文章二:面向 Ascend C 的高性能 sin/cos 实现:从角度规约到向量化多项式逼近
**浮点精度**:$k = \lfloor\theta / (2\pi)\rfloor$ 的计算涉及除法和取整,当 $\theta$ 很大时,$\theta - k \cdot 2\pi$ 的精度会略有损失;也可以用相位平移 $\cos\theta = \sin(\theta + \frac{\pi}{2})$ 来复用 `sin` 的实现,但需要注意规约后的角度可能超出 $[0, 2\pi)$,需
1. 背景:为什么需要自己实现三角函数
在上一篇文章中,我们介绍了如何用切比雪夫多项式和 LIGC 公式来逼近菲涅尔余弦积分 。但在渐近段的实现中,遇到了一个新问题,在AscendC 编程模型没有官方的三角函数API可以直接调用,因此需要自己实现:
,
这里需要计算。当
很大时,角度
会变得非常大,甚至超过
很多圈。
1.1 初步尝试:直接用泰勒展开
最直观的做法是用泰勒展开:
但这个方法有严重问题:
- 当 很大(比如
)时,泰勒展开的收敛速度极慢,需要保留几十项才能有合理精度;
- 高阶项 等数值上会爆掉或损失精度;
- 在 Ascend C 上实现高阶泰勒展开,既占用大量缓冲区,又难以向量化。
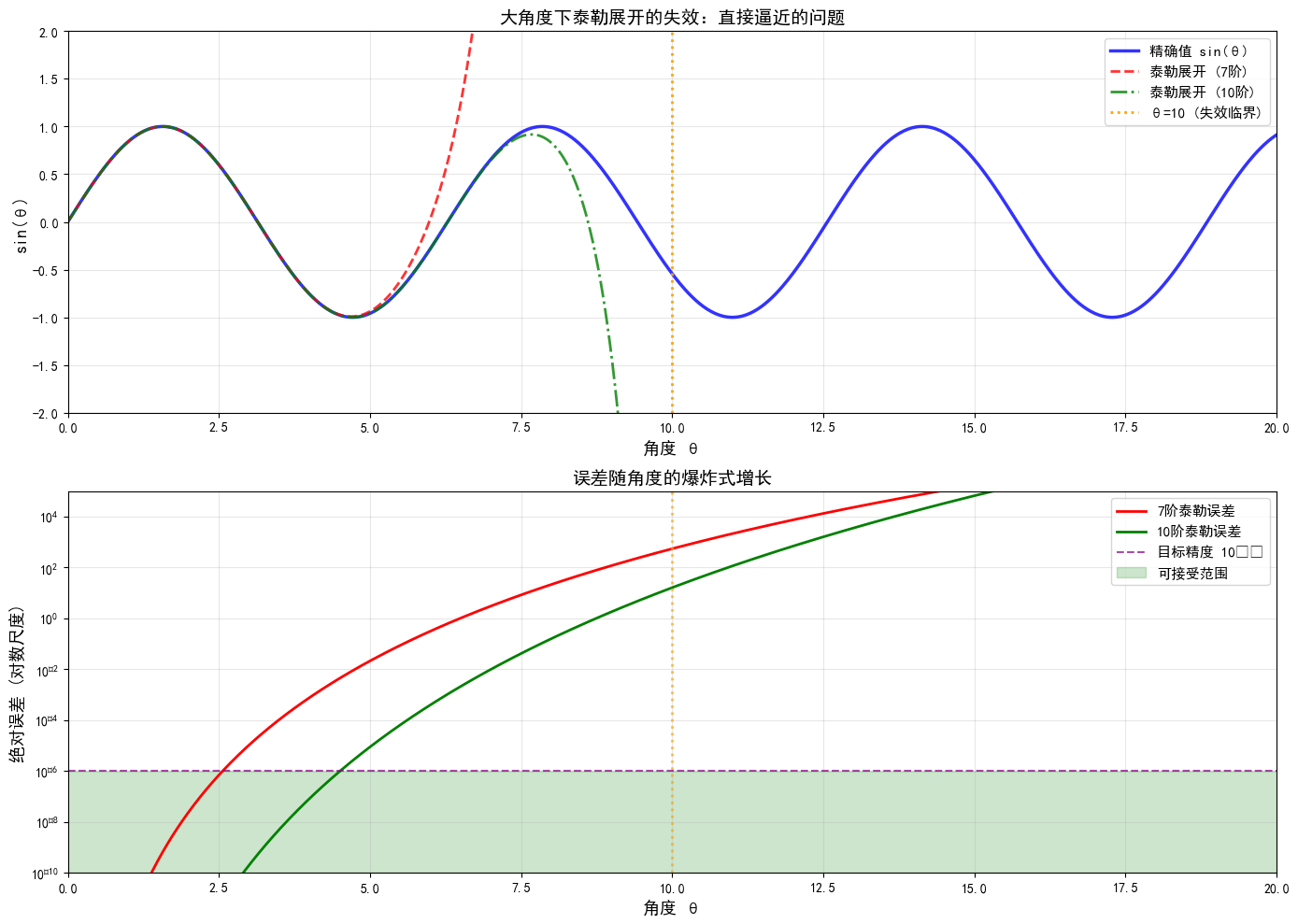
图1 泰勒展开失效分析
1.2 核心思路:角度规约 + 小区间多项式
解决方案是经典的「角度规约(Argument Reduction)」:
1. 利用三角函数的周期性,先把角度规约到;
2. 再利用对称性和象限关系,进一步规约到 ;
3. 在这个小区间上,用低阶多项式就能达到高精度;
4. 根据原始角度所在的象限,给结果加上正确的符号。
这样就把「大角度 + 高阶多项式」的问题,转化为「小角度 + 低阶多项式 + 符号处理」,非常适合在 Ascend C 上进行向量化实现。
---
2. 角度规约的数学原理
2.1 第一步:规约到
对于任意角度 ,利用周期性
,可以先做模 $2\pi$ 运算:
在 Ascend C 向量实现中,避免使用真正的模运算(会导致分支),而是用乘法 + `Floor` + 减法的组合:
```cpp
// INV_TWO_PI = 1 / (2π)
