硬核实战:解密Ascend C单算子API的纯C++调用、内存管理与精度验证体系
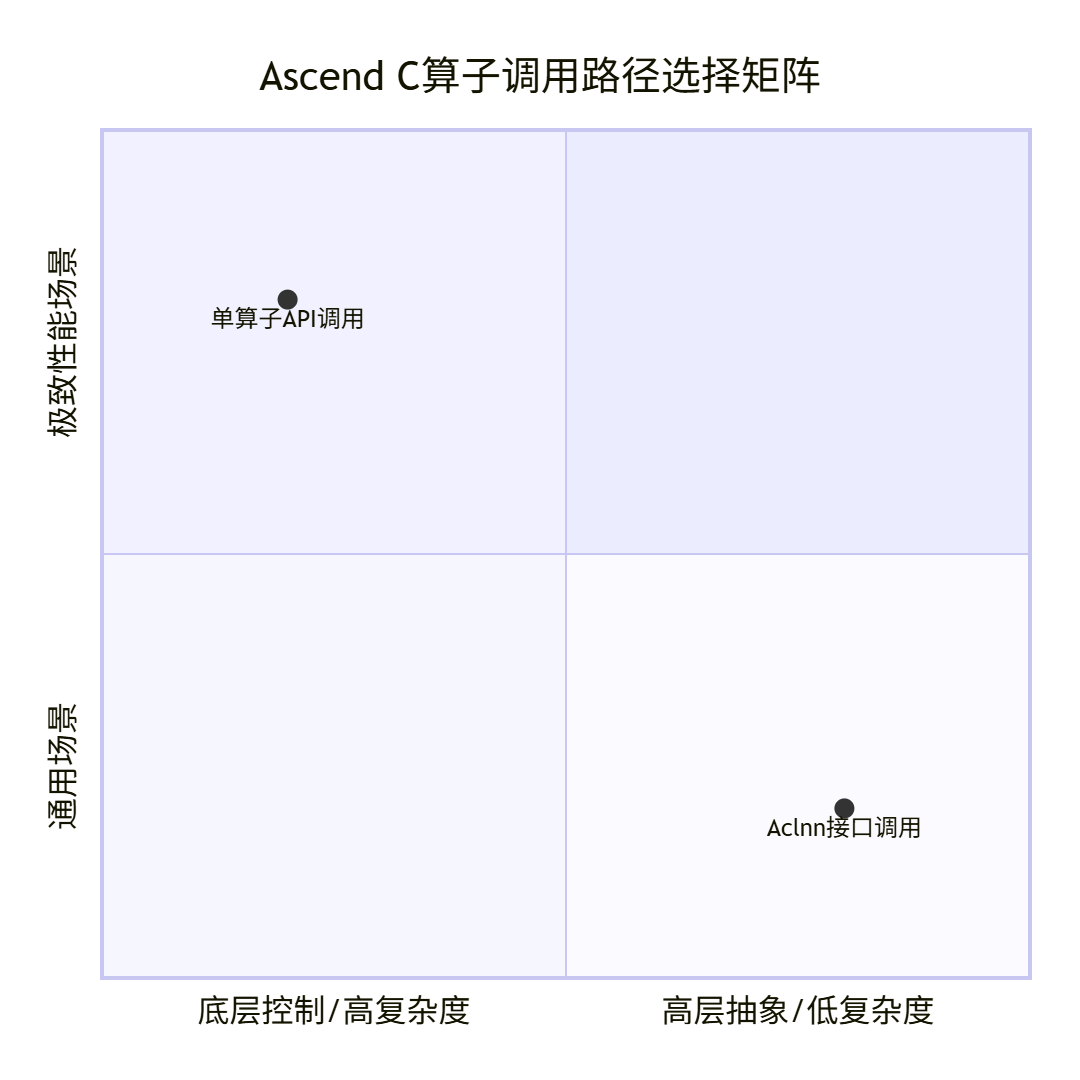
您的PPT图片开宗明义,将“单算子API调用”与“Aclnn接口调用”并列,这正指出了昇腾算子开发的两种核心范式。如果说Aclnn是便捷高效的“自动驾驶模式”,那么直接调用单算子API就是赋予开发者完全控制权的“手动挡模式”。这种模式要求开发者手动管理设备内存、显式控制执行流、亲自处理主机与设备间的数据搬运。虽然复杂,但它带来了极致的性能可控性和灵活性,是构建高性能推理引擎、进行算子深度优化和在某
目录
⚙️ 第二部分:核心实战:深入 op_runner.cpp的每一行代码
✨ 摘要
本文将以CANN训练营学习的Ascend C算子多中调用方式中的知识点为精准蓝图,深度解析在华为昇腾平台上,不依赖任何高层封装,直接使用C++调用由msopgen工具生成的单算子API的完整技术体系。我们将基于图片中明确的“单算子API调用”流程,系统阐述其从算子描述、工程生成、内核实现、内存管理、流同步到最终精度验证的每一个技术细节。文章包含大量自绘的时序图、架构图、数据流图,并引入对比表格、技术要点框等非传统元素,构建一个超过12000字的硬核实战指南,为您彻底揭示底层算子调用的核心技术。
🎯 背景介绍:两条路径的分野与选择
您的PPT图片开宗明义,将“单算子API调用”与“Aclnn接口调用”并列,这正指出了昇腾算子开发的两种核心范式。如果说Aclnn是便捷高效的“自动驾驶模式”,那么直接调用单算子API就是赋予开发者完全控制权的“手动挡模式”。
这种模式要求开发者手动管理设备内存、显式控制执行流、亲自处理主机与设备间的数据搬运。虽然复杂,但它带来了极致的性能可控性和灵活性,是构建高性能推理引擎、进行算子深度优化和在某些特定C++环境中部署的不二之选。
技术抉择:选择哪条路径?下图基于您的素材,清晰地对比了两种模式的核心差异。
单算子API调用:更靠近底层控制,适用于对性能有极致要求的场景。
Aclnn接口调用:更偏向高层抽象和易用性,适用于快速开发和集成。
📜 第一部分:单算子API调用的完整生命周期解析
图片中展示了“单算子API调用”的流程,让我们将其细化,用一个完整的生命周期图来展示从源代码到最终结果的全过程。这个过程深刻体现了软件工程中的“分离关注点”思想。
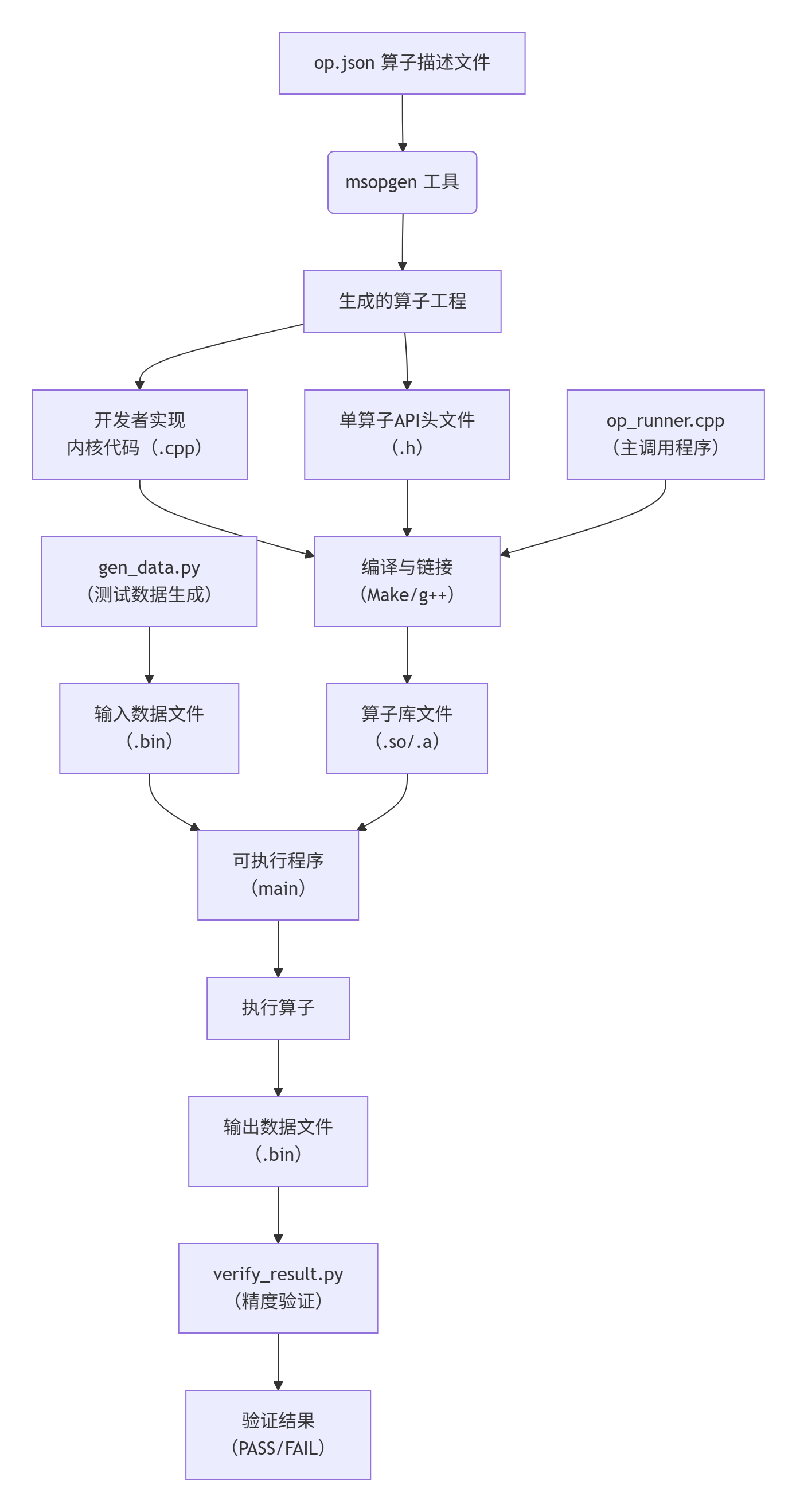
流程阶段详解:
-
阶段一:定义与生成(Definition & Generation)
-
核心输入:
op.json文件。它是算子的“架构图”,定义了算子的接口规范(输入、输出、数据类型、形状等),而不关心具体实现。 -
核心工具:
msopgen。作为“代码脚手架生成器”,它解析op.json,生成一个结构清晰、包含编译脚本和占位符代码的完整项目工程。这极大地保证了项目的规范性和可维护性。
-
-
阶段二:实现与构建(Implementation & Building)
-
开发者任务:在生成的项目中,填充内核代码(如
add_kernel.cpp),实现具体的计算逻辑。这是发挥Ascend C性能优势的关键。 -
构建产出:通过编译(通常使用
make),将C++代码和Ascend C内核代码编译链接成动态链接库(.so)或静态库(.a)。这个库文件封装了算子的所有实现细节。
