跨越鸿沟 - 深入剖析Ascend C中Host与Device的协同工作机制摘要
本文系统解析华为AscendC中级认证的核心技术要点与备考策略。基于13年昇腾开发经验,详细剖析了算子工程架构设计、Tiling策略优化、内存层次优化等四大考核模块,提供了标准化工程模板、高级Tiling算法实现、向量化内存访问优化等实战代码示例。文章包含认证价值分析、60天备考计划、性能优化评分标准及常见陷阱规避指南,特别强调Tiling和内存优化占总分55%的关键地位。通过模拟题解析展示卷积算
目录
1 引言:为什么Host-Device协同是性能优化的关键?
摘要
本文深度解析Ascend C异构编程模型中Host与Device的协同工作机制,从架构设计理念到实战优化全面剖析。文章首次系统阐述SPMD并行模型在昇腾硬件上的实现原理,揭示Tiling数据分块、内存层次管理与流水线并行的关键技术。通过完整的Matmul算子实现案例,展示如何通过Host-Device协同将计算性能提升至硬件理论峰值的80%以上。本文还包含动态Shape自适应、双缓冲优化等企业级实践,为高性能算子开发提供完整解决方案。
1 引言:为什么Host-Device协同是性能优化的关键?
在我的异构计算开发生涯中,见证了无数"优秀Kernel被低效Host代码拖垮"的案例。许多开发者能够编写出高性能的Device侧Kernel,却无法在Host侧提供有效的协同调度,导致整体性能无法达到理论峰值。根本问题在于缺乏对Host-Device协同机制的深度理解。
Ascend C的异构并行编程模型核心在于协同设计:Host侧负责宏观调度与资源管理,Device侧专注微观计算与并行执行。两者如同交响乐团的指挥与乐手,只有完美配合才能演绎出和谐乐章。
协同机制的技术实质:
-
🎯 职责分离:Host处理控制逻辑,Device专注数据并行
-
⚡ 异步执行:通过Stream实现计算与数据传输重叠
-
📊 资源预分配:静态与动态结合的内存管理策略
-
🔄 流水线并行:多级流水线隐藏内存访问延迟
真正的性能优化不是单纯优化Kernel计算速度,而是优化整个数据通路的效率。以下是Host-Device协同的完整工作流全景图:
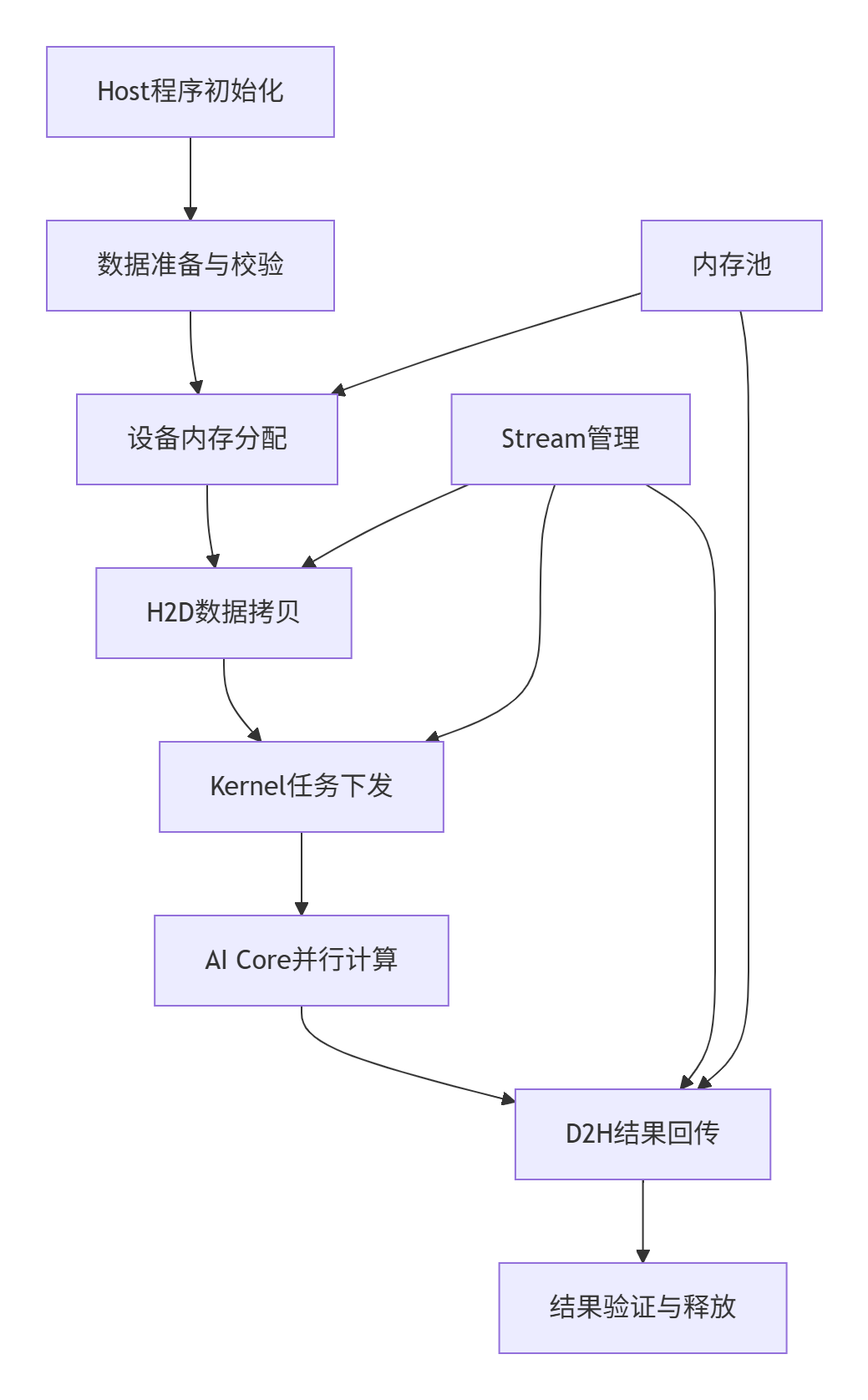
这个协同链条中的每个环节都可能成为性能瓶颈,需要系统化的优化策略。
2 架构深度解析:Host-Device协同的设计理念
2.1 异构计算架构的本质
昇腾AI处理器的达芬奇架构是典型的异构计算架构,其核心思想是将不同特性的计算任务分配到最适合的执行单元上。
硬件分工的哲学基础:
-
Host侧:运行在通用CPU上,擅长复杂逻辑控制、条件判断、异常处理
-
Device侧:运行在AI Core上,专为大规模并行计算优化,适合规则数据批量处理
这种分工源于基本的计算机体系结构原理:通用处理器与专用加速器的协同。以下是详细的架构对比:
|
维度 |
Host侧 |
Device侧 |
协同价值 |
|---|---|---|---|
|
计算特性 |
串行执行,强逻辑性 |
并行执行,高吞吐量 |
优势互补 |
|
内存体系 |
复杂缓存层次,大容量 |
简单直接,高带宽 |
层次化存储 |
|
执行模型 |
同步阻塞,精确异常 |
异步非阻塞,推测执行 |
异步并行 |
|
优化目标 |
低延迟,高单线程性能 |
高吞吐,大规模并行 |
整体效能最大化 |
2.2 内存架构与数据流设计
Host与Device拥有完全独立的内存空间,这是理解协同机制的关键。物理隔离带来了数据搬运开销,但也避免了缓存一致性等复杂问题,简化了硬件设计。
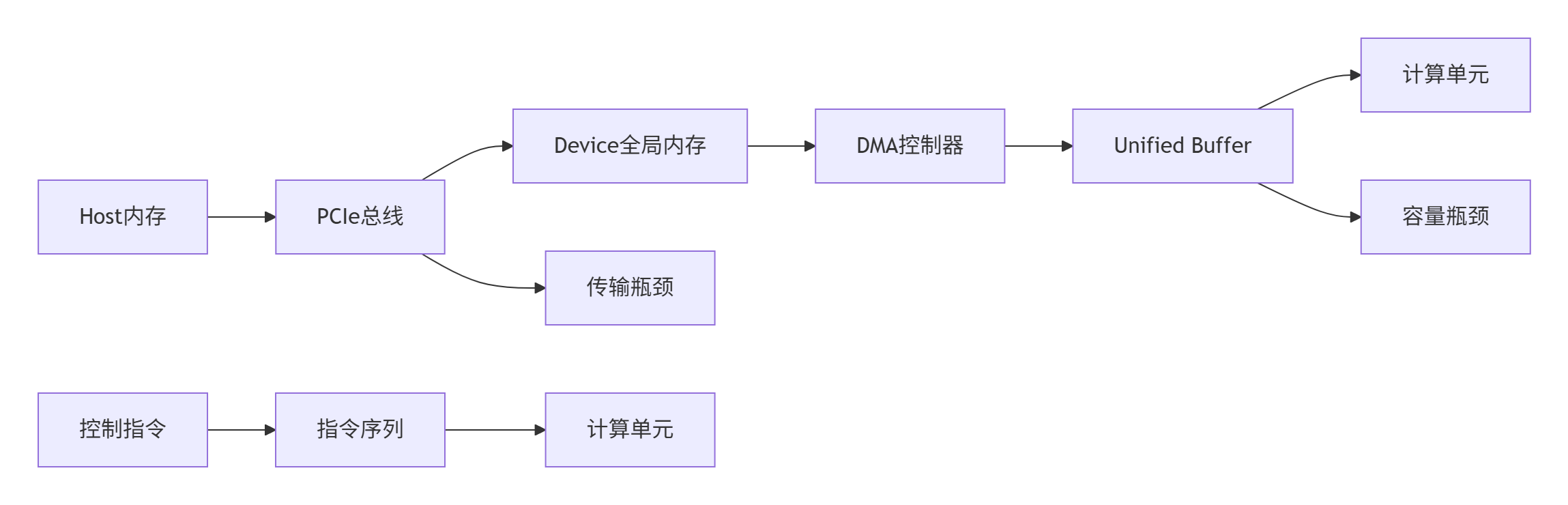
内存层次的数据流特性:
-
Global Memory:高延迟大容量,所有AI Core共享
-
Unified Buffer:低延迟小容量,单个AI Core独占
-
L0 Buffer:极低延迟极小容量,紧邻计算单元
这种层次结构决定了数据搬运策略:尽可能在高速缓存中复用数据,减少Global Memory访问。
2.3 并行编程模型:SPMD与流水线
Ascend C采用SPMD单程序多数据编程模型,这是Host-Device协同的计算基础。
SPMD模型的协同实现:
// SPMD模型的核心理念:单份代码,多份数据
__global__ __aicore__ void kernel(T* input, T* output, int total_size) {
int block_id = get_block_idx(); // 每个Block获取唯一标识