AscendC::Muls(tmp, angle, INV_TWO_PI, length); // angle / (2π)
AscendC::Floor(k, tmp, length); // k = floor(angle / 2π)
AscendC::Muls(tmp, k, TWO_PI, length); // k * 2π
AscendC::Sub(theta0, angle, tmp, length); // θ0 = angle - k·2π
```
这样 就被限制在
区间内。
2.2 第二步:象限判定与规约到
在 上,根据四个象限有不同的对称关系:
| 象限 | 范围 | $\sin$ 的值 | 规约公式 |
|------|------|-------------|----------|
| I | |
|
|
| II | |
|
|
| III | |
|
|
| IV | |
|
|
也就是说,只要能算出 上的
,再根据象限加上正负号,就能得到原始角度的正弦值。
这个规约过程通常用「奇变偶不变,符号看象限」来记忆(这里是偶变换,所以函数不变)。
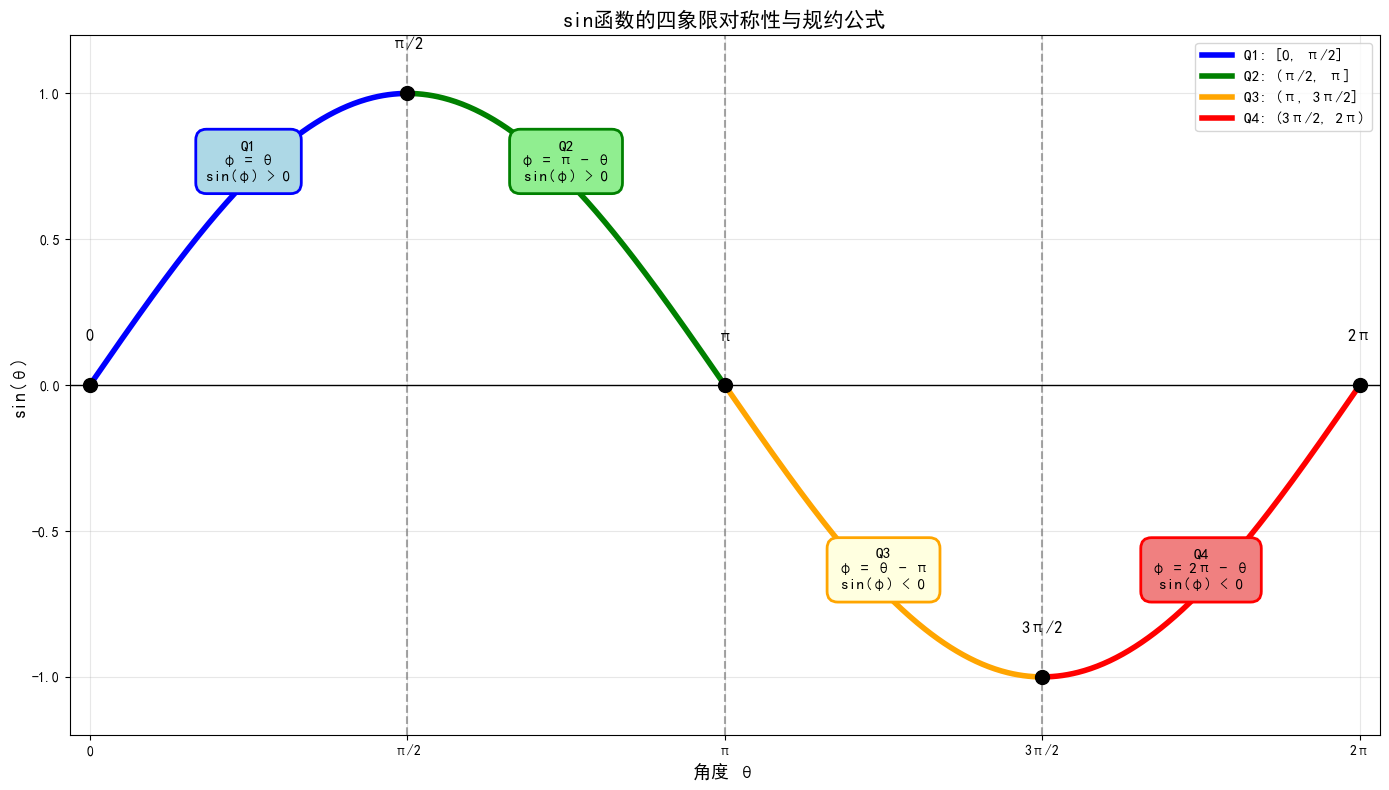
图2 四象限对称性示意图
---
3. Ascend C 上的向量化实现
3.1 构造象限掩码
在 AscendC 的向量化实现中,不能用 if/else 来判断象限,而是要构造布尔掩码:
```cpp
AscendC::LocalTensor<bool> mask_q1 = B_mask1.Get<bool>();
AscendC::LocalTensor<bool> mask_q2 = B_mask2.Get<bool>();
AscendC::LocalTensor<bool> mask_q3 = B_mask3.Get<bool>();
AscendC::LocalTensor<bool> mask_q4 = B_mask4.Get<bool>();
// 第一象限:0 <= θ0 <= π/2
AscendC::Compare(mask_q1, theta0, PI_OVER_2, CMPMODE::LE, length);
// 第二象限:π/2 < θ0 <= π
