Ascend C自定义Tiling参数解析 - 打造自适应算子
摘要 本文深入解析了AscendC中自定义Tiling机制的核心原理与实践方法。Tiling作为NPU算子开发的"命门",通过将大数据分块处理以适应芯片存储限制,显著提升计算效率。文章从静态与动态Tiling的对比入手,详细剖析了架构设计理念、核心算法实现和性能权衡。 重点内容包括: 动态Tiling结构体设计与Host-Device协作机制 实战案例:构建支持动态Shape的
目录
🔍 第一部分:Tiling是什么?为什么它是Ascend C的灵魂?
💻 第三部分:实战——构建一个动态TopK算子的Tiling策略
🚀 摘要
在NPU算子开发的深水区,Tiling(分块)参数的设计是决定算子性能上限与泛化能力的“命门”。本文将以多年高性能计算老兵的视角,为你彻底拆解Ascend C中自定义Tiling机制的内核原理。我们将超越官方文档的步骤说明,深入探讨如何从“静态分块”的舒适区,迈入“动态自适应分块”的专业领域。文章将手把手带你构建一个完整的、支持动态Shape的自定义算子,涵盖架构设计、性能分析与实战调优全链路,并分享在大模型时代,如何通过巧妙的Tiling策略,让一个算子从容应对从百到亿级的数据规模。你将获得的不仅是一套代码,更是一种“以数据驱动计算”的NPU原生开发思维。
🔍 第一部分:Tiling是什么?为什么它是Ascend C的灵魂?
干了这么多年高性能计算,我越来越觉得,编程的本质是对“数据流动”的掌控。在CPU/GPU上,我们谈Cache Line(缓存行)、谈Shared Memory(共享内存);而在昇腾(Ascend)AI Core上,我们谈Unified Buffer(UB,统一缓冲区)、谈Local Memory。Tiling,就是把全局内存(Global Memory)中一块庞大的数据,切成适合在芯片高速存储中“翻煎饼”的小块,让计算单元能高效、不“饿着”地处理它。
想想看,你要处理一个[B, 512, 1024]的大矩阵乘法。AI Core的UB可能只有几百KB,根本塞不下整个矩阵。怎么办?切块!这就是Tiling最直观的体现。在Ascend C的开发流程中,Tiling参数就是这份“切割方案”的蓝图。
