【vLLM-模型特性适配】vllm-ascend开发之Rope适配
摘要:本文详细介绍了旋转位置编码(RoPE)的技术原理及其在VLLM框架中的实现。RoPE通过旋转矩阵为Transformer的查询和键向量注入位置信息,支持half和interleave两种计算模式。文章剖析了RoPE的核心计算逻辑,包括位置索引处理、向量拆分和旋转运算,并对比了不同实现方式。随后以Qwen3为例,展示了VLLM中RoPE的完整执行流程,包括初始化、缓存计算及多硬件后端适配机制。
作者:昇腾实战派
1. 背景及Rope结构介绍
RoPE(旋转位置编码)是一种用于Transformer模型的位置编码技术,其核心思想是通过旋转矩阵为查询(q)和键(k)向量注入绝对位置信息,从而在注意力计算中实现相对位置编码。
首先看一下常见的rope计算的逻辑:
-
根据position_id的值从cos_sin_cache中取出对应的cos,和sin。
-
将Q/K在最后一维根据rotary_dim进行拆分。有些模型因为rotary_dim=head_size,所以就不需要这一步,如Qwen2/3。
-
将Q_rot/K_rot在最后一维拆成两份,注意这里有两种模式:half和interleave。
- half也就是gpt_neox style,直接在最后一维对半切:
x.reshape(bs, 2, head_num*head_size//2).chunk(2, dim=-2); - interleave也就是gptj style,是在最后一维交叉取值:
x.reshape(bs, head_num*head_size//2, 2).chunk(2, dim=-1)
- half也就是gpt_neox style,直接在最后一维对半切:
-
以Q为例,这样我们就拿到了x1,x2,cos,sin,接下来就是rope的主要计算,不同模型在实现上有些差异:
# 实现1:
o1 = x1 * cos - x2 * sin
o2 = x2 * cos + x1 * sin
# half模式
q = torch.cat((o1, o2), dim=-1)
# interleave模式
q = torch.stack((o1, o2), dim=-1).flatten(-2)
# 实现2:
# 这一段可能在init中完成
cos = torch.cat((cos, cos), dim=-1)
sin = torch.cat((sin, sin), dim=-1)
def _rotate_neox(x: torch.Tensor) -> torch.Tensor:
x1 = x[..., :x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2:]