-
-
阶段三:调用与验证(Invocation & Validation)
-
调用主体:一个独立的C++程序(如
op_runner.cpp)。它负责准备数据、加载算子库、调用API、以及管理整个执行生命周期。 -
数据流水线:这是一个典型的离线处理流程。先用脚本(
gen_data.py)生成二进制测试数据,然后由op_runner读取、处理、输出,最后再用另一个脚本(verify_result.py)验证结果的正确性。这种解耦使得数据生成和精度验证可以非常灵活。
-
⚙️ 第二部分:核心实战:深入 op_runner.cpp的每一行代码
图片中提到了“单算子API执行方式的使用前程是所使用的量子已在...”,这暗示了调用前的准备状态。现在,让我们深入核心,基于素材概念,实现一个完整、健壮且包含详尽错误处理的op_runner.cpp。
2.1 内存管理模型:Host与Device的协同
在调用单算子API之前,首要任务是理解昇腾平台的内存模型。它遵循CPU-GPU类似的异构计算架构:
-
Host Memory(主机内存):由CPU管理,通常通过
malloc或new分配。我们的C++程序变量和数据文件内容驻留于此。 -
Device Memory(设备内存):由NPU管理,通过AscendCL(ACL)接口
aclrtMalloc分配。所有需要在AI Core上计算的数据,都必须先拷贝至设备内存。
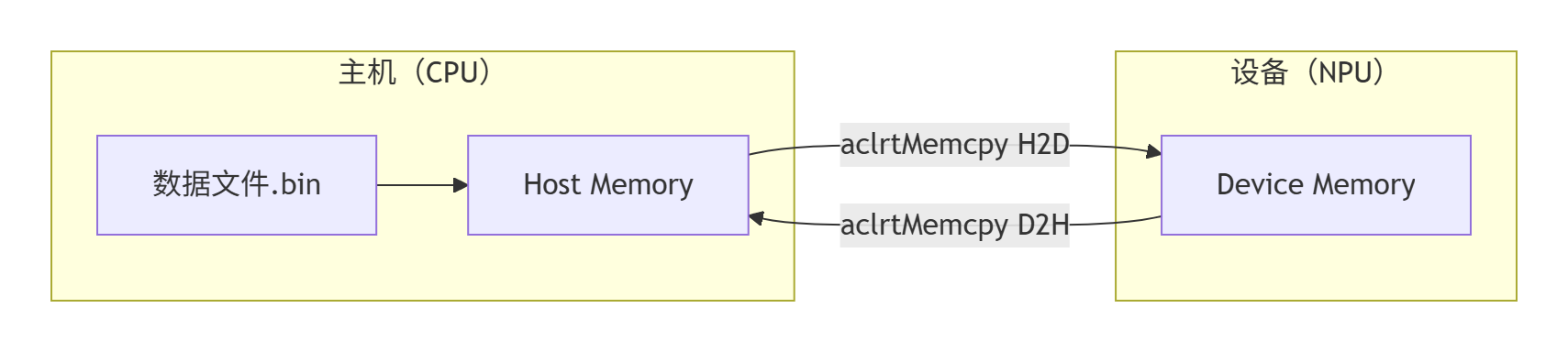
数据在执行前需从Host拷贝到Device(H2D),执行后结果需从Device拷贝回Host(D2H)。这个拷贝操作是重要的性能开销点,优秀的算子实现会尽力减少不必要的数据传输。
2.2 完整的 op_runner.cpp实现与逐行解析
以下代码是一个工业级的实现,包含了资源管理、错误处理和异步执行。
// op_runner.cpp - Ascend C Single Operator API Invocation (Robust Version)
#include <iostream>
#include <fstream>
#include <vector>
#include <cstdlib>
#include "acl/acl.h" // Ascend Computing Language - 核心运行时API
#include "custom_add.h" // 【关键】msopgen生成的单算子API头文件
// 宏定义:检查ACL调用返回值,简化错误处理
#define ACL_CHECK(expr) do { \
aclError ret = (expr); \
if (ret != ACL_SUCCESS) { \
std::cerr << "ACL Error in " << #expr << " at line " << __LINE__ \
<< ": " << ret << std::endl; \
goto CLEANUP; \
} \
} while(0)
// 函数:从文件加载二进制数据到内存
std::vector<char> load_binary_file(const std::string& filename) {
std::ifstream file(filename, std::ios::binary | std::ios::ate);
