CANN训练营第二季笔记(2)小白如何用Ascend C开发第一个矩阵算子?
在 AI 模型推理与训练中,最耗时、最频繁的操作就是矩阵运算全连接层(Dense Layer)→ 本质是一个矩阵乘法(Matrix Multiplication,即 GEMM)卷积层(Convolution)→ 底层通常通过 im2col + GEMM 实现注意力机制(Attention)→ 包括大量的矩阵乘、转置、加权求和等归一化层(如 LayerNorm)、激活函数→ 通常是逐元素(eleme
我正在参加CANN训练营第二季,重点学习了Ascend C算子基础入门课程。这门课程作为昇腾AI开发的重要基础环节,让我系统且全面地掌握了如何基于Ascend C编写高效算子。要知道,编写高效算子可是连接AI算法逻辑与昇腾芯片硬件的关键桥梁.
一、为什么要学习 Ascend C 与自定义算子开发?
在 AI 模型推理与训练中,最耗时、最频繁的操作就是 矩阵运算,比如:

- 全连接层(Dense Layer) → 本质是一个矩阵乘法(Matrix Multiplication,即 GEMM)
- 卷积层(Convolution) → 底层通常通过 im2col + GEMM 实现
- 注意力机制(Attention) → 包括大量的矩阵乘、转置、加权求和等
- 归一化层(如 LayerNorm)、激活函数 → 通常是逐元素(element-wise)操作
我们使用 AI 框架(如 TensorFlow、PyTorch、MindSpore)时,这些操作通常已有默认的高效实现。但在以下情况中,框架提供的通用算子可能无法满足需求:
| 场景 | 说明 | 是否需要自定义算子? |
|---|---|---|
| 1. 业务逻辑特殊 | 比如带 mask 的矩阵乘、加权矩阵乘、特殊数值处理 | 需要 |
| 2. 性能不达标 | 框架算子是通用实现,但你的输入尺寸有特殊性,通用优化不一定最优 | 需要 |
| 3. 没有现成算子 | 比如某种特殊的数学变换,框架未提供 | 需要 |
| 4. 想压榨硬件性能 | 想直接调用昇腾芯片的矩阵计算指令,发挥最大算力 | 需要 |
这时候,我们就需要基于 Ascend C 开发 自定义算子(Custom Operator),直接在 昇腾AI处理器上 实现高性能、灵活、业务紧密相关的计算逻辑。
二、Ascend C 是什么?和普通 C++ 有何不同?
Ascend C 是华为 CANN(Compute Architecture for Neural Network)工具链 提供的一种 面向 AI 硬件算子开发的高级语言,它是:
C++ 的一个子集,同时扩展了调用昇腾芯片底层计算资源与内存管理能力的 API 和语法特性。
你可以把它理解为:
一个让你用类 C++ 的语法,写出能直接运行在昇腾芯片上,并能发挥其 AI 计算硬件优势的代码的语言。
Ascend C 的特点:

三、矩阵算子为什么是开发的核心?
矩阵运算是 AI 计算中最基础的计算类型,比如:
| 矩阵操作 | 是否核心 | 说明 |
|---|---|---|
| 矩阵乘(GEMM) | ⭐⭐⭐⭐⭐ | 所有全连接层、卷积底层都依赖它 |
| 矩阵加/减 | ⭐⭐⭐⭐ | 残差连接、归一化中常见 |
| 矩阵转置 | ⭐⭐⭐ | 比如注意力机制中的 QKV 处理 |
| 逐元素操作 | ⭐⭐⭐⭐ | 激活函数、归一化、Dropout 等 |
自定义矩阵算子的目标通常是:
- 实现框架未提供的特殊计算逻辑
- 优化特定数据尺寸/排布下的计算性能
- 替代默认算子,获得更高的计算吞吐和能效
四、Ascend C 矩阵算子开发实战:以矩阵乘(GEMM)为例
接下来我们以最经典的 矩阵乘(GEMM)算子 为例,手把手带你走一遍 开发流程。
1️⃣ 第一步:明确需求 —— 我们要算什么?