return torch.cat((-x2, x1), dim=-1)
def _rotate_gptj(x: torch.Tensor) -> torch.Tensor:
x1 = x[..., ::2]
x2 = x[..., 1::2]
x = torch.stack((-x2, x1), dim=-1)
return x.flatten(-2)
# half模式
q = q * cos + _rotate_neox(q) * sin
# interleave模式
q = q * cos + _rotate_gptj(q) * sin
- 最后需要把Q_pass/K_pass和Q_rot/K_pass再拼回来。
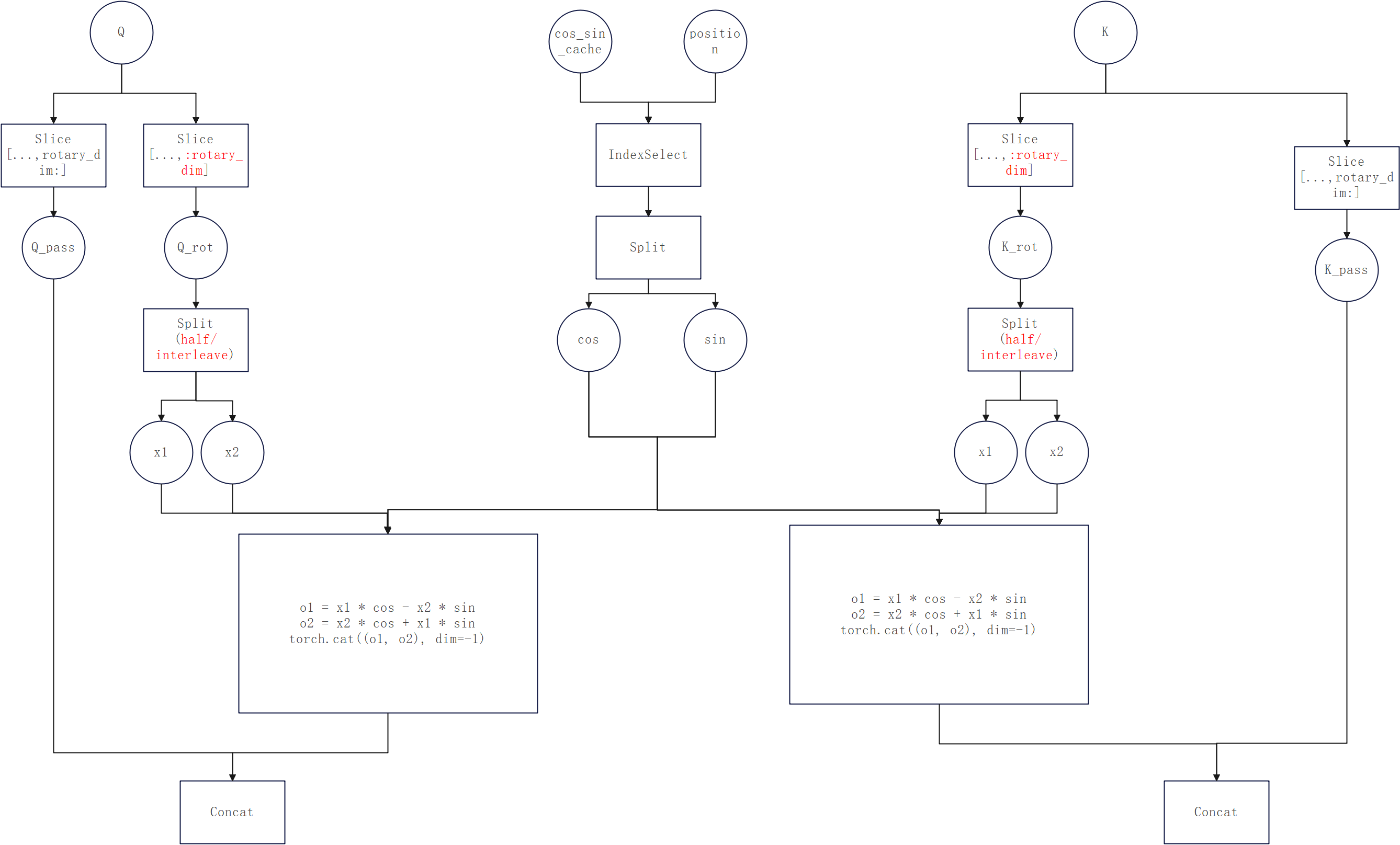
2. vllm中Rope的实现
VLLM的模型统一通过vllm.model_executor.layers.rotary_embedding中的get_rope方法,根据传入的参数来选择具体的RotaryEmbedding类。接下来以v.010.0的Qwen3为例简要说明执行流程:
- 模型的Attention init中调用get_rope获取rope对象:
class Qwen3Attention(nn.Module):
def __init__(self, ...):
...
self.rotary_emb = get_rope(
self.head_dim,
rotary_dim=self.head_dim,
max_position=max_position,
base=self.rope_theta,
rope_scaling=rope_scaling,
)
- get_rope根据config选择RotaryEmbedding类实例化:
def get_rope(...):
...
if dual_chunk_attention_config is not None:
extra_kwargs = {
k: v
for k, v in dual_chunk_attention_config.items()
if k in ("chunk_size", "local_size")
}
rotary_emb = DualChunkRotaryEmbedding(head_size, rotary_dim,
max_position, base,
is_neox_style, dtype,
**extra_kwargs)
elif not rope_scaling:
# Qwen3走的是这个
rotary_emb = RotaryEmbedding(head_size, rotary_dim, max_position, base,
is_neox_style, dtype)
else:
...
