办法:n-gram 惩罚
将出现过的候选词的概率设置为 0
设置no_repeat_ngram_size=2 ,任意 2-gram 不会出现两次
缺点: 实际文本生成需要重复出现,调整后文本不一定能重复。
4、 Sample
根据当前条件概率分布随机选择输出词𝑤_𝑡
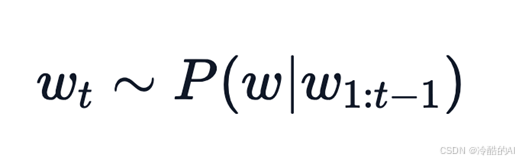
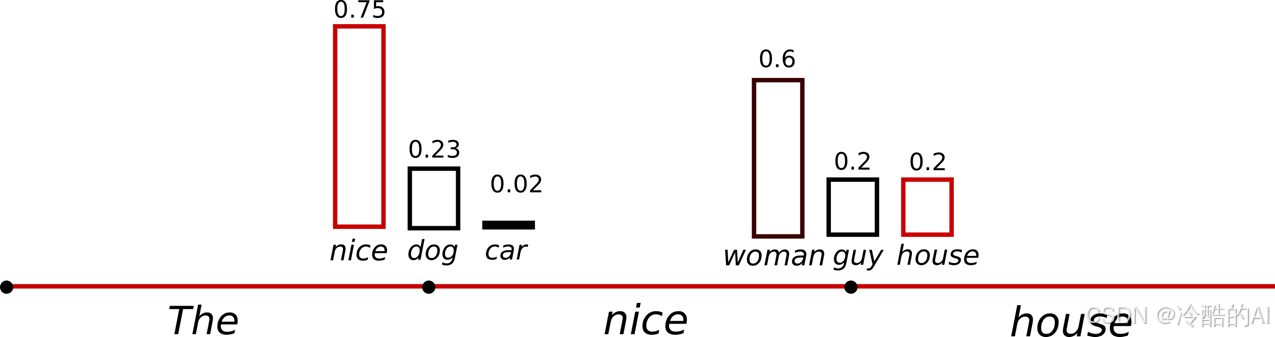
("car") ~P(w∣"The") ("drives") ~P(w∣"The","car") 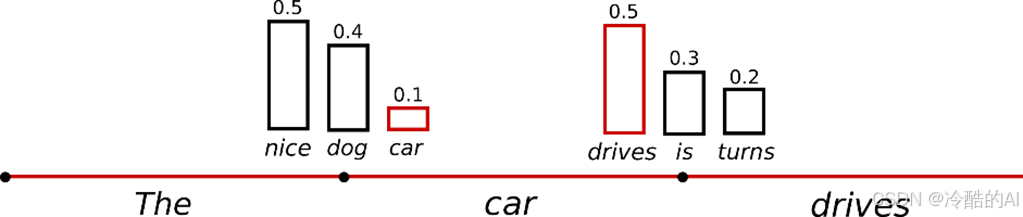
