昇腾AI应用开发实战:从AscendC基础到Atlas开发板部署
华为昇腾AI全栈技术体系基于达芬奇架构处理器,构建了从芯片到应用的完整解决方案。Atlas 200 IDKA2开发板搭载昇腾310B芯片,支持8GB内存和24TOPS算力,适用于边缘AI任务。AscendC编程语言专为AI计算设计,支持多核并行和三级流水线编程。以YOLOv7模型部署为例,展示了模型转换、推理程序开发和性能优化过程。开发建议包括容器化环境配置、性能调优、内存管理等策略。昇腾平台将持
一、昇腾AI全栈技术体系概述
华为昇腾AI生态系统基于自研的达芬奇(Da Vinci)架构AI处理器,构建了从芯片层、芯片使能层、应用使能层到商业应用层的全栈解决方案。该技术体系覆盖了从底层硬件到上层应用的全链路AI开发需求,具备软硬协同优化的显著优势。
- 硬件基础层 昇腾系列AI处理器采用创新的达芬奇3D Cube架构,通过独特的张量计算引擎实现高效的矩阵运算。典型产品包括:
- 昇腾910:面向数据中心的旗舰级AI处理器
- 昇腾310:面向边缘计算的低功耗AI处理器
2.软件中间层 CANN(Compute Architecture for Neural Networks)作为核心软件栈,包括:
- 算子开发库:提供3000+基础算子
- 图引擎:支持动态/静态图执行
- 任务调度器:实现高效的异构计算资源管理
- 运行时环境:提供模型加载、内存管理等基础服务
3.计算能力实现 昇腾AI处理器的计算能力主要通过AI Core实现:
- 每个AI Core包含:
- 2个计算单元(Cube Unit)
- 1个向量处理单元(Vector Unit)
- 专用存储缓冲区
- 支持多种数据精度计算:
- FP32/FP16:高精度计算
- INT8/INT4:低比特量化计算
- 混合精度训练支持

4.开发工具链 华为推出了专为AI计算设计的编程语言AscendC,主要特性包括:
- 类C++语法设计
- 内置AI专用指令集
- 支持自动并行优化
- 提供丰富的数学函数库 典型应用场景包括计算机视觉、自然语言处理、推荐系统等领域的核心算法开发。
二、Atlas 200I DK A2开发板硬件解析
Atlas 200I DK A2是华为推出的高性能AI开发者套件,专为边缘计算场景设计。该开发板采用昇腾310B处理器芯片,基于达芬奇架构,支持AI推理和训练任务。硬件配置方面,搭载8GB LPDDR4X高速内存(带宽达51.2GB/s),集成24TOPS INT8计算能力,可高效执行计算机视觉、自然语言处理等AI任务。
核心接口规格:
- 显示输出:支持4K@30fps的HDMI 2.0接口
- 数据接口:2个USB 3.0 Type-A接口(理论带宽5Gbps),1个USB Type-C调试接口
- 网络连接:千兆以太网口(RJ45),支持Wi-Fi/蓝牙扩展
- 存储扩展:1个M.2插槽支持NVMe SSD
- 其他接口:40针GPIO扩展接口、3.5mm音频接口
开发环境搭建详细步骤:
-
准备阶段:
- 从华为昇腾社区下载最新Mind Studio开发套件(包含Ubuntu 18.04镜像)
- 准备8GB以上U盘作为安装介质
- 下载HiTool刷机工具(版本需匹配开发板型号)
-
硬件连接:
- 使用USB Type-C数据线连接开发板与主机
- 接上12V/2A电源适配器
- 通过HDMI连接显示器(可选)
-
系统烧录:
- 启动HiTool工具,选择"烧写eMMC"模式