- RotaryEmbedding的init中生成self.cos_sin_cache,forward中执行实际的rope计算:
class RotaryEmbedding(CustomOp):
def __init__(...):
super().__init__()
self.head_size = head_size
self.rotary_dim = rotary_dim
self.max_position_embeddings = max_position_embeddings
self.base = base
self.is_neox_style = is_neox_style
self.dtype = dtype
# 此处生成最大序列长度的cos_sin_cache
cache = self._compute_cos_sin_cache()
cache = cache.to(dtype)
self.cos_sin_cache: torch.Tensor
# 注册为self.cos_sin_cache
self.register_buffer("cos_sin_cache", cache, persistent=False)
self.is_rocm_aiter_enabled = is_rocm_rotary_embedding_enabled()
# 此处计算inv_freq
def _compute_inv_freq(self, base: float) -> torch.Tensor:
"""Compute the inverse frequency."""
# NOTE(woosuk): To exactly match the HF implementation, we need to
# use CPU to compute the cache and then move it to GPU. However, we
# create the cache on GPU for faster initialization. This may cause
# a slight numerical difference between the HF implementation and ours.
inv_freq = 1.0 / (base**(torch.arange(
0, self.rotary_dim, 2, dtype=torch.float) / self.rotary_dim))
return inv_freq
# 此处根据最大长度计算cos和sin
def _compute_cos_sin_cache(self) -> torch.Tensor:
"""Compute the cos and sin cache."""
inv_freq = self._compute_inv_freq(self.base)
t = torch.arange(self.max_position_embeddings, dtype=torch.float)
# 注意部分模型(如gemma3)的非vllm实现中,这里会对freqs做repeat,对应上节1.4中实现2:
# freqs = torch.cat((freqs, freqs), dim=-1)
freqs = torch.einsum("i,j -> ij", t, inv_freq)
cos = freqs.cos()
sin = freqs.sin()
cache = torch.cat((cos, sin), dim=-1)
return cache
def forward_native(...):
...
def forward_cuda(...):
...
def forward_xpu(...):
...
def forward_hpu(...):
...
def forward_neuron(...):
...
- 可以看到上面的RotaryEmbedding针对不同的硬件后端有多个forward方法,forward的选择逻辑在其基类CustomOp中实现,vllm-ascend是通过替换forward_oot方法来做的兼容:
class CustomOp(nn.Module):
"""
Base class for custom ops.
Dispatches the forward method to the appropriate backend.
"""
def __init__(self):
super().__init__()
self._forward_method = self.dispatch_forward()
def forward_oot(self, *args, **kwargs):
# By default, we assume that OOT ops are compatible with the
# PyTorch-native implementation.
return self.forward_native(*args, **kwargs)
def dispatch_forward(self):
