昇思25天学习打卡营第26天 | BERT对话情绪识别
内容介绍:
BERT全称是来自变换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers),它是Google于2018年末开发并发布的一种新型语言模型。与BERT模型相似的预训练语言模型例如问答、命名实体识别、自然语言推理、文本分类等在许多自然语言处理任务中发挥着重要作用。模型是基于Transformer中的Encoder并加上双向的结构,因此一定要熟练掌握Transformer的Encoder的结构。
BERT模型的主要创新点都在pre-train方法上,即用了Masked Language Model和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
在用Masked Language Model方法训练BERT的时候,随机把语料库中15%的单词做Mask操作。对于这15%的单词做Mask操作分为三种情况:80%的单词直接用[Mask]替换、10%的单词直接替换成另一个新的单词、10%的单词保持不变。
因为涉及到Question Answering (QA) 和 Natural Language Inference (NLI)之类的任务,增加了Next Sentence Prediction预训练任务,目的是让模型理解两个句子之间的联系。与Masked Language Model任务相比,Next Sentence Prediction更简单些,训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,BERT模型预测B是不是A的下一句。
BERT预训练之后,会保存它的Embedding table和12层Transformer权重(BERT-BASE)或24层Transformer权重(BERT-LARGE)。使用预训练好的BERT模型可以对下游任务进行Fine-tuning,比如:文本分类、相似度判断、阅读理解等。
对话情绪识别(Emotion Detection,简称EmoTect),专注于识别智能对话场景中用户的情绪,针对智能对话场景中的用户文本,自动判断该文本的情绪类别并给出相应的置信度,情绪类型分为积极、消极、中性。 对话情绪识别适用于聊天、客服等多个场景,能够帮助企业更好地把握对话质量、改善产品的用户交互体验,也能分析客服服务质量、降低人工质检成本。
具体内容:
1. 导包:
import os
import mindspore
from mindspore.dataset import text, GeneratorDataset, transforms
from mindspore import nn, context
from mindnlp._legacy.engine import Trainer, Evaluator
from mindnlp._legacy.engine.callbacks import CheckpointCallback, BestModelCallback
from mindnlp._legacy.metrics import Accuracy
import numpy as np
from mindnlp.transformers import BertTokenizer
from mindnlp.transformers import BertForSequenceClassification, BertModel
from mindnlp._legacy.amp import auto_mixed_precision2. 数据加载器
class SentimentDataset:
"""Sentiment Dataset"""
def __init__(self, path):
self.path = path
self._labels, self._text_a = [], []
self._load()
def _load(self):
with open(self.path, "r", encoding="utf-8") as f:
dataset = f.read()
lines = dataset.split("\n")
for line in lines[1:-1]:
label, text_a = line.split("\t")
self._labels.append(int(label))
self._text_a.append(text_a)
def __getitem__(self, index):
return self._labels[index], self._text_a[index]
def __len__(self):
return len(self._labels)3. 数据集
这里提供一份已标注的、经过分词预处理的机器人聊天数据集,来自于百度飞桨团队。数据由两列组成,以制表符('\t')分隔,第一列是情绪分类的类别(0表示消极;1表示中性;2表示积极),第二列是以空格分词的中文文本,如下示例,文件为 utf8 编码。
label--text_a
0--谁骂人了?我从来不骂人,我骂的都不是人,你是人吗 ?
