昇思25天学习打卡营第05天|数据变换 Transforms
通常情况下,原始数据并不能直接送入神经网络进行训练,此时我们需要对其进行数据预处理。MindSpore提供不同种类的数据变换(Transforms),配合数据处理Pipeline来实现数据预处理。提供了面向图像、文本、音频等不同数据类型的Transforms,同时也支持使用Lambda函数。所有的Transforms均可通过。方法传入,实现对指定数据列的处理。
·
通常情况下,原始数据并不能直接送入神经网络进行训练,此时我们需要对其进行数据预处理。MindSpore提供不同种类的数据变换(Transforms),配合数据处理Pipeline来实现数据预处理。所有的Transforms均可通过map方法传入,实现对指定数据列的处理。
mindspore.dataset提供了面向图像、文本、音频等不同数据类型的Transforms,同时也支持使用Lambda函数。
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
import time
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
train_dataset = MnistDataset('MNIST_Data/train')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape)
composed = transforms.Compose(
[
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
)
train_dataset = train_dataset.map(composed, 'image')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape)
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
print(random_np)
rescale = vision.Rescale(1.0 / 255.0, 0)
rescaled_image = rescale(random_image)
print(rescaled_image)
normalize = vision.Normalize(mean=(0.1307,), std=(0.3081,))
normalized_image = normalize(rescaled_image)
print(normalized_image)
hwc_image = np.expand_dims(normalized_image, -1)
hwc2chw = vision.HWC2CHW()
chw_image = hwc2chw(hwc_image)
print(hwc_image.shape, chw_image.shape)
texts = ['Welcome to Beijing']
test_dataset = GeneratorDataset(texts, 'text')
def my_tokenizer(content):
return content.split()
test_dataset = test_dataset.map(text.PythonTokenizer(my_tokenizer))
print(next(test_dataset.create_tuple_iterator()))
vocab = text.Vocab.from_dataset(test_dataset)
print(vocab.vocab())
test_dataset = test_dataset.map(text.Lookup(vocab))
print(next(test_dataset.create_tuple_iterator()))
test_dataset = GeneratorDataset([1, 2, 3], 'data', shuffle=False)
test_dataset = test_dataset.map(lambda x: x * 2)
print(list(test_dataset.create_tuple_iterator()))
def func(x):
return x * x + 2
test_dataset = test_dataset.map(lambda x: func(x))
print(list(test_dataset.create_tuple_iterator()))
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()),'skywp')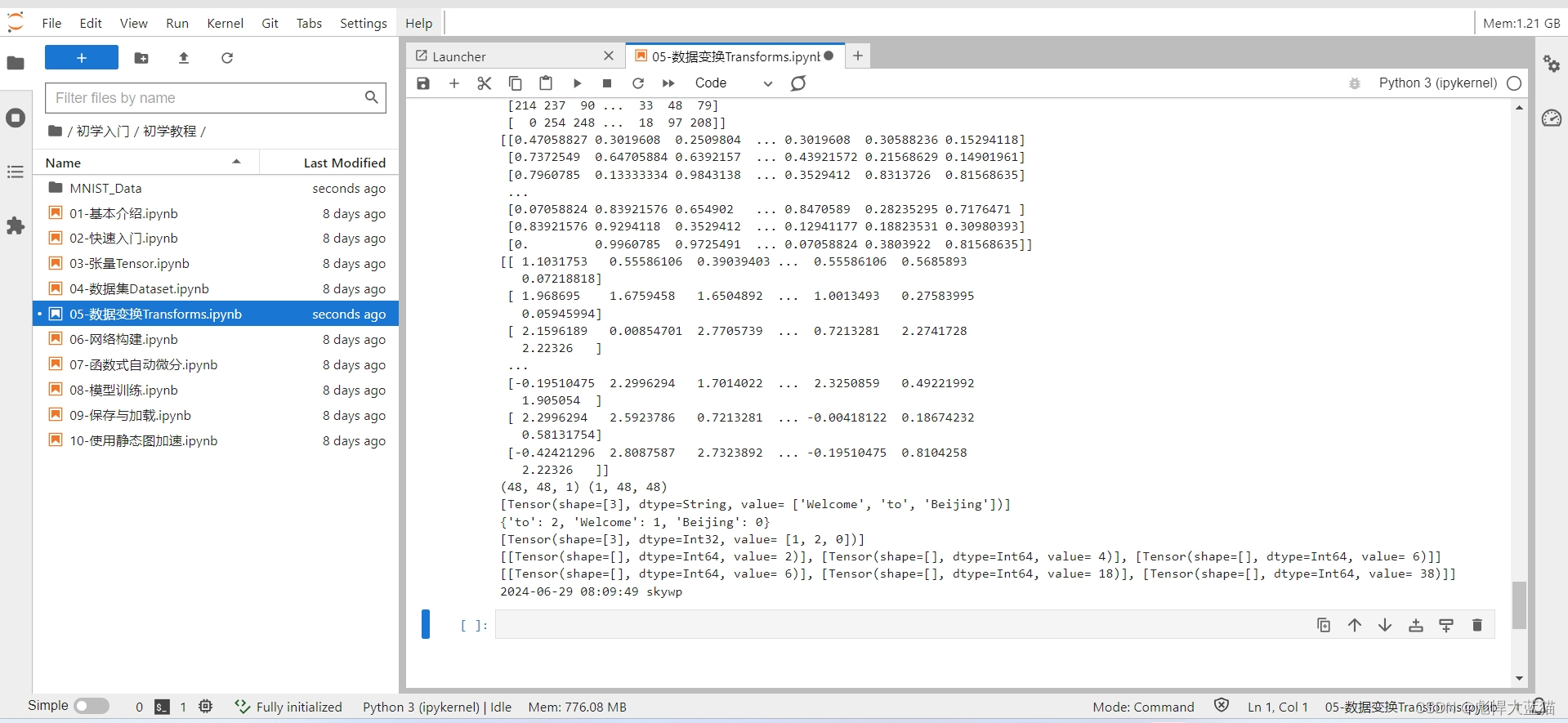

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)