Hello,MindSpore!入门模型最简教程体验指南
基于LeNet5的手写数字识别实验介绍LeNet5 + MNIST被誉为深度学习领域的“Hello world”。本实验主要介绍使用MindSpore在MNIST手写数字数据集上开发和训练一个LeNet5模型,并验证模型精度。今天就给大家做一个简简单单的模型案例复现,详情均可以阅读官网参考文档。数据集准备MNIST是一个手写数字数据集,训练集包含60000张手写数字,测试集包含10000张手写数字

基于LeNet5的手写数字识别
实验介绍
LeNet5 + MNIST被誉为深度学习领域的“Hello world”。
本实验主要介绍使用MindSpore在MNIST手写数字数据集上开发和训练一个LeNet5模型,并验证模型精度。今天就给大家做一个简简单单的模型案例复现,详情均可以阅读官网参考文档。
数据集准备
MNIST是一个手写数字数据集,训练集包含60000张手写数字,测试集包含10000张手写数字,共10类。MNIST数据集的官网:THE MNIST DATABASE。
• 方式一,从MNIST官网下载如下4个文件到本地并解压:
train-images-idx3-ubyte.gz: training set images (9912422 bytes)
train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
• 方式二,从华为云OBS中下载MNIST数据集并解压。
• 方式三(推荐),使用ModelArts训练作业/Notebook时,可以拷贝他人共享的OBS桶内的数据集,方法详见适配训练作业、数据拷贝。
脚本准备
从课程gitee仓库 上下载本实验相关脚本。将脚本和数据集组织为如下形式:
lenet5
├── MNIST
│ ├── test
│ │ ├── t10k-images-idx3-ubyte
│ │ └── t10k-labels-idx1-ubyte
│ └── train
│ ├── train-images-idx3-ubyte
│ └── train-labels-idx1-ubyte
└── main.py创建OBS桶
使用ModelArts训练作业/Notebook时,需要使用华为云OBS存储实验脚本和数据集,可以参考快速通过OBS控制台上传下载文件,了解使用OBS创建桶、上传文件、下载文件的使用方法(下文给出了操作步骤)。
提示: 华为云新用户使用OBS时通常需要创建和配置“访问密钥”,可以在使用OBS时根据提示完成创建和配置;也可以参考获取访问密钥并完成ModelArts全局配置获取并配置访问密钥。
打开OBS控制台,点击右上角的“创建桶”按钮进入桶配置页面,创建OBS桶的参考配置如下:
• 区域:华北-北京四
• 数据冗余存储策略:单AZ存储
• 桶名称:全局唯一的字符串
• 存储类别:标准存储
• 桶策略:公共读
• 归档数据直读:关闭
• 企业项目、标签等配置:免
上传文件
点击新建的OBS桶名,再打开“对象”标签页,通过“上传对象”、“新建文件夹”等功能,将脚本和数据集上传到OBS桶中。
上传文件后,查看页面底部的“任务管理”状态栏(正在运行、已完成、失败),确保文件均上传完成。
若失败请:
• 参考上传对象大小限制/切换上传方式;
• 参考上传对象失败常见原因;
• 若无法解决请新建工单,产品类为“对象存储服务”,问题类型为“桶和对象相关”,会有技术人员协助解决。
实验步骤(ModelArts训练作业)
ModelArts提供了训练作业服务,训练作业资源池大,且具有作业排队等功能,适合大规模并发使用。使用训练作业时,如果有修改代码和调试的需求,有如下三个方案:
1、在本地修改代码后重新上传;
2、使用PyCharm ToolKit 配置一个本地Pycharm+ModelArts的开发环境,便于上传代码、提交训练作业和获取训练日志;
3、在ModelArts上创建Notebook,然后设置Sync OBS功能,可以在线修改代码并自动同步到OBS中。因为只用Notebook来编辑代码,所以创建CPU类型最低规格的Notebook就行。
适配训练作业
创建训练作业时,运行参数会通过脚本传参的方式输入给脚本代码,脚本必须解析传参才能在代码中使用相应参数。如data_url和train_url,分别对应数据存储路径(OBS路径)和训练输出路径(OBS路径)。脚本对传参进行解析后赋值到args变量里,在后续代码里可以使用。
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--data_url', required=True, default=None, help='Location of data.')