AscendC::Compare(mask_temp, theta0, PI_OVER_2, CMPMODE::GT, length);
AscendC::Compare(mask_q2, theta0, PI, CMPMODE::LE, length);
AscendC::And(mask_q2, mask_q2, mask_temp, length);
// 第三象限:π < θ0 <= 3π/2
AscendC::Compare(mask_temp, theta0, PI, CMPMODE::GT, length);
AscendC::Compare(mask_q3, theta0, PI_3_OVER_2, CMPMODE::LE, length);
AscendC::And(mask_q3, mask_q3, mask_temp, length);
// 第四象限:3π/2 < θ0 < 2π
AscendC::Compare(mask_q4, theta0, PI_3_OVER_2, CMPMODE::GT, length);
```
这样每个元素都有一个对应的象限标记。
3.2 规约到 并确定符号
初始化 ,然后根据掩码逐步修正:
```cpp
AscendC::LocalTensor<float> phi = B_tri1.Get<float>();
AscendC::LocalTensor<float> sign = B_tri2.Get<float>();
AscendC::LocalTensor<float> tmp = B_result1.Get<float>();
// 初始:φ = θ0, sign = +1
AscendC::DataCopy(phi, theta0, length);
AscendC::Duplicate(sign, 1.0f, length);
// 第二象限:φ = π - θ0
AscendC::Sub(tmp, PI, theta0, length);
AscendC::Select(phi, mask_q2, tmp, phi, length);
// 第三象限:φ = θ0 - π, sign = -1
AscendC::Sub(tmp, theta0, PI, length);
AscendC::Select(phi, mask_q3, tmp, phi, length);