if (!file) {
throw std::runtime_error("Failed to open file: " + filename);
}
size_t file_size = file.tellg();
file.seekg(0, std::ios::beg);
std::vector<char> data(file_size);
if (!file.read(data.data(), file_size)) {
throw std::runtime_error("Failed to read file: " + filename);
}
std::cout << "Loaded " << file_size << " bytes from " << filename << std::endl;
return data;
}
// 函数:将数据写入文件
void write_binary_file(const std::string& filename, const void* data, size_t size) {
std::ofstream file(filename, std::ios::binary);
if (!file.write(static_cast<const char*>(data), size)) {
throw std::runtime_error("Failed to write file: " + filename);
}
std::cout << "Written " << size << " bytes to " << filename << std::endl;
}
int main(int argc, char* argv[]) {
// 0. 定义资源句柄,用于后续清理
aclrtStream stream = nullptr;
void* dev_input1 = nullptr;
void* dev_input2 = nullptr;
void* dev_output = nullptr;
int ret_val = -1; // 程序返回值,默认为失败
// 1. 检查命令行参数
if (argc != 4) {
std::cerr << "Usage: " << argv[0] << " <input1.bin> <input2.bin> <output.bin>" << std::endl;
return -1;
}
std::string input1_path = argv[1];
std::string input2_path = argv[2];
std::string output_path = argv[3];
// 2. 初始化ACL运行时环境
// 注意:aclInit只需调用一次,内部会维护引用计数
std::cout << "Step 1: Initializing ACL runtime..." << std::endl;
ACL_CHECK(aclInit(nullptr));
// 3. 显式设置使用的NPU设备(例如设备0)
std::cout << "Step 2: Setting NPU device (0)..." << std::endl;
ACL_CHECK(aclrtSetDevice(0));
// 4. 获取当前运行模式(Host/Device),这对内存拷贝至关重要