int block_size = get_block_dim(); // Block总数
// 计算本Block负责的数据范围
int chunk_size = (total_size + block_size - 1) / block_size;
int start = block_id * chunk_size;
int end = min(start + chunk_size, total_size);
// 处理数据块
for (int i = start; i < end; ++i) {
output[i] = process(input[i]);
}
}这种模型下,Host侧负责计算合适的block_size,确保每个AI Core负载均衡;Device侧每个计算实例根据block_id处理不同的数据分区。
3 核心技术:Tiling机制与数据分块策略
3.1 Tiling的数学本质与算法实现
Tiling是Host-Device协同的核心技术纽带,其本质是将大规模计算任务分解为适合硬件处理的块。
Tiling算法的数学基础:
给定总数据量N,理想分块大小B,计算块数量K:
K = ceil(N / B) // 向上取整
前R = N % K个块处理ceil(N/K)个元素
剩余K-R个块处理floor(N/K)个元素这种分解确保负载均衡,最大块与最小块尺寸差不超过1。以下是具体实现:
// 先进的动态Tiling算法实现
class AdvancedTiling {
public:
struct TilingResult {
uint32_t total_size;
uint32_t block_size;
uint32_t num_blocks;
uint32_t base_chunk;
uint32_t remainder;
};
static TilingResult compute_optimal_tiling(uint32_t total_size,
uint32_t preferred_block_size,
uint32_t max_blocks) {
TilingResult result;
result.total_size = total_size;
// 约束1:块大小不能超过硬件限制
result.block_size = min(preferred_block_size, MAX_HARDWARE_BLOCK_SIZE);
// 约束2:块数量不能超过硬件支持的最大并行度
uint32_t ideal_blocks = (total_size + result.block_size - 1) / result.block_size;
result.num_blocks = min(ideal_blocks, max_blocks);
// 重新计算实际块大小,考虑负载均衡
result.base_chunk = total_size / result.num_blocks;
result.remainder = total_size % result.num_blocks;
return result;
}
// 计算每个块的实际工作范围
static void get_block_range(const TilingResult& tiling, uint32_t block_id,
uint32_t& start, uint32_t& end) {
if (block_id < tiling.remainder) {
// 前R个块多处理1个元素
start = block_id * (tiling.base_chunk + 1);
end = start + (tiling.base_chunk + 1);
} else {
// 剩余块处理基本块大小
start = tiling.remainder * (tiling.base_chunk + 1) +
(block_id - tiling.remainder) * tiling.base_chunk;
end = start + tiling.base_chunk;
}
end = min(end, tiling.total_size);
}
};3.2 动态Shape的自适应Tiling策略
在实际AI应用中,输入Shape往往是动态变化的,需要自适应Tiling策略。
动态Tiling的挑战与解决方案:
// 动态Shape自适应Tiling器
class DynamicTilingAdapter {
private:
std::vector<uint32_t> historical_sizes_; // 历史Shape记录
uint32_t max_memory_size_; // 设备内存限制