# NOTE(woosuk): Here we assume that vLLM was built for only one
# specific backend. Currently, we do not support dynamic dispatching.
compilation_config = get_current_vllm_config().compilation_config
enabled = self.enabled()
if enabled:
compilation_config.enabled_custom_ops.update([self.__class__.name])
else:
compilation_config.disabled_custom_ops.update(
[self.__class__.name])
if not enabled:
return self.forward_native
if current_platform.is_rocm():
return self.forward_hip
elif current_platform.is_cpu():
return self.forward_cpu
elif current_platform.is_hpu():
return self.forward_hpu
elif current_platform.is_tpu():
return self.forward_tpu
elif current_platform.is_xpu():
return self.forward_xpu
elif current_platform.is_neuron():
return self.forward_neuron
elif current_platform.is_out_of_tree():
return self.forward_oot
else:
return self.forward_cuda
3. vllm-ascend的实现
- 以v0.10.0rc1为例,vllm-ascend的rope实现在ops/rotary_embedding.py中,可以看到我们单独写了个rope_forward_oot方法并在最后替换了原生的forward_oot。所以通过vllm-ascend调用的RotaryEmbedding,最终都会走rope_forward_oot**:**
def rope_forward_oot(
self,
positions: torch.Tensor,
query: torch.Tensor,
key: torch.Tensor,
offsets: Optional[torch.Tensor] = None,
is_neox_style_override: Optional[bool] = None
) -> Tuple[torch.Tensor, torch.Tensor]:
if get_ascend_config().torchair_graph_config.enabled:
return self.forward_native(
positions,
