vLLM框架入门基础教程(保姆级详解),vLLM从入门到精通,收藏这一篇就够了!
作为vLLM源码的开发者、框架的使用者,刚接触vLLM框架时会有这样的问题“如何快速地了解vLLM全貌?”。推荐的一个学习步骤:先大致了解整体运行流程,接着理解关键模块逻辑,然后学习关键特性。同时,逐步理解源码。
作为vLLM源码的开发者、框架的使用者,刚接触vLLM框架时会有这样的问题“如何快速地了解vLLM全貌?”。推荐的一个学习步骤:
先大致了解整体运行流程,接着理解关键模块逻辑,然后学习关键特性。同时,逐步理解源码。
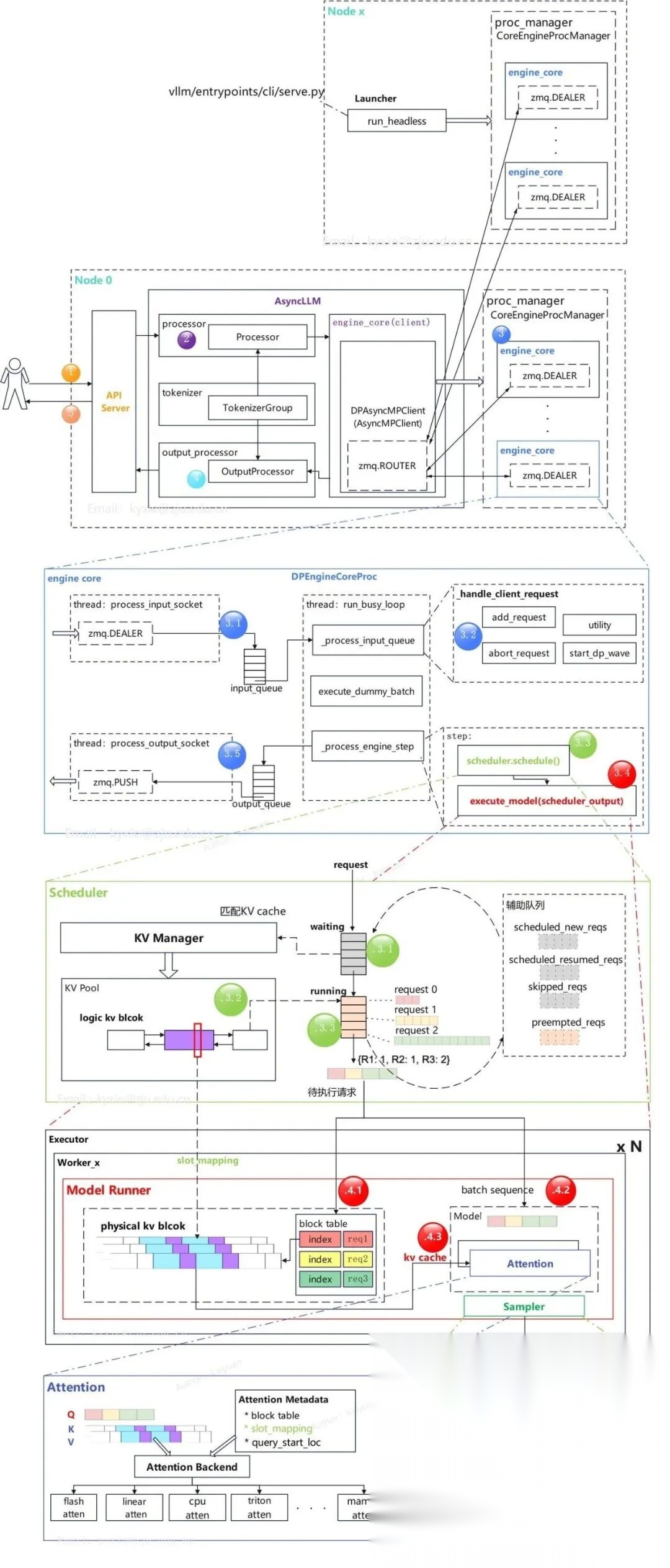
本文作为这个过程的一个前置引导,主要分析vLLM框架的运行流程。由于vLLM框架的迭代速度非常之快,如果直接解读源码,可能过几个月后这些逻辑就发生了较大的变化,所以文中以概念为主,代码逻辑为辅。主要参考vLLM 0.10.0,本人梳理了一版整体架构图,如下所示,细节后面逐步展开。
1 为什么需要一个LLM推理框架?