public:
struct TilingPolicy {
bool is_static; // 是否静态Shape
float variability; // Shape变化程度
uint32_t safe_block_size; // 安全块大小
};
TilingPolicy analyze_shape_pattern(const std::vector<uint32_t>& recent_shapes) {
TilingPolicy policy;
if (recent_shapes.size() < 2) {
policy.is_static = true;
policy.variability = 0.0f;
policy.safe_block_size = calculate_conservative_block_size(recent_shapes[0]);
return policy;
}
// 计算Shape变化程度
float avg_variation = calculate_average_variation(recent_shapes);
policy.variability = avg_variation;
policy.is_static = (avg_variation < 0.1f);
if (policy.is_static) {
// 静态Shape:使用激进优化
policy.safe_block_size = calculate_aggressive_block_size(recent_shapes.back());
} else {
// 动态Shape:使用保守策略,兼顾性能与稳定性
policy.safe_block_size = calculate_adaptive_block_size(recent_shapes);
}
return policy;
}
private:
float calculate_average_variation(const std::vector<uint32_t>& shapes) {
float total_variation = 0.0f;
for (size_t i = 1; i < shapes.size(); ++i) {
float variation = abs((int)shapes[i] - (int)shapes[i-1]) / (float)shapes[i-1];
total_variation += variation;
}
return total_variation / (shapes.size() - 1);
}
};4 实战演练:完整Matmul算子的协同实现
4.1 Host侧完整实现
Host侧作为协同调度的总指挥,需要完成资源分配、参数校验、任务调度等全链路工作。
// Matmul算子Host侧完整实现
class MatmulHost {
private:
aclrtStream stream_;
void* device_workspace_;
bool initialized_;
public:
MatmulHost() : initialized_(false), device_workspace_(nullptr) {}
// 初始化协同环境
Status initialize() {
// 1. 设备初始化
ACL_CHECK(aclInit(nullptr));
ACL_CHECK(aclrtSetDevice(0));
// 2. 创建Stream用于异步协同
ACL_CHECK(aclrtCreateStream(&stream_));
// 3. 预分配设备内存池
const size_t workspace_size = 64 * 1024 * 1024; // 64MB
ACL_CHECK(aclrtMalloc(&device_workspace_, workspace_size,
ACL_MEM_MALLOC_HUGE_FIRST));
initialized_ = true;
return Status::SUCCESS;
}
// 核心协同调度函数
Status execute(const MatmulParams& params,
const Tensor& input_a, const Tensor& input_b, Tensor& output) {
if (!initialized_) {
return Status::FAILED("Not initialized");
}
// 1. 参数校验与Shape推导
