【MindSpore学习打卡】初学教程-05数据变化 Transforms-使用MindSpore进行数据变换
在深度学习模型的训练过程中,数据预处理是不可或缺的一环。直接加载的原始数据往往无法直接用于训练神经网络,因此需要进行必要的数据变换和增强。MindSpore作为一款强大的深度学习框架,提供了丰富的数据变换工具,帮助我们高效地处理和增强数据。本篇博客将详细介绍如何使用MindSpore进行数据变换,通过具体的代码示例和图示,帮助你快速掌握这一技能。
数据变换概述
MindSpore的mindspore.dataset模块提供了一系列面向图像、文本、音频等不同数据类型的Transforms。所有的Transforms均可通过map方法传入,实现对指定数据列的处理。
常见Transforms
mindspore.dataset.transforms模块支持一系列通用Transforms。这里我们以Compose为例,介绍其使用方式。
Compose
为什么要使用Compose进行数据变换?Compose允许我们将多个数据变换操作组合成一个管道,这样可以简化代码并提高可读性。在处理复杂的数据预处理流程时,使用Compose可以使代码更加模块化和易于维护。Compose接收一个数据增强操作序列,然后将其组合成单个数据增强操作。我们以Mnist数据集为例,展示如何使用Compose进行数据处理。
from mindspore.dataset import transforms, vision, MnistDataset
# 下载并加载MNIST数据集
train_dataset = MnistDataset('MNIST_Data/train')
image, label = next(train_dataset.create_tuple_iterator())
print("原始图像形状:", image.shape)
# 定义Compose操作
composed = transforms.Compose([
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
])
# 应用Compose操作
train_dataset = train_dataset.map(composed, 'image')
image, label = next(train_dataset.create_tuple_iterator())
print("处理后图像形状:", image.shape)
图像Transforms
mindspore.dataset.vision模块提供一系列针对图像数据的Transforms。在这里,我们详细介绍几个常用的图像变换操作。
Rescale
Rescale变换用于调整图像像素值的大小。下面我们使用numpy随机生成一个像素值在[0, 255]的图像,将其像素值进行缩放。
import numpy as np
from PIL import Image
from mindspore.dataset import vision
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
print("原始图像像素值:\n", random_np)
rescale = vision.Rescale(1.0 / 255.0, 0)
rescaled_image = rescale(random_image)
print("缩放后图像像素值:\n", rescaled_image)
Normalize
为什么要进行归一化(Normalize)?Normalize变换用于对输入图像的归一化。归一化操作将图像数据的像素值调整到一个标准范围内(通常是0到1之间),这有助于加快模型的收敛速度,并提高模型的稳定性和性能。归一化后的数据可以减少不同特征之间的数量级差异,使得模型更容易学习。
normalize = vision.Normalize(mean=(0.1307,), std=(0.3081,))
normalized_image = normalize(rescaled_image)
print("归一化后图像像素值:\n", normalized_image)
HWC2CHW
为什么要进行格式转换(HWC2CHW)?HWC2CHW变换用于转换图像格式。不同的硬件设备和深度学习框架可能对图像数据的存储格式有不同的要求。HWC(Height, Width, Channel)和CHW(Channel, Height, Width)是两种常见的图像数据格式。MindSpore默认使用HWC格式,但在某些情况下(如使用特定的神经网络架构或硬件加速器时),需要将图像转换为CHW格式。使用HWC2CHW变换可以方便地完成这一转换。
下面我们将图像从HWC格式转换为CHW格式:
hwc_image = np.expand_dims(normalized_image, -1)
hwc2chw = vision.HWC2CHW()
chw_image = hwc2chw(hwc_image)
print("转换前形状:", hwc_image.shape, "转换后形状:", chw_image.shape)
文本Transforms
mindspore.dataset.text模块提供了一系列针对文本数据的Transforms。下面我们介绍如何使用这些Transforms进行文本处理。
PythonTokenizer
为什么要使用分词(Tokenize)操作?