优点:文本生成多样性高
缺点:生成文本不连续
解决办法:降低softmax 的temperature使 P(w∣w1:t−1)分布更陡峭
增加高概率单词的似然并降低低概率单词的似然
5、Top-K sample
选出概率最大的 K 个词,重新归一化,最后在归一化后的 K 个词中采样 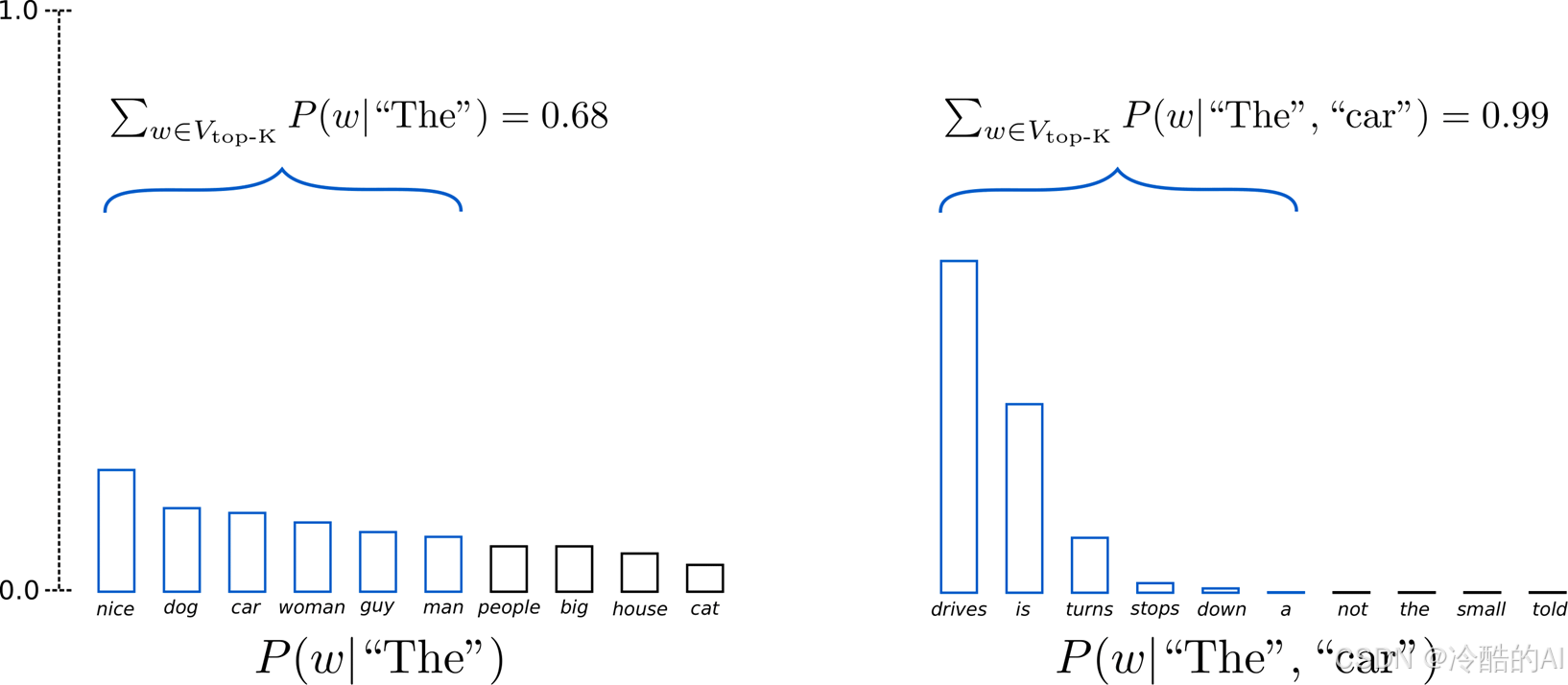
缺点如下:
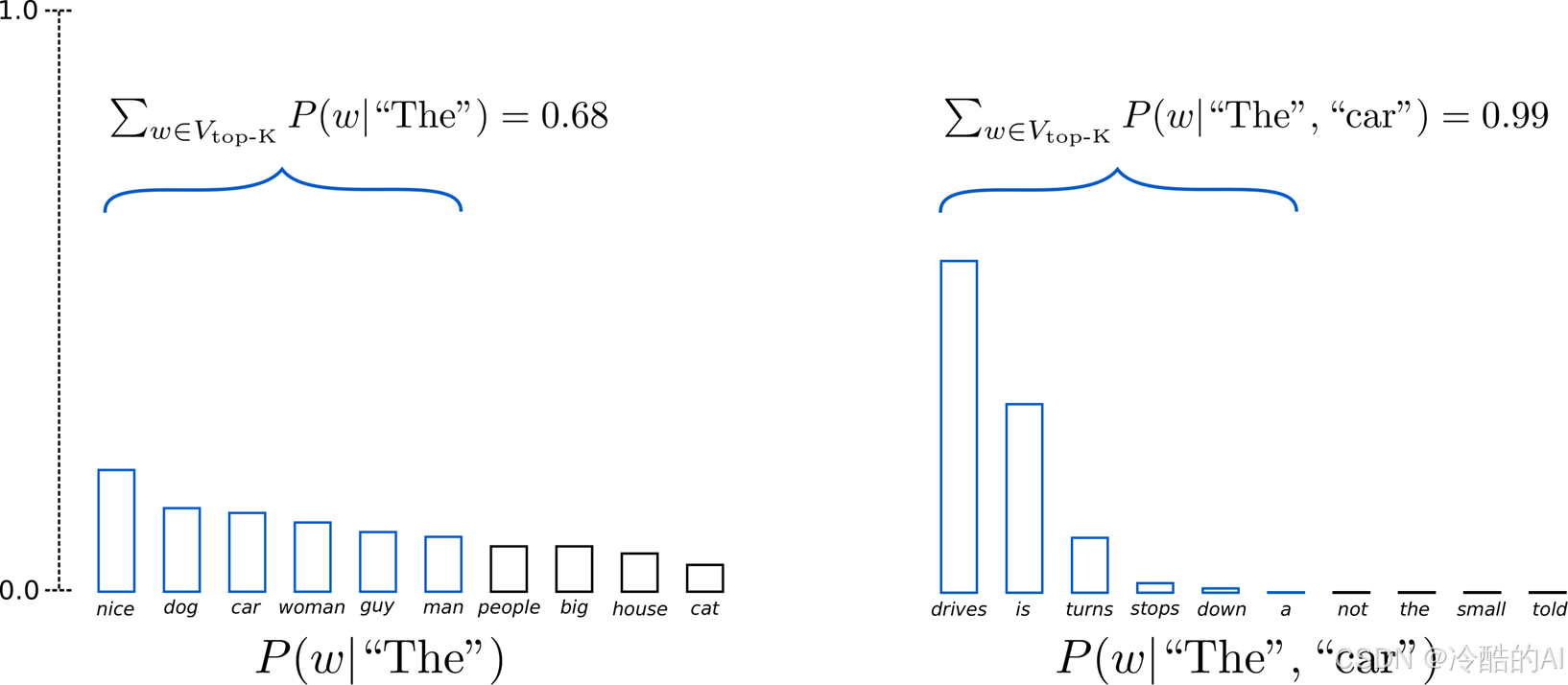
将采样池限制为固定大小 K :
- 在分布比较尖锐的时候产生胡言乱语