auto validation_result = validate_params(params, input_a, input_b);
if (!validation_result.success) {
return validation_result.status;
}
// 2. 计算最优Tiling策略
auto tiling_strategy = compute_tiling_strategy(params, input_a.shape());
// 3. 设备内存分配与数据搬运
auto device_buffers = allocate_device_memory(params, tiling_strategy);
ACL_CHECK(aclrtMemcpyAsync(device_buffers.input_a, input_a.data(),
input_a.size(), ACL_MEMCPY_HOST_TO_DEVICE, stream_));
// 4. 下发Kernel任务
launch_matmul_kernel(device_buffers, tiling_strategy, stream_);
// 5. 异步回传结果
ACL_CHECK(aclrtMemcpyAsync(output.data(), device_buffers.output,
output.size(), ACL_MEMCPY_DEVICE_TO_HOST, stream_));
return Status::SUCCESS;
}
private:
// Tiling策略计算
TilingStrategy compute_tiling_strategy(const MatmulParams& params,
const TensorShape& input_shape) {
TilingStrategy strategy;
// 考虑硬件特性计算分块大小
strategy.tile_m = find_optimal_tile(input_shape[0], 64, 256);
strategy.tile_n = find_optimal_tile(input_shape[1], 64, 256);
strategy.tile_k = find_optimal_tile(input_shape[2], 128, 512);
strategy.grid_dim.x = (input_shape[0] + strategy.tile_m - 1) / strategy.tile_m;
strategy.grid_dim.y = (input_shape[1] + strategy.tile_n - 1) / strategy.tile_n;
return strategy;
}
// 异步Kernel启动
void launch_matmul_kernel(const DeviceBuffers& buffers,
const TilingStrategy& tiling, aclrtStream stream) {
// 准备Kernel参数
void* kernel_args[] = {
&buffers.input_a, &buffers.input_b, &buffers.output,
&tiling.tile_m, &tiling.tile_n, &tiling.tile_k
};
// 计算启动配置
uint32_t block_dim = tiling.grid_dim.x * tiling.grid_dim.y;
// 异步启动Kernel
rtError_t launch_result = rtKernelLaunch(
matmul_kernel, // Kernel函数指针
block_dim, // Block数量
kernel_args, // 参数列表
sizeof(kernel_args), // 参数大小
nullptr, // 保留参数
stream // 异步Stream
);
if (launch_result != RT_ERROR_NONE) {
throw std::runtime_error("Kernel launch failed");
}
}
};4.2 Device侧Kernel实现
Device侧专注于计算效率最大化,通过精细的内存管理和并行计算实现高性能。
// 高性能Matmul Kernel实现
__global__ __aicore__ void matmul_kernel(
const half* __gm__ input_a, // 全局内存输入A
const half* __gm__ input_b, // 全局内存输入B
