昇思Mindspore学习25天打卡Day12:ResNet50迁移
昇思Mindspore学习25天打卡Day12:ResNet50迁移
一、数据准备
在实际应用场景中,由于训练数据集不足,所以很少有人会从头开始训练整个网络。普遍的做法是,在一个非常大的基础数据集上训练得到一个预训练模型,然后使用该模型来初始化网络的权重参数或作为固定特征提取器****应用于特定的任务中。本章将使用迁移学习的方法对lmageNet数据集中的狼和狗图像进行分类。
- 迁移学习详细内容见[Standford University CS231n](https://cs231n.github.io/transfer-learning/#tf)。
1.1 下载数据集
下载案例所用到的[狗与狼分类数据集](https://cloud-78365a87-82f4-48e6-83bb-b49e1db37fc2.xihe.mindspore.cn/lab/tree/%E5%BA%94%E7%94%A8%E5%AE%9E%E8%B7%B5/%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%86%E8%A7%89/ResNet50%E8%BF%81%E7%A7%BB%E5%AD%A6%E4%B9%A0.ipynb),数据集中的图像来自于lmageNet,每个分类有大约120张训练图像与30张验证图像。使用download 接口下载数据集,并将下载后的数据集自动解压到当前目录下。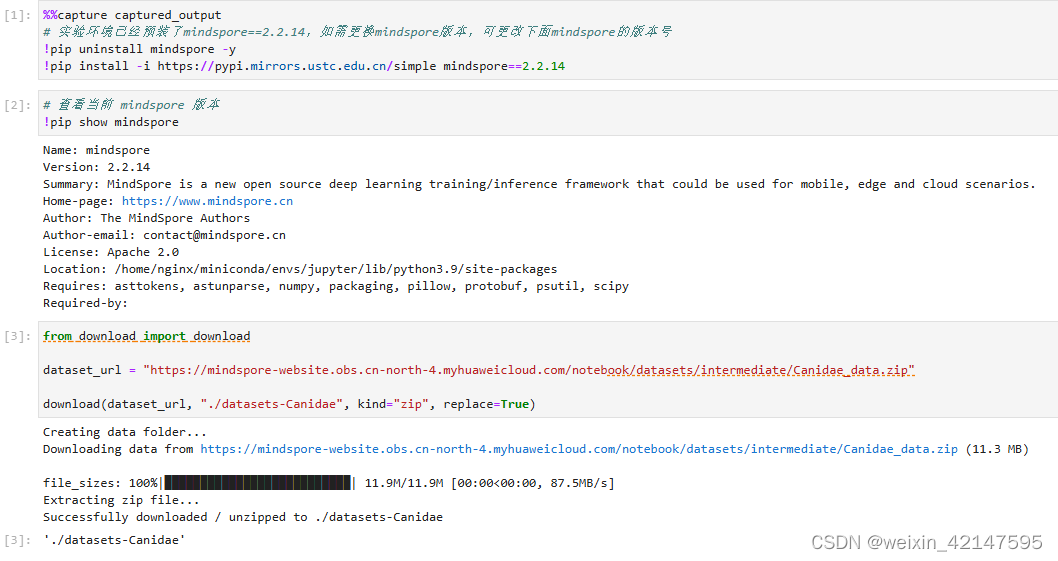
数据集的目录结构如下: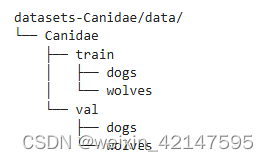
二、 加载数据集