AscendC::Select(sign, mask_q3, NEG_ONE, sign, length);
// 第四象限:φ = 2π - θ0, sign = -1
AscendC::Sub(tmp, TWO_PI, theta0, length);
AscendC::Select(phi, mask_q4, tmp, phi, length);
AscendC::Select(sign, mask_q4, NEG_ONE, sign, length);
```
此时已经被规约到
,
记录了符号(+1 或 -1)。
3.3 小区间多项式逼近
现在只需要在 上逼近
。使用改进版的泰勒展开:
,
其中 。
为了减少计算量,先算 ,然后递推得到高次幂:
```cpp
AscendC::Mul(phi2, phi, phi, length); // φ^2
AscendC::Mul(phi3, phi2, phi, length); // φ^3 = φ^2 * φ
AscendC::Mul(phi5, phi3, phi2, length); // φ^5 = φ^3 * φ^2
AscendC::Mul(phi7, phi5, phi2, length); // φ^7 = φ^5 * φ^2
```
然后组合成多项式:
```cpp
// result = a1*φ + a3*φ^3 + a5*φ^5 + a7*φ^7
AscendC::Muls(result, phi, A1, length); // a1*φ
AscendC::Muls(tmp, phi3, A3, length); // a3*φ^3
AscendC::Add(result, result, tmp, length);
AscendC::Muls(tmp, phi5, A5, length); // a5*φ^5
AscendC::Add(result, result, tmp, length);
AscendC::Muls(tmp, phi7, A7, length); // a7*φ^7
AscendC::Add(result, result, tmp, length);
```
最后乘上符号:
```cpp