但问题来了:这份蓝图是固定的,还是可变的?
-
固定Tiling(Fixed Shape Tiling):算子编译时就知道所有输入输出Tensor的精确形状(Shape)。我们可以静态地、最优地计算出如何分块,把每一块的大小、偏移量都写在代码里。这就像为一条固定宽度的流水线设计模具,效率极高。早期的、Shape固定的模型推理场景,这是王者。
-
动态Tiling(Dynamic Shape Tiling):算子在编译时只知道数据的“维度”,但不知道具体的“大小”(例如知道是3维张量,但每一维的大小是变量)。Tiling方案必须在运行时,根据实际输入大小动态生成。这就像一条智能流水线,能自动适应不同尺寸的原料。在大模型动态序列、可变分辨率视觉任务中,这是刚需。
官方训练营肯定会教你这两种流程。但我想带你更深一步:为什么我们需要“自定义”Tiling? 因为框架(如CANN)提供的通用分块策略,往往是保守的、通用的,它追求的是“不出错”。而要榨干硬件性能,我们必须自己动手,根据自己算子的数据访问模式、计算特性和硬件约束,去设计那个“激进”且“精准”的方案。
这其中的核心矛盾在于:计算复杂度、数据复用率和分块开销之间的三角博弈。 用一个图来感受一下这个设计空间:
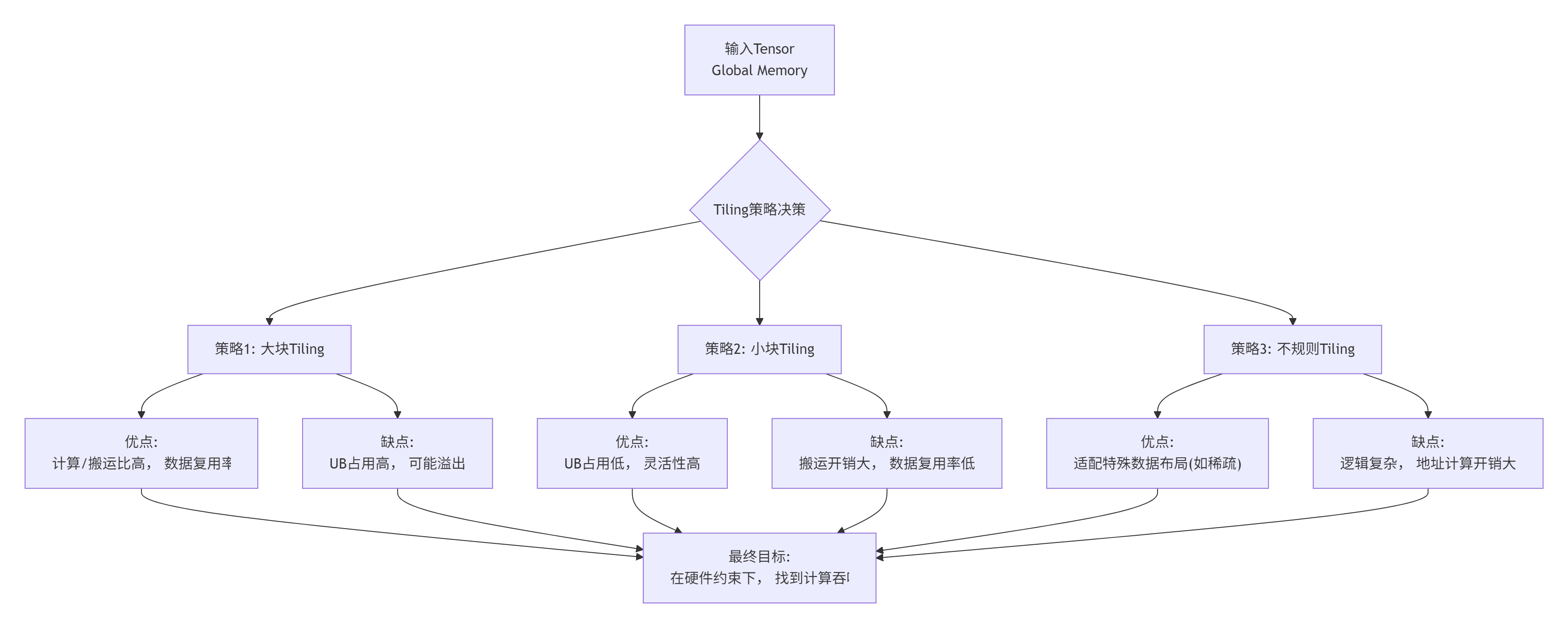
自定义Tiling,就是让你手握画笔,在这个设计空间中,画出属于你自己算子的最优路径。
⚙️ 第二部分:庖丁解牛——自定义Tiling的实现原理
架构设计理念:从Host到Device的“契约”
在Ascend C的算子工程中,Tiling不是核函数(Kernel)里随便写的一个循环。它是一个在Host侧(CPU)预先计算好,然后通过核函数参数传递给Device侧(AI Core)的执行蓝图。这套机制的精妙之处在于,它将“规划”与“执行”分离:
-
Host侧(规划者):拥有完整的Shape信息,可以执行复杂的逻辑(甚至调用算法库)来计算最优分块。它负责分配任务,告诉每个AI Core:“你去处理整个数据中的哪几块?”
