MindIE推理蒸馏模型DeepSeek-R1-Distill-Qwen-1.5B
本文介绍了使用与分别对轻量蒸馏模型进行纯模型推理与服务化推理。
本文介绍了使用atb-models与mindie-service分别对轻量蒸馏模型DeepSeek-R1-Distill-Qwen-1.5B进行纯模型推理与服务化推理。
1. 下载与安装
1.1 模型权重下载
建议下载到/home目录下,下一步创建的容器跟宿主机共享/home目录下文件
git lfs install
git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B.git下载好的模型权重如下图所示
![]()
1.2 下载相关镜像
在官方镜像仓库获取Mindie镜像
创建容器(修改容器名称与镜像ID)
docker run -it -d --net=host --shm-size=1g \ --privileged \ --name 容器名称 \ --device=/dev/davinci_manager \ --device=/dev/hisi_hdc \ --device=/dev/devmm_svm \ -v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \ -v /usr/local/sbin:/usr/local/sbin:ro \
-v /path-to-weights:/path-to-weights:ro \
-v /home:/home \
镜像ID进入容器(修改容器名称)
docker exec -it 容器名称 bash2. 推理
2.1 纯模型推理
2.1.1 对话测试
进入atb-models路径(默认路径:/usr/local/Ascend/atb-models),修改模型路径并执行如下命令
torchrun --nproc_per_node 2 --master_port 20037 -m examples.run_pa --model_path 模型路径 --max_output_length 20如下图所示
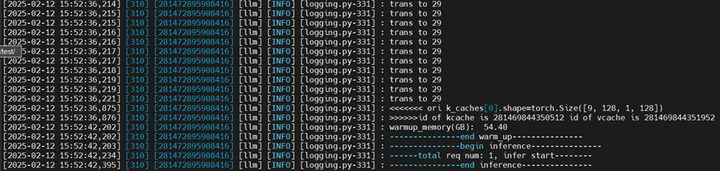
2.1.2 性能测试
从当前目录进入modeltest路径
cd /test/modeltest运行测试脚本
bash run.sh pa_[data_type] performance [case_pair] [batch_size] ([prefill_batch_size]) [model_name] ([is_chat_model]) (lora [lora_data_path]) [weight_dir] ([trust_remote_code]) [chip_num] ([parallel_params]) ([max_position_embedding/max_sequence_length])具体执行batch=1, 输入长度256, 输出长度256用例的2卡并行性能测试命令如下:
bash run.sh pa_bf16 performance [[256,256]] 1 qwen 模型路径 2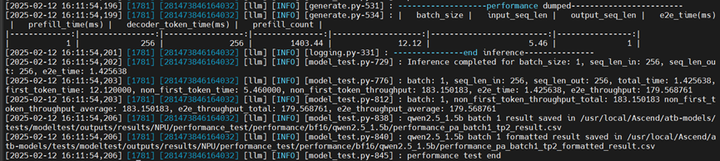
测试结果
2.2服务化推理
进入mindie-service路径,打开config.json文件
cd /usr/local/Ascend/mindie/latest/mindie-service
vim conf/config.json修改config.json文件如下内容并保存
"httpsEnabled" : false,
"npuDeviceIds" : [[0,1]],
"truncation" : false,
"modelName" : "qwen",
"modelWeightPath" : "模型路径",
"worldSize" : 2打开模型路径中的config.json,将modelName修改为qwen并保存,退出后执行如下指令配置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh
source /usr/local/Ascend/mindie/set_env.sh
source /usr/local/Ascend/atb-models/set_env.sh回到mindie-service路径,进入/bin,执行如下命令启动服务化
./mindieservice_daemon
如果报上图错误说明是权限问题,将mindie-service/conf/config.json与模型路径中的config.json都赋予640权限
chmod 640 config.json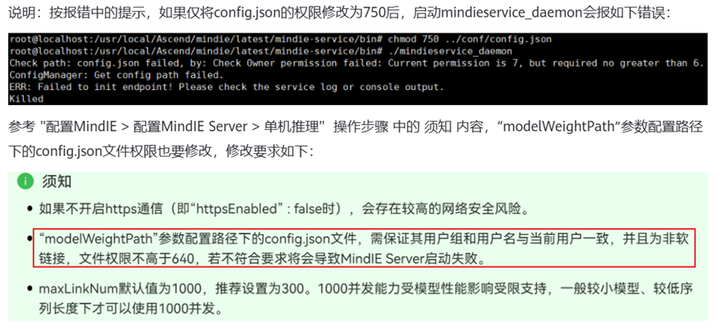

如上图所示,成功拉起服务化,重开一个窗口,在宿主机执行如下指令即可进行推理
curl 127.0.0.1:1025/generate -d '{
"prompt": "我叫小明",
"max_tokens": 32,
"stream": false,
"do_sample":true,
"repetition_penalty": 1.00,
"temperature": 0.01,
"top_p": 0.001,
"top_k": 1,
"model": "qwen"
}'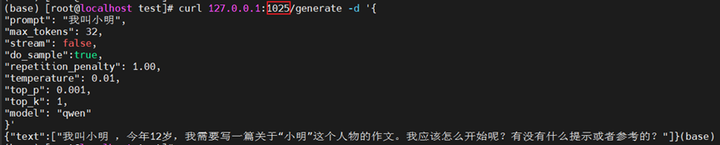
推理成功
注意:红框部分需要修改成mindie-service/conf/config.json中填写的port

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)