MindSpore入门——数据处理流程
MindSpore中数据处理流程
数据是深度学习的基础,高质量数据输入会在整个深度神经网络中起到积极作用。
数据处理流程:输入Tensor–数据处理–输入到神经网络模型–数据的加载–数据的迭代–数据的处理与增强。
数据处理流程
Load
在网络训练和推理流程中,原始数据一般存储在磁盘或数据库中,需要首先通过数据加载步骤将其读取到内存空间,通过采样器sampier把一部分的数据加载到内存中,然后转换成神经网络模型需要的Tensor格式。
Transform
上一步的数据输入到Transform模块,然后Transform模块对数据进行一系列的处理、变换和增强,如:打散、清洗等操作,将其映射到更加易于学习的特征空间。作用就是让数据更加丰富、提升数据泛化性。
Train
处理之后的数据会输入到网络模型中,真正的开始进行训练。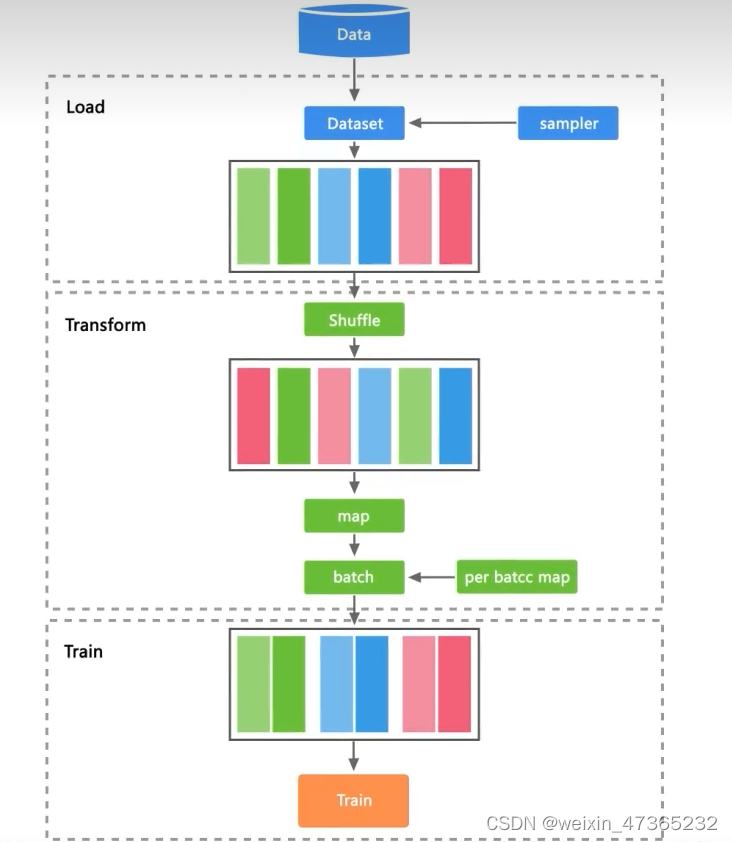
相关问题
为什么要对初始的数据集进行打散?
如果不打乱数据集,每次都输入同一批相同的数据,有可能导致网络模型出现过拟合的现象。
一般来说,batch_size参数是什么意思?batch_size表示每一组包含的数据个数,比如加载的数据为图片集,为了加速运算,每次不是只计算一张图片,而是计算一堆图片,因此会对一堆数据进行打包,一次过塞进去到神经网络中。
实验中,如果数据太多会造成过拟合,数据太少网络模型训练不起来,训练精度不达标,这种情况应该怎么办?
进行数据增强:把当前数据变得更多,变得更宽,变得更广,让神经网络训练的时候拥有更多的数据。
比如现在数据集只有100张图片,对图片裁剪,把裁剪后的图片当作新的图片,那么图片数量就翻倍了。甚至,对图片进行变换颜色、增强噪声,100张图片可以源源不断地产生新的图片,拥有更多的数据进行训练。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)