昇腾CANN开发:Ascend C算子开发全流程实践
昇腾CANN训练营2025第二季专为零基础开发者量身打造成长阶梯,以开源开放的全场景生态为依托,通过体系化课程、实操案例与专属福利,助力小白快速解锁算子开发技能,轻松迈入AI底层技术领域。- 开源基础系列(周一19:00):从Ascend C语法基础、算子开发核心概念讲起,配套极简入门代码示例,搭配详细注释与截图演示,让零基础学习者快速搭建知识框架。即刻加入,锁定每周直播课程,跟着讲师拆解代码、完
·
一、前言
昇腾CANN作为华为昇腾AI芯片的核心开发套件,为算子开发提供了全栈式技术支撑,而Ascend C作为CANN生态下面向算子原生开发的核心语言,凭借底层硬件直达、高性能优化、灵活适配多场景的优势,成为实现算子极致性能的关键技术路径。本文聚焦Ascend C算子开发全流程,从开发环境深度配置、核心技术原理拆解、算子编码实现细节、编译调试优化到性能验证,补充更多底层逻辑、实操技巧与问题解决方案,精准覆盖有经验开发者的技术需求,助力高效完成高性能Ascend C算子开发,规避开发过程中的核心技术难点。
二、Ascend C算子开发核心基础
2.1 核心技术定位与优势
Ascend C是面向昇腾AI芯片张量计算单元(TPU)的原生算子开发语言,基于C/C++扩展增强,通过直接操作芯片硬件资源(计算单元、存储单元、总线),突破高阶框架封装带来的性能损耗,其核心优势体现在三方面:
1. 硬件亲和性强:深度适配昇腾芯片异构计算架构,支持直接调用TPU核心计算指令,最大化发挥硬件算力;
2. 性能优化空间大:提供细粒度的存储层级(寄存器、L1 Buffer、L2 Buffer、DDR)管理能力,支持数据本地化调度优化;
3. 场景适配灵活:可开发通用算子、专用算子,适配深度学习训练/推理全场景,兼容CANN全栈工具链,无缝集成到TensorFlow、PyTorch等框架。
2.2 核心概念拆解
- 算子层级划分:Ascend C算子属于CANN底层算子(L0层),区别于框架层算子(L1层)与应用层算子(L2层),直接映射硬件指令,是高性能计算的核心载体;
- 存储层级模型:昇腾芯片存储体系从快到慢分为寄存器(最高速,容量最小)、L1 Buffer(核内高速缓存)、L2 Buffer(片上共享缓存)、DDR(外部内存),Ascend C开发的核心优化点的就是减少跨层级数据搬运,提升数据复用率;
- 核函数与任务调度:Ascend C算子以核函数(Kernel)形式存在,通过任务调度单元(TSU)分配到不同TPU核心执行,支持单核、多核并行调度,需通过合理的任务划分提升并行效率;
- 数据类型适配:原生支持昇腾芯片优化的数据类型(如fp16、bf16、int8、uint8等),同时兼容通用数据类型,需根据计算场景选择适配类型平衡性能与精度。
三、开发环境深度配置
3.1 环境依赖精准匹配
- 基础依赖版本组合:
- 昇腾AI芯片:Ascend 310P/910A(主流开发芯片,支持Ascend C全特性);
- CANN版本:6.0.RC1及以上(需与芯片型号匹配,低版本可能缺失部分Ascend C API);
- 编译器:aarch64-linux-gnu-gcc 7.3.0(ARM架构)、x86_64-linux-gnu-gcc 7.3.0(x86架构,仅用于交叉编译);
- 开发工具:Visual Studio Code(安装Ascend C插件、C/C++插件)、DDK工具链(CANN自带,包含Ascend C编译工具);
- 调试工具:Ascend Debugger(ADB,CANN配套调试工具,支持算子执行过程追踪)。
- 版本校验命令(避免版本不兼容导致开发异常):