query,
key,
offsets,
)
import torch_npu
query_shape, key_shape = query.shape, key.shape
if self.cos_sin_cache.device != query.device:
self.cos_sin_cache = self.cos_sin_cache.to(query.device)
if self.cos_sin_cache.dtype != query.dtype:
self.cos_sin_cache = self.cos_sin_cache.to(query.dtype)
neox_style = self.is_neox_style
if is_neox_style_override is not None:
neox_style = is_neox_style_override
# adopt custom kernel path for rotary_embedding
if custom_rotary_embedding_enabled(query, neox_style,
self.head_size) and not is_310p():
query, key = torch.ops._C.rotary_embedding(
positions,
query,
key,
self.head_size,
self.cos_sin_cache,
neox_style,
)
return query.view(query_shape), key.view(key_shape)
if offsets is not None:
raise NotImplementedError(
"Batched rotary embedding is currently not supported on NPU.")
else:
# 默认走这里
query = query.contiguous().view(query.shape[0], -1)
key = key.contiguous().view(key.shape[0], -1)
torch_npu._npu_rotary_embedding(
positions,
query,
key,
self.head_size,
self.cos_sin_cache,
neox_style,
)
return query.view(query_shape), key.view(key_shape)
...
RotaryEmbedding.forward_oot = rope_forward_oot
- 当前调用的接口torch_npu._npu_rotary_embedding使用的是ATB算子,以下是torch_npu里的适配代码,我在需要注意的细节上加了注释:
void InitializeCosSinCache(const at::Tensor &cos_sin_cache)
{
auto cosSinChunks = cos_sin_cache.chunk(2, -1);
// 算子内部的实现猜测也是1.4中实现2,所以该接口会自动对cos和sin做repeat,需要注意