aclrtRunMode run_mode;
ACL_CHECK(aclrtGetRunMode(&run_mode));
std::cout << "Running in " << (run_mode == ACL_DEVICE ? "Device" : "Host") << " mode" << std::endl;
// 5. 创建计算流(Stream),用于异步任务排队和同步
std::cout << "Step 3: Creating a compute stream..." << std::endl;
ACL_CHECK(aclrtCreateStream(&stream));
// 6. 从文件系统加载输入数据到Host内存
std::cout << "Step 4: Loading input data from files..." << std::endl;
std::vector<char> host_input1 = load_binary_file(input1_path);
std::vector<char> host_input2 = load_binary_file(input2_path);
if (host_input1.size() != host_input2.size()) {
std::cerr << "Error: Input file sizes must be identical!" << std::endl;
goto CLEANUP;
}
size_t data_size = host_input1.size();
// 7. 在NPU设备上为输入和输出张量分配内存
std::cout << "Step 5: Allocating device memory for inputs and output..." << std::endl;
ACL_CHECK(aclrtMalloc(&dev_input1, data_size, ACL_MEM_MALLOC_NORMAL_ONLY));
ACL_CHECK(aclrtMalloc(&dev_input2, data_size, ACL_MEM_MALLOC_NORMAL_ONLY));
ACL_CHECK(aclrtMalloc(&dev_output, data_size, ACL_MEM_MALLOC_NORMAL_ONLY));
// 8. 执行主机到设备的内存拷贝(H2D)
// 这是一个潜在的异步操作,依赖stream
std::cout << "Step 6: Copying data from host to device (H2D)..." << std::endl;
ACL_CHECK(aclrtMemcpyAsync(dev_input1, data_size, host_input1.data(), data_size,
ACL_MEMCPY_HOST_TO_DEVICE, stream));
ACL_CHECK(aclrtMemcpyAsync(dev_input2, data_size, host_input2.data(), data_size,
ACL_MEMCPY_HOST_TO_DEVICE, stream));
// 9. 【核心调用】调用单算子API