3.2 环境变量精细化配置
CANN安装完成后,需配置精准的环境变量,保障Ascend C编译、运行依赖正常加载,以CANN安装路径 /usr/local/Ascend/cann-toolkit 为例,完整环境变量配置如下(添加到 ~/.bashrc 文件):

配置完成后执行 source ~/.bashrc 生效,通过 echo $ASCEND_C_PATH 校验变量是否配置成功,确保Ascend C头文件、库文件可正常索引。
3.3 工程目录规范搭建
为提升算子工程可维护性,按功能分层搭建规范目录结构,适配多算子协同开发与版本管理:
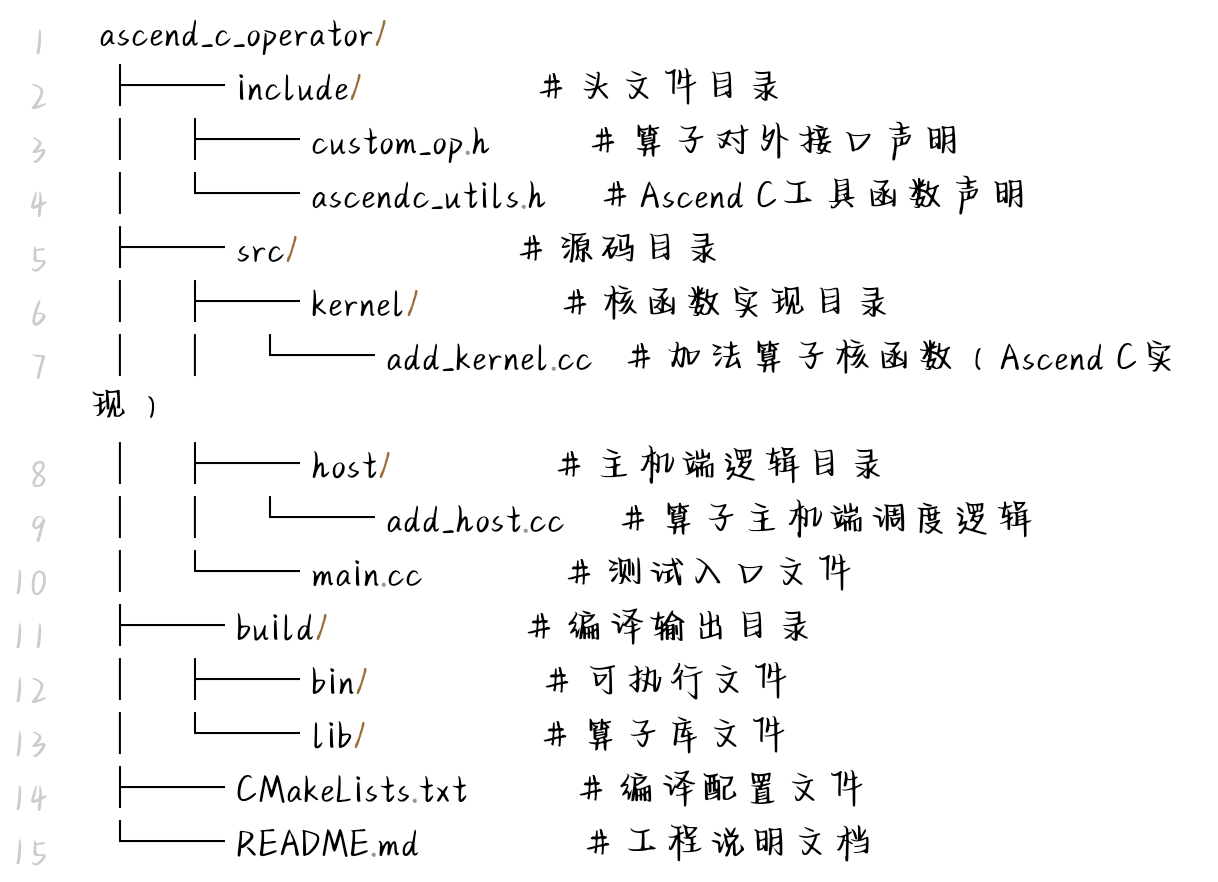
四、Ascend C算子开发全流程
以自定义fp16精度加法算子为例,完整拆解从需求分析到编码实现的全流程,补充底层实现逻辑与优化技巧。
4.1 算子需求与硬件适配分析
- 核心需求:实现两个fp16类型张量的逐元素加法,支持任意维度(1D~4D),输入输出张量形状一致;
- 硬件适配设计:
1. 计算单元选择:基于TPU核心执行向量计算,调用Ascend C向量加法指令提升计算效率;
2. 存储调度设计:输入数据优先加载到L1 Buffer,计算过程中从L1 Buffer读取数据,结果写入L1 Buffer,最终同步到DDR,减少DDR访问频次;
3. 并行策略设计:按张量维度拆分任务,分配到多个TPU核心并行执行,例如2D张量按行拆分,每个核心处理指定行数的数据。
4.2 核函数开发
核函数是Ascend C算子的核心,直接运行在TPU核心,需通过Ascend C专属API实现硬件资源调用与计算逻辑,以下是优化后的加法算子核函数实现:
1. 头文件声明(include/custom_op.h)