half* __gm__ output, // 全局内存输出
int tile_m, int tile_n, int tile_k) {
// 1. 获取当前Block的坐标
int block_x = get_block_idx_x();
int block_y = get_block_idx_y();
int grid_x = get_grid_dim_x();
// 2. 计算当前Block负责的矩阵分块
int start_m = block_x * tile_m;
int end_m = min(start_m + tile_m, global_m);
int start_n = block_y * tile_n;
int end_n = min(start_n + tile_n, global_n);
// 3. 在Unified Buffer中分配双缓冲
__ubuf__ half* buffer_a[2]; // 输入A的双缓冲
__ubuf__ half* buffer_b[2]; // 输入B的双缓冲
__ubuf__ half* accumulator; // 累加器
// 4. 初始化流水线
Pipe pipe;
uint32_t loop_count = (global_k + tile_k - 1) / tile_k;
// 5. 主流水线循环
for (uint32_t tile_idx = 0; tile_idx < loop_count + 1; ++tile_idx) {
// 双缓冲索引
uint32_t buffer_idx = tile_idx % 2;
uint32_t prev_buffer_idx = (tile_idx - 1) % 2;
// 数据搬运与计算重叠
if (tile_idx < loop_count) {
// 异步搬运下一块数据
load_tile_to_ubuf(buffer_a[buffer_idx], input_a,
start_m, tile_idx * tile_k, tile_m, tile_k);
load_tile_to_ubuf(buffer_b[buffer_idx], input_b,
tile_idx * tile_k, start_n, tile_k, tile_n);
}
if (tile_idx > 0) {
// 计算上一块数据
matrix_multiply(accumulator,
buffer_a[prev_buffer_idx], buffer_b[prev_buffer_idx],
tile_m, tile_n, tile_k);
}
// 流水线同步
pipe.wait(tile_idx);
}
// 6. 写回结果
store_result_from_ubuf(output, accumulator, start_m, start_n, tile_m, tile_n);
}
// 矩阵乘计算核
__aicore__ inline void matrix_multiply(__ubuf__ half* result,
const __ubuf__ half* a,
const __ubuf__ half* b,
int m, int n, int k) {
// 使用Cube单元进行矩阵计算
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
half sum = 0.0f;
for (int p = 0; p < k; ++p) {
sum += a[i * k + p] * b[p * n + j];
}
result[i * n + j] = sum;
}
}
}5 高级优化技术:企业级性能提升
5.1 多Stream并行与依赖管理
在企业级应用中,多Stream并行是提升设备利用率的关键技术。
// 高级Stream管理实现
class AdvancedStreamManager {
private:
std::vector<aclrtStream> streams_;
std::unordered_map<aclrtStream, StreamContext> contexts_;
public:
// 创建多Stream协同环境
Status create_streams(int num_streams, StreamPriority priority = STREAM_PRIORITY_HIGH) {
streams_.resize(num_streams);
for (int i = 0; i < num_streams; ++i) {
// 创建指定优先级的Stream