parser.add_argument('--train_url', required=True, default=None, help='Location of training outputs.')
args, unknown = parser.parse_known_args()
MindSpore暂时没有提供直接访问OBS数据的接口,需要通过ModelArts自带的moxing框架与OBS交互。
• 方式一,拷贝自己账户下OBS桶内的数据集至执行容器。
import moxing
• # src_url形如's3://OBS/PATH',为OBS桶中数据集的路径,dst_url为执行容器中的路径
• moxing.file.copy_parallel(src_url=args.data_url, dst_url='MNIST/')
• 方式二(推荐),拷贝他人共享的OBS桶内的数据集至执行容器,前提是他人账户下的OBS桶已设为公共读/公共读写。若在创建桶时桶策略为私有,请参考配置标准桶策略 修改为公共读/公共读写。
import moxing
• moxing.file.copy_parallel(src_url="s3://share-course/dataset/MNIST/", dst_url='MNIST/')
• 方式三(不推荐),先关联他人私有账户,再拷贝他人账户下OBS桶内的数据集至执行容器,前提是已获得他人账户的访问密钥、私有访问密钥、OBS桶-概览-基本信息-Endpoint。
import moxing
• # 设置他人账户的访问密钥, ak:Access Key Id, sk:Secret Access Key, server:endpoint of obs bucket
• moxing.file.set_auth(ak='Access Key', sk='Secret Access Key', server="obs.cn-north-4.myhuaweicloud.com")
• moxing.file.copy_parallel(src_url="s3://share-course/dataset/MNIST/", dst_url='MNIST/')创建训练作业
可以参考使用常用框架训练模型 来创建并启动训练作业(下文给出了操作步骤)。
打开ModelArts控制台-训练管理-训练作业 ,点击“创建”按钮进入训练作业配置页面,创建训练作业的参考配置:
• 算法来源:常用框架->Ascend-Powered-Engine->MindSpore
• 代码目录:选择上述新建的OBS桶中的lenet5目录,用obs browser+上传
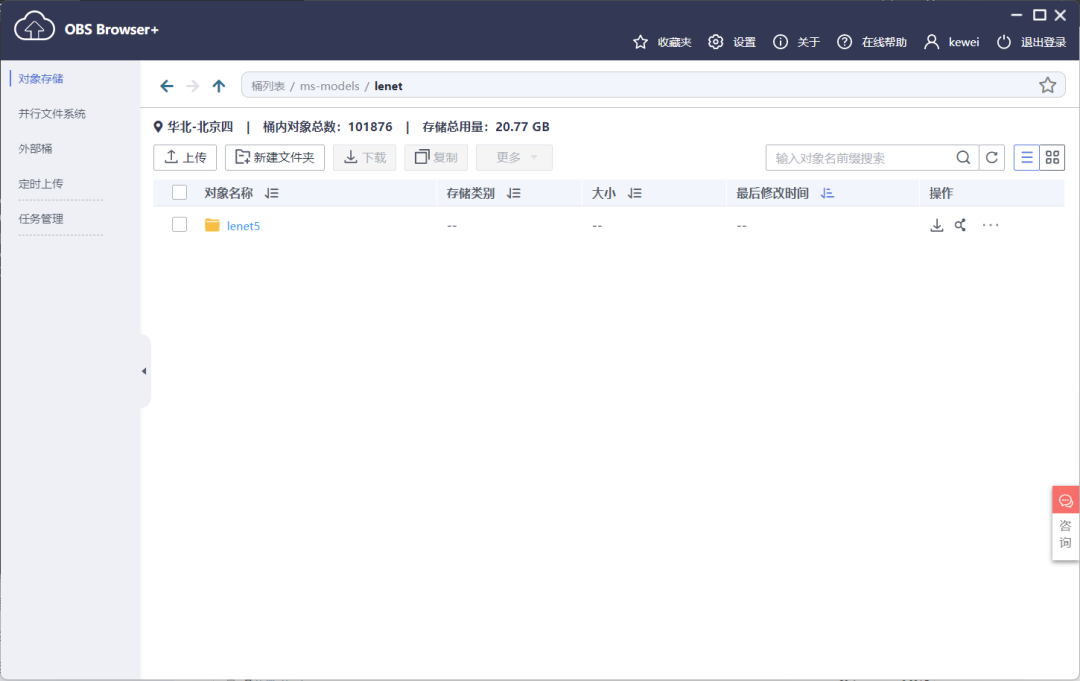
• 启动文件:选择上述新建的OBS桶中的lenet5目录下的main.py,快速创建算法