狼狗数据集提取自lmageNet分类数据集,使用mindspore.dataset.ImageFolderDataset 接口来加载数据集,并进行相关图像增强操作。
首先执行过程定义一些输入: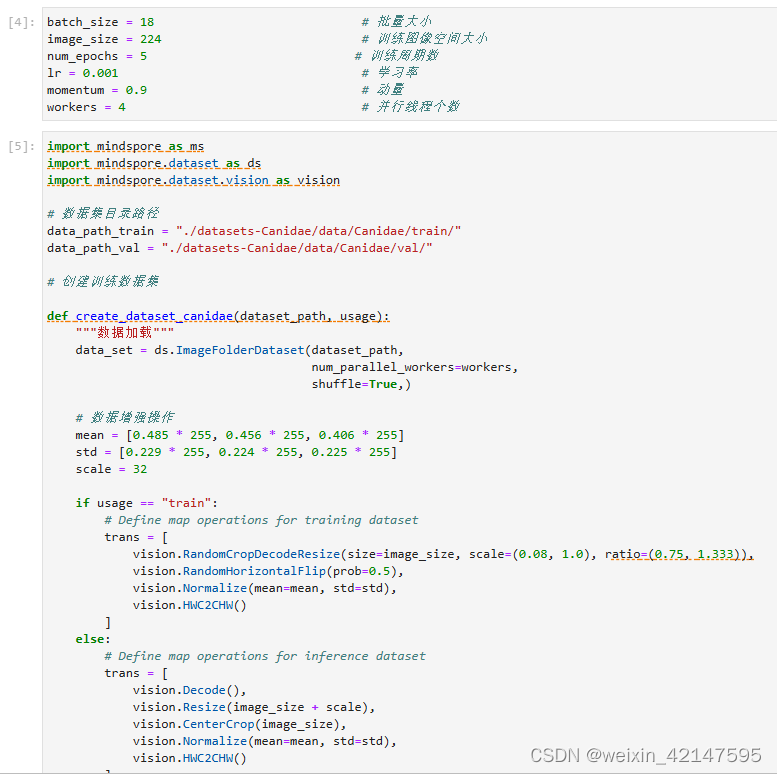

2.1 数据集可视化
从mindspore.dataset.ImageFolderDataset 接口中加载的训练数据集返回值为字典,用户可通过create_dict_iterator 接口创建数据迭代器,使用next迭代访问数据集。本章中 batch_size设为18,所以使用next一次可获取18个图像及标签数据。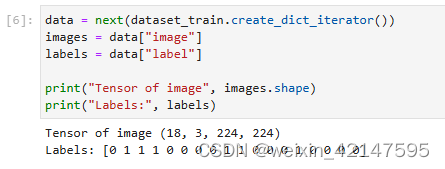
对获取到的图像及标签数据进行可视化,标题为图像对应的label名称。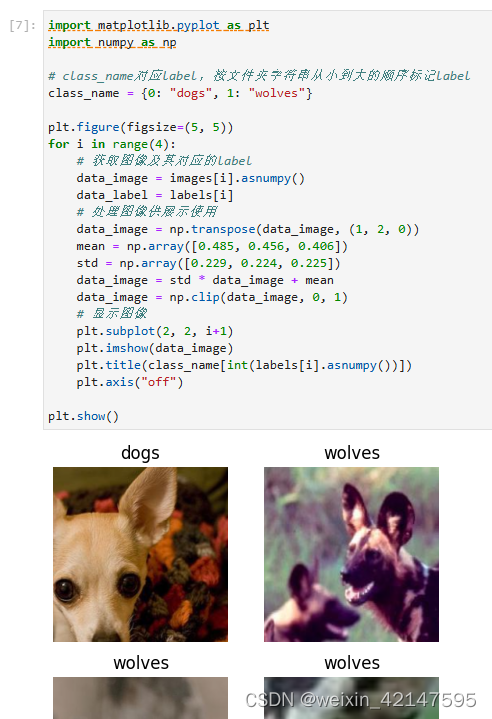