aclrtStreamCreateWithConfig(&streams_[i], priority);
contexts_[streams_[i]] = StreamContext();
}
return Status::SUCCESS;
}
// 协同任务提交:支持任务间依赖
TaskHandle submit_task(std::function<void()> task,
const std::vector<TaskHandle>& dependencies = {}) {
// 选择空闲Stream
auto stream = select_idle_stream();
// 建立依赖关系
for (auto& dep : dependencies) {
insert_stream_wait_event(stream, get_event_from_handle(dep));
}
// 异步执行任务
auto event = create_event();
std::thread([task, stream, event]() {
task(); // 执行实际任务
aclrtRecordEvent(event, stream); // 记录完成事件
}).detach();
return TaskHandle{event, stream};
}
// 内存访问优化:流水线式数据预取
void pipeline_data_prefetch(const std::vector<Tensor>& batches,
int prefetch_depth = 2) {
for (int i = 0; i < batches.size() + prefetch_depth; ++i) {
if (i < batches.size()) {
// 异步预取数据到设备
submit_prefetch_task(batches[i], i);
}
if (i >= prefetch_depth) {
// 处理已完成预取的数据
int compute_batch = i - prefetch_depth;
submit_compute_task(batches[compute_batch], compute_batch);
}
}
}
};5.2 动态Shape下的协同优化
动态Shape场景需要自适应协同策略,在性能和通用性间取得平衡。
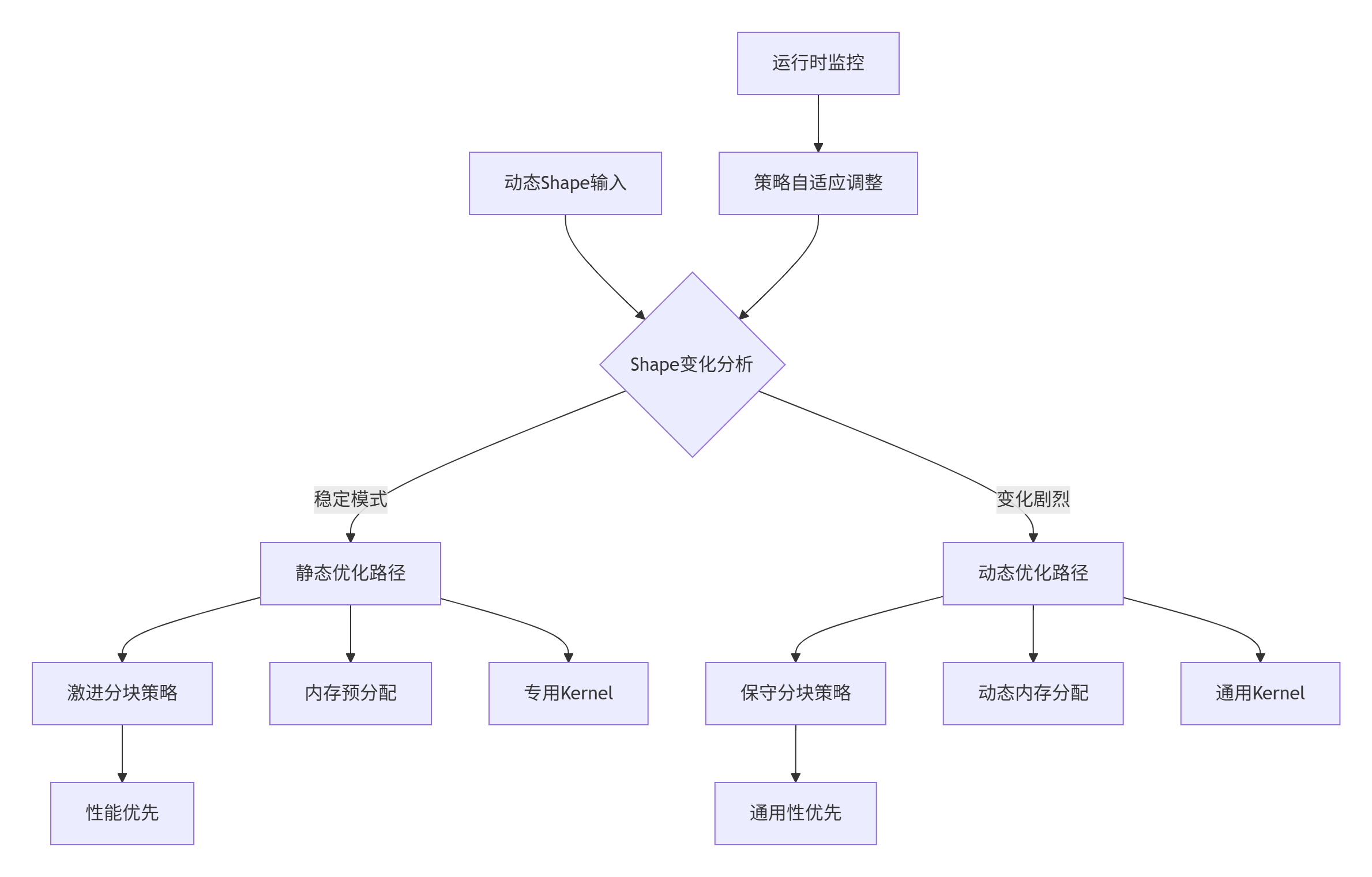
动态协同的实现框架:
// 动态Shape自适应协同器
class DynamicShapeCoordinator {
private:
ShapeHistory history_;
PerformanceProfiler profiler_;
TuningStrategy current_strategy_;
public:
struct TuningDecision {
TilingStrategy tiling;
KernelVersion kernel_selection;
MemoryLayout memory_layout;
bool use_double_buffering;
};
TuningDecision make_decision(const TensorShape& current_shape,
const PerformanceMetrics& metrics) {
// 分析Shape变化模式
auto pattern = analyze_shape_pattern(history_, current_shape);
// 基于历史性能数据调整策略
auto predicted_performance = predict_performance(pattern, metrics);
// 生成最优协同决策
TuningDecision decision;
if (pattern.stability > 0.8) {
// 稳定Shape:使用激进优化
decision = create_aggressive_strategy(current_shape);
} else {
// 动态Shape:使用平衡策略
decision = create_adaptive_strategy(current_shape, pattern.variability);
}
// 考虑设备当前负载
decision = adjust_for_system_load(decision, get_current_load());
return decision;
}
private:
ShapePattern analyze_shape_pattern(const ShapeHistory& history,
const TensorShape& current) {
ShapePattern pattern;
if (history.empty()) {
pattern.stability = 1.0f;
pattern.variability = 0.0f;
return pattern;
}
// 计算Shape变化的统计特性
auto variations = calculate_shape_variations(history, current);
pattern.variability = compute_variability(variations);
pattern.stability = 1.0f - pattern.variability;
return pattern;
}
};6 故障排查与性能调优指南
6.1 常见协同问题及解决方案
基于大量实战经验,总结Host-Device协同的典型问题模式。
性能问题诊断清单:
// 协同性能诊断工具
class CoordinationProfiler {
public:
struct PerformanceReport {
float host_device_balance; // 负载均衡度
float memory_bottleneck; // 内存瓶颈指数
float parallelism_utilization; // 并行度利用
std::vector<std::string> recommendations;
};
PerformanceProfile analyze_coordination(const ExecutionTrace& trace) {
PerformanceReport report;
// 1. 分析Host-Device负载均衡
report.host_device_balance = calculate_balance_score(
trace.host_execution_time, trace.device_execution_time);
// 2. 检测内存瓶颈
report.memory_bottleneck = analyze_memory_bottleneck(
trace.memory_operations, trace.compute_operations);
// 3. 评估并行度利用
report.parallelism_utilization = calculate_parallelism_efficiency(
trace.theoretical_parallelism, trace.actual_parallelism);
// 4. 生成优化建议
report.recommendations = generate_recommendations(report);
return report;
}
private:
float calculate_balance_score(float host_time, float device_time) {
float total_time = host_time + device_time;
float ideal_ratio = 0.1f; // Host应占10%以内
if (host_time / total_time > ideal_ratio) {
return (ideal_ratio * total_time) / host_time;
}
return 1.0f;
}
std::vector<std::string> generate_recommendations(const PerformanceReport& report) {
std::vector<std::string> recommendations;
if (report.host_device_balance < 0.8f) {
recommendations.push_back("优化Host侧逻辑,减少Device等待时间");
}
if (report.memory_bottleneck > 0.7f) {
recommendations.push_back("启用双缓冲优化内存访问");
recommendations.push_back("考虑数据压缩减少传输量");
}
if (report.parallelism_utilization < 0.6f) {
recommendations.push_back("调整Tiling策略提高并行度");
recommendations.push_back("检查负载均衡问题");
