MindSpeed-RL GRPO 昇腾全共卡方案实践总结
本文分享了基于昇腾Atlas 800T A2服务器,使用MindSpeed-RL框架对Qwen2.5-7B/32B模型进行GRPO训练的实践经验。重点介绍了自定义数据集和奖励规则的适配方法:通过修改map_keys和dataset_additional_keys字段实现数据格式转换,并详细说明了如何根据任务需求设计自定义reward规则。同时提供了数据集预处理模板配置和奖励函数映射的具体实现方案,
作者:昇腾实战派
知识地图链接: 强化学习知识地图
一、背景
本文记录了基于昇腾Atlas 800T A2服务器,使用自定义数据集和算法规则,使用MindSpeed-RL框架对Qwen2.5-7B/32B模型进行全共卡场景GRPO训练实践,总结了在功能适配、精度对齐和性能调优中的实践经验,为类似场景提供参考。
二、强化学习算法适配
1. GRPO算法适配关键点分析
在GRPO强化学习实践中,我们遇到了自定义reward规则和数据集格式适配的需求。下面介绍适配非默认格式数据集和自定义reward规则的思路和方法。
1.1 数据集适配
input: ./dataset/
tokenizer_name_or_path: ./model_from_hf/qwen25-7b
output_prefix: ./dataset/data
handler_name: R1AlpacaStyleInstructionHandler
tokenizer_type: HuggingFaceTokenizer
workers: 8
log_interval: 1000
prompt_type: empty
map_keys: {"prompt":"problem", "query":"", "response": "answer", "system":""}
dataset_additional_keys: ["labels",]
GRPO Qwen-2.5-7B默认的数据集预处理配置如上所示。在实际应用中,需要根据具体的数据集格式进行适当修改。
- map_keys:从
map_keys中可以看到,默认把数据集的problem字段作为模型的输入prompt字段,把answer字段映射为数据集给出的推理输出response字段。在训练开始时,response字段又会被映射为adaset_additional_keys中的label字段。 - dataset_additional_keys:若数据集中有其他的字段在训练时也需要用到,可以添加在
adaset_additional_keys中,在训练时可以直接通过adaset_additional_keys中的字段名获取对应的数据,如data_source、task等。 - prompt_type:配置yaml中的
prompt_type根据需求进行修改,prompt_type的值代template模板的名字,名字不同处理prompt的使用的模板不同。template模板名对应的模板内容可以参考MindSpeed-RL/configs/model/templates.json,其中name字段对应此处的promt_type,根据用到的模板进行选择。
map_keys和adaset_additional_keys处理逻辑如图所示:

0724024159.png?origin_url=.%2Fe96a7037-ba5f-4829-8983-791fdbd83d05.png&pos_id=img-GIqQufp7-1772174946733)
具体实现在mindspeed_rl/datasets/data_handler.py的R1AlpacaStyleInstructionHandler._tokenize_prompt函数中,代码片段如下:
for add_key in self.args.dataset_additional_keys:
if add_key == "labels":
model_inputs["labels"] = self._unwrapped_tokenizer.encode(
example["response"][-1]["content"], padding=False, add_special_tokens=False)
else:
model_inputs[add_key] = self._unwrapped_tokenizer.encode(
example[add_key], padding=False, add_special_tokens=False)
MindSpeed-RL/configs/model/templates.json的"qwen_r1"模板部分如下:
[
{
"name": "qwen_r1",
"format_user": {
"slots": [
"<|im_start|>user\nA conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think><answer> answer here </answer>. Put your final answer within \\boxed{}.\n{{content}}<|im_end|>\n<|im_start|>assistant\n"
]
},
"format_system": {
"slots": [
"<|im_start|>system\n{{content}}<|im_end|>\n"
]
},
"format_observation": {
"slots": [
"<|im_start|>tool\n{{content}}<|im_end|>\n<|im_start|>assistant\n"
]
},
"format_separator": {
"slots": [
"\n"
]
},
"default_system": "You are a helpful assistant.",
"stop_words": [
"<|im_end|>"
],
"replace_eos": true
},
]
1.2 reward规则适配
MindSpeed-RL中只提供了常见的reward规则,可以根据自己的数据集和使用场景,设计自己的自定义规则。MindSpeed-RL规则名和规则函数映射的代码如下(MindSpeed-RL/tree/master/mindspeed_rl/models/rule_verifier.py):
def verifier(responses, data, config, **kwargs):
"""
User-defined verifier scoring process.
Parameters:
----------
responses(List[`str`]):
Actor rollout answers.
labels(List[`str`]):
Ground Truth.
infos(List[`str`], *optional*):
Additional usable information loaded from the dataset.
Return:
scores(List[`float`]): Final scores.
"""
rule_verifier_function = {
"acc": accuracy_reward,
"format": format_reward,
"step": reasoning_steps_reward,
"strict_format": strict_format_reward,
"base_acc": base_model_accuracy_reward,
}
在训练配置的yaml中(如configs/grpo_qwen25_32b_A2.yaml),如果在verifier_function中指定了规则名,则会调用对应的函数计算规则,如下。
verifier_function: ["base_acc"]
上面在verifier_function指定了"base_acc"规则, 在计算规则得分的时候,就会调用对应的base_model_accuracy_reward。计算规则的函数入参是一个的responses list,函数会对list中的所有response都计算得分,并返回一个score list。自定义的规则函数入参可能是一条response而不是一个response list,则需要在适配时使用for循环调用自定义规则函数,并将结果组成一个score list作为返回值。
2.2 功能需求分析与适配
本文基于在GPU上使用verl进行Qwen2.5-7B/32B GRPO训练,将在GPU上进行的训练迁移至NPU上。
本文在verl的基础上进行代码改动,适配了自己的规则和功能等,例如ref model更新和保存的功能。我们通过三个角度分析将GPU任务迁移至NPU上使用MindSpeed-RL需要适配的需求:
- 自定义数据集和规则
- 使用的verl中有的但MindSpeed-RL尚未支持的功能
- 对verl进行的其他修改
2.3 功能适配
由于数据集和自定义规则适配的需求较为常见,本文这里仅对数据集适配和自定义规则的适配做重点介绍,其他功能的适配仅做简单介绍。
2.3.1 自定义数据集适配
本文自定义的数据集中有task数据项,即每条数据都有一个对应task。根据数据的task的不同,使用不同的规则进行打分。
因为计算规则得分的时候,需要使用到task数据项,所以数据集在做预处理时需要保留数据集里的task数据项。此外,本文使用的的数据集本身已经经过template处理,因此不需要再使用template,即使用的template为empty进行处理即可。对数据集预处理的配置文件修改如下:
input: ./dataset/
tokenizer_name_or_path: ./model_from_hf/qwen25-7b
output_prefix: ./dataset/data
handler_name: R1AlpacaStyleInstructionHandler
tokenizer_type: HuggingFaceTokenizer
workers: 8
log_interval: 1000
prompt_type: empty
map_keys: {"prompt":"problem", "query":"", "response": "answer", "system":""}
dataset_additional_keys: ["labels", "task"]
2.3.2 自定义规则适配
自定义的数据集中有task数据项,通过task的值是选择对应的规则计算reward得分。这里需要注意,如果task和规则不匹配,在计算的分会返回0,如果task规则匹配,该条数据的规则得分也可能为0。这两种场景返回均为0,但含义不同,如果task和规则不匹配,返回的0也会被append到该项规则计算出的reward得分列表当中,最后也会参与该规则的所有得分的平均reward的计算,task和规则不匹配得到的0分会拉低这组batch的数据在该规则上的整体reward。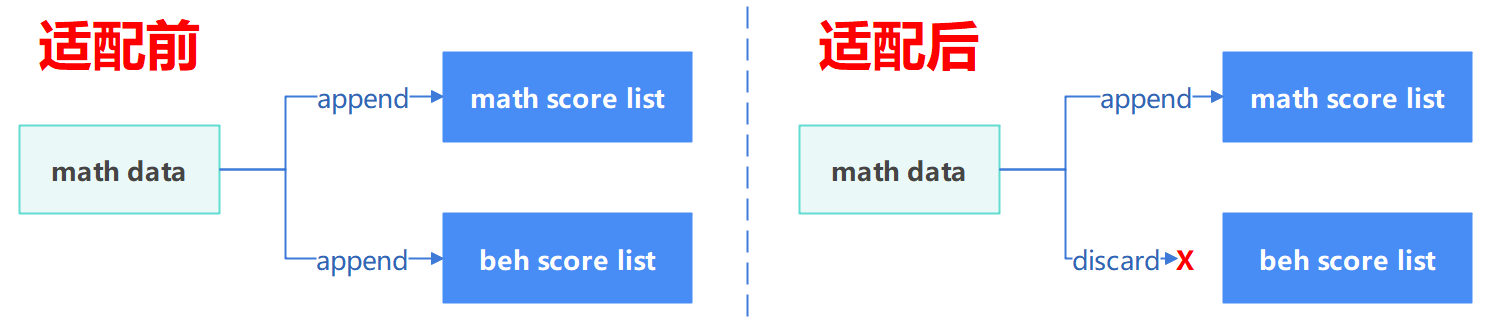
以"math"任务为例,数据集是shuffle过的,随着"math"类型数据在batch里的占比波动,"math"得分也会因为取到的数据有波动,极端情况下,假设该组batch取到的数据恰好没有"math"任务类型的数据,会使得该组数据的"math"得分为0,最终导致reward曲线不符合预期。
因此,在把规则函数返回的得分append到该项规则计算出的reward得分列表之前,需要校验数据的task是否和规则匹配,只有匹配的情况下才会把得分加到列表里。
2.3.3 use_remove_padding
use_remove_padding 特性可以在GRPO的inference阶段和training阶段去掉input_ids里的pad_ids,配合megatron的动态长度特性megatron_config.variable-sequence-length,能够省掉pad_ids带来的冗余计算,在句子长度差异很大的场景下,能够大幅减少inference阶段和training阶段的时间,从而减少单步迭代时间,提升性能。MindSpeed-RL上 use_remove_padding 的核心代码如下:
# Total packed length after padding
pack_length = int(seqlens_in_batch_padded.sum().item())
input_ids_packed = torch.zeros(pack_length, dtype=input_ids.dtype, device=input_ids.device)
# Copy valid tokens sequentially
for i in range(batch_size):
start = cu_seqlens_padded[i].item()
length = seqlens_in_batch[i].item()
input_ids_packed[start:start + length] = input_ids[i, :length]
由于本文的实验中rollout阶段产生的response的长度变化范围较大,最短的只有十几个tokens,最长的有4096个,因此pad_ids的占比较高。实测在GPU上使用verl开启了use_remove_padding特性后,性能优化很大,所以要求我们适配该特性。
三、 精度对齐
1. 精度验收指标
- reward曲线:走势近似,曲线绝对误差<=4% ,数据集全量数据长稳训练(24小时或500个step,取最小时间对应的情况),reward收敛误差范围<=5%。
- 开源数据集下游任务评测:评测指标误差<=2%,采样32次(avg32)取平均分。参考数据集范围:数学:Math 500,GPQA。代码:LiveCodeBench。
2. 精度对齐三板斧