1--我有事等会儿就回来和你聊
2--我见到你很高兴谢谢你帮我
这部分主要包括数据集读取,数据格式转换,数据 Tokenize 处理和 pad 操作。
数据加载和数据预处理
def process_dataset(source, tokenizer, max_seq_len=64, batch_size=32, shuffle=True):
is_ascend = mindspore.get_context('device_target') == 'Ascend'
column_names = ["label", "text_a"]
dataset = GeneratorDataset(source, column_names=column_names, shuffle=shuffle)
# transforms
type_cast_op = transforms.TypeCast(mindspore.int32)
def tokenize_and_pad(text):
if is_ascend:
tokenized = tokenizer(text, padding='max_length', truncation=True, max_length=max_seq_len)
else:
tokenized = tokenizer(text)
return tokenized['input_ids'], tokenized['attention_mask']
# map dataset
dataset = dataset.map(operations=tokenize_and_pad, input_columns="text_a", output_columns=['input_ids', 'attention_mask'])
dataset = dataset.map(operations=[type_cast_op], input_columns="label", output_columns='labels')
# batch dataset
if is_ascend:
dataset = dataset.batch(batch_size)
else:
dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id),
'attention_mask': (None, 0)})
return datasettokenizer = BertTokenizer.from_pretrained('bert-base-chinese')tokenizer.pad_token_iddataset_train = process_dataset(SentimentDataset("data/train.tsv"), tokenizer)
dataset_val = process_dataset(SentimentDataset("data/dev.tsv"), tokenizer)
dataset_test = process_dataset(SentimentDataset("data/test.tsv"), tokenizer, shuffle=False)dataset_train.get_col_names()print(next(dataset_train.create_tuple_iterator()))
4. 模型构建
通过 BertForSequenceClassification 构建用于情感分类的 BERT 模型,加载预训练权重,设置情感三分类的超参数自动构建模型。后面对模型采用自动混合精度操作,提高训练的速度,然后实例化优化器,紧接着实例化评价指标,设置模型训练的权重保存策略,最后就是构建训练器,模型开始训练。
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=3)
model = auto_mixed_precision(model, 'O1')
optimizer = nn.Adam(model.trainable_params(), learning_rate=2e-5)metric = Accuracy()
# define callbacks to save checkpoints
ckpoint_cb = CheckpointCallback(save_path='checkpoint', ckpt_name='bert_emotect', epochs=1, keep_checkpoint_max=2)
best_model_cb = BestModelCallback(save_path='checkpoint', ckpt_name='bert_emotect_best', auto_load=True)
trainer = Trainer(network=model, train_dataset=dataset_train,
eval_dataset=dataset_val, metrics=metric,
epochs=5, optimizer=optimizer, callbacks=[ckpoint_cb, best_model_cb])%%time
# start training
trainer.run(tgt_columns="labels")
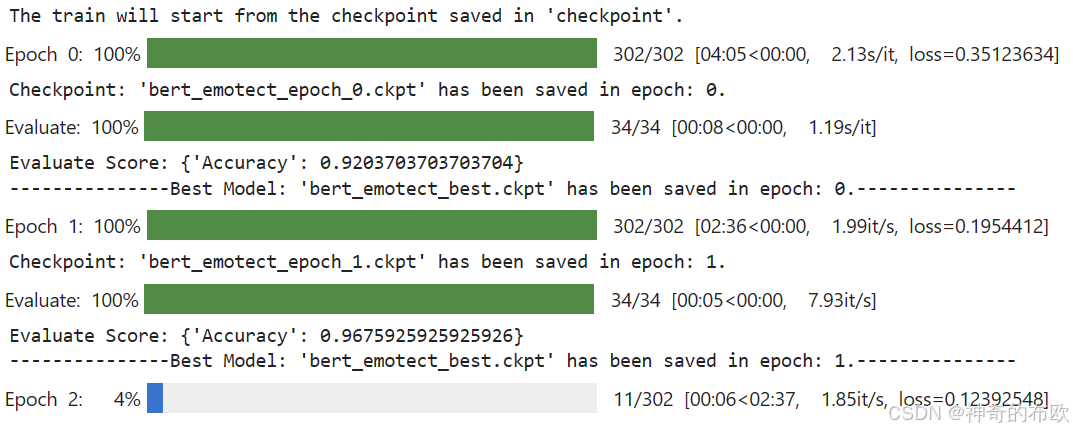

5. 模型验证
evaluator = Evaluator(network=model, eval_dataset=dataset_test, metrics=metric)
evaluator.run(tgt_columns="labels")
6. 模型推理
dataset_infer = SentimentDataset("data/infer.tsv")def predict(text, label=None):
label_map = {0: "消极", 1: "中性", 2: "积极"}
text_tokenized = Tensor([tokenizer(text).input_ids])
logits = model(text_tokenized)
predict_label = logits[0].asnumpy().argmax()
info = f"inputs: '{text}', predict: '{label_map[predict_label]}'"
if label is not None:
info += f" , label: '{label_map[label]}'"
print(info)for label, text in dataset_infer:
predict(text, label)
在对话情绪识别的任务中,准确捕捉对话双方的情感倾向往往依赖于对整体对话语境的精准把握。BERT凭借其强大的双向编码能力,能够同时考虑句子中每个词的前后文信息,从而生成更加丰富、准确的语义表示。这种能力使得模型在判断对话中的情绪变化、微妙语气转换时,能够做出更加细腻和贴近人类感知的预测。
其次,我深刻体会到了迁移学习在NLP领域中的巨大价值。通过在大规模语料库上预训练的BERT模型,我们无需从头开始训练复杂的模型,而是可以直接利用这些预训练好的参数来初始化我们的对话情绪识别模型。这不仅大大缩短了模型的训练时间,还显著提高了模型的泛化能力。在实际应用中,我们只需针对特定任务进行微调,即可快速适应并提升模型在对话情绪识别上的性能。


昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 17
17 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)