昇思MindSpore技术公开课——第二课:BERT
word2vec/Glove将离散的文本数据转换为固定长度的静态词向量,后根据下游任务训练不同的语言模型;ELMo预训练模型将文本数据结合上下文信息,转换为动态词向量,后根据下游任务训练不同的语言模型;BERT同样将文本数据转换为动态词向量,能够更好地捕捉句子级别的信息与语境信息,后续只需对BERT参数进行微调,仅重新训练最后的输出层即可适配下游任务;GPT等预训练语言模型主要用于文本生成类任务,
1、学习总结
1.1NLP中的预训练模型
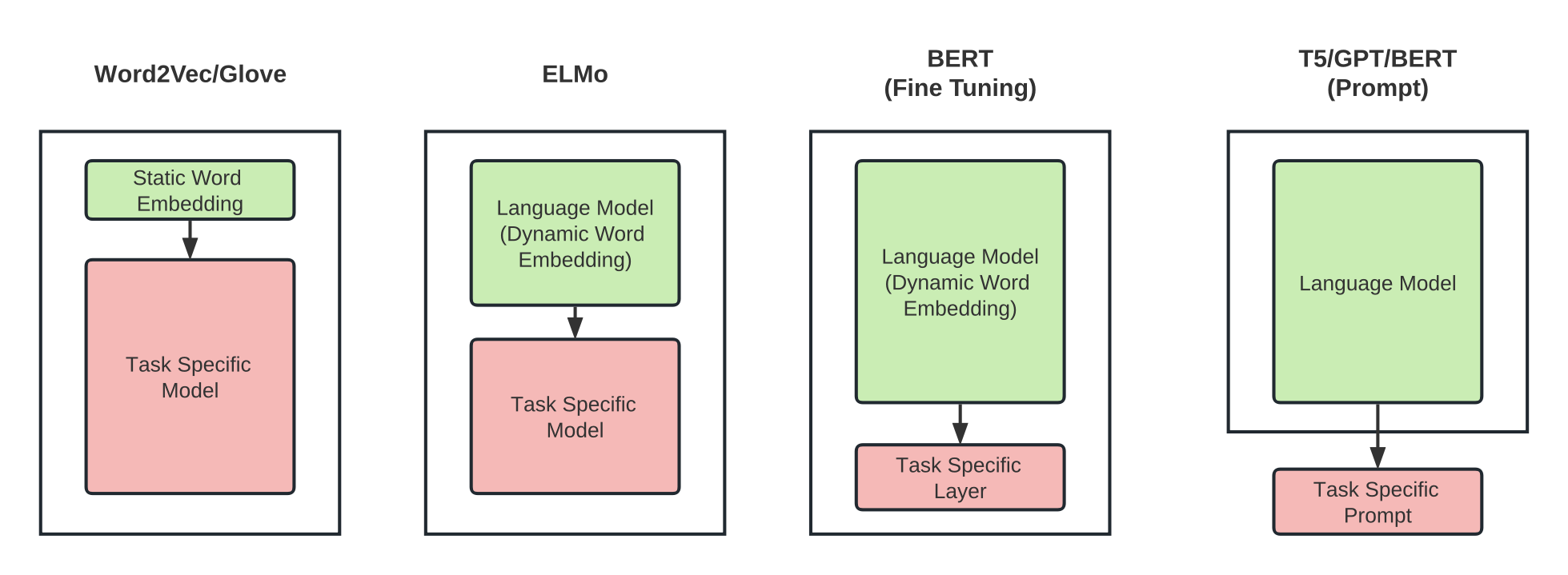
- word2vec/Glove将离散的文本数据转换为固定长度的静态词向量,后根据下游任务训练不同的语言模型;
- ELMo预训练模型将文本数据结合上下文信息,转换为动态词向量,后根据下游任务训练不同的语言模型;
- BERT同样将文本数据转换为动态词向量,能够更好地捕捉句子级别的信息与语境信息,后续只需对BERT参数进行微调,仅重新训练最后的输出层即可适配下游任务;