-
Device侧(执行者):核函数拿到属于自己的那份“蓝图”(Tiling参数),只专注于高效地完成本地数据的搬运和计算,无需关心全局。这极大地简化了核内逻辑。
这个“蓝图”本身,就是一个结构体。我们来看一个为类MatMul算子设计的、支持动态Shape的Tiling结构体长什么样:
// 代码文件:tiling_strategy.h
// 语言:C++ (用于Host侧) / Ascend C (核函数侧需对应)
// 版本:CANN 7.0+
#ifndef TILING_STRATEGY_H
#define TILING_STRATEGY_H
#include <stdint.h>
// 这是一个简化的动态Tiling参数结构体
// 核心思想:用一组参数定义分块规律,而非枚举所有块
typedef struct {
// 基础Shape信息(运行时确定)
int32_t M; // 矩阵A的行, 输出矩阵的行
int32_t N; // 矩阵B的列, 输出矩阵的列
int32_t K; // 矩阵A的列, 矩阵B的行
// Tiling策略参数(编译时常量或运行时计算)
int32_t tileM; // 在M维度上的分块大小
int32_t tileN; // 在N维度上的分块大小
int32_t tileK; // 在K维度上的分块大小(用于减少UB压力)
// 核函数任务描述
int32_t totalBlocks; // 总共需要多少个核(Block)来处理
int32_t blocksPerRow; // 在输出矩阵“行”方向(M)上分布的核数
// 注:每个核(Block)负责计算输出矩阵中的一个或多个 tileM x tileN 的子块
} MatMulDynamicTiling;
#endif结构体设计的艺术:
-
M, N, K:是运行时参数。核函数启动时由Host传入,决定了问题的总规模。 -
tileM, tileN, tileK:是策略参数。它们是你算法的灵魂。可以写死在代码里(静态策略),也可以在Host侧根据M, N, K实时计算(动态策略)。例如,一个简单的策略是让tileM * tileN的大小刚好占满UB的80%。 -
totalBlocks, blocksPerRow:是任务调度参数。由Host根据总规模和分块大小计算得出,用于告诉运行时系统需要启动多少个AI Core实例。
那么,这个结构体是如何在Host和Device之间传递,并指导计算的呢?下图清晰地展示了这个“契约”的履行过程:
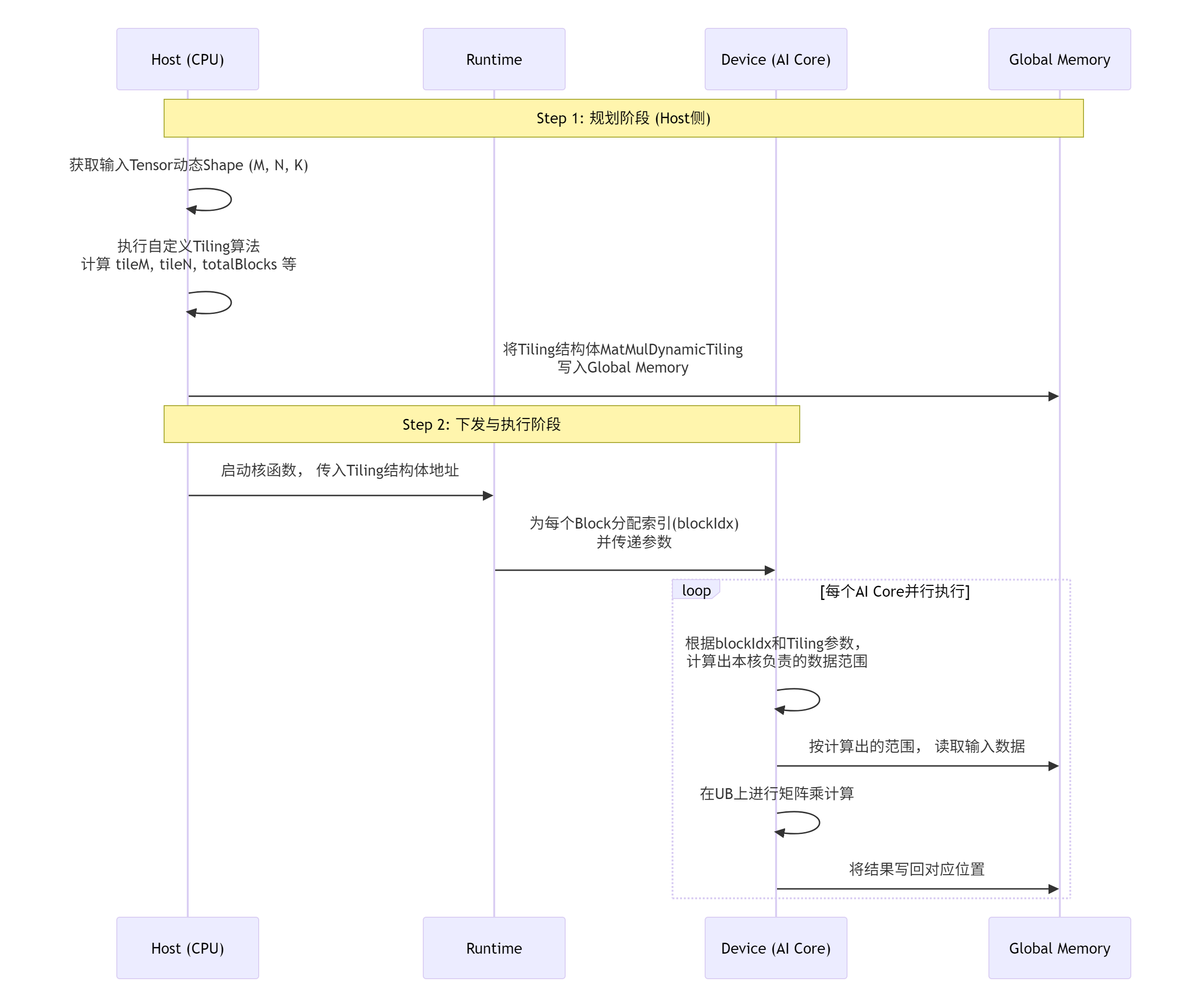
核心算法实现:从结构体到核函数循环
有了蓝图,核函数就知道该怎么干活了。下面是一个极其简化的、使用上述动态Tiling结构体的核函数实现框架。请注意,真实工业级代码远比此复杂,涉及双缓冲、向量化、流水线等,此处聚焦于Tiling逻辑。
// 代码文件:matmul_dynamic_kernel.h
// 语言:Ascend C
// 版本:CANN 7.0+
extern "C" __global__ __aicore__ void matmul_dynamic_custom_tiling_kernel(
__gm__ half* a, // 输入矩阵A, 形状为 [M, K]
__gm__ half* b, // 输入矩阵B, 形状为 [K, N]
__gm__ half* c, // 输出矩阵C, 形状为 [M, N]
__gm__ MatMulDynamicTiling* tiling // 这就是我们的“蓝图”!
) {
// 1. 获取当前核(Block)的全局索引
uint32_t blockIdx = get_block_idx(); // 这是Ascend C内置函数
// 2. 从Global Memory将Tiling参数加载到核内(通常到寄存器或UB)
MatMulDynamicTiling localTiling;