分词(Tokenize)操作是文本数据的基础处理方法。在处理文本数据时,分词是一个基础且必要的步骤。分词将文本数据拆分为单个的Token(通常是单词或子词),这些Token是后续文本处理和建模的基本单位。不同的分词策略会影响模型的表现,因此选择合适的分词方法非常重要。
下面是一个简单的示例:
from mindspore.dataset import text, GeneratorDataset
texts = ['Welcome to Beijing']
test_dataset = GeneratorDataset(texts, 'text')
def my_tokenizer(content):
return content.split()
test_dataset = test_dataset.map(text.PythonTokenizer(my_tokenizer))
print("分词结果:", next(test_dataset.create_tuple_iterator()))
Lookup
Lookup为词表映射变换,用来将Token转换为Index。下面是一个简单的示例:
vocab = text.Vocab.from_dataset(test_dataset)
print("词表:", vocab.vocab())
test_dataset = test_dataset.map(text.Lookup(vocab))
print("Token转Index结果:", next(test_dataset.create_tuple_iterator()))
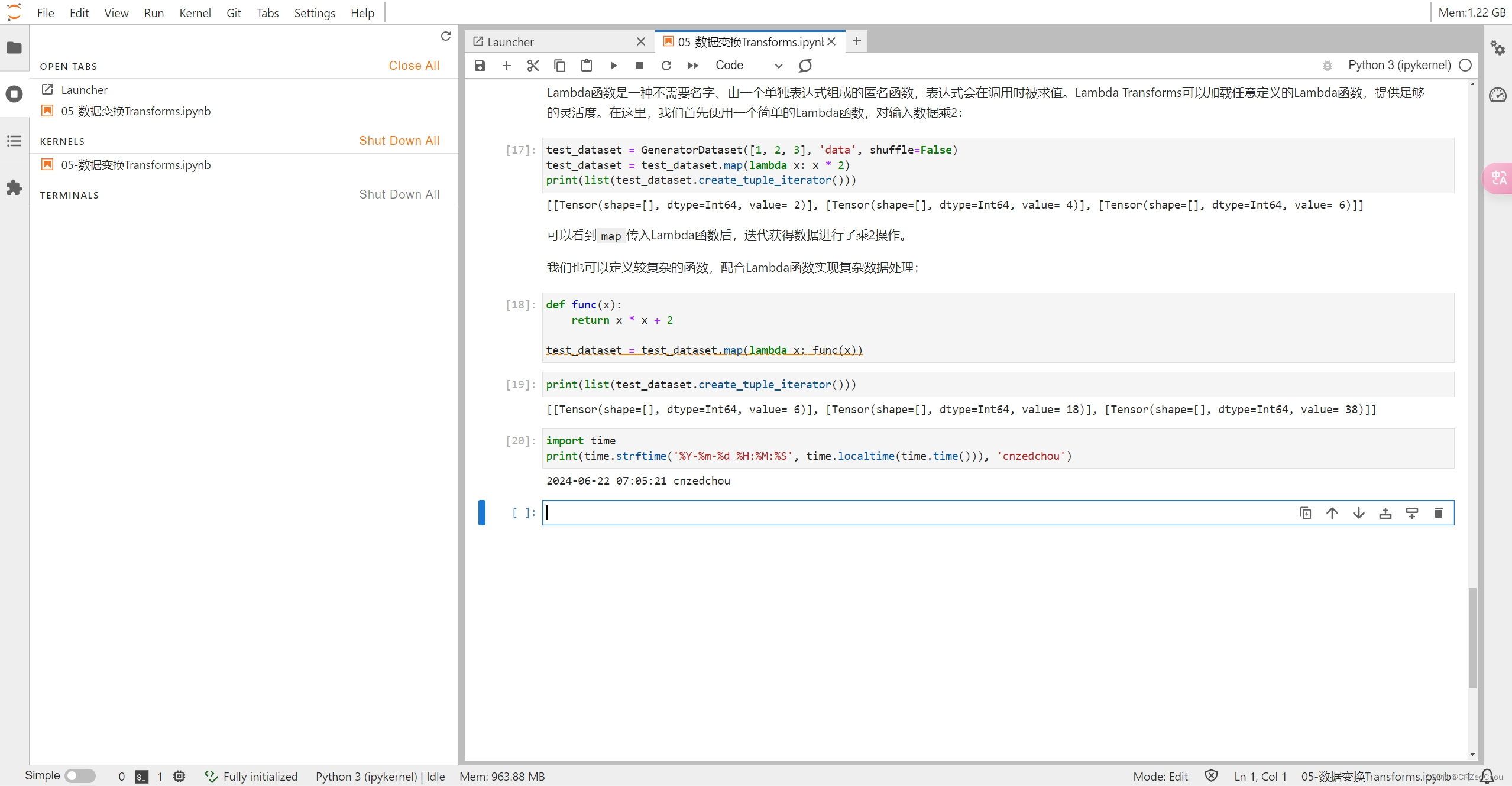
Lambda Transforms
为什么要使用Lambda函数进行数据变换?
Lambda函数提供了极大的灵活性,允许我们定义任意的自定义变换操作。对于一些特定的需求或复杂的变换逻辑,使用Lambda函数可以简化代码,并使得数据处理过程更加灵活和高效。
Lambda函数是一种不需要名字、由一个单独表达式组成的匿名函数。下面是一个简单的示例:
test_dataset = GeneratorDataset([1, 2, 3], 'data', shuffle=False)
test_dataset = test_dataset.map(lambda x: x * 2)
print("Lambda函数结果:", list(test_dataset.create_tuple_iterator()))
我们也可以定义较复杂的函数,配合Lambda函数实现复杂数据处理:
def func(x):
return x * x + 2
test_dataset = test_dataset.map(lambda x: func(x))
print("复杂Lambda函数结果:", list(test_dataset.create_tuple_iterator()))

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 15
15 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)