- GPT等预训练语言模型主要用于文本生成类任务,需要通过prompt方法来应用于下游任务,指导模型生成特定的输出。
1.2BERT介绍
1.2.1监督学习和半监督学习
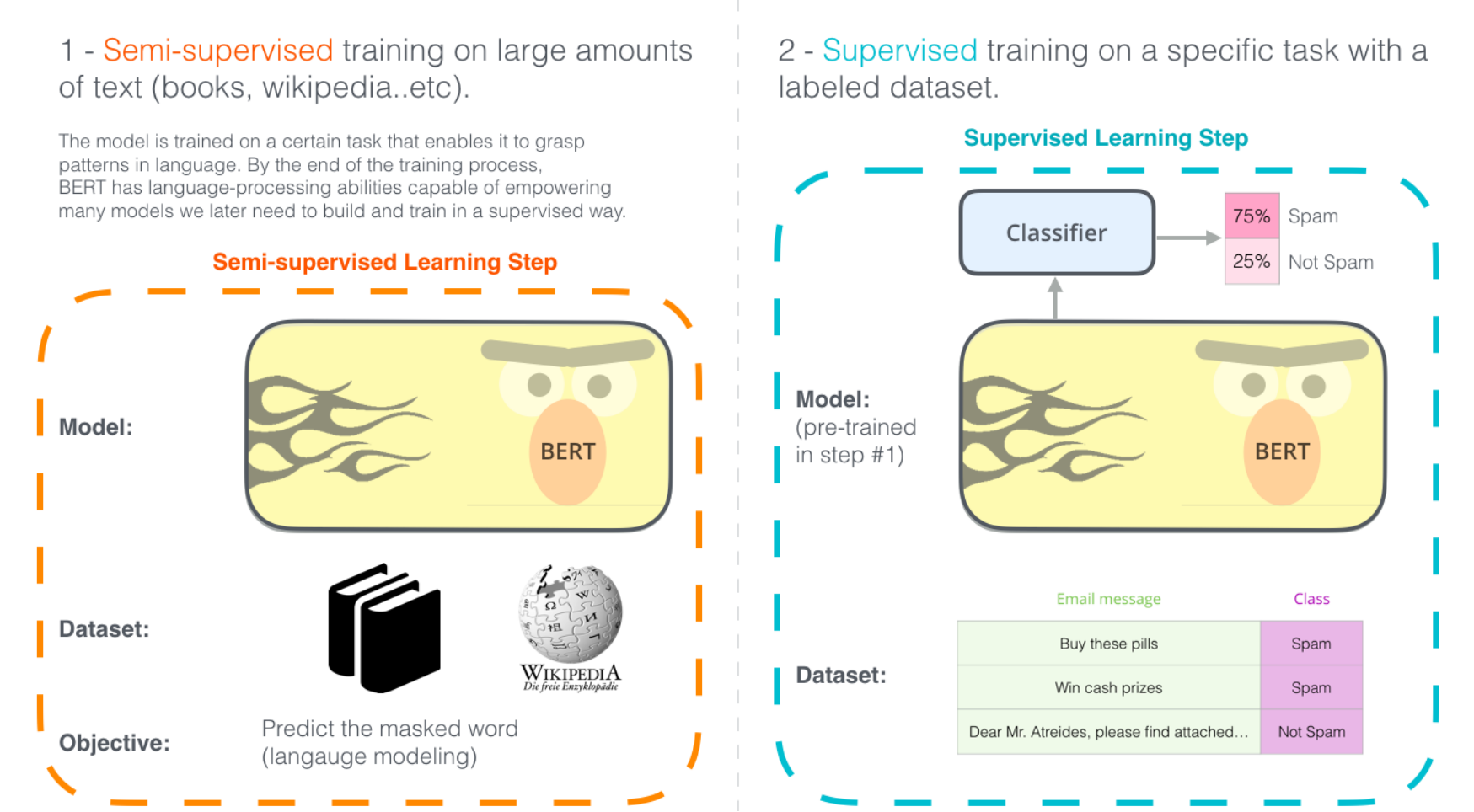
在监督学习中,训练数据集中的每一个样本都有明确的标签或类别。通过学习这些带有标签的数据,模型可以学习到输入数据和输出结果之间的映射关系,进而能够对新的、未标记的数据进行分类或预测。监督学习的目标是找到一个最佳的函数或者模型,使得训练数据集中的数据能够被准确分类或预测。
半监督学习则是一种介于监督学习和无监督学习之间的学习方式。在半监督学习中,训练数据集既包含有标签的数据,也包含未标记的数据。通过同时利用有标签和未标签的数据,半监督学习试图在保持模型性能的同时,提高模型的泛化能力。
简而言之,监督学习仅使用标记过的数据,而半监督学习则使用部分标记过的数据和部分未标记的数据。
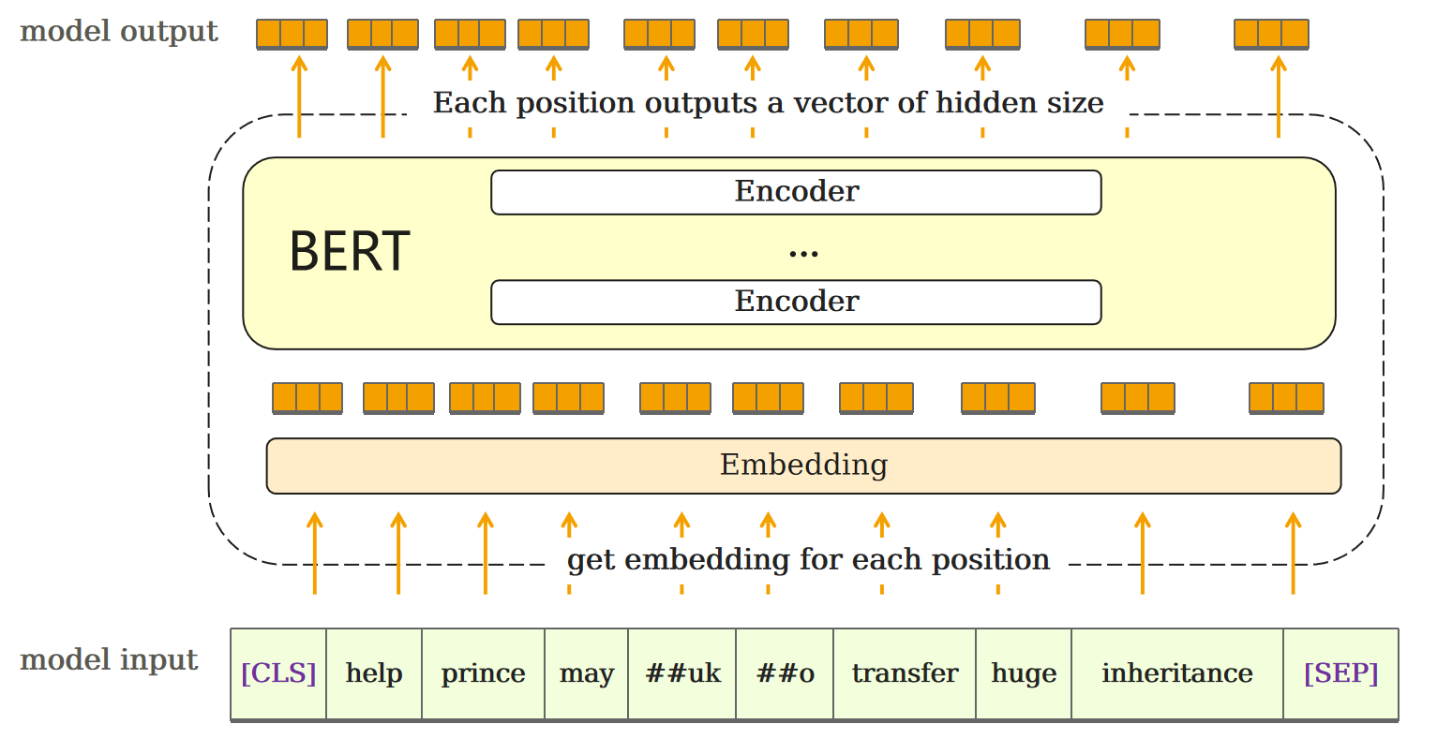
1.2.2BERT Input
- Tokenization,输入的句子经过分词后,首尾添加[CLS]与[SEP]特殊字符,后转换为数字id;