AscendC::Mul(result, result, sign, length);
```
这样就得到了最终的 。
---
4. cos 的实现
函数可以用类似的思路实现,主要区别在于:
- 是偶函数,所以
,规约时可以直接取绝对值;
- 象限对称关系略有不同:
- I 象限:;
- II 象限:;
- III 象限:;
- IV 象限:。
也可以用相位平移来复用 `sin` 的实现,但需要注意规约后的角度可能超出
,需要再做一次模运算。
在当前代码中,`cos` 是单独实现的,逻辑与 `sin` 平行。
---
5. 性能优化的细节
5.1 常量预计算
所有涉及 的常量(如
)都在编译期预计算并定义为全局常量:
```cpp
constexpr float PI = 3.141592653589793f;
constexpr float TWO_PI = 6.283185307179586f;
constexpr float INV_TWO_PI = 0.15915494309189535f;
constexpr float PI_OVER_2 = 1.5707963267948966f;
constexpr float PI_3_OVER_2 = 4.71238898038469f;
```
这样在运行时不需要做任何除法或超越函数调用。
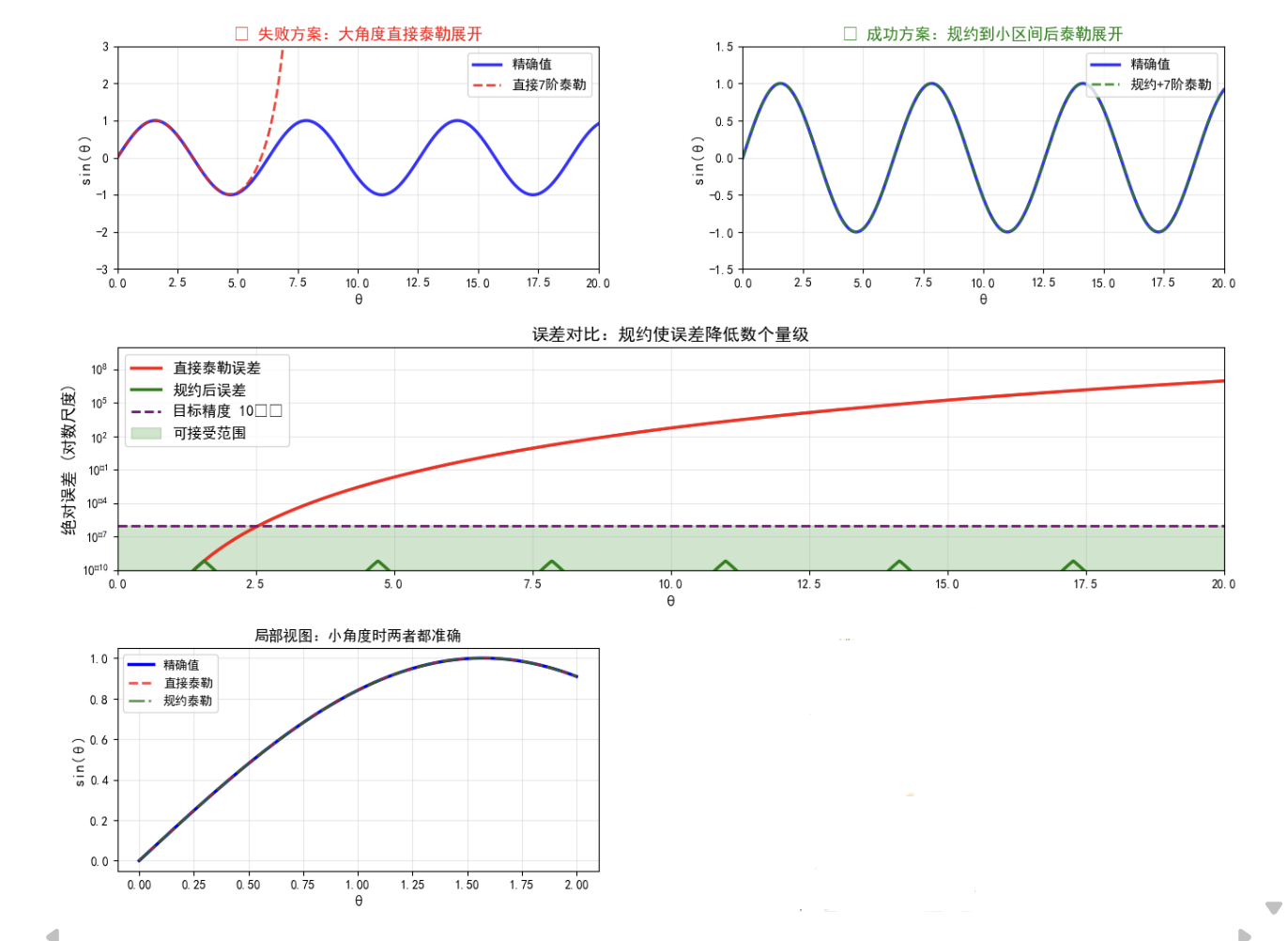
图3 规约前后精度对比图
5.2 缓冲区复用
`sin/cos` 的实现中需要多个临时向量(如)。为了节省本地内存,代码中使用了预先分配的 `B_c1..B_c7` 和 `B_tri1..B_tri2`:
```cpp
AscendC::LocalTensor<float> theta0 = B_c1.Get<float>();
AscendC::LocalTensor<float> phi = B_tri1.Get<float>();
AscendC::LocalTensor<float> sign = B_tri2.Get<float>();
AscendC::LocalTensor<float> phi2 = B_c2.Get<float>();
AscendC::LocalTensor<float> phi3 = B_c3.Get<float>();
// ...