- 在分布比较平坦的时候限制模型的创造力
6、Top-P sample
在累积概率超过概率 p 的最小单词集中进行采样,重新归一化
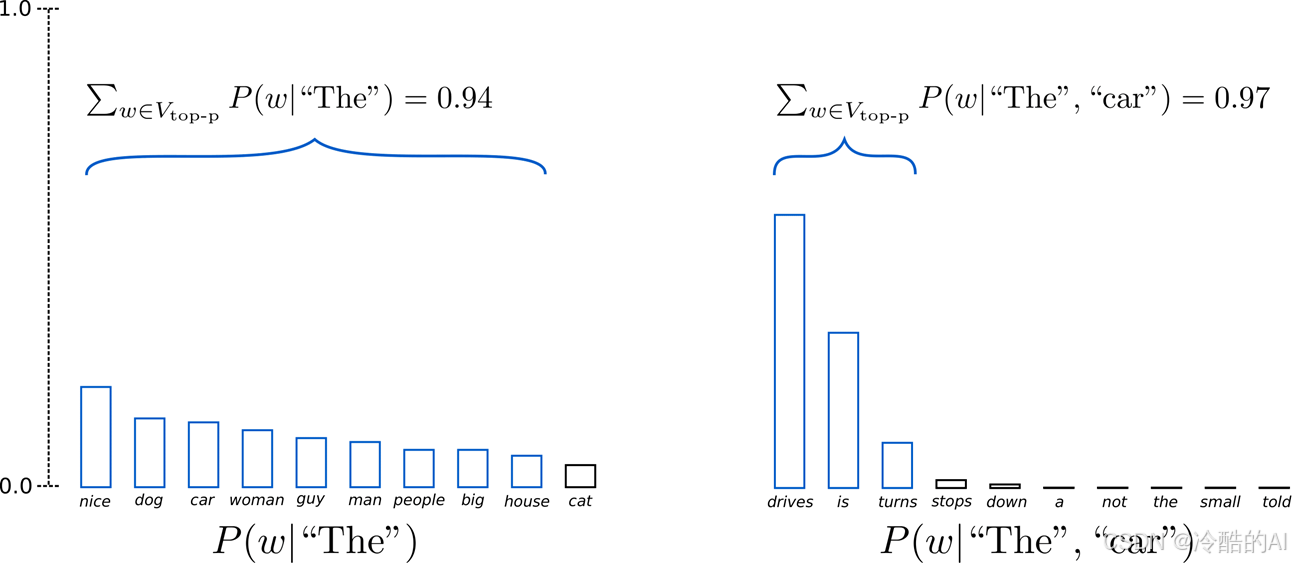
采样池可以根据下一个词的概率分布动态增加和减少
7、top_k_top_p 结合
对上面的问题有一定改善作用。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 9
9 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)