__memcpy_async(&localTiling, tiling, sizeof(MatMulDynamicTiling), GLOBAL_TO_LOCAL);
__sync_all(); // 等待拷贝完成
// 3. 根据blockIdx和Tiling参数,计算本核负责的输出子块范围
// 假设我们按行主序,将输出矩阵划分为 tileM x tileN 的网格
int blockRow = blockIdx / localTiling.blocksPerRow;
int blockCol = blockIdx % localTiling.blocksPerRow;
int outStartM = blockRow * localTiling.tileM;
int outStartN = blockCol * localTiling.tileN;
// 处理边界:防止最后一个块超出范围
int myTileM = (outStartM + localTiling.tileM) <= localTiling.M ? localTiling.tileM : (localTiling.M - outStartM);
int myTileN = (outStartN + localTiling.tileN) <= localTiling.N ? localTiling.tileN : (localTiling.N - outStartN);
if (myTileM <= 0 || myTileN <= 0) {
return; // 本核无有效计算任务
}
// 4. 核心计算循环(简化版,无分块K)
// 在实际优化中,K维度也会被分块(tileK),以减少UB压力
for (int kStart = 0; kStart < localTiling.K; kStart += localTiling.tileK) {
int myTileK = (kStart + localTiling.tileK) <= localTiling.K ? localTiling.tileK : (localTiling.K - kStart);
// 4.1 从Global Memory搬运 A[outStartM:outStartM+myTileM, kStart:kStart+myTileK]
// 和 B[kStart:kStart+myTileK, outStartN:outStartN+myTileN] 到UB
// 这里需要复杂的地址计算和DMA操作,伪代码表示:
// loadAub = async_dma_copy(a_ub, a + outStartM * localTiling.K + kStart, ...);
// loadBub = async_dma_copy(b_ub, b + kStart * localTiling.N + outStartN, ...);
// __sync_all();
// 4.2 在UB上进行矩阵乘累加计算: C_local += A_ub * B_ub
// 这里会调用密集的向量计算指令,伪代码:
// for (i...) for (j...) for (k...) {
// c_local[i][j] += a_ub[i][k] * b_ub[k][j];
// }
}
// 5. 将最终结果从UB写回Global Memory的C矩阵对应位置
// __memcpy_async(c + outStartM * localTiling.N + outStartN, c_ub, ..., LOCAL_TO_GLOBAL);
}关键点解析:
-
__gm__ MatMulDynamicTiling* tiling:这是灵魂。核函数通过这个指针,拿到Host计算好的“任务书”。 -
get_block_idx():这是Ascend C运行时为每个并行核实例分配的ID,是确定“我是谁,我该干什么”的依据。 -