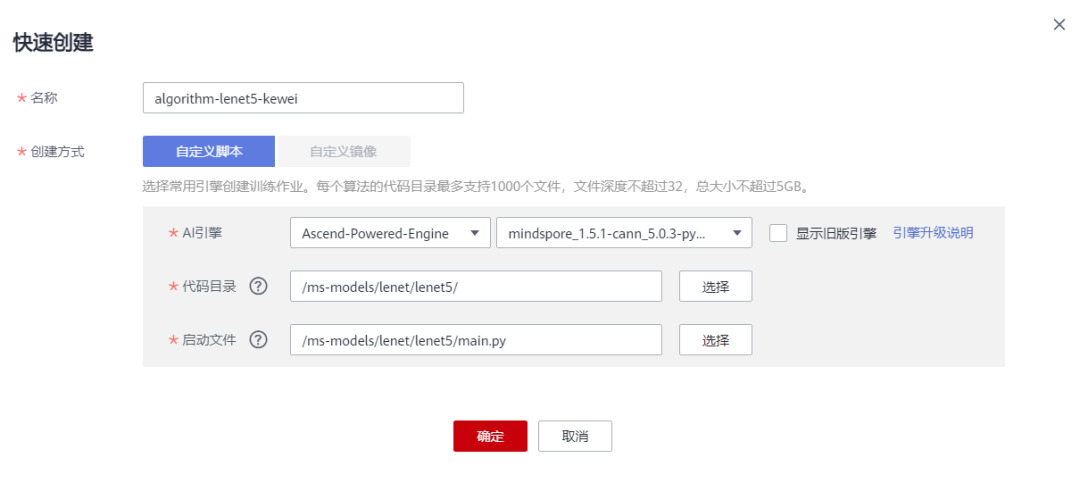
• 数据来源:数据存储位置->选择上述新建的OBS桶中的lenet5目录下的MNIST目录
• 训练输出位置:选择上述新建的OBS桶中的lenet5目录并在其中创建output目录
• 作业日志路径:同训练输出位置
• 规格:Ascend:1*Ascend 910
• 其他均为默认
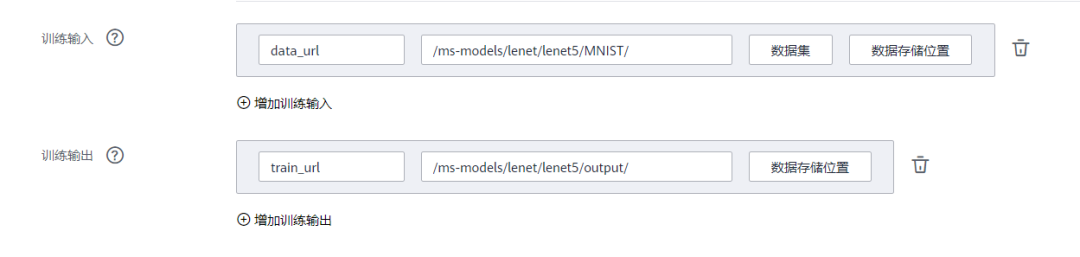
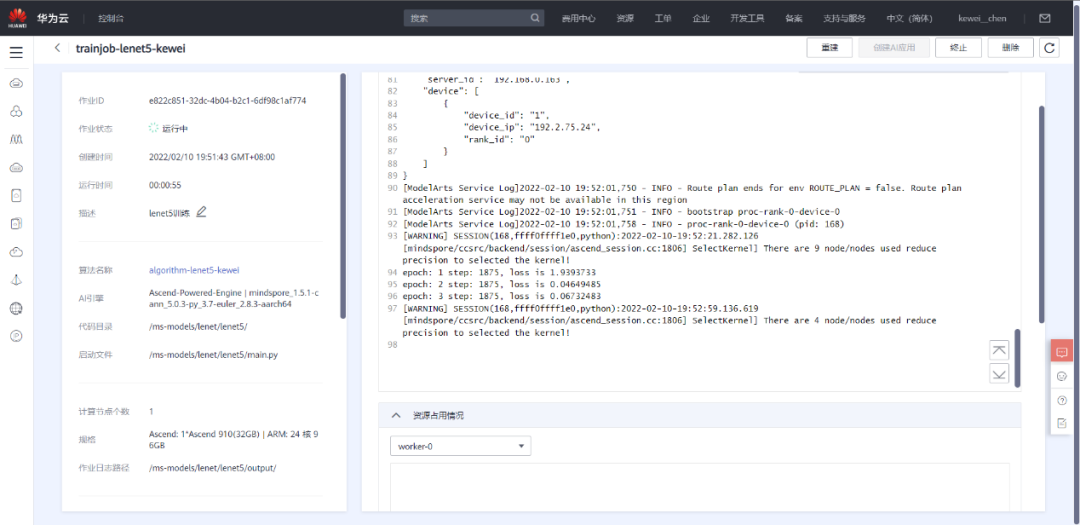
启动并查看训练过程:
1. 点击提交以开始训练;
2. 在训练作业列表里可以看到刚创建的训练作业,在训练作业页面可以看到版本管理;
3. 点击运行中的训练作业,在展开的窗口中可以查看作业配置信息,以及训练过程中的日志,日志会不断刷新,等训练作业完成后也可以下载日志到本地进行查看;
4. 参考实验步骤(ModelArts Notebook),在日志中找到对应的打印信息,检查实验是否成功。
epoch: 1 step: 1875, loss is 1.9393733
6. epoch: 2 step: 1875, loss is 0.04649485
7. epoch: 3 step: 1875, loss is 0.06732483
8. [WARNING] SESSION(168,ffff0ffff1e0,python):2022-02-10-19:52:59.136.619 [mindspore/ccsrc/backend/session/ascend_session.cc:1806] SelectKernel] There are 4 node/nodes used reduce precision to selected the kernel!
9. Metrics: {'loss': 0.07129916341009682, 'acc': 0.9781650641025641}实验步骤
(ModelArts Notebook)
ModelArts Notebook资源池较小,且每个运行中的Notebook会一直占用Device资源不释放,不适合大规模并发使用(不使用时需停止实例,以释放资源)。
创建Notebook
可以参考创建并打开Notebook 来创建并打开Notebook(下文给出了操作步骤)。
打开ModelArts控制台-开发环境-Notebook,点击“创建”按钮进入Notebook配置页面,创建Notebook的参考配置:
• 计费模式:按需计费
• 名称:notebook-lenet5
• 工作环境:公共镜像->Ascend+ARM算法开发和训练基础镜像,AI引擎预置TensorFlow和MindSpore
• 资源池:公共资源
• 类型:Ascend
• 规格:单卡1*Ascend 910