我们要实现:
C = A × B
- A 是 [M, K] 的二维矩阵
- B 是 [K, N] 的二维矩阵
- C 是 [M, N] 的二维矩阵
- 所有数据类型是 float
这是标准的矩阵乘法,我们要用 Ascend C 实现它,并最终部署到 昇腾AI芯片 上运行。
2️⃣ 第二步:环境准备(简要说明)
需要:
- 安装 CANN Toolkit(提供 Ascend C 编译器、运行时库、头文件)
- 安装 MindStudio(华为提供的集成开发环境,支持算子开发、调试、性能分析)
- 有昇腾硬件更佳,也可以使用模拟器
如果只是学习,可以从华为云或 CANN 官方获取 MindStudio + 模拟器镜像,无需购买真实硬件。
3️⃣ 第三步:设计算子接口与计算逻辑
我们要实现的计算公式是:
对于每一个 i ∈ [0, M),j ∈ [0, N):
C[i][j] = Σ (A[i][k] × B[k][j]),k ∈ [0, K)
也就是:C 的每个元素是 A 的某一行与 B 的某一列的点积。
4️⃣ 第四步:编写 Ascend C 核心代码(Device 侧,真正计算的代码)
下面是一个 更完整、更接近实际开发场景的 Ascend C 核函数示例,它展示了:
- 如何接收输入输出指针
- 如何通过线程索引确定要计算的 C[i][j]
- 如何执行矩阵乘的核心计算逻辑:点积求和
完整代码示例:矩阵乘核函数
// 文件名:matrix_mul_kernel.ascendc
#include "ascendc.h" // Ascend C 标准头文件
// 核函数:每个线程计算 C矩阵中的一个元素 C[i][j]
__aicore__ void MatrixMulKernel(
const float* A, // 输入矩阵 A [M, K]
const float* B, // 输入矩阵 B [K, N]
float* C, // 输出矩阵 C [M, N]
int M, // A 的行数
int K, // A 的列数 / B 的行数
int N // B 的列数 / C 的列数
) {
// 假设框架已经调度好:每个线程负责一个 C[i][j]
