[模型适配]-[多模态生成]-基于昇腾910B部署Qwen-Image-2512
vLLM-Omni框架扩展了多模态支持,实现文本、图像、视频和音频的并行生成。环境配置使用vLLM-Ascend镜像和GitHub代码库,成功安装所需依赖。通过启动vLLM模型推理服务和图形界面,测试了图像生成功能。此外,采用TeaCache和Cache-DiT两种加速方法优化性能,对比显示TeaCache将端到端延迟降低至基准的93.3%,Cache-DiT达到96.6%。该框架显著提升了多模态
本次部署模型Qwen-Image-2512。
模型地址:
1. vllm-Omni
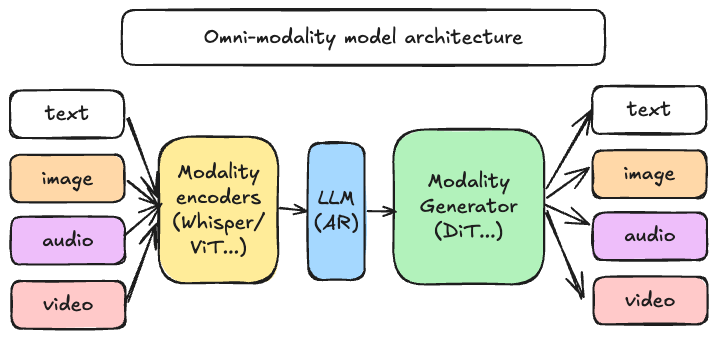
vLLM 最初是为了支持文本自动回归生成任务的大型语言模型而设计的。vLLM-Omni 是一个框架,它扩展了对全模态模型推理和服务的支持
- 全模态:文本、图像、视频和音频数据处理
- 非自回归架构:将 vLLM 的 AR 支持扩展到 Diffusion Transformers (DiT) 和其他并行生成模型
- 异构输出:从传统的文本生成到多模态输出
2.环境准备
vllm环境准备
使用vllm-ascend镜像,本例使用
quay.io/ascend/vllm-ascend:v0.12.0rc1-openeuler
镜像下载地址:Quay
vllm-omni环境准备
github上下载vllm-omni代码仓库
git clone https://github.com/vllm-project/vllm-omni.git
cd vllm-omni
pip install -e -v .
。。。
Successfully installed accelerate-1.12.0 aiofiles-24.1.0 antlr4-python3-runtime-4.9.3 brotli-1.2.0 cache-dit-1.1.8 diffusers-0.36.0 ffmpy-1.0.0 gradio-5.50.0 gradio-client-1.14.0 groovy-0.1.2 importlib_metadata-8.7.1 omegaconf-2.3.0 orjson-3.11.5 pillow-11.3.0 pydantic-2.12.3 pydantic-core-2.41.4 pydub-0.25.1 resampy-0.4.3 ruff-0.14.10 safehttpx-0.1.7 semantic-version-2.10.0 tomlkit-0.13.3 vllm-omni-0.12.0rc1 zipp-3.23.0安装成功版本查看
vllm 0.12.0+empty /vllm-workspace/vllm
vllm_ascend 0.12.0rc1 /vllm-workspace/vllm-ascend
vllm-omni 0.12.0rc1模型下载
3.服务启动
2.1 启动vllm 模型推理服务
export ASCEND_RT_VISIBLE_DEVICES=0,1
export VLLM_WORKER_MULTIPROC_METHOD=spawn
vllm serve /path/to/models/Qwen-Image/ --omni --port 10027
...
Loading safetensors checkpoint shards: 100% Completed | 9/9 [01:01<00:00, 7.35s/it]
Loading safetensors checkpoint shards: 100% Completed | 9/9 [01:01<00:00, 6.85s/it]
[Stage-0] INFO 12-29 15:15:08 [diffusers_loader.py:214] Loading weights took 61.97 seconds
[Stage-0] INFO 12-29 15:15:09 [npu_worker.py:79] Model loading took 53.7445 GiB and 91.143213 seconds
[Stage-0] INFO 12-29 15:15:09 [npu_worker.py:84] Worker 0: Model loaded successfully.
[Stage-0] INFO 12-29 15:15:09 [npu_worker.py:118] Worker 0: Scheduler loop started.
[Stage-0] INFO 12-29 15:15:09 [gpu_worker.py:229] Worker 0 ready to receive requests via shared memory [Stage-0] INFO 12-29 15:15:09 [scheduler.py:46] SyncScheduler initialized result MessageQueue [Stage-0] INFO 12-29 15:15:09 [async_omni_diffusion.py:83]
。。。
INFO: Started server process [1118] (APIServer pid=1118)
INFO: Waiting for application startup. (APIServer pid=1118)
INFO: Application startup complete.服务测试:
测试脚本 openai_chat_t2i.py
python openai_chat_t2i.py \
--prompt "A beautiful landscape painting" \
--output output.png \
--server http://127.0.0.1:10027 \
--seed 21 \
--height 224--width 224
2.2 启动图形界面服务
python gradio_demo.py --server http://127.0.0.1:10027 --port 10029
使用浏览器打开界面:
http://127.0.0.1:10029
4.加速方法
3.1 TeaCache
vllm serve /opt/models/Qwen-Image/ --omni --port 10027 \
--cache-backend tea_cache \
--cache-config '{"rel_l1_thresh": 0.2}'3.2 Cache-DiT
vllm serve /opt/models/Qwen-Image/ --omni --port 10027 \
--cache-backend cache_dit \
--cache-config '{"Fn_compute_blocks": 1, "Bn_compute_blocks": 0, "max_warmup_steps": 4, "residual_diff_threshold": 0.12}'3.3 效果对比
prompt='生成一个ultraman', ref_images=0, params={'height': 384, 'width': 512, 'num_inference_steps': 10, 'true_cfg_scale': 4, 'num_outputs_per_prompt': 1
|
部署方式 |
e2e |
时延倍率 |
|
baseline |
8995 |
1 |
|
TeaCache |
8394 |
0.933 |
|
Cache-Dit |
8688 |
0.966 |

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)