在有PyTorch/TensorFlow这些既能训练又能推理的深度学习框架后,为什么还需要构建一个推理框架?这是在学习vLLM前需要思考的一个关键问题。
以PyTorch框架为例,有了训练好的模型后,切换model的模式即可运行推理:
# 关键步骤:
# 1. 设置为推理模式
model.eval()
# 2. 进行推理(不计算梯度)
with torch.no_grad():
output = model(input_data)
对于自回归的大语言模型(LLM)多个步骤:增加前、后token的转换处理,token的流处理:
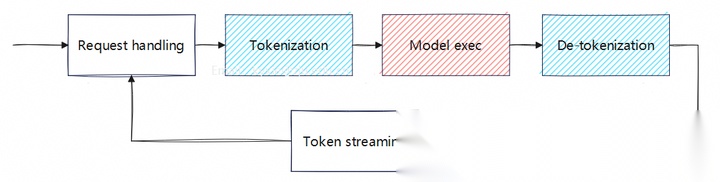
但这种方式会面临如下问题:
- 如何处理来自不同用户的请求?
- 资源利用率如何维持较高水平?
- 如何避免超显存(OOM)?
对于问题1一般的解决方式是部署推理服务,通过API server来响应用户的并发请求。如Tensorflow的推理部署服务、NVIDIA的Triton。
问题2、问题3主要跟负载的动态变化相关:
- 单位时间内推理服务处理的请求数量会发生动态变化,这是推理服务所共有的问题。
- 单个请求的资源需求会发生变化。这是自回归模型所特有的。 随着序列的增长,计算量、KV cache显存量均会增长。
若按照峰值需求来配置资源,会导致资源整体利用率低;若资源给得太少,会使得推理服务质量下降,或者触发OOM问题。所以针对LLM的特点,需要有一个专门推理引擎完成高效的请求调度与资源分配。
2 vLLM的基本要素
为了解决通用深度学习框架中存在的不足,vLLM设计了几个关键模块:
- 调度器(Scheduler),用于解决多请求之间的调度协同问题;
- 显存管理(KV cache manager),为请求分配KV cache内存资源。
- 执行器(Model runner),完成模型的计算。