- 加载已下载的.img格式系统镜像
- 设置波特率为115200,点击"烧写"按钮
- 等待进度条完成(约15-20分钟)
-
环境配置:
- 首次启动后运行初始化脚本:
sudo ./init_env.sh - 配置静态IP或连接Wi-Fi网络
- 安装必备组件:CANN工具包、Python3.7+、OpenCV等
- 验证安装:运行
npu-smi info查看设备状态
- 首次启动后运行初始化脚本:
典型应用场景:
- 智能视频分析(如人脸识别、行为分析)
- 工业质检(缺陷检测)
- 智慧城市(交通流量监控)
- 机器人视觉导航
三、AscendC编程语言深度解析
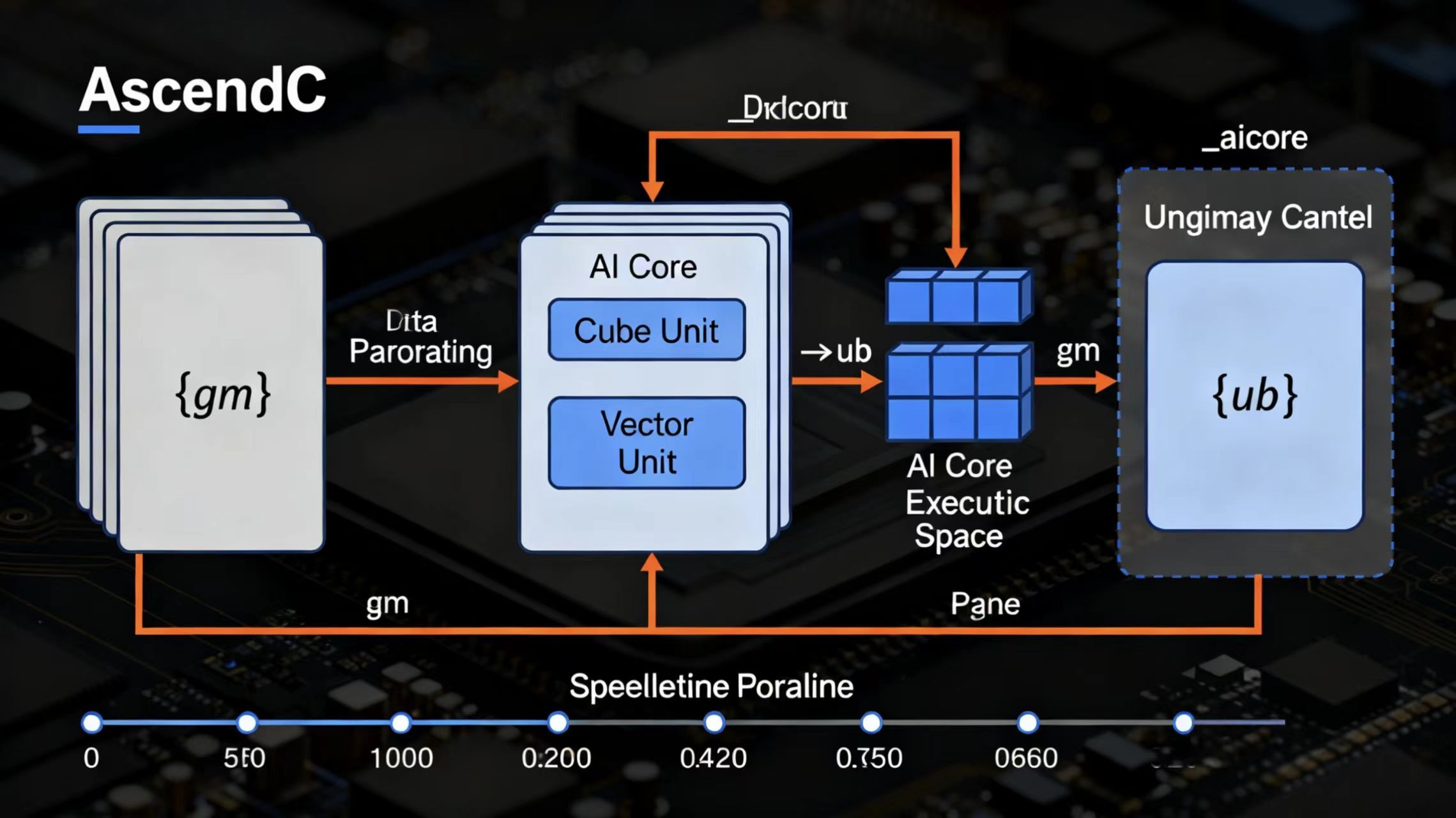
3.1 核心语言特性
AscendC基于标准C++语法规范进行扩展,提供了专为AI计算设计的编程接口。其主要特性包括:
函数执行空间限定符:通过__aicore__修饰符指定函数在AI Core上执行
__aicore__ void kernel_example(/* 参数列表 */) {
// 核函数实现
}
地址空间限定符:明确数据存储位置,包括__gm__(全局内存)、__ub__(统一缓存)等
__gm__ float* input_data; // 全局内存数据指针
3.2 核函数开发模式
AscendC采用三级流水线编程范式,最大化硬件利用效率:
- 数据搬运阶段:将数据从全局内存搬入到片上升级缓存
- 计算阶段:在AI Core上进行矩阵运算和向量计算
- 数据回写阶段:将计算结果从片上缓存写回全局内存
3.3 多核并行编程
AscendC支持多核并行计算,通过数据切分实现任务级并行:
// 核函数调用示例
constexpr int32_t block_num = 8;
constexpr int32_t tile_len = 2048;
void invoke_kernel() {
// 多核并行配置
ascendc::set_core_num(block_num);
// 核函数调用
kernel_example<<<block_num, ascendc::GMDEFAULT>>>(/* 参数 */);
}
四、实战案例:YOLOv7模型部署
4.1 环境准备与模型转换
首先需要将PyTorch或TensorFlow训练的YOLOv7模型转换为昇腾支持的OM模型格式:
# 使用ATC工具进行模型转换
atc --model=yolov7.prototxt \
--weight=yolov7.caffemodel \
--framework=0 \
--output=yolov7 \
--soc_version=Ascend310 \
--input_shape="input:1,3,640,640"
4.2 推理程序开发
基于AscendC的推理程序主要包括以下组件:
#include <iostream>
#include "acl/acl.h"
class YOLOv7Infer {
public:
YOLOv7Infer() {
// 初始化ACL上下文
aclInit(nullptr);
aclrtSetDevice(0);
}
~YOLOv7Infer() {
// 资源释放
aclrtResetDevice(0);
aclFinalize();
}
void load_model(const std::string& model_path) {
// 模型加载实现
// ...