cosCache = cosSinChunks[0].repeat_interleave(2, 1);
sinCache = cosSinChunks[1].repeat_interleave(2, 1);
cosCacheNeox = cosSinChunks[0].repeat({1, 2});
sinCacheNeox = cosSinChunks[1].repeat({1, 2});
}
void _npu_rotary_embedding(const at::Tensor &positions, at::Tensor &query, at::Tensor &key, int64_t head_size, const at::Tensor &cos_sin_cache, bool is_neox_style)
{
const c10::OptionalDeviceGuard device_guard(device_of(positions));
// 这里接口内部会缓存cos和sin(存疑),对于cos和sin会根据layer变动的模型(gemma3)可能会有精度问题。
if (!cosCache.defined() || !sinCache.defined()) {
InitializeCosSinCache(cos_sin_cache);
}
at::Tensor flatPositions = positions.flatten();
int32_t currentTokenCount = flatPositions.size(0);
// 每次执行rope都会调用两次index_select,一次decode就会执行layer_num*2次。
// 但实际每个layer的cos_sin_cache和position_id都一样,所以这里属于重复计算。
// 优化思路是把这两个index_select移到layer的循环之前
at::Tensor cos = is_neox_style ? cosCacheNeox.index_select(0, flatPositions)
: cosCache.index_select(0, flatPositions);
at::Tensor sin = is_neox_style ? sinCacheNeox.index_select(0, flatPositions)
: sinCache.index_select(0, flatPositions);
if (!sequenceLength.defined() || previousTokenCount != currentTokenCount) {
previousTokenCount = currentTokenCount;
sequenceLength = at::tensor({currentTokenCount}, at::kInt).to(query.device());
}
RopeParam ropeparam;
ropeparam.rotaryCoeff = is_neox_style ? 2 : head_size;