上述3个模块放置在引擎核(Engine core)中。有了关键模块后,再采用API服务的方式,得到如下所示的改进方案:
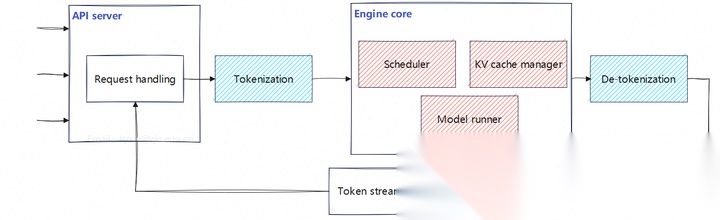
在这个基础上为了提升算子的下发速度,框架要做进一步优化。把在CPU侧执行的一些步骤放入独立的进程中,如请求的前置处理,token转换等,进程之间采用异步流程。这么做能够降低CPU运算对GPU运算的阻塞影响。
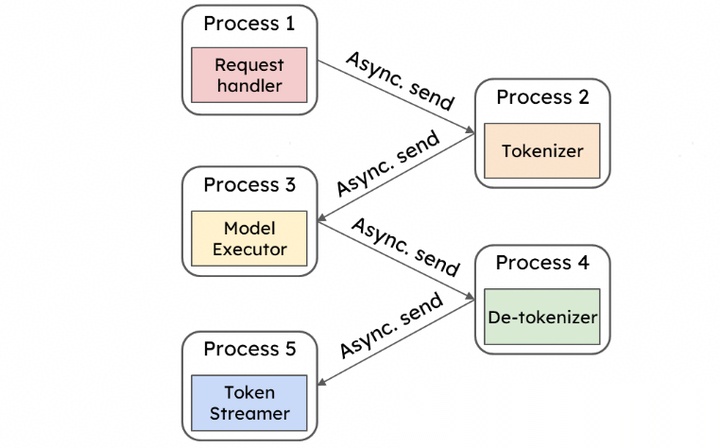
同时为了适配分布式并行推理,在engine core里面抽出了一个engine core client模块。该模块负责给不同的engine core分配请求。在模块管理上面,除了engine core,其它模块基本放入AsyncLLM中。这也是为了防止CPU成为运算的瓶颈。
vLLM的基本流程执行框图如下,其中Node 0为主节点,上面运行了API Server、AsyncLLM、engine core;从节点(Node1~N),仅运行engine core。
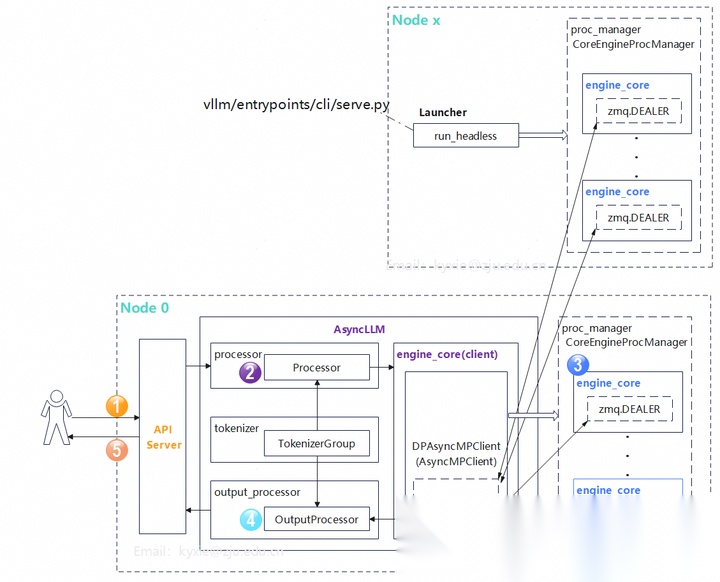
按照OpenAI的格式,给vLLM发送一个在线服务请求:

收到请求后,其基本的处理步骤:
- API server响应请求,对请求的信息进行初步处理;
- 进行请求的前置处理,包括对prompt进行token转换获得token id;
- engine core client将请求发送给合适engine core,engine core完成自回归运算;
- 进行后置处理,包括token转文本的过程;
- 返回请求结果给用户。
3 关键模块运行逻辑
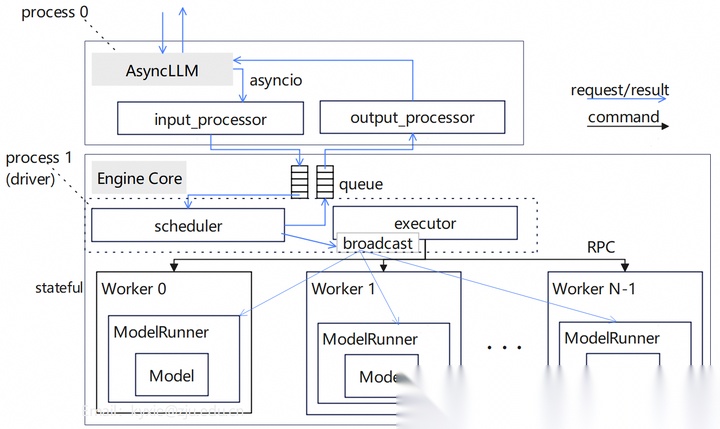