三、训练模型
本章使用ResNet50模型进行训练。搭建好模型框架后,通过将pretrained参数设置为True来下载ResNet50的预训练模型并将权重参数加载到网络中。
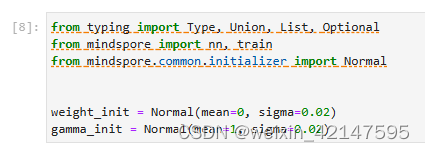
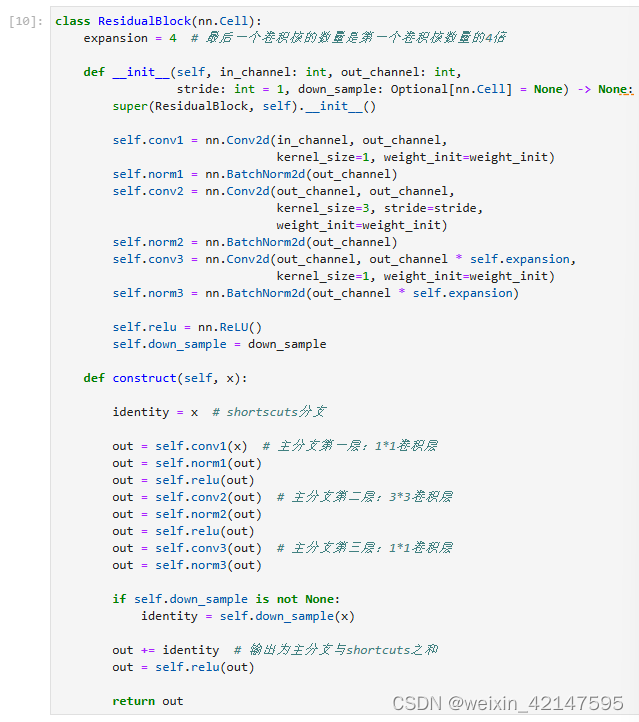
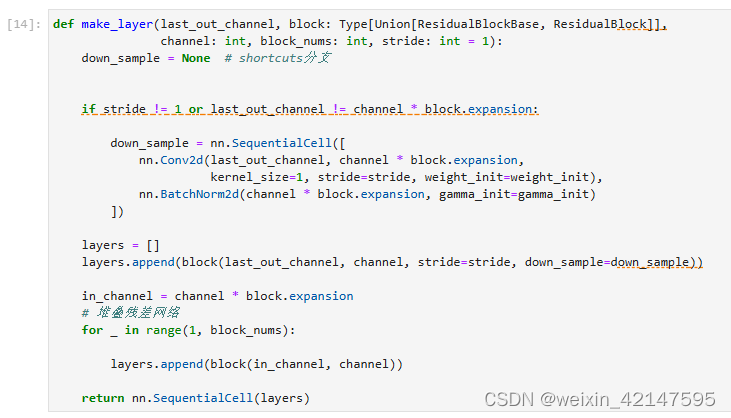
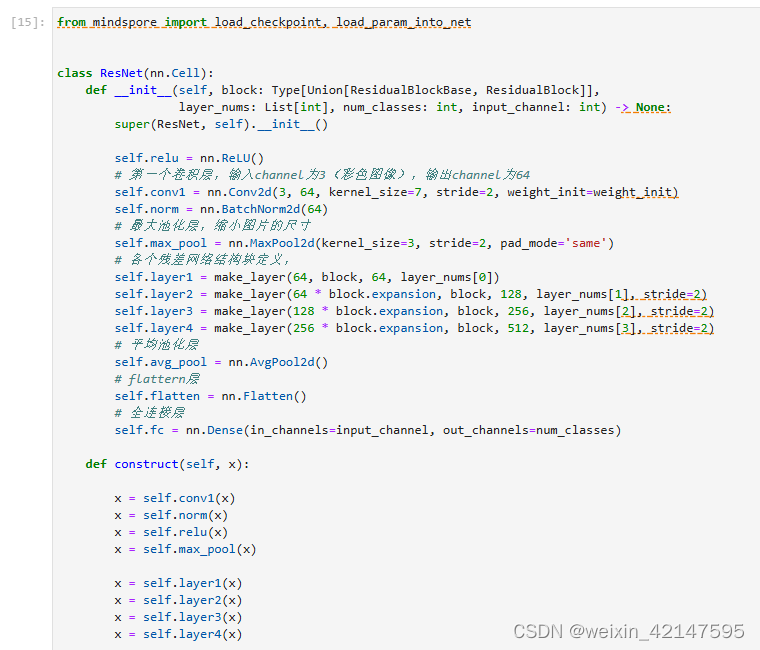
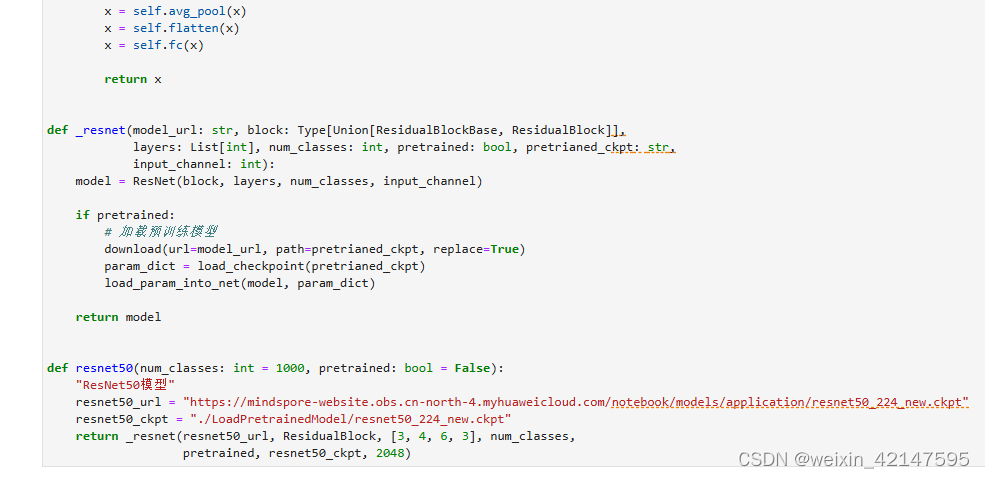
3.1 构建Resnet50网络



3.2 固定特征进行训练


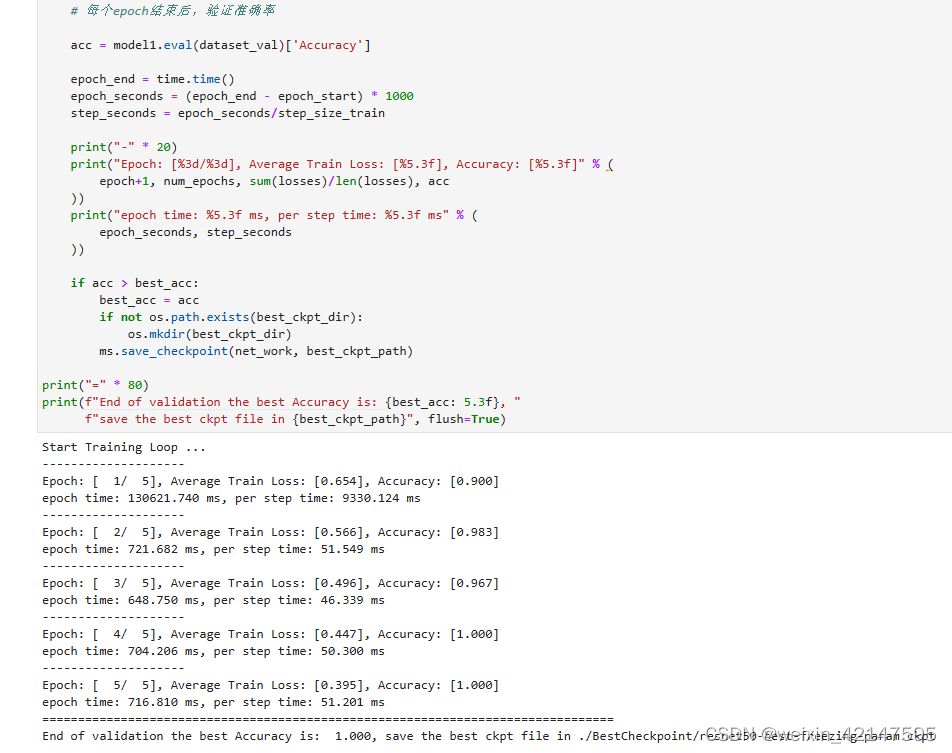
3.2.1 训练和评估