}
void inference(const cv::Mat& input_image) {
// 预处理、推理、后处理完整流程
// ...
}
};
4.3 性能优化技巧
- 内存复用:通过AscendC内存管理接口实现内存预分配和复用
- 流水线并行:重叠数据搬运与计算操作
- 算子融合:使用TBE(Tensor Boost Engine)自定义融合算子
高效内存管理:利用AscendC接口预分配并复用内存资源 智能流水线优化:实现数据搬运与计算操作的无缝重叠 深度算子融合:基于TBE引擎构建高性能自定义融合算子
五、开发实践建议
5.1 开发环境配置与工具链使用
为提升开发效率,建议采用容器化方式部署昇腾AI开发环境。华为官方提供的Docker镜像已预装CANN工具包、MindSpore框架及AscendCL库,能够避免环境依赖冲突。推荐使用Ascend-Docker镜像作为基础环境,通过VSCode远程连接进行开发,充分利用其代码提示和调试功能。
开发过程中应熟练使用Ascend-CLI工具链,包括:
- ATC模型转换工具:支持从ONNX、TensorFlow等格式向OM模型转换,需注意指定正确的soc_version参数
- Ascend-Debugger:支持图形化性能分析和算子精度比对,可定位计算图异常节点
- msprof性能采集器:生成 timeline.json 文件可视化硬件执行流水线
5.2 性能分析与调优方法
性能优化应遵循"测量-分析-优化"的闭环流程:
诊断工具使用示例:
# 采集推理性能数据
msprof --application="python infer.py" --output=./profile
# 生成瓶颈分析报告
ascend-dbg -m model.om -i input.bin -o output_report
优化后的性能指标关注点:
核心性能指标监测重点:
- 计算资源利用率
- 通过npu-smi工具实时监控AI Core使用率
- 目标是将计算单元利用率稳定维持在80%以上
- 内存带宽优化
- 实施内存复用技术降低HBM访问频率
- 运用__aicore__限定符优化数据布局
- 并行处理效率
- 采用双缓冲技术实现计算与数据传输重叠
- 参考标准流水线并行实现方案
- :
// 流水线并行示例
__aicore__ void pipeline_kernel() {
// 阶段1: 异步预取下一批次数据
ascendc::async_copy(gm_input, ub_buffer);
// 阶段2: 处理当前批次数据
process_data(ub_buffer);
// 阶段3: 回写结果
ascendc::async_copy(ub_result, gm_output);
}
5.3 内存与资源管理
针对Atlas 200I DK A2的8GB内存约束,推荐采用以下策略:
- 内存预分配:在初始化阶段通过aclrtMallocHost申请持久化内存池
- 动态分片:对大型模型实施Tensor切分,使用AscendC的tile机制分块处理
- 零拷贝优化:对于视频流处理场景,配置DVPP硬解码直接输出到Device内存
5.4 模型优化专项实践
混合精度部署方案:
- 使用AMP(Auto Mixed Precision)工具自动识别可转换为FP16的算子
- 对敏感层(如分类头)保持FP32精度
- 插入Loss Scale防止梯度下溢
算子融合优化:
通过TBE(Tensor Boost Engine)自定义融合算子:
# 自定义BN-ReLU融合算子
@te_fusion.fusion_pattern(pattern="BN+ReLU")
def bn_relu_fusion(input_shape):
bn_output = te_batch_norm(input_shape)
return te_relu(bn_output)
5.5 测试与持续集成
建立自动化测试流水线:
- 精度验证:使用NPU精度校验工具比对GPU/CPU计算结果
- 性能回归:在ATC转换阶段注入--precision_mode参数控制精度模式
- 功耗监控:通过内置传感器采集典型场景下的功耗曲线
推荐搭建Jenkins+Ascend-Toolkit的CI/CD环境,实现:
- 自动模型转换与量化
- 夜间回归测试
- 性能基线对比
六、总结与展望
昇腾AI平台通过AscendC编程语言和Atlas硬件设备的结合,为AI应用开发提供了高性能的软硬件一体化解决方案。随着生态系统的不断完善,昇腾平台在计算机视觉、自然语言处理等领域的应用将更加广泛。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 26
26 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)