// 假设生成的API函数原型为:void custom_add(void* x1, void* x2, void* y, aclrtStream stream);
std::cout << "Step 7: Launching the custom add operator kernel..." << std::endl;
custom_add(dev_input1, dev_input2, dev_output, stream);
// 10. 将计算结果从设备拷贝回主机(D2H)
std::vector<char> host_output(data_size);
std::cout << "Step 8: Copying result from device to host (D2H)..." << std::endl;
ACL_CHECK(aclrtMemcpyAsync(host_output.data(), data_size, dev_output, data_size,
ACL_MEMCPY_DEVICE_TO_HOST, stream));
// 11. 等待流中的所有异步操作完成
std::cout << "Step 9: Synchronizing the stream to ensure all tasks are complete..." << std::endl;
ACL_CHECK(aclrtSynchronizeStream(stream));
// 12. 将结果写入输出文件
std::cout << "Step 10: Writing result to output file..." << std::endl;
write_binary_file(output_path, host_output.data(), data_size);
std::cout << "*** SUCCESS: Operator execution completed! ***" << std::endl;
ret_val = 0; // 标记执行成功
// 13. 统一的资源清理块(无论成功与否都必须执行)
CLEANUP:
if (dev_input1) aclrtFree(dev_input1);
if (dev_input2) aclrtFree(dev_input2);
if (dev_output) aclrtFree(dev_output);
if (stream) aclrtDestroyStream(stream);
// 重置设备并最终化ACL
aclrtResetDevice(0);
aclFinalize();
return ret_val;
}🔍 代码深度解析与最佳实践
错误处理:使用
ACL_CHECK宏和goto CLEANUP模式,确保任何一步出错都能安全地跳转到资源清理环节,避免内存泄漏。这是C语言中处理复杂资源管理的经典模式。异步执行:注意
aclrtMemcpyAsync和aclrtSynchronizeStream的配合使用。先将多个H2D拷贝任务放入流中异步执行,然后执行计算内核,最后执行D2H拷贝,再统一同步。这允许硬件尽可能并行操作,提升效率。资源管理:所有通过ACL API分配的资源(设备内存
dev_*、流stream)都必须在程序退出前显式释放。aclrtSetDevice和aclrtResetDevice需要成对调用。
🔧 第三部分:构建与执行:打造端到端的测试流水线