```
这些缓冲区在其它函数中也有复用,通过生命周期规划避免冲突。
5.3 掩码操作的优化
`Compare` 和 `Select` 是 AscendC 中相对昂贵的操作(虽然仍然是向量化的)。为了减少掩码操作次数,代码中尽量合并逻辑:
- 例如第二象限的判定,用一次 `Compare` + 一次 `And` 完成,而不是嵌套多个 `Select`;
- 符号的确定只需要一次 `Select`(III 和 IV 象限合并处理)。
---
6. 精度与误差分析
6.1 规约误差
在规约过程中,主要的误差来源是:
- 浮点精度: 的计算涉及除法和取整,当
很大时,
的精度会略有损失;
- 常量精度:和
的表示精度(单精度浮点数约有 7 位有效数字)。
对于 量级,这些误差通常在
以内,不会影响整体精度。
6.2 多项式逼近误差
在 上,7 阶泰勒展开的理论误差约为:
实测中,这个误差水平在整个区间上都能保持,满足单精度浮点的精度要求。
6.3 与标准库的对比
在一些测试用例中,用这套 Ascend C 实现计算的 与标准库(如 `std::sin`)的结果对比,最大绝对误差在
量级,相对误差在
量级,对于深度学习的应用已经足够。
---
7. 在菲涅尔积分中的集成
回到渐近段的计算:
其中 是某个修正因子(在 LIGC 公式中可能更复杂)。
在 `CalculateAsymptotic` 函数中,调用了前面实现的 `SinWithReduction`:
```cpp
// 计算 θ = (π/2) * x^2
AscendC::Mul(theta, x_abs, x_abs, length); // x^2
AscendC::Muls(theta, theta, PI / 2.0f, length); // (π/2) * x^2
// 调用 sin
SinWithReduction(sin_val, theta, length);
// C(x) ≈ 0.5 + (1 / πx) * sin(θ)
AscendC::Muls(tmp, x_abs, PI, length); // πx
AscendC::Div(tmp, sin_val, tmp, length); // sin(θ) / (πx)
AscendC::Adds(result, tmp, 0.5f, length); // 0.5 + ...
```
这样整个渐近段的实现就完整了,而且所有三角函数计算都是基于 Ascend C 的高效向量化操作。
---
8. 小结与后续
这篇文章详细介绍了如何在 Ascend C 上实现高性能的 `sin/cos` 函数,核心思路是:
1. 角度规约:利用周期性和对称性,把大角度规约到 小区间;
2. 象限掩码:用 `Compare` + `Select` 实现无分支的象限判定和符号处理;
3. 低阶多项式:在小区间上用 7 阶泰勒展开即可达到高精度;
4. 缓冲区复用:精心规划临时变量,减少本地内存占用。
这套方法不仅适用于菲涅尔积分,也可以推广到任何需要通过 Ascend C 实现三角函数的场景。在下一篇文章中,我们会介绍整个菲涅尔积分算子的工程优化策略,包括掩码驱动的分段、缓冲区生命周期规划、以及与 LIGC 公式的集成。
文章二:[文章一:基于切比雪夫多项式与查找表的菲涅尔余弦积分逼近:从渐近公式到分段优化的演进 —— Ascend C实现与优化](文章一:基于切比雪夫多项式与查找表的菲涅尔余弦积分逼近:从渐近公式到分段优化的演进 —— AscendC实现与优化-CSDN博客)
文章三:[文章三 Ascend C上的菲涅尔积分算子工程实践:掩码分段、缓冲区复用与渐近公式](文章三 Ascend C上的菲涅尔积分算子工程实践:掩码分段、缓冲区复用与渐近公式-CSDN博客)
---

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)