ParamSetter parametter;
parametter.Input(query, true)
.Input(key, true)
.Input(cos, true)
.Input(sin, true)
.Input(sequenceLength, true)
.Output(query)
.Output(key);
OpParamCache<RopeParam> &ropeParamCache = OpParamCache<RopeParam>::getInstance();
auto opRope = ropeParamCache.getOperation(ropeparam, "RopeOperation");
RunAtbCmd(opRope, parametter, "RopeOperation");
}
- 如果你的模型使用的不是RotaryEmbedding,则需要进行额外的适配,比如DeepseekScalingRotaryEmbedding:
def native_rope_deepseek_forward(self,
positions: torch.Tensor,
query: torch.Tensor,
key: torch.Tensor,
offsets: Optional[torch.Tensor] = None,
max_seq_len: Optional[int] = None):
if max_seq_len is not None and max_seq_len > self.max_seq_len:
_set_cos_sin_cache(self, max_seq_len, query.device, query.dtype)
if len(key.shape) == 2:
key = key[:, None, :]
# Note: we implement the non neox_style method with shuffle the last dim and neox style
# calculation method which is also more compute friendly to the ascend machine
# https://huggingface.co/deepseek-ai/DeepSeek-V3-0324/blob/main/modeling_deepseek.py
neox_style = True
if self.is_neox_style is False:
b, h_q, d = query.shape
query = query.view(b, h_q, d // 2, 2).transpose(3,
2).reshape(b, h_q, d)
b, h_k, d = key.shape
key = key.view(b, h_k, d // 2, 2).transpose(3, 2).reshape(b, h_k, d)
q_pe, k_pe = rope_forward_oot(self, positions, query, key, offsets,