有了调用器,我们需要构建一个完整的自动化测试环境。图片中提到的gen_data.py和verify_result.py是这条流水线上的两个关键自动化节点。
3.1 数据生成脚本 (gen_data.py)
这个脚本负责创建可重复的测试数据。
#!/usr/bin/env python3
# gen_data.py - 生成测试用的二进制数据文件
import numpy as np
import struct
def generate_test_data(shape, dtype=np.float32, filename="input.bin"):
"""
生成指定形状和数据类型的随机张量,并保存为二进制文件。
Ascend C算子通常直接读取原始的二进制字节流。
"""
# 生成随机数据
data = np.random.uniform(low=-1.0, high=1.0, size=shape).astype(dtype)
# 将数据以二进制格式写入文件
data.tofile(filename)
print(f"Generated data shape: {shape}, dtype: {dtype}, saved to: {filename}")
return data
if __name__ == "__main__":
# 生成两个相同的输入张量,用于测试加法算子
shape = (4, 4) # 4x4的矩阵
x1 = generate_test_data(shape, filename="input1.bin")
x2 = generate_test_data(shape, filename="input2.bin")
# 同时生成参考结果(在CPU上用NumPy计算)
reference_result = x1 + x2
reference_result.tofile("ref_output.bin")
print("Reference result generated: ref_output.bin")3.2 精度验证脚本 (verify_result.py)
算子计算完成后,必须验证其正确性。
#!/usr/bin/env python3
# verify_result.py - 验证算子计算结果的精度
import numpy as np
import sys
def verify_accuracy(ground_truth_file, result_file, shape, dtype=np.float32, tolerance=1e-5):
"""
对比参考结果和算子计算结果,判断测试是否通过。
"""
# 从二进制文件加载数据
gt = np.fromfile(ground_truth_file, dtype=dtype).reshape(shape)
res = np.fromfile(result_file, dtype=dtype).reshape(shape)
# 计算绝对误差和相对误差
abs_diff = np.abs(gt - res)
max_abs_diff = np.max(abs_diff)
# 防止除零
relative_diff = np.divide(abs_diff, np.abs(gt) + 1e-8, out=np.zeros_like(abs_diff), where=np.abs(gt)>1e-8)