// 这里我们通过内置函数获取当前线程要计算的行号 i 和列号 j
int i = get_global_id(0); // 实际可能是 get_row_idx(),这里仅为示意
int j = get_global_id(1); // 实际可能是 get_col_idx()
// 如果索引超出范围,直接返回(实际中由调度逻辑保证不会越界)
if (i >= M || j >= N) return;
// 用于累加 A[i][:] * B[:][j]
float sum = 0.0f;
// 核心计算:点积
for (int k = 0; k < K; ++k) {
sum += A[i * K + k] * B[k * N + j];
}
// 将计算结果写入到输出矩阵的对应位置 C[i][j]
C[i * N + j] = sum;
}
__aicore__:这是 Ascend C 的关键字,表示该函数将在 昇腾 AI Core 上运行,是运行在硬件上的核心计算单元。- 函数参数:
A是输入矩阵 A 的指针,数据排布为 [M, K],即每行 K 个元素,共 M 行B是输入矩阵 B 的指针,数据排布为 [K, N],即每行 N 个元素,共 K 行C是输出矩阵的指针,数据排布为 [M, N]M, K, N是矩阵的维度,用于计算索引
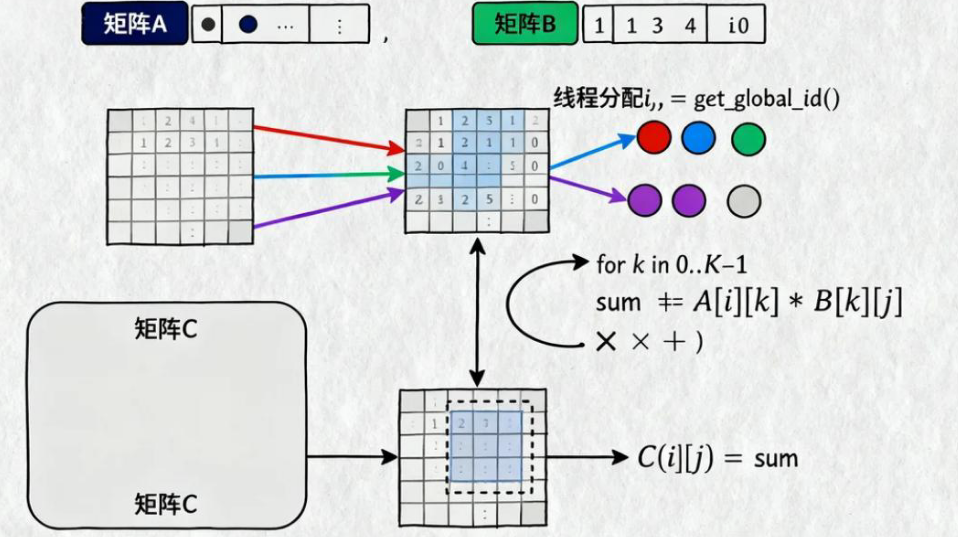
- 线程分工:
- 我们假设每个线程负责计算一个输出元素,即 C[i][j]
get_global_id(0)和get_global_id(1)(示意函数,实际可能是get_row_idx()/get_col_idx())用来获取当前线程对应的行号 i 和列号 j
- 核心计算:
- 通过一个 for 循环,遍历 K,计算 A 的第 i 行与 B 的第 j 列的点积
- 累加结果保存在变量
sum中
- 结果写回:
- 最终将
sum写入到 C[i][j],完成该位置的输出
- 最终将
这就是 Ascend C 算子的核心所在:你只需要专注于如何计算每一个输出元素,框架会帮你调度线程,并行处理所有输出位置。
效果的大致流程如图所示:
5️⃣ 第五步:Host 侧代码
Host 侧代码一般用 C++ 编写,负责:
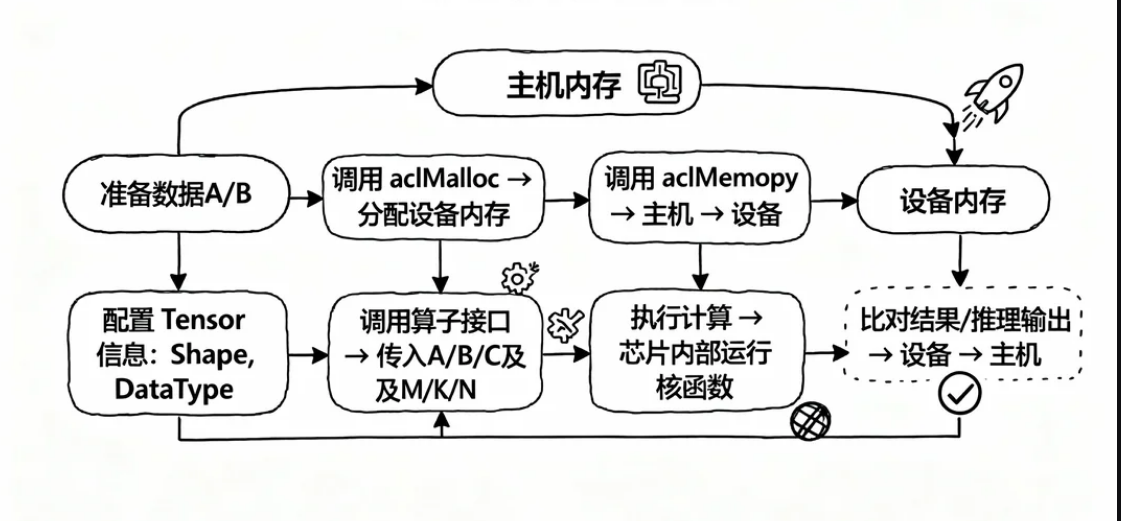
- 准备输入数据 A 和 B(比如随机初始化或从文件加载)
- 调用 aclMalloc 在设备(昇腾卡)上分配内存
- 使用 aclMemcpy 把数据从主机拷贝到设备
- 配置 Tensor 描述信息(Shape、DataType 等)
- 调用算子启动接口,传入 A、B、C 的指针以及 M、K、N 参数
- 把计算结果从设备拷贝回主机
- 比对结果或做后续推理
6️⃣ 第六步:编译与构建
使用 MindStudio 或 CMake 配置工程,调用 CANN 提供的 编译工具链,将 Ascend C 代码编译为 .om 文件(离线模型),供推理时调用。
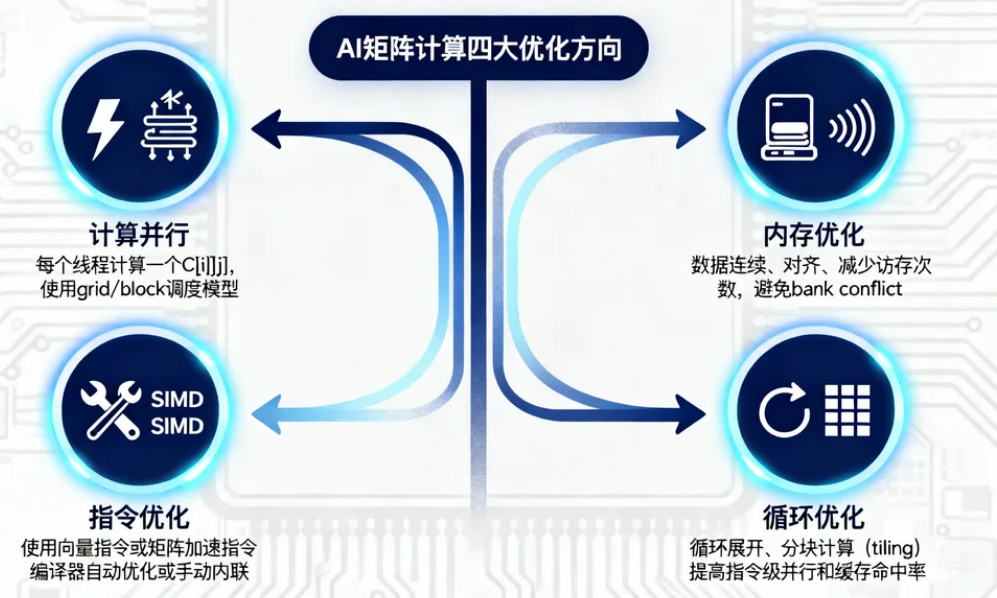
7️⃣第七步:性能优化
矩阵乘是计算密集型任务,常见优化方向包括:
8️⃣ 第八步:常见问题排查
| 问题 | 可能原因 | 排查方法 |
|---|---|---|
| 输出不对 | 索引计算错误、数据未对齐 | 打印中间值,检查索引公式 |
| 程序崩溃 | 内存越界、非法指针 | 检查 aclMalloc / aclMemcpy,确保内存分配正确 |
| 性能低 | 串行计算、访存瓶颈 | 优化线程模型与内存访问模式 |
| 编译失败 | 头文件缺失、链接错误 | 检查 CMake 配置与依赖项 |
五、总结
通过本节课视频,我系统地学习了:
✔ Ascend C 是什么,为什么要用它开发 AI 算子
✔ 为什么矩阵算子是核心,为什么要自定义
✔ Ascend C 矩阵乘算子开发全流程:环境、代码、编译、调试、优化
✔ 核心代码思路与开发实践(尤其是 Device 侧的并行计算逻辑,含完整代码示例)
✔ 性能优化方法论与问题排查思路
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 17
17 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)