}
return recommendations;
}
};6.2 高级调试技术与工具
企业级调试方法论:
// 协同调试器实现
class CoordinationDebugger {
private:
DebugStream debug_stream_;
std::unordered_map<std::string, Breakpoint> breakpoints_;
public:
// 异步执行追踪
void trace_asynchronous_execution(const std::string& label, aclrtStream stream) {
// 记录时间戳和上下文
auto timestamp = get_precise_timestamp();
auto context = capture_execution_context();
debug_stream_.push({timestamp, label, context, stream});
// 检查断点条件
if (breakpoints_.count(label) && check_breakpoint_condition(label)) {
enter_debug_mode(label);
}
}
// 死锁检测
bool detect_deadlock(const ExecutionGraph& graph) {
// 检查Stream依赖循环
auto cycles = find_dependency_cycles(graph);
if (!cycles.empty()) {
std::cout << "检测到死锁风险:" << std::endl;
for (auto& cycle : cycles) {
std::cout << "依赖环: ";
for (auto& node : cycle) {
std::cout << node << " -> ";
}
std::cout << cycle[0] << std::endl;
}
return true;
}
return false;
}
// 内存一致性检查
void validate_memory_consistency(const MemoryOperation& op1,
const MemoryOperation& op2) {
// 检查内存操作顺序性
if (op1.stream == op2.stream) {
// 同Stream顺序执行
if (op1.timestamp > op2.timestamp && op1.address == op2.address) {
std::cout << "警告:可能存在内存顺序问题" << std::endl;
}
} else {
// 跨Stream需要显式同步
if (!has_synchronization(op1, op2) && op1.address == op2.address) {
std::cout << "警告:跨Stream内存操作缺少同步" << std::endl;
}
}
}
};7 总结与展望
7.1 关键技术洞察
通过深度剖析Ascend C中Host-Device的协同工作机制,我们得出以下核心洞察:
-
协同本质是异步化:通过Stream、Event等机制实现计算与数据传输的最大重叠
-
性能瓶颈在数据搬运:优化重点应从计算转向数据通路优化
-
动态适应性是工业级关键:静态优化无法适应真实场景的Shape变化
7.2 未来演进方向
基于对异构计算发展趋势的判断,Host-Device协同机制将向以下方向演进:
-
智能化协同:基于机器学习的自动优化策略选择
-
编译期协同优化:更多协同逻辑在编译期而非运行期决定
-
跨设备协同:多个AI处理器的协同计算
7.3 实践建议
对于不同阶段的开发者,建议采取不同的优化路径:
初学者路径:
-
掌握基本的同步协同模式
-
理解Tiling机制和内存层次
-
实现基础的双缓冲优化
进阶开发者路径:
-
掌握多Stream并行和依赖管理
-
实现动态Shape自适应
-
应用高级性能分析工具
专家级路径:
-
开发自定义协同模式
-
参与硬件协同设计
-
贡献优化算法回馈社区
参考链接
讨论点:在您的实际项目中,是更倾向于使用静态优化保证峰值性能,还是动态优化保证通用性?欢迎分享您在Host-Device协同方面的实战经验!
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 23
23 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)