• 存储位置:对象存储服务(OBS)->选择上述新建的OBS桶中的lenet5文件夹(此为旧版操作,新版有所变更,请看下面详细叙述)
• 自动停止:打开->选择1小时后(后续可在Notebook中随时调整)
将数据添加到并行文件系统中
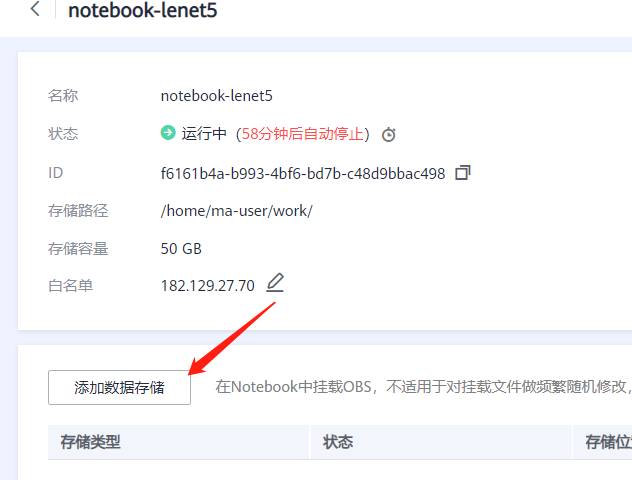
创建完成后,添加数据存储,将数据挂载到data目录下即可。
打开Notebook后,选择MindSpore环境作为Kernel。
导入模块
导入MindSpore模块和辅助模块,设置MindSpore上下文,如执行模式、设备等。
import os
# os.environ['DEVICE_ID'] = '0'
import mindspore as ms
import mindspore.context as context
import mindspore.dataset.transforms.c_transforms as C
import mindspore.dataset.vision.c_transforms as CV
from mindspore import nn
from mindspore.train import Model
from mindspore.train.callback import LossMonitor
context.set_context(mode=context.GRAPH_MODE, device_target='Ascend') # Ascend, CPU, GPU
数据处理
在使用数据集训练网络前,首先需要对数据进行预处理,如下:
def create_dataset(data_dir, training=True, batch_size=32, resize=(32, 32),
rescale=1/(255*0.3081), shift=-0.1307/0.3081, buffer_size=64):
data_train = os.path.join(data_dir, 'train') # train set
data_test = os.path.join(data_dir, 'test') # test set
ds = ms.dataset.MnistDataset(data_train if training else data_test)
ds = ds.map(input_columns=["image"], operations=[CV.Resize(resize), CV.Rescale(rescale, shift), CV.HWC2CHW()])
ds = ds.map(input_columns=["label"], operations=C.TypeCast(ms.int32))