开始训练模型,与没有预训练模型相比,将节约一大半时间,因为此时可以不用计算部分梯度。保存评估精度最高的ckpt文件于当前路径的./BestCheckpoint/resnet50-best-freezing-param.ckpt。
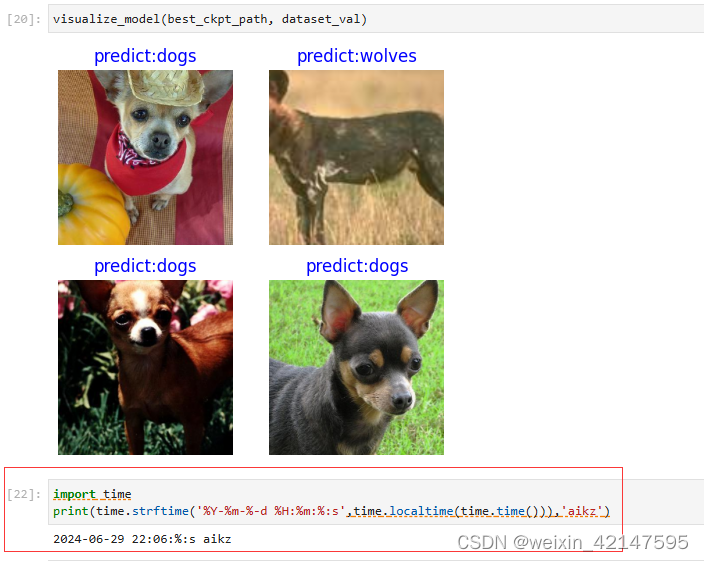
3.2.2 可视化模型预测 以及打上时间标签和标记
使用固定特征得到的best.ckpt文件对对验证集的狼和狗图像数据进行预测。若预测字体为蓝色即为预测正确,若预测字体为红色则预测错误。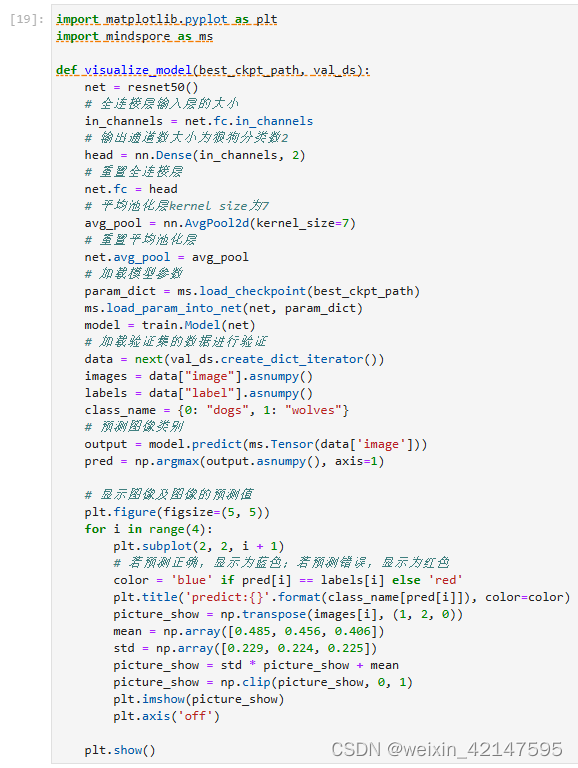

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 17
17 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)