3.1 Engine core模块
单engine core的基本架构图如下所示。AsyncLLM与engine core运行在不同的进程中,两者通过队列(queue)交互。engine core的任务由executor下发,多个worker共同完成LLM的数据生成。一般情况下,每个worker拥有一张GPU卡,多worker可实现TP/SP/EP等并行策略。
Engine core里有三个协同的线程:
- 输入处理线程(process input):主要负责接收engine core client传递过来的数据,并将请求放入队列;
- 输出处理线程(process output):将数据通过zmq通信返回给engine core client;
- 处理循环线程(run busy loop):持续地从输入队列拿取请求,按照vLLM config里的参数构造数据,并执行引擎的step操作。step操作包括请求调度和模型运算。
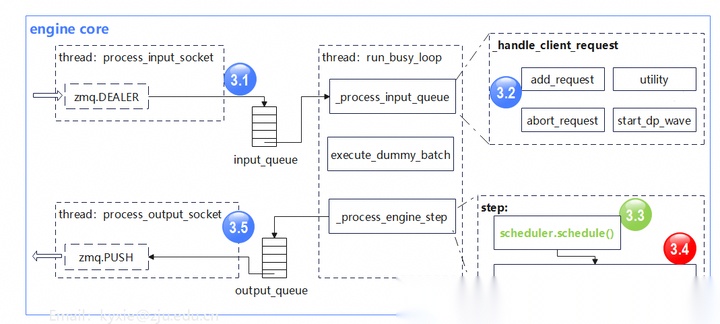
engine core计算流
3.2 Scheduler模块
scheduler模块主要职责是:根据系统资源和当前在执行请求的情况,组织每次推理需要计算的数据。
- 分析scheduler的执行逻辑前,先回顾下LLM推理过程的一般特点:
- 推理的阶段不一样,计算、访存的资源消耗量不同。prefill属于计算密集、decode属于访存密集。
不同请求的decode结束时机不同,生成的序列长短也不一样。
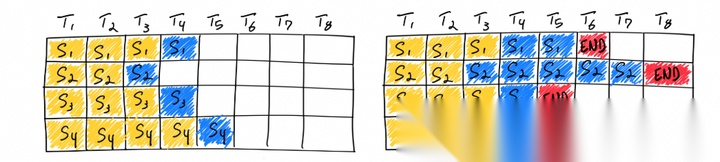
批处理示意:黄色表示prefill、蓝色表示decode生成
结合LLM的推理特点,scheduler目前应用了两个关键技术:
1.持续批处理(Continus-batching):持续地往GPU中送入请求数据,而不是离散的进行数据推理。一个请求结束立刻下发新的请求。
continuous batching
2.分块预填充(Chunked Prefill):将大的prefill分块成更小的块(切分序列)执行,也可以将它们与decode阶段的请求一起混合执行。
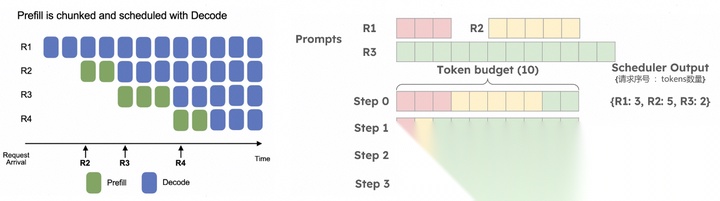
除此之外,scheduler还要根据请求优先级调整执行顺序,高优先级的请求可以打断低优先级的请求。
scheduler整体逻辑:按照可用资源的数量和优先级构建调度输出。scheduler里面有两个主要的队列waiting和running,以及一些辅助队列。运行时,请求在不同的队列之间轮转。scheduler通过KV manager为请求配备KV cache。scheduler的优先级默认是FCFS(先到先服务),也支持用户自定义。
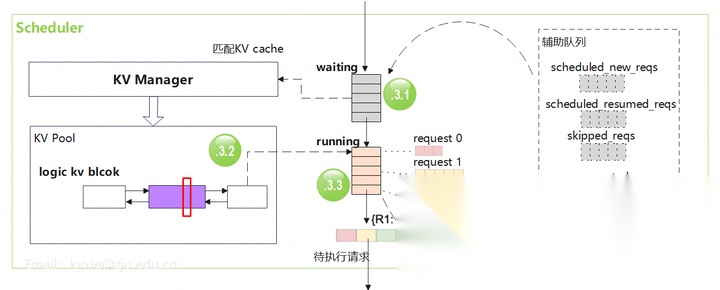
scheduler处理的大致步骤:
- 请求抵达后,先进入waiting队列;
- 找KV manager申请KV cache块;
- 具备下发条件的请求转入running队列,组batch下发执行(图示中有3个请求);资源不足的请求会转回waiting队列。
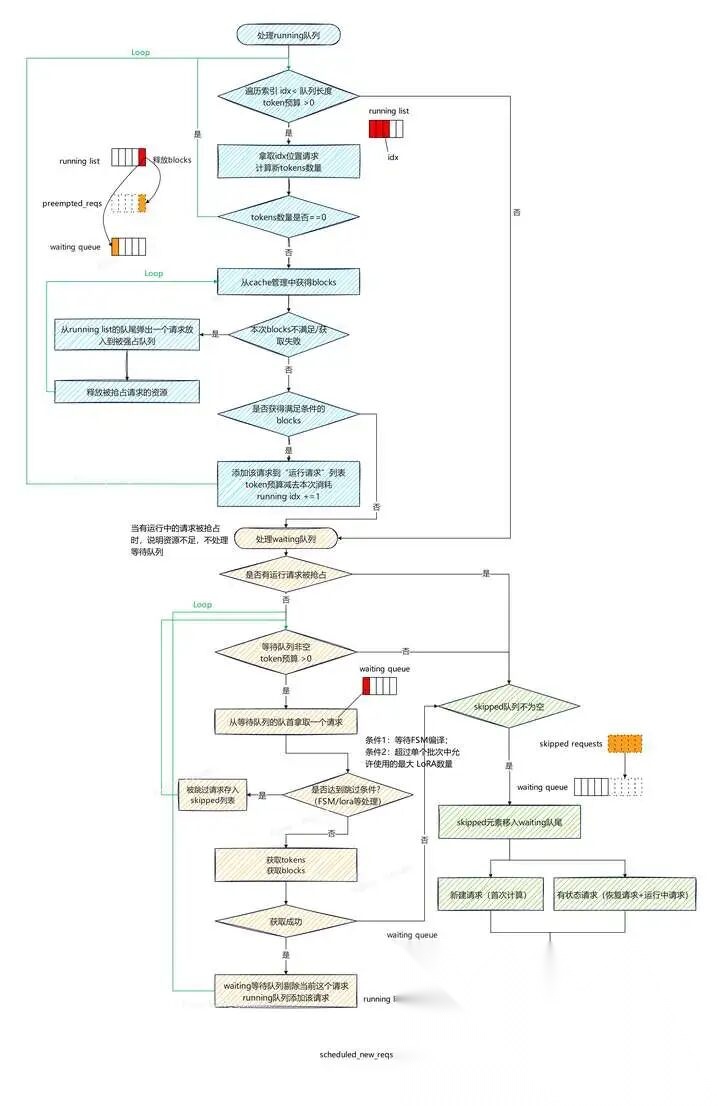
更细节的执行步骤参考[5]:
3.3 KV Manager模块
KV值的复用能够降低 Attention中的冗余计算,目前KV cache已成为了Attention推理计算的标准配置。框架中需要完成对多个不同请求的KV cache管理。