- Embedding, 输入到BERT模型的信息由三部分内容组成:- 表示内容的token ids- 表示位置的position ids- 用于区分不同句子的token type ids;
- 将三种信息分别输入Embedding层。
1.2.3BERT Architecture
BERT由Encoder Layer堆叠而成,Encoder Layer的组成:自注意力层 + 前馈神经网络,中间通过residual connection和LayerNorm连接。
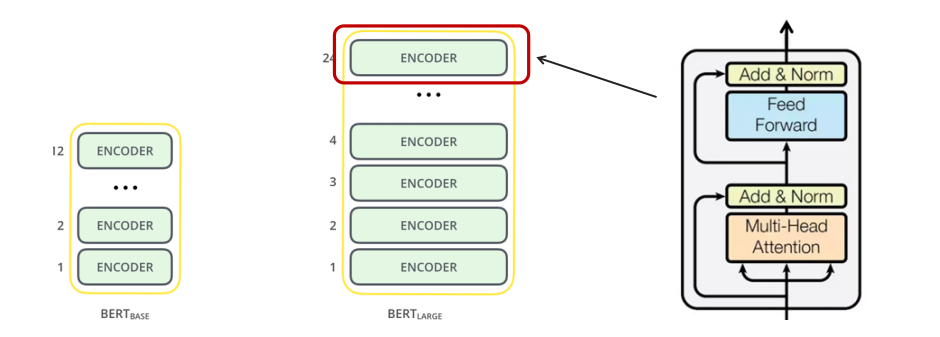
BERT的模型大小有如下两种:
BERT BASE:与Transformer参数量齐平,用于比较模型效果(110M parameters)
BERT LARGE:在BERT BASE基础上扩大参数量,达到了当时各任务最好的结果(340M parameters)
1.2.4BERT Output
BERT会针对每一个位置输出大小为hidden size的向量,在下游任务中,会根据任务内容的不同,选取不同的向量放入输出层。
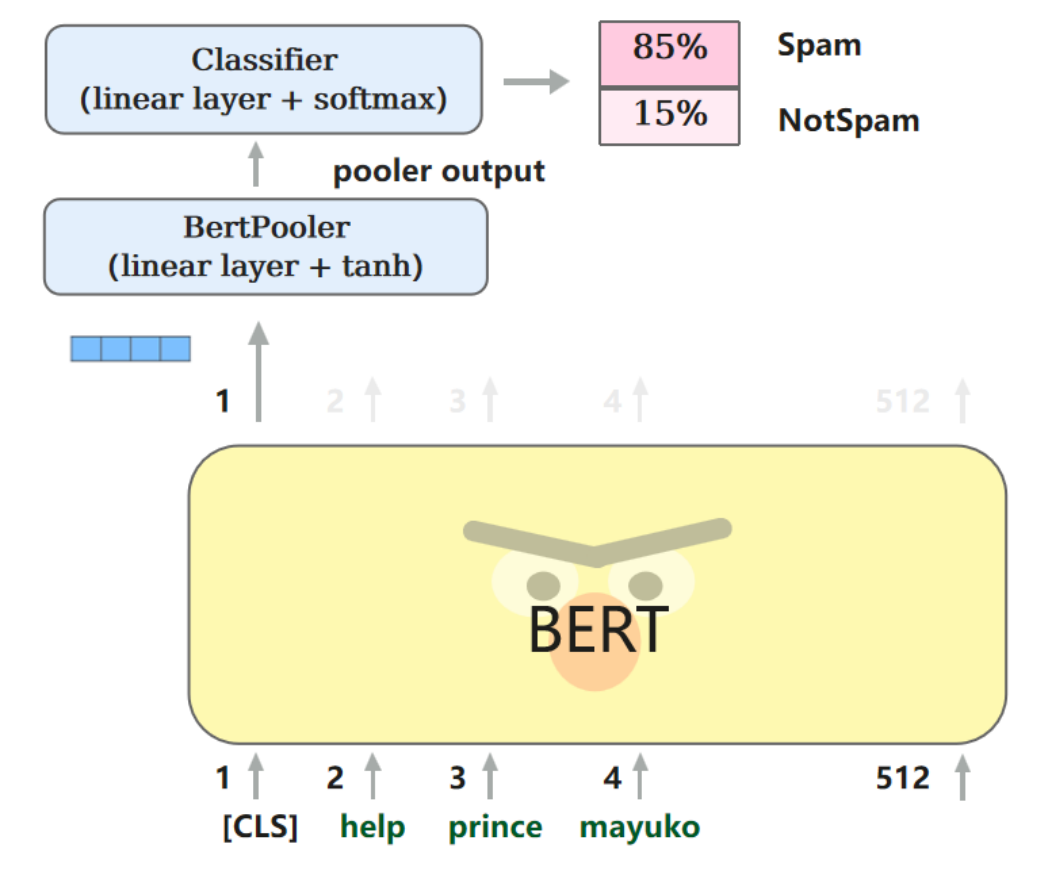