2. 核函数实现(src/kernel/add_kernel.cc)

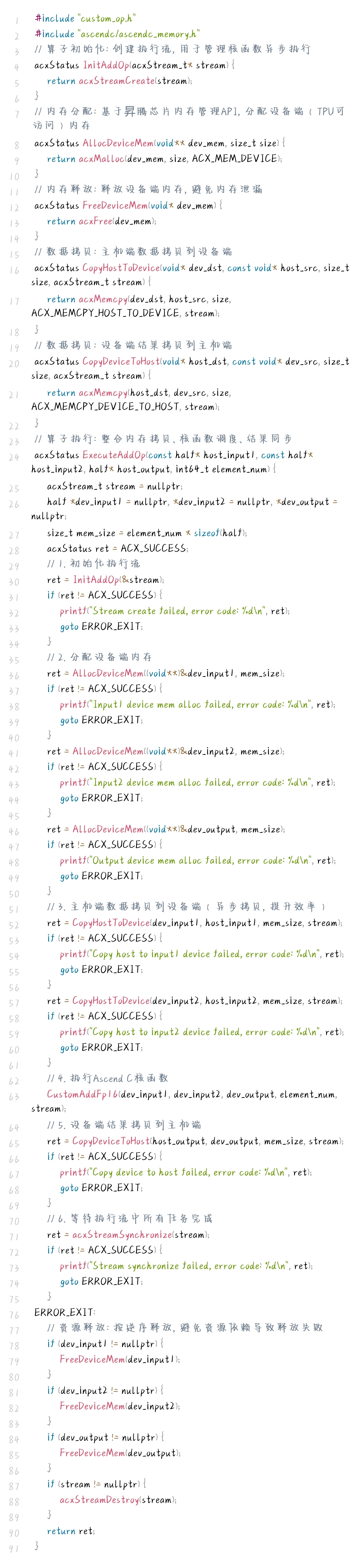
4.3 主机端调度逻辑
主机端负责算子的初始化、内存分配、核函数调度、结果同步等逻辑,需通过CANN Runtime API与Ascend C核函数协同,实现高效调度:
src/host/add_host.cc
4.4 测试入口实现
src/main.cc

4.5 编译配置
CMakeLists.txt

五、编译、调试与性能优化
5.1 编译执行流程
1. 编译操作

2. 编译常见问题排查
- 问题1:Ascend C头文件找不到
解决方案:校验 ASCEND_C_PATH 环境变量是否正确,确保 ascendc_runtime.h 等文件存在于该路径,重新执行 source ~/.bashrc 生效环境变量;
- 问题2:链接时找不到ascendc库
解决方案:确认CANN版本是否支持Ascend C,低版本需升级至6.0.RC1及以上,同时校验 ASCENDC_LIB 路径是否正确;
- 问题3:编译报错“undefined reference to acxL1Load”
解决方案:在CMakeLists中添加 -D__ASCEND_C__ 编译宏,确保Ascend C专属API被正确识别。
3. 执行测试