neox_style)
return q_pe, k_pe
DeepseekScalingRotaryEmbedding.forward = native_rope_deepseek_forward
4. torch_npu的rope接口们
-
torch_npu._npu_rotary_embedding:现在vllm-ascend中默认使用的接口,调用ATB的RopeOperation,下图红线内的就是它的计算逻辑。
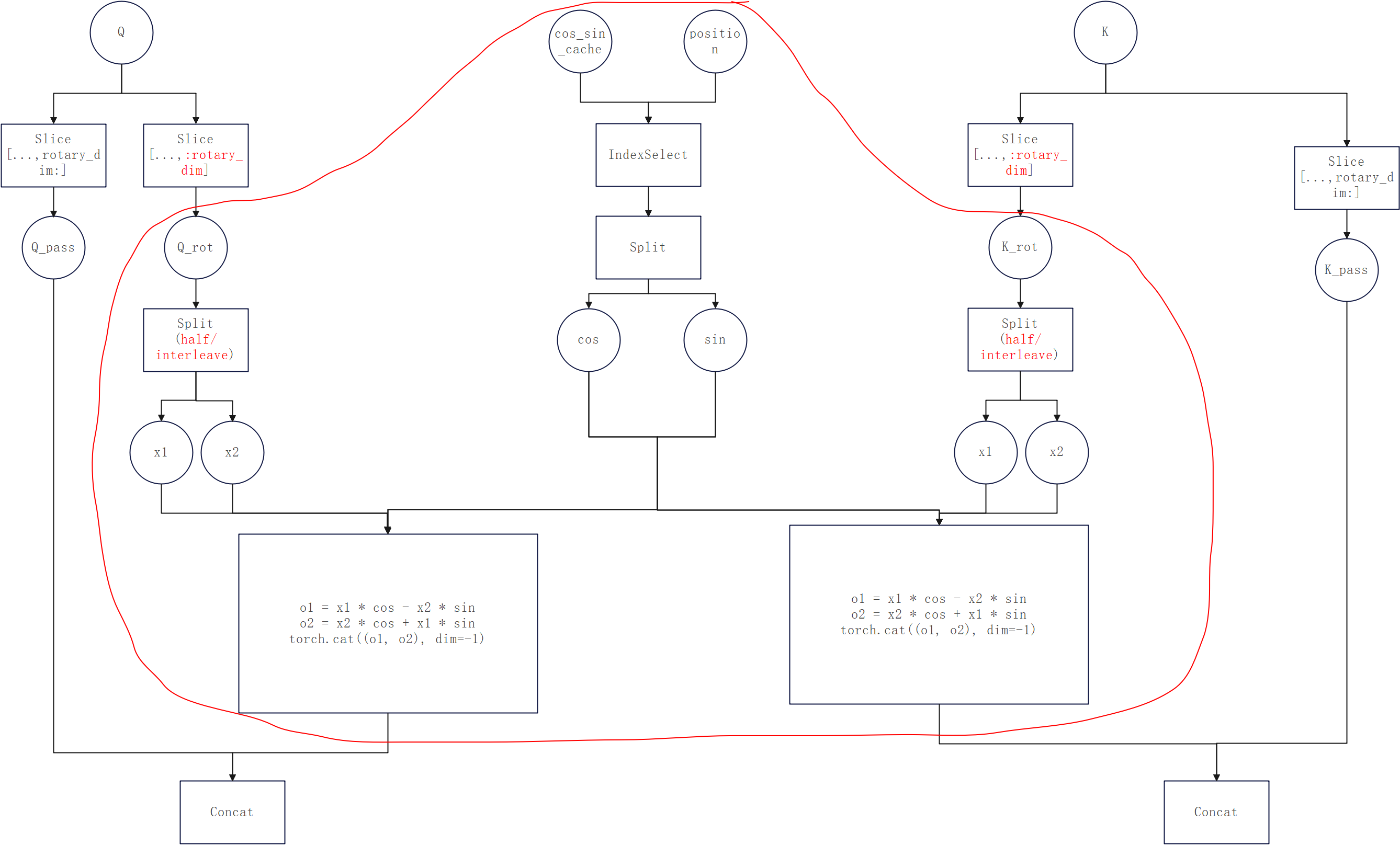
-
torch_npu.npu_mrope:调用aclnnRopeWithSinCosCache算子,同时支持rope和mrope,计算逻辑和_npu_rotary_embedding一致,因为做了select_index+rope融合,所以性能更好。
query, key = torch_npu.npu_mrope(
positions,
query,
key,
self.cos_sin_cache,
self.head_size,
mrope_section=[0,0,0], # 走rope时这里设为全0
rotary_mode='half' if neox_style else 'interleave',
)
- torch_npu.npu_apply_rotary_pos_emb:调用aclnnApplyRotaryPosEmb算子,没有包含index_select部分,可以用来做cos和sin外置优化(参考链接:https://github.com/vllm-project/vllm-ascend/pull/1719),但是限制较多:
- 需要传入repeat后的cos和sin
- 只支持neox style
- 要求模型的head_size和rotary_dim都为128
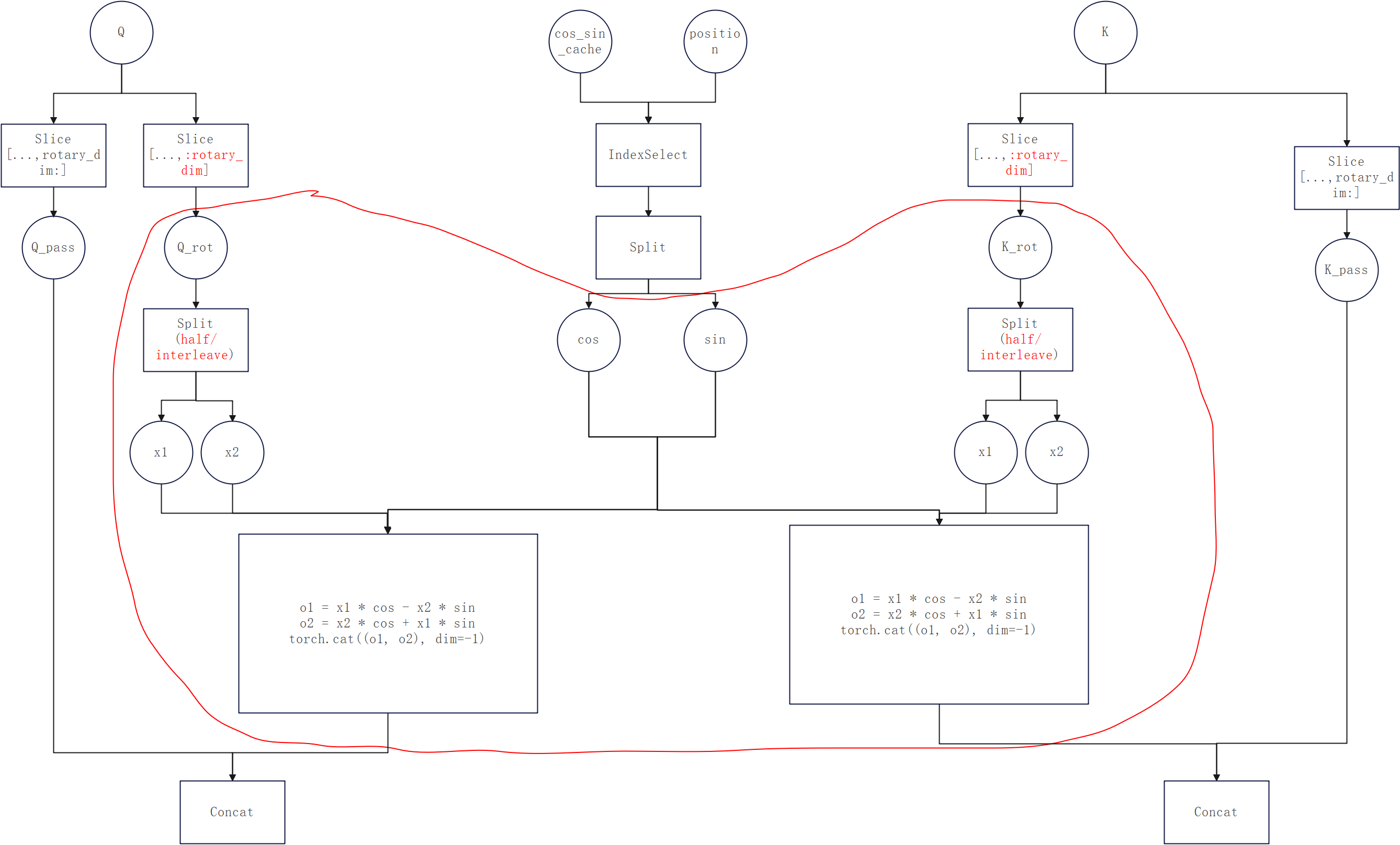
- torch_npu.npu_interleave_rope:调用aclnnInterleaveRope算子,3中接口只支持neox style,那interleave模式可以尝试这个接口,参考文档:https://www.hiascend.com/document/detail/zh/Pytorch/710/apiref/torchnpuCustomsapi/context/torch_npu-npu_interleave_rope.md
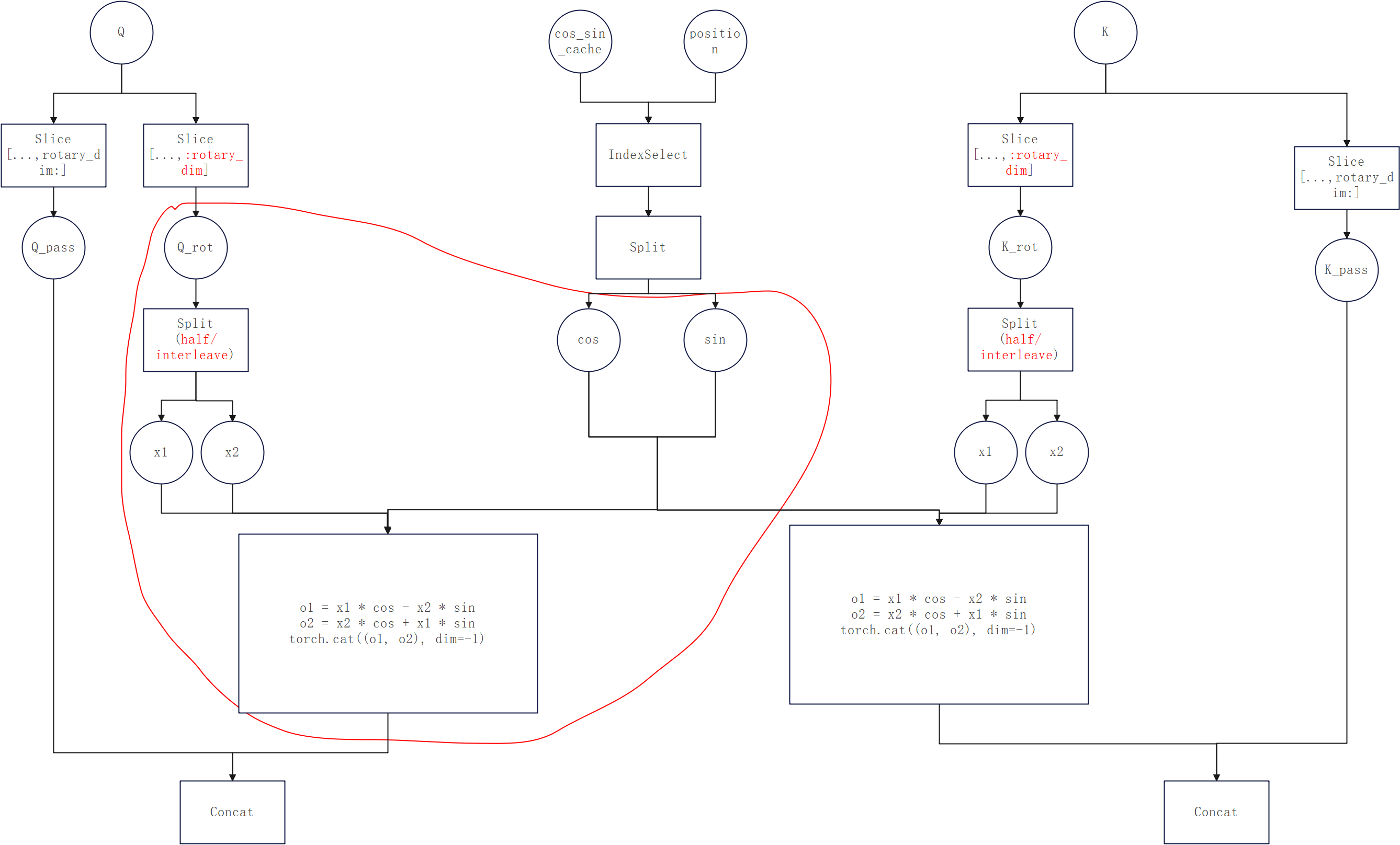
- torch_npu.npu_rotary_mul:如下图,计算Q和K需要调两次这个接口,也能用来实现cos和sin外置,但性能如何暂未验证,参考文档:https://www.hiascend.com/document/detail/zh/Pytorch/710/apiref/torchnpuCustomsapi/context/torch_npu-npu_rotary_mul.md

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)