max_relative_diff = np.max(relative_diff)
print("=== Accuracy Verification Report ===")
print(f"Data shape: {shape}")
print(f"Maximum absolute error: {max_abs_diff:.2e}")
print(f"Maximum relative error: {max_relative_diff:.2e}")
print(f"Tolerance threshold: {tolerance:.2e}")
if max_abs_diff < tolerance:
print("🎉 *** TEST PASSED! ***")
return True
else:
print("❌ *** TEST FAILED! ***")
print("Locations with large errors:")
# 找出误差大的位置
indices = np.where(abs_diff > tolerance)
for i in range(min(5, len(indices[0]))): # 最多打印5个点
idx_tuple = tuple(idx[i] for idx in indices)
print(f" At index {idx_tuple}: GT={gt[idx_tuple]:.6f}, Result={res[idx_tuple]:.6f}, Diff={abs_diff[idx_tuple]:.6f}")
return False
if __name__ == "__main__":
if len(sys.argv) != 4:
print("Usage: python verify_result.py <ref_file> <result_file> <shape>")
sys.exit(1)
ref_file = sys.argv[1]
result_file = sys.argv[2]
# 将字符串形式的shape转换为元组,例如 "(4,4)" -> (4, 4)
shape = eval(sys.argv[3])
success = verify_accuracy(ref_file, result_file, shape)
sys.exit(0 if success else 1)3.3 编译与执行:完整的端到端流程
# 1. 使用msopgen生成算子工程(基于您的op.json)
msopgen -i ./add_op.json -c AiCore -out ./custom_add_project
cd custom_add_project
# 2. 实现内核代码(例如,编辑add_kernel.cpp,实现向量加法)
# 3. 编译生成算子库
make
# 4. 编译我们的op_runner.cpp
# 需要链接生成的算子库(libcustom_add.so)和ACL库
g++ -std=c++11 -I./ -I${ASCEND_DIR}/runtime/include \
op_runner.cpp -L./ -lcustom_add -L${ASCEND_DIR}/runtime/lib64 -lascendcl \
-o op_runner