5.2 调试技巧
1. Ascend Debugger(ADB)调试流程
- 步骤1:启动调试服务
adb start-server
- 步骤2:配置调试参数,在VS Code中添加launch.json配置:

- 步骤3:设置断点(如核函数中计算逻辑、主机端调度逻辑),启动调试,可查看变量值、执行流程,定位计算错误、内存越界等问题。
2. 日志调试
在代码中添加Ascend C日志打印API,输出关键信息辅助调试:

通过 export ASCEND_C_LOG_LEVEL=INFO 开启日志输出,执行程序后查看日志定位问题。
5.3 性能优化策略(补充底层优化技巧)
1. 存储层级优化
- 优化逻辑:最大化数据在L1/L2 Buffer中的复用,减少DDR访问(DDR访问延迟是L1的100倍以上);
- 实操技巧:将连续计算的输入数据批量加载到L1 Buffer,一次性处理多个元素后再回写DDR,例如修改核函数实现批量处理8个元素:

2. 并行调度优化
- 优化逻辑:合理配置线程块与网格大小,充分利用TPU多核算力,避免线程闲置;
- 实操技巧:线程块大小建议设置为256、512等2的幂次方(适配TPU硬件调度特性),网格大小根据元素总数精准计算,避免线程冗余;对于大规模张量,可采用多核分片处理,通过Ascend C多核调度API分配任务。
3. 指令优化
- 优化逻辑:优先使用Ascend C向量指令、矩阵指令,替代标量指令,提升计算并行度;
- 实操技巧:根据数据类型选择对应向量指令(如fp16用 acxVectorAddF16 ,int8用 acxVectorAddS8 ),对于矩阵运算场景,调用 acxMatrixMulF16 等矩阵指令,充分发挥TPU矩阵计算单元性能。
六、算子集成与性能验证(补充集成逻辑与验证标准)
6.1 与深度学习框架集成
Ascend C算子开发完成后,可通过CANN提供的算子注册机制,集成到TensorFlow、PyTorch等框架中使用,核心步骤:
1. 按框架算子规范编写算子封装代码,实现框架与CANN Runtime的接口适配;
2. 通过CANN算子注册工具( op_proto_gen )生成算子原型文件,注册到框架算子库;
3. 在框架中通过自定义算子接口调用Ascend C算子,实现端到端训练/推理。
6.2 性能验证标准与工具
1. 核心验证指标
- 吞吐率:单位时间内处理的元素数/数据量,反映算子处理效率;
- 时延:算子从输入到输出的总耗时,需满足实际业务延迟需求;
- 硬件利用率:通过 npu-smi info -t usages 查看TPU利用率,优化后需达到80%以上,确保硬件算力充分发挥;
- 精度误差:与CPU计算结果对比,fp16精度误差需控制在1e-3以内,满足深度学习精度要求。
2. 性能测试工具
- CANN性能分析工具(Ascend Profiler):精准统计算子执行耗时、内存访问频次、硬件资源利用率,定位性能瓶颈;
- 自定义性能测试脚本:循环执行算子1000次,统计平均耗时与吞吐率,避免单次执行的偶然误差。
七、总结与拓展
本文从底层技术原理到实操落地,完整拆解了Ascend C算子开发全流程,核心聚焦硬件适配、存储优化、并行调度三大关键维度,补充了大量开发细节、问题排查技巧与性能优化策略,可直接作为实操指南落地高性能算子开发。
Ascend C算子开发的核心在于深度理解昇腾芯片硬件架构,通过精细化的资源管理与指令调用,最大化发挥硬件算力。后续进阶方向可围绕:复杂算子开发(如卷积、Transformer核心算子)、异构计算协同(TPU与CPU/GPU协同执行)、低精度优化(int4/int2量化算子)、分布式算子开发(多芯片并行),进一步深挖昇腾芯片性能潜力,助力昇腾AI生态下高性能计算应用落地。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)