# When `dataset_sink_mode=True` on Ascend, append `ds = ds.repeat(num_epochs) to the end
ds = ds.shuffle(buffer_size=buffer_size).batch(batch_size, drop_remainder=True)
return ds
对其中几张图片进行可视化,可以看到图片中的手写数字,图片的大小为32x32。
import matplotlib.pyplot as plt
ds = create_dataset('data/lenet/lenet5/MNIST', training=False)#修改为挂载路径即可
data = ds.create_dict_iterator(output_numpy=True).get_next()
images = data['image']
labels = data['label']
for i in range(1, 5):
plt.subplot(2, 2, i)
plt.imshow(images[i][0])
plt.title('Number: %s' % labels[i])
plt.xticks([])
plt.show()
定义模型
定义LeNet5模型
class LeNet5(nn.Cell):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5, stride=1, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, stride=1, pad_mode='valid')
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
self.fc1 = nn.Dense(400, 120)
self.fc2 = nn.Dense(120, 84)
self.fc3 = nn.Dense(84, 10)
def construct(self, x):
x = self.relu(self.conv1(x))
x = self.pool(x)
x = self.relu(self.conv2(x))
x = self.pool(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
训练
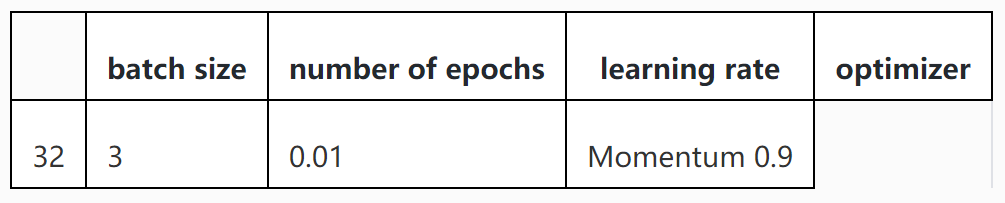
使用MNIST数据集对上述定义的LeNet5模型进行训练。训练策略如下表所示,可以调整训练策略并查看训练效果,要求验证精度大于95%。
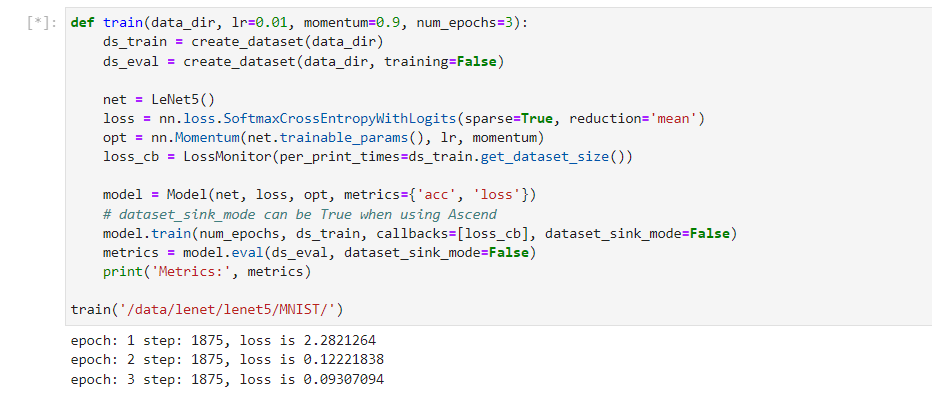
def train(data_dir, lr=0.01, momentum=0.9, num_epochs=3):
ds_train = create_dataset(data_dir)