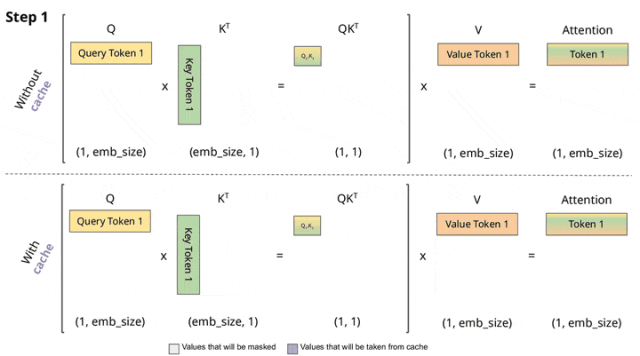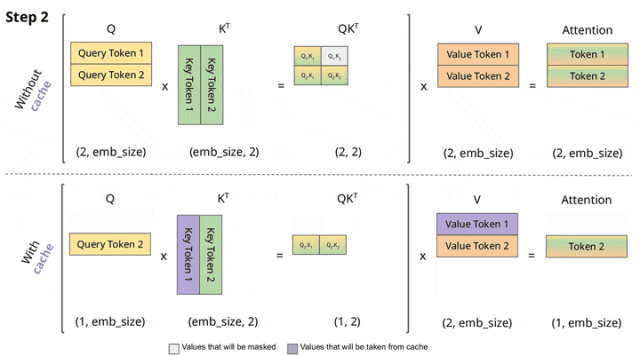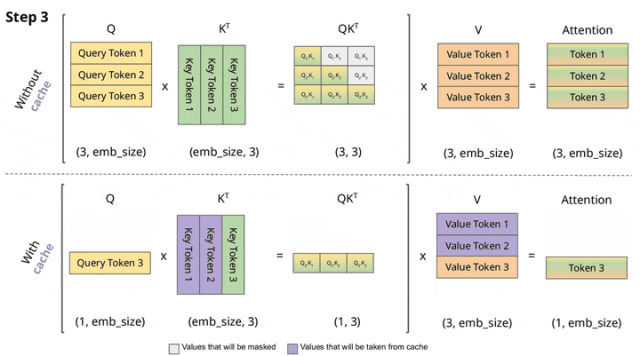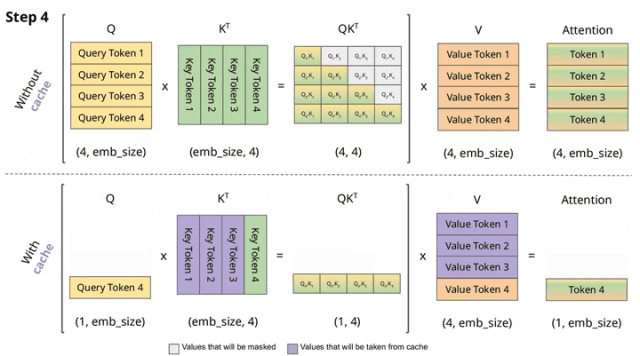
vLLM中的KV cache管理逻辑基于Paged attention原理,目前的版本还融合了前缀树特点[6]。
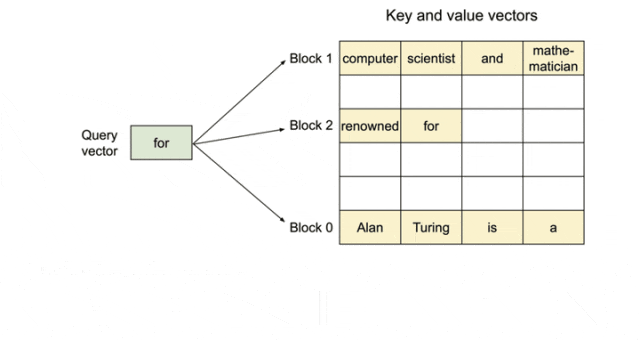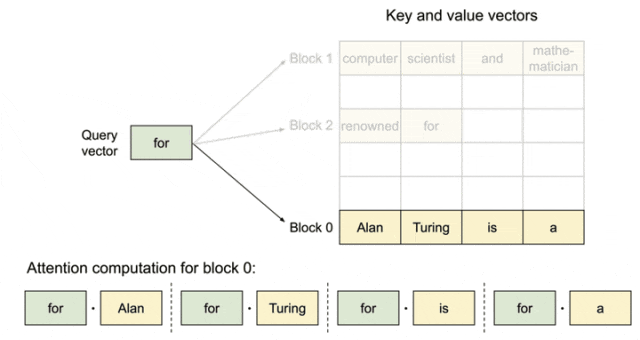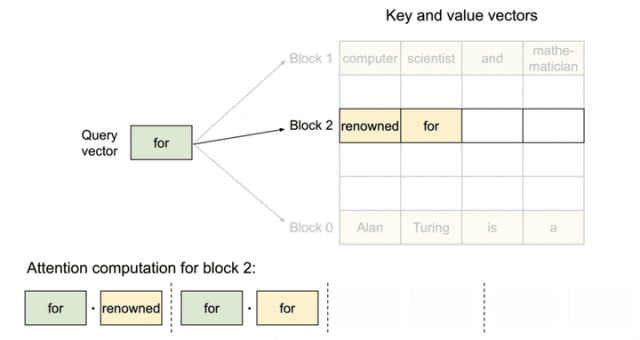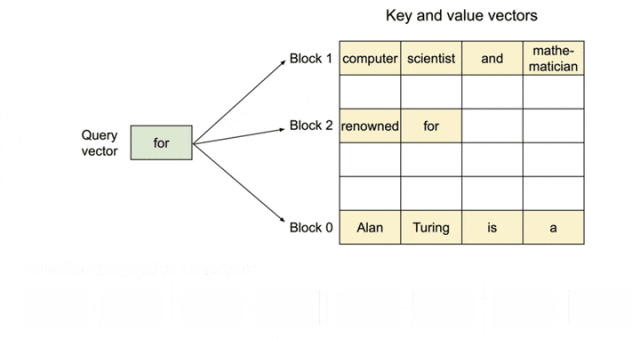
KV cache管理的整体架构示意图如下所示,分为了逻辑层和物理层。KV Manager负责逻辑层、Model Runner处理物理层;Scheduler(调度器)作为信息传递的桥梁,衔接了逻辑层与物理层。cache的管理元素包括:池(pool)表(table)、层(layer)、块(block)和槽(slot)。
- slot:为最小管理单元,每个token占一个slot;
- block:为请求分配的基本单位,一个block包含多个slot;
- pool:为逻辑层block的管理合集,通过链表将block数据组织起来;
- table:管理请求与数据的映射表,一个table可包含多个请求的信息。位于物理层;
- layer:一个整体的tensor,拆分成多个blocks使用。对应attention的一个层,所有请求共用;
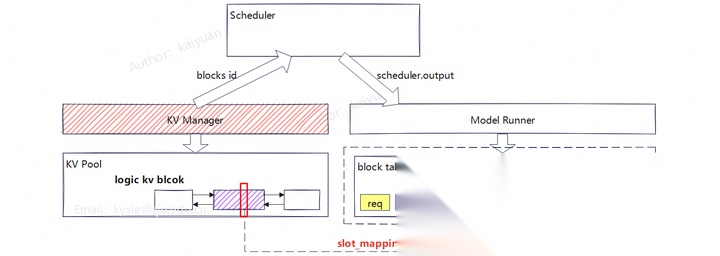
模块之间运行的关键步骤:
- Scheduler分配资源给请求,通过KV Manager申请逻辑blocks;
- KV Manager把Pool中空闲的blocks选中后给到对应请求;
