昇思学习营-模型推理和性能优化
推理效果的调优:对于部分推理输出中会出现重复性的语句可以在上面提到的generate_kwargs配置中加入repetition_penalty=1.2来处理,如下图所示。基于权重加载和启动推理,就mindspore框架来说,基于lora微调后的推理流程分别为加载基础模型参数和微调参数,如下图代码所示。下面三段代码的截图为载入模型、配置模型的对话参数及模型对话功能演示。2. mindspore.j
Midnspore框架下大模型的整体部署流程:

DeepSeek-R1-Distill-Qwen-1.5B 模型推理流程:
基于权重加载和启动推理,就mindspore框架来说,基于lora微调后的推理流程分别为加载基础模型参数和微调参数,如下图代码所示

基于model.generate进行推理,相关参数如下图所示:
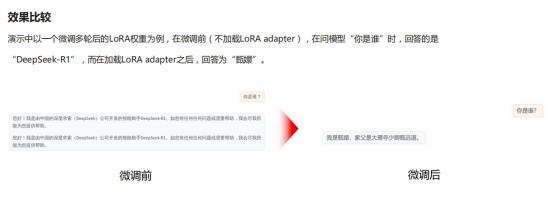
微调前和微调后的回答效果比较如下:
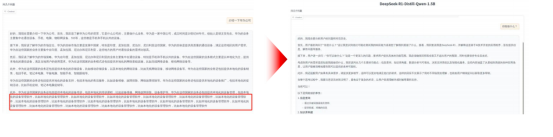
推理效果的调优:对于部分推理输出中会出现重复性的语句可以在上面提到的generate_kwargs配置中加入repetition_penalty=1.2来处理,如下图所示。
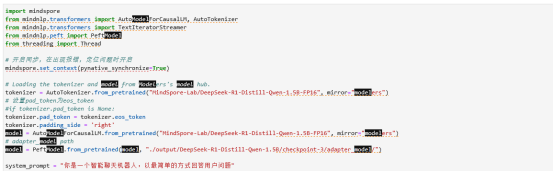
 、
、
下面三段代码的截图为载入模型、配置模型的对话参数及模型对话功能演示。

性能测试及优化:
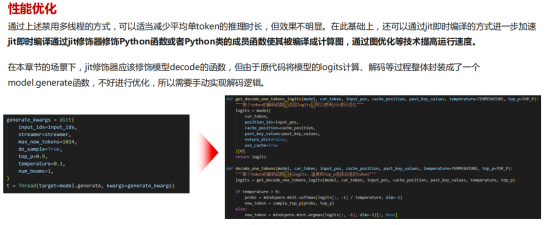
Mindspore中对模型推理优化通过禁用多线程外,可以通过jit来进行优化,如下图所示:
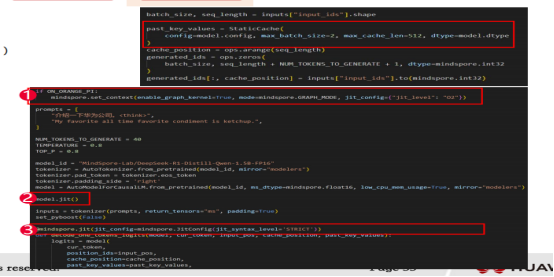
性能优化的前序准备包含下面流程:
1. 实现解码逻辑(decode函数、prefill-decode阶段)
2. 实例化StaticCache,动态Cache无法成图
添加jit装饰器
1. model.jit()
2. mindspore.jit装饰decode函数
整体流程如下图所示:
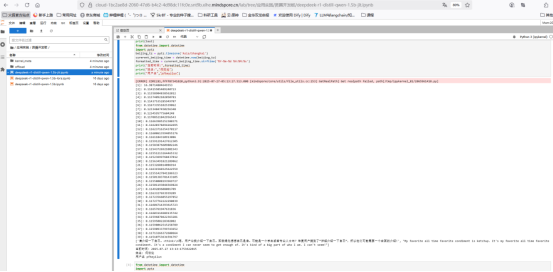
最后,整体优化后的每个token的输出时间如下所示:
学习心得:
1.了解mindspore的模型部署流程
- 对mindspore的模型微调训练后的参数如何加载进行了解
- 对于模型静态图和动态图的执行效率进行分析
- 对mindspore的jit模块的优化流程进行了解
- 对jit模块优化后的模型推理效果有一定程度的了解

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 2
2 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)