ds_eval = create_dataset(data_dir, training=False)
net = LeNet5()
loss = nn.loss.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
opt = nn.Momentum(net.trainable_params(), lr, momentum)
loss_cb = LossMonitor(per_print_times=ds_train.get_dataset_size())
model = Model(net, loss, opt, metrics={'acc', 'loss'})
# dataset_sink_mode can be True when using Ascend
model.train(num_epochs, ds_train, callbacks=[loss_cb], dataset_sink_mode=False)
metrics = model.eval(ds_eval, dataset_sink_mode=False)
print('Metrics:', metrics)
train('data/lenet/lenet5/MNIST/')#此处我们修改为自己的挂载路径即可
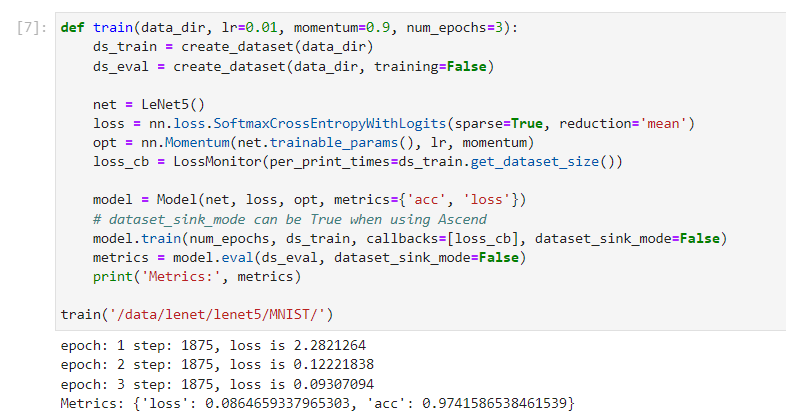
训练完成。
实验步骤
(本地CPU/GPU/Ascend)
MindSpore还支持在本地CPU/GPU/Ascend环境上运行,如Windows/Ubuntu x64笔记本,NVIDIA GPU服务器,以及Atlas Ascend服务器等。在本地环境运行实验前,需要先参考安装教程配置环境。
在Windows/Ubuntu x64笔记本上运行实验:
# 编辑main.py 将第15行的context设置为`device_target='CPU'或者'GPU'
python main.py --data_url=.\MNIST#拷贝到当前文件夹,也可自定义路径。

实验小结
本实验展示了如何使用MindSpore进行手写数字识别,以及开发和训练LeNet5模型。
通过对LeNet5模型做几代的训练,然后使用训练后的LeNet5模型对手写数字进行识别,识别准确率大于95%,即LeNet5学习到了如何进行手写数字识别。

MindSpore官方资料
GitHub : https://github.com/mindspore-ai/mindspore
Gitee : https : //gitee.com/mindspore/mindspore
官方QQ群 : 486831414

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 1
1 0
0- 0



 已为社区贡献1191条内容
已为社区贡献1191条内容

所有评论(0)