- 分配好逻辑blocks后Scheduler构建scheduler.output传递给ModelRunner;
- ModelRunner为每条请求创建block table,并生成slot_mapping;
- 计算时把slot_mapping传入attention,就能够从物理KV blocks上面找到所需的数据。
逻辑KV blocks是一个双向链表,采用LRU策略淘汰旧数据[7]。

blocks数据结构示意
3.4 Model Runner
模型执行器(model runner)主要负责计算调度器发送过来的批请求,并返回执行结果。
从上面engine core的架构可知,executor可以有多个worker模块,每个worker都会有自己的model runner。model runner的逻辑主要是模型运算、以及物理层的kv cache分配与管理。
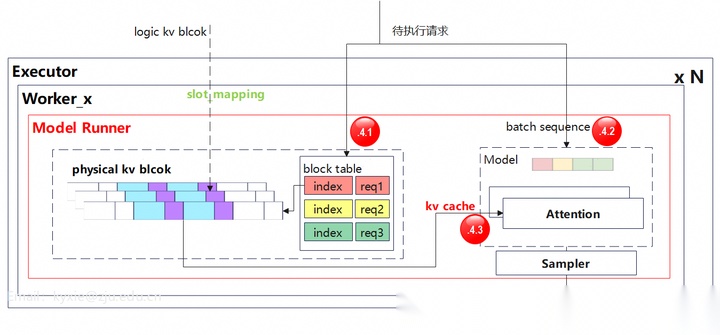
执行的基本步骤:
- 根据映射表(block table)信息为每个待执行请求分配kv blocks;
- 将请求组成序列batch,并让模型处理该batch数据。
- 在Attention层运算阶段,每层拿取自己对应的kv cache数据,完成MHA/GQA/MLA运算。
3.5 Attention模块
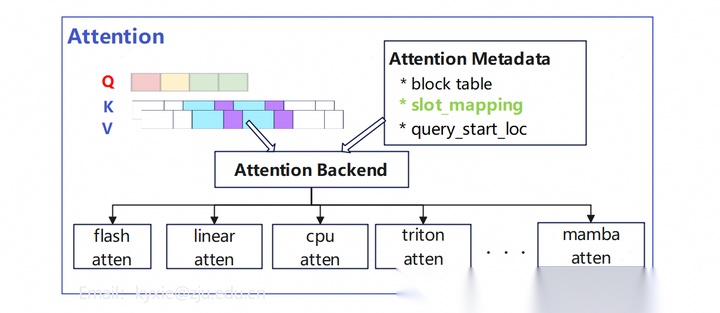
Attetnion模块负责承载注意力计算的算子,其关键要素:
-
QKV数据:Q值是展平后的tokens序列,KV则是整个KV Cache Tensor。
-
Metadata:注意力运算的元数据,包括KV相关的block table、slot_mapping,以及Q值的起始位置信息(query_start_loc),用于区分不同请求;
-