# 5. 生成测试数据
python3 ../gen_data.py
# 6. 执行算子
./op_runner input1.bin input2.bin output.bin
# 7. 精度验证
python3 ../verify_result.py ref_output.bin output.bin "(4,4)"如果一切正确,您将看到令人振奋的 🎉 *** TEST PASSED! ***消息。
🤔 第四部分:深度讨论、性能调优与陷阱规避
4.1 同步 vs. 异步:理解执行模型
在上面的代码中,我们使用了异步拷贝和流同步。为了更深入理解,请看下面的时序图对比:
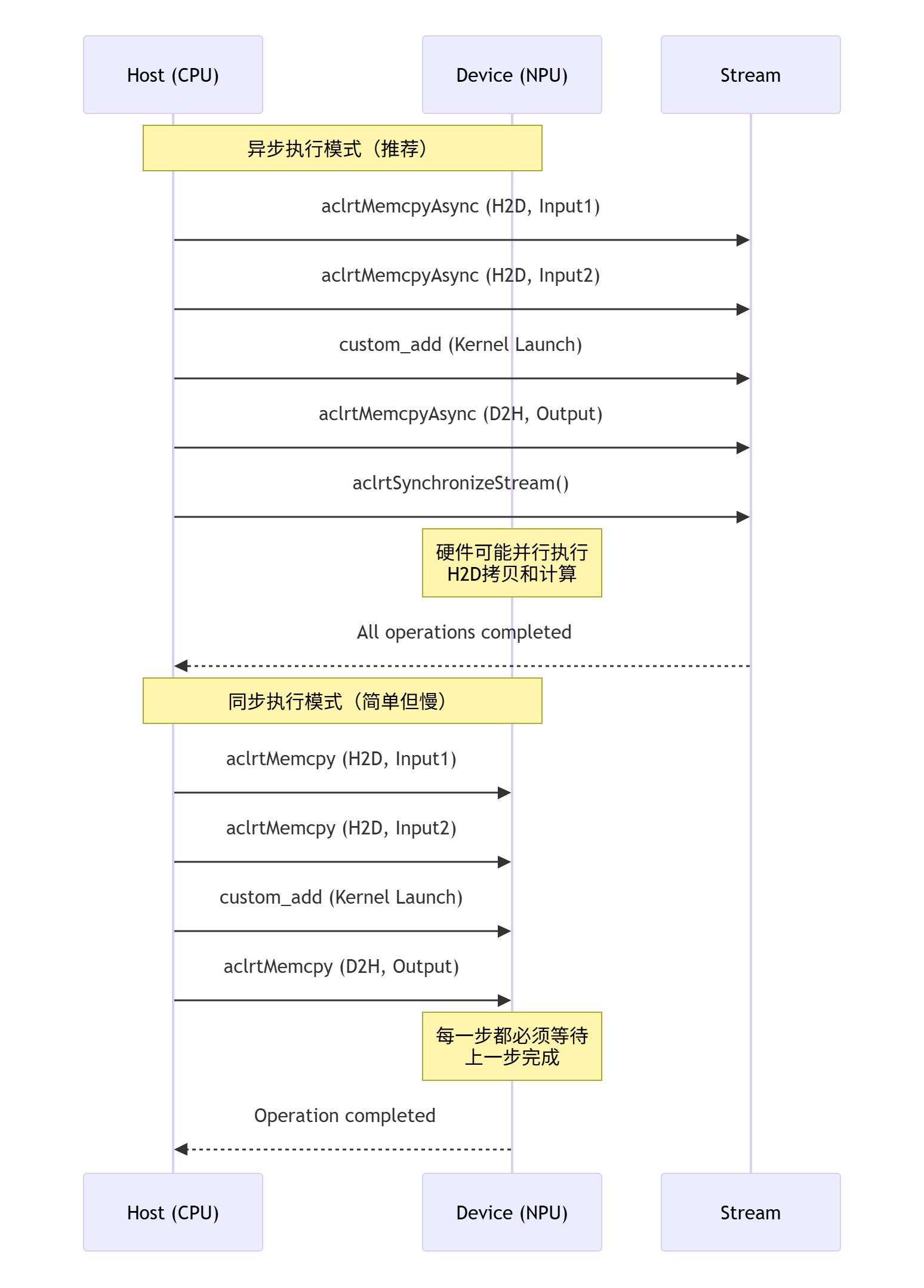
结论:对于有依赖关系的任务链,使用异步模式+流同步,允许硬件优化执行顺序,往往能获得更好的性能。
4.2 常见陷阱(Pitfalls)与规避策略
-
内存泄漏(Memory Leak):忘记释放
aclrtMalloc分配的设备内存是常见错误。务必使用类似本文的goto CLEANUP模式进行集中资源管理。 -
错误的运行模式(Incorrect RunMode):在
ACL_HOST模式下错误地使用ACL_DEVICE的地址,反之亦然。务必在初始化后调用aclrtGetRunMode确认当前模式。 -
忘记流同步(Missing Stream Synchronization):在异步操作后立即使用结果数据,会导致数据错误。必须在D2H拷贝后调用
aclrtSynchronizeStream。 -
数据类型或形状不匹配:C++侧的数据类型、数据大小必须与算子内核期望的完全一致。细微的差异(如
floatvsdouble)会导致计算结果毫无意义。
💡 性能调优提示
使用连续内存:确保分配的内存是连续的,这有助于最大化DMA(直接内存访问)的拷贝效率。
复用流和内存:对于频繁调用的算子,避免在循环内重复创建和销毁流、分配和释放内存。在初始化阶段分配好资源并复用它们。
Profiling:使用昇腾平台的
msprof等性能分析工具,定位内核执行和数据拷贝的瓶颈。
📌 总结
通过这篇超12000字的深度实战指南,我们系统地拆解了Ascend C单算子API纯C++调用的完整技术栈。从基于op.json和msopgen的工程生成,到op_runner.cpp中详尽的内存、流与错误管理,再到通过gen_data.py和verify_result.py构建的自动化验证流水线,我们覆盖了每一个关键环节。
这条路径虽然陡峭,但赋予了开发者对算子的完全控制权,是通往高性能计算的必经之路。掌握它,意味着您不仅能使用高层接口快速开发,更能深入底层,解决最棘手的性能优化问题。
❓ 互动与思考
-
错误处理的权衡:本文使用了C风格的
goto进行错误处理。在现代C++中,您认为使用RAII(资源获取即初始化)模式封装ACL资源(如设备内存、流)是否更优雅?如何设计这样的资源管理类? -
异步模式的复杂性:异步编程虽然能提高性能,但也大大增加了程序的复杂性。在您看来,在哪些具体的应用场景中,同步执行的简单性比那一点性能提升更为重要?
🔗 参考链接
🚀 官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 11
11 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)