1.3BERT预训练
BERT预训练任务有两种:Masked Language Modelling(MLM) 和 Next Sentence Prediction (NSP)。MLM:随机遮盖输入句子中的一些词语,并预测被遮盖的词语是什么(完形填空)
NSP:预测两个句子是不是上下文的关系
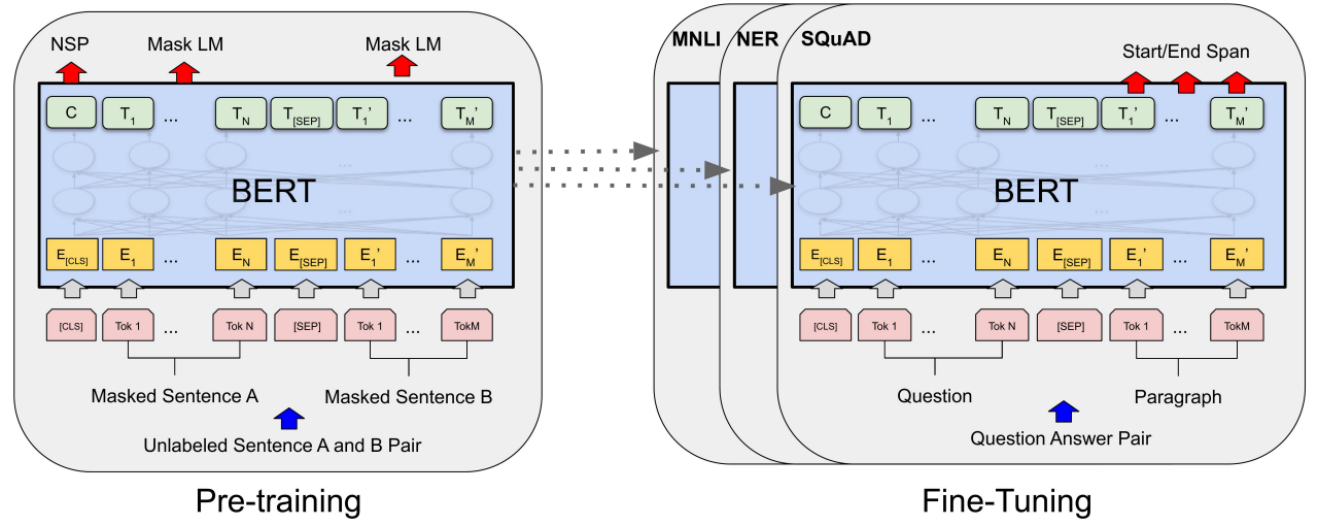
1.4BERT微调
在下游任务中,我们使用少量的标注数据(labelled data)对预训练Transformer编码器的所有参数进行微调,额外的输出层将从头开始训练。
2、学习心得
BERT的预训练方式使得它在各种NLP任务中都表现出了卓越的性能,这让我对深度学习在语言处理方面的应用有了更深入的理解。BERT模型本质上是结合了ELMo模型与GPT模型的优势。
相比于ELMo,BERT仅需改动最后的输出层,而非模型架构,便可以在下游任务中达到很好的效果;相比于GPT,BERT在处理词元表示时考虑到了双向上下文的信息。
3、经验分享
- 选择合适的预训练模型:BERT有不同的版本和变体,如BERT-Base和BERT-Large,以及不同的预训练数据集,如WikiText和BookCorpus。选择适合任务的预训练模型是很重要的。一般来说,更大的模型和更多的预训练数据可以提供更好的性能,但也需要更多的计算资源和时间来进行训练和推理。
- 进行适当的微调:微调是使BERT适应特定任务的关键步骤。通过微调,可以调整BERT模型的参数以适应特定任务,并提高模型的性能。选择适当的微调策略,如学习率、批量大小和训练轮数,以及调整输入序列的长度和标记化方法,都是非常重要的。
4、课程反馈
通过学习BERT,我对自然语言处理领域的发展趋势有了更清晰的认识。BERT作为Transformer架构的一种应用,体现了当前NLP领域对于大规模预训练模型和自监督学习的重视。
5、未来展望
学习BERT是一次非常宝贵的学习经历。它不仅提高了我的技术水平,也拓宽了我的视野,激发了我对自然语言处理领域的热情。我期待在未来的学习和工作中,能够更好地应用BERT和其他先进技术,为NLP领域的发展做出贡献。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)