Backend:通过定义不同后端(backend)来支持不同类型的Attention算子,以及不同的硬件。
4 数据处理流程
接下来通过一个请求处理的数据流的例子,了解从请求、kv cache、attention算子、到采样的数据传递过程。
给vLLM发送请求,提示词prompts包含两条语句,即有两个子请求。
方式一:在线服务(online serving):

方式二:离线推理(offline infer):

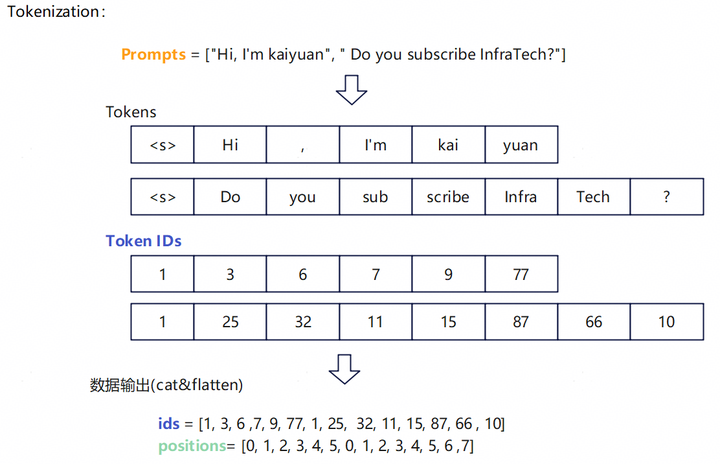
Step1:文字转token ids(Tokenization)。 多个请求会拼接成一个数据(组batch),用位置(positions)记录每个请求对应的ids。
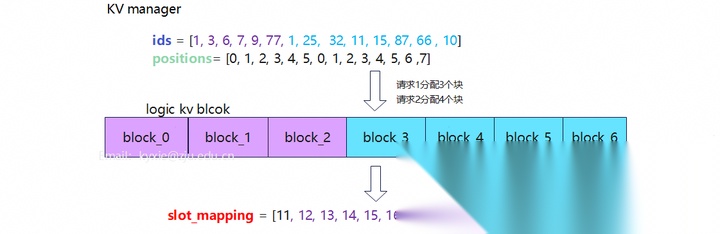
Step2:KV manager分配逻辑块、计算slot。
Step3:Model runner分配KV cache
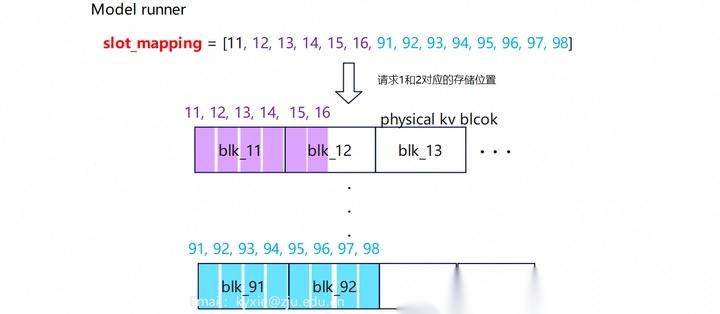
Step4:Decoding生成新token,并更新ids、positions、slot_mapping数据。该过程需要迭代多次。
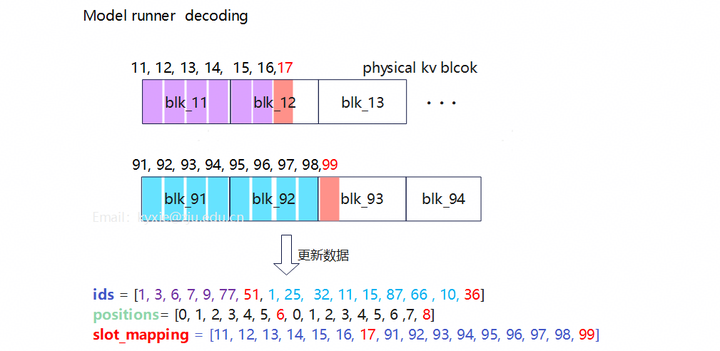
示例中KV manager的逻辑块是连续的,而物理块在model runner中不连续。
从模型输出的logits到token id,要经过采样(sampling)计算。
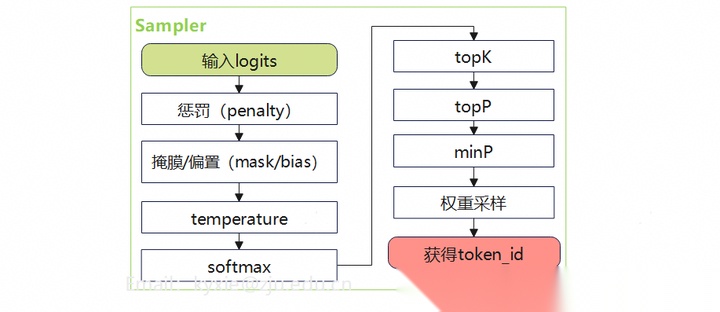
Step5:将token id还原成词(De-Tokenization)。

学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)