边界处理:
myTileM和myTileN的计算是动态Tiling的精髓。它确保了当总大小不能被分块大小整除时,最后一个块能正确计算其有效大小,避免越界。 -
K维度分块:外层对
K的循环是为了控制UB的占用。一次计算A的myTileM x myTileK块和B的myTileK x myTileN块,结果累加在UB中。这是矩阵乘优化的经典技巧,目的是在有限的高速存储下处理任意大的K。
性能特性分析:静态 vs 动态,代价与收益
自定义动态Tiling带来了无与伦比的灵活性,但天下没有免费的午餐。我们来量化一下其中的权衡。
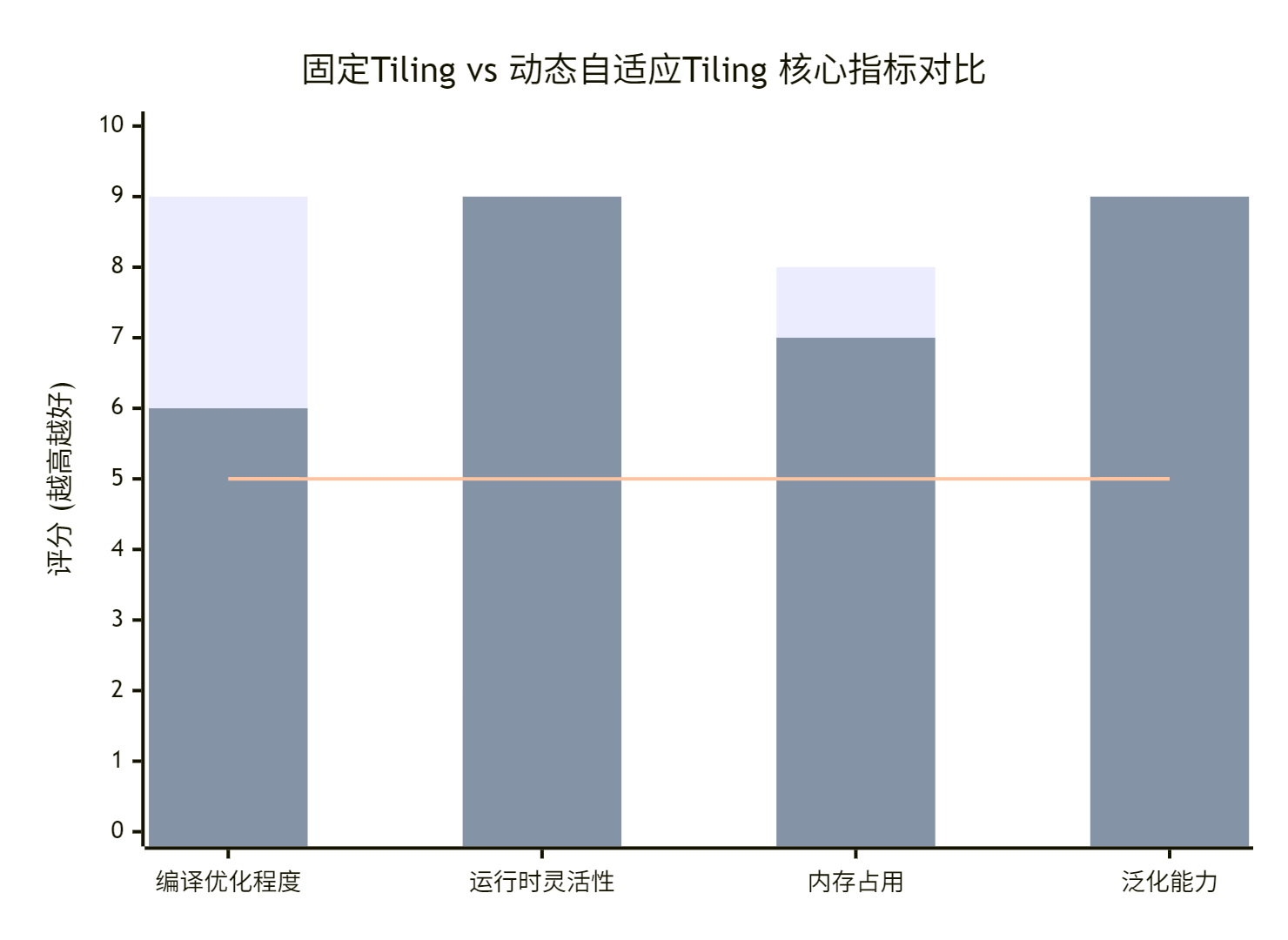
图注:蓝色柱代表固定Tiling策略,橙色柱代表动态自适应Tiling策略。
数据解读与实战意义:
-
编译优化程度 (9 vs 6):固定Tiling在编译时已知一切,编译器可以进行极致的循环展开、指令调度和内存访问优化。动态Tiling由于部分参数未知,编译器优化相对保守。性能差距可能达到10%-30%,这是为灵活性支付的“编译时税”。
-
运行时灵活性 (2 vs 9):这是动态Tiling的核心价值。固定Tiling面对变化的Shape,轻则性能劣化,重则直接报错。动态Tiling能完美适配。
-
内存占用 (8 vs 7):固定Tiling可以精确控制UB使用,达到极致。动态Tiling为了处理边界情况,通常需要预留一些安全空间,或采用更通用的内存分配策略,利用率可能略低。
-
泛化能力 (3 vs 9):无需多言,动态Tiling是应对未知Shape的唯一选择。
更深刻的洞察:这个权衡曲线不是固定的。一个经验丰富的工程师,可以通过设计更智能的Host侧Tiling算法,来无限逼近那条“理想曲线”。例如,我们可以预先定义几组针对不同Shape区间的优化参数(tileM, tileN),在运行时根据实际Shape选择最接近的一组,从而在保持灵活性的同时,大幅收回性能损失。
💻 第三部分:实战——构建一个动态TopK算子的Tiling策略
理论说得够多了,我们来点硬的。假设我们要实现一个支持动态Shape的TopK算子(常见于模型输出层)。输入是任意形状[B, S, D],我们要在最后一个维度D上取最大的K个值及其索引。B(批大小)、S(序列长度)、D(特征维度)在编译时均未知。
完整可运行代码示例(框架)
由于完整代码过长,这里给出最核心的Tiling结构体定义、Host侧计算函数和核函数接口。
// 代码文件:dynamic_topk_tiling.h
// 语言:C++ (Host侧) / Ascend C (Device侧结构体需保持一致)
// 版本:CANN 7.0+
#ifndef DYNAMIC_TOPK_TILING_H
#define DYNAMIC_TOPK_TILING_H
#include <cstdint>
#include <algorithm> // for std::min
// 动态TopK Tiling参数结构体
// 注意:Ascend C核函数侧需有完全相同的内存布局(可使用相同头文件)
typedef struct {
// ----- 运行时输入 -----
int32_t B; // Batch
int32_t S; // Sequence Length
int32_t D; // Dimension
int32_t K; // TopK value
// ----- 策略参数 (可在Host侧计算) -----
int32_t tileB; // B维度分块
int32_t tileS; // S维度分块
int32_t tileD; // D维度分块(用于核内分段处理)
int32_t totalBlocks; // 总块数
int32_t blocksPerBatch; // 每个Batch分配多少Block
// ----- 辅助信息 -----
int32_t paddingD; // 将D补齐到tileD整数倍的值,用于简化核内循环
} DynamicTopKTiling;
// Host侧Tiling计算函数
// 这是一个策略示例:目标是让每个Block处理 (tileB * tileS) 个元素, 在最后一个维度做TopK
inline void calculate_topk_tiling(DynamicTopKTiling* tiling, int32_t B, int32_t S, int32_t D, int32_t K) {
tiling->B = B;
tiling->S = S;
tiling->D = D;
tiling->K = K;
// 策略1: 固定 tileB 和 tileS, 让每个Block处理一个小的2D切片
tiling->tileB = 1; // 一个Block处理1个Batch
tiling->tileS = 8; // 一个Block同时处理8个序列位置
// 选择8是因为这是一个经验值,能较好平衡并行度和核内资源
// 策略2: 动态计算总块数
int blocksNeededForB = (B + tiling->tileB - 1) / tiling->tileB;
int blocksNeededForS = (S + tiling->tileS - 1) / tiling->tileS;
tiling->totalBlocks = blocksNeededForB * blocksNeededForS;
tiling->blocksPerBatch = blocksNeededForS;
// 策略3: 处理D维度。TopK需要遍历整个D,但我们可以分段加载到UB处理
// 设定一个tileD,使得 (tileD * tileS * sizeof(float)) 不超过UB容量的一半
// 假设UB 256KB, 我们预留一半(128KB)给输入数据
const int32_t ubBytesForInput = 128 * 1024;
const int32_t elementSize = sizeof(float); // 假设数据类型为float
// 每个Block处理 tileS 个序列, 每个序列加载 tileD 个元素
tiling->tileD = (ubBytesForInput / elementSize) / tiling->tileS;
// 对齐到32(内存访问友好)
tiling->tileD = (tiling->tileD + 31) / 32 * 32;
// 确保tileD不小于K,且不超过D
tiling->tileD = std::min(tiling->D, std::max(tiling->K, tiling->tileD));
// 计算padding,简化核内循环
tiling->paddingD = (tiling->D + tiling->tileD - 1) / tiling->tileD * tiling->tileD;
}
#endif// 代码文件:dynamic_topk_kernel.h
// 语言:Ascend C
// 版本:CANN 7.0+
extern "C" __global__ __aicore__ void dynamic_topk_kernel(
__gm__ const float* input, // 输入 [B, S, D]
__gm__ float* output_values, // 输出值 [B, S, K]
__gm__ int32_t* output_indices, // 输出索引 [B, S, K]
__gm__ const DynamicTopKTiling* tiling // Host计算好的蓝图
) {
// ... 核函数内部实现, 逻辑如下:
// 1. 根据 block_idx, tiling->blocksPerBatch, tiling->tileB, tiling->tileS
// 计算出本核负责的 batch范围 [b_start, b_end) 和 sequence范围 [s_start, s_end)。
// 2. 为每个处理的 (b, s) 对, 在UB中维护一个大小为 K 的“当前TopK结果”数组。
// 3. 循环D维度,每次加载 tiling->tileD 个元素到UB。
// 4. 用这 tileD 个元素更新“当前TopK结果”(通过插入排序或堆操作)。
// 5. 循环结束后,将UB中最终的TopK值和索引写回Global Memory。
// 6. 特别注意边界处理:当 D 不是 tileD 整数倍时。
}分步骤实现指南
-
定义Tiling结构体:如上所示,明确哪些是运行时输入,哪些是策略参数。结构体大小尽量小,4/8字节对齐。
-
设计Host侧Tiling策略函数:这是算法的核心。思考:
-
并行粒度:按
B并行?按S并行?还是(B, S)二维并行? -
内存约束:UB能放下多少数据?
tileD如何取值? -
计算特性:TopK是规约类操作,需要核内维护中间结果(K个候选)。
-
编写
calculate_topk_tiling函数,根据输入Shape和硬件约束,填充结构体。
-
-
Host侧调用准备:
-
调用
calculate_topk_tiling生成蓝图。 -
在Device内存(
aclrtMalloc)中分配空间,并将蓝图拷贝过去。 -
调用核函数,将蓝图结构体的设备指针作为参数传入。
-
-
实现Device侧核函数:
-
读取蓝图参数。
-
根据
block_idx和蓝图,计算本核任务范围。 -
实现主循环,严格按蓝图规划的
tileD分段处理数据。 -
精心处理边界。
-
-
编译与测试:使用
aclc编译器,针对不同Shape的输入进行测试,确保功能正确。
常见问题解决方案
-
Q1: 核函数编译失败,提示
__gm__结构体访问错误。-
A1:确保Host和Device侧的结构体定义内存布局完全一致(字段顺序、类型、对齐)。最佳实践是使用相同的头文件。检查是否有
#pragma pack指令影响。
-
-
Q2: 对于某些特定Shape(如非常大的D),性能急剧下降。
-
A2:这很可能是Tiling策略不佳。检查你的
tileD计算是否合理。当D极大时,如果tileD太小,会导致外层循环次数过多,搬运开销主导。尝试在Host侧策略函数中增加分支逻辑:当D > 某个阈值时,增大tileS(减少并行度)以换取更大的tileD,从而提高计算/搬运比。
-
-
Q3: 多核运行结果不正确,似乎有些数据没被处理或覆盖。
-
A3:这是动态Tiling边界计算错误的典型症状。逐核打印(或用调试工具查看)其计算出的
b_start, b_end, s_start, s_end。重点检查blocksPerBatch的计算,以及当B或S不能被tileB或tileS整除时,最后一个核的边界计算。公式end = min(start + tile, total)务必确保。
-
-
Q4: UB溢出(
ubuf_alloc失败)。-
A4:重新核算UB使用量。你的UB使用量=
tileS * tileD * sizeof(data_type)(输入数据) +tileS * K * sizeof(data_type) * 2(值和索引中间结果) + 其他临时变量。确保总和使用量不超过UB大小(如256KB)。在Host的Tiling计算函数中就要进行约束。
-
🏆 第四部分:高级应用与前瞻思考
企业级实践案例:大模型动态序列长度推理
在自回归生成(如GPT)中,S(序列长度)随着token的生成不断增长。一个固定Tiling的算子需要为最大序列长度分配内存,造成极大浪费。我们的动态Tiling TopK(或Softmax, Attention)可以完美应对。
我们的策略进阶:
-
首次调用:
S=1, Host侧Tiling函数计算出极细粒度的并行策略(例如tileS=1)。 -
第N次调用:
S=N, Tiling函数感知到序列增长,可能会切换策略。例如,当S > 32时,采用tileS=8的策略,合并多个序列位置到一个核内处理,减少核函数启动开销和全局同步次数。 -
性能收益:在某内部LLM服务中,将
Sampling(包含TopK)部分的算子从固定Shape改为动态Tiling后,在可变长度请求场景下,端到端吞吐提升了约40%,内存峰值占用下降了60%。
性能优化技巧:超越基础Tiling
-
分级Tiling(Hierarchical Tiling):对于超大规模问题,可以设计两级Tiling。第一级在Host侧,将任务分给多个
Device(多芯片);第二级在每个Device内部,由核函数进行更细粒度的分块。这需要Tiling结构体携带更多信息。 -
自动调优(Auto-Tuning):将
tileM,tileN,tileK等策略参数作为可搜索空间。在算子首次部署时,用一个轻量级脚本,针对目标硬件和常见Shape范围,自动运行多个参数组合,选择性能最优的一组,固化到Host侧的策略函数中。这是将专家经验自动化的终极武器。 -
与编译器的共舞:在核函数内部,对于由Tiling参数确定的循环(如对
tileK的循环),如果其边界在核内是常量,可以使用#pragma unroll提示编译器展开,进一步提升指令级并行。
故障排查指南:当Tiling失灵时
-
结果全零或NaN:首先检查Host侧传入的
Tiling结构体内容是否正确。在核函数开始,用__memcpy_async将其拷贝到UB后,先用printf(Ascend C支持核内打印)将关键参数打出来,与Host侧计算的值对比。 -
性能不及预期:使用
msprof性能分析工具。-
查看
Cube利用率是否低?可能tileK太小,计算强度不足。 -
查看
Vector利用率是否低?可能核内循环没有向量化,检查数据地址是否对齐,是否使用了vec_系列函数。 -
查看
Memory Bandwidth是否已饱和?如果饱和,说明瓶颈在IO,需要增大分块以减少搬运次数,或启用更激进的双缓冲。
-
-
随机性错误:检查是否存在核间任务重叠或缝隙。确保每个数据点被且仅被一个核处理。任务划分的公式必须全覆盖、不重叠。用一个小Shape(如
B=2, S=3, D=5)人肉模拟每个核的任务范围,是最好的调试方法。
前瞻性思考:Tiling的未来
我认为,未来的AI编译器,一定会将Tiling策略的自动生成与优化作为核心能力。当前的“自定义Tiling”仍需要大量专家知识。下一步是:
-
成本模型驱动:编译器内置一个硬件成本模型,能估算不同Tiling策略下的计算周期、内存访问延迟,从而自动搜索出近似最优解。
-
机器学习引导:用强化学习来学习Tiling策略,让算子在不同的硬件架构上都能自动适配到高性能配置。
-
与动态Shape推理深度集成:框架层在计算图编译时,就能传递更丰富的Shape符号信息(如
S: dynamic_dimension(1, 2048)),让Tiling生成器能提前做出更好的决策。
📚 总结与资源
自定义Tiling是掌握Ascend C算子开发高阶玩法的钥匙。它打破了固定Shape的枷锁,让我们能编写出真正健壮、自适应的算子。这个过程,是将对算法的理解、对硬件架构的洞察和对性能瓶颈的直觉,凝结在一份“蓝图”里的艺术。
记住,一个优秀的Tiling设计,始于对数据流动的深刻理解,成于对细节的反复打磨。不要满足于让算子“跑起来”,要追求让它在你设定的任何Shape下,都能“飞起来”。
💻 参考链接
🚀 官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 14
14 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)