基于Ascend C开发具备泛化能力的Vector算子:我的代码重构与思考
简单说,你的算子不能是“硬编码”的。Hard-Coded(差):假设每次处理256个fp16数据,循环10次。Generalized(好):给我任意长度N(比如 10001),我都能自动算出需要循环多少次,最后一次剩多少数据,并且不出错。Tiling切分:怎么把任意长度的数据切成适合UB(Unified Buffer)大小的块?尾块处理:最后一块数据如果不满足32字节对齐,或者填不满一个Block
我将还原一个真实场景:最开始写的算子只能跑固定Shape(比如1024),一换数据长度就崩。 然后通过学习**“具备泛化能力的Vector算子”**课程,对代码进行重构,使其能够适应任意长度、任意切分策略的过程。
前言:代码能跑,和代码能用,是两码事

在参加CANN训练营的前几天,我照着官方Sample写了一个 Add 算子。当时觉得挺简单:定义输入输出,写个循环,调用 Add 指令,齐活。
结果,当我把测试用例的输入长度从 2048 改成 2050 时,程序直接 Core Dump 了。
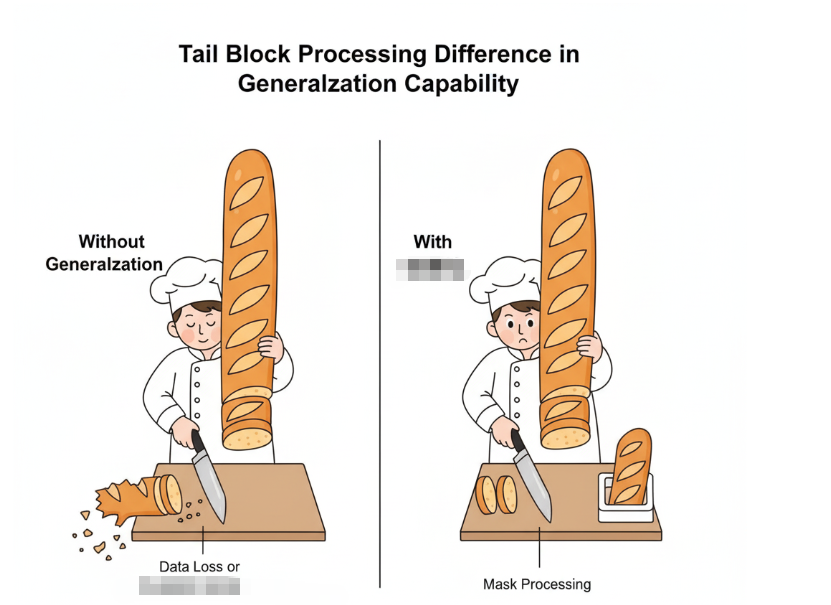
这时候我才深刻理解图3里那节课标题的含金量——“具备泛化能力”。
一个只能跑固定Shape的算子,在生产环境就是废铁。
这两天我把代码推倒重来,重点解决了Tiling策略动态化和尾块(Tail Block)处理这两个痛点。今天就来分享一下我的重构思路。
一、 什么是“泛化能力”?
简单说,你的算子不能是“硬编码”的。
- Hard-Coded(差):假设每次处理256个fp16数据,循环10次。
- Generalized(好):给我任意长度
N(比如 10001),我都能自动算出需要循环多少次,最后一次剩多少数据,并且不出错。
在Ascend C中,泛化能力的拦路虎主要有两个:
- Tiling切分:怎么把任意长度的数据切成适合UB(Unified Buffer)大小的块?
- 尾块处理:最后一块数据如果不满足32字节对齐,或者填不满一个Block,怎么算?
二、 重构第一步:Host侧Tiling的动态化
之前的代码,我的 BLOCK_DIM 是写死在头文件里的。
重构后,我把逻辑移到了 Host侧(CPU)。
思考逻辑:
Host侧拿到 totalLength,根据NPU的核数(Core Num)和UB的大小,动态计算出:
tileNum: 总共切几块?tileLength: 每块多大?lastTileLength: 最后一块多大?
重构后的Tiling代码片段(代码):
// 以前我是写死的: context->SetTilingKey(1);
// 重构后:
uint32_t totalLength = context->GetInputDesc(0)->GetShape().GetDim(0);
uint32_t ubSize = ...; // 获取硬件UB大小
// 计算策略...
tiling.set_totalLength(totalLength);
tiling.set_tileNum(totalLength / tileLength);
tiling.set_lastTileLength(totalLength % tileLength);
// 序列化并发给Device
context->SetTilingData(tiling);
这一步做完,无论输入是几百万还是几百,Kernel侧拿到的参数都是“量身定制”的。
三、 重构第二步:Kernel侧的“尾块”保卫战
Device侧拿到Tiling参数后,循环处理前 N-1 块都很简单,因为它们是完整的。
最要命的是最后一块(Tail)。
3.1 为什么要用Mask?
在Vector计算中,指令通常是按照Block(32字节)批量执行的。
假设最后只剩下 10 个 half 类型的数据(20字节),不够一个Block。
如果你直接算一个Block,就会读到后面 12 字节的脏数据,甚至导致内存越界。
解决方案:Mask(掩码)。
Ascend C的计算指令(如 Add, Mul)都支持Mask参数。通过Mask,我们可以告诉硬件:“只算前20个字节,后面的别碰!”
3.2 重构前后的代码对比
🔴 重构前(只能跑整块):
// 假设tileLength总是对齐的
__aicore__ inline void Compute(int32_t progressIdx)
{
// ... CopyIn ...
// 直接全量计算,没有任何保护
Add(zLocal, xLocal, yLocal, this->tileLength);
// ... CopyOut ...
}
🟢 重构后(具备泛化能力):
__aicore__ inline void Process()
{
int32_t loopCount = this->tileNum;
for (int32_t i = 0; i < loopCount; i++) {
// 判断是不是最后一块
bool isLast = (i == loopCount - 1);
uint32_t currentLen = isLast ? this->lastTileLength : this->tileLength;
Compute(i, currentLen);
}
}
__aicore__ inline void Compute(int32_t progressIdx, uint32_t len)
{
// ... CopyIn ...
// 【关键点】利用DataCopyPad或Mask机制处理
// 这里展示计算指令的泛化
// 如果len不是256字节倍数,API会自动根据len生成Mask
Add(zLocal, xLocal, yLocal, len);
// ... CopyOut ...
}

思考:
Ascend C的新版API其实非常智能。像 Add(..., len) 这种接口,如果你传入的 len 不是对齐的,它底层会自动处理Mask逻辑(只要数据量满足最小限制)。但在更底层的开发中,手动设置 SetVectorMask 依然是必修课。
四、 总结:从“玩具”到“工具”
通过这次重构,我的算子终于从一个“只能演示的Demo”变成了一个“能扛实战的工具”。
开发具备泛化能力的算子,核心就三点:
- Host侧要把账算细(Tiling策略)。
- Kernel侧要把关守好(循环边界)。
- 指令调用要带好盾牌(Mask机制)。
在CANN训练营的图3课程中,对这些细节有非常详细的源码级讲解。如果你也在写算子,建议一定要去看看那段关于“泛化能力”的视频,能帮你省下好几天Debug Core Dump的时间。
🔥 2025昇腾CANN训练营·第二季 报名开启!
别让你的AI模型只跑在黑盒子里,来这里,亲手拆解它!
👇 扫码/点击链接,硬核玩家速来集合:
https://www.hiascend.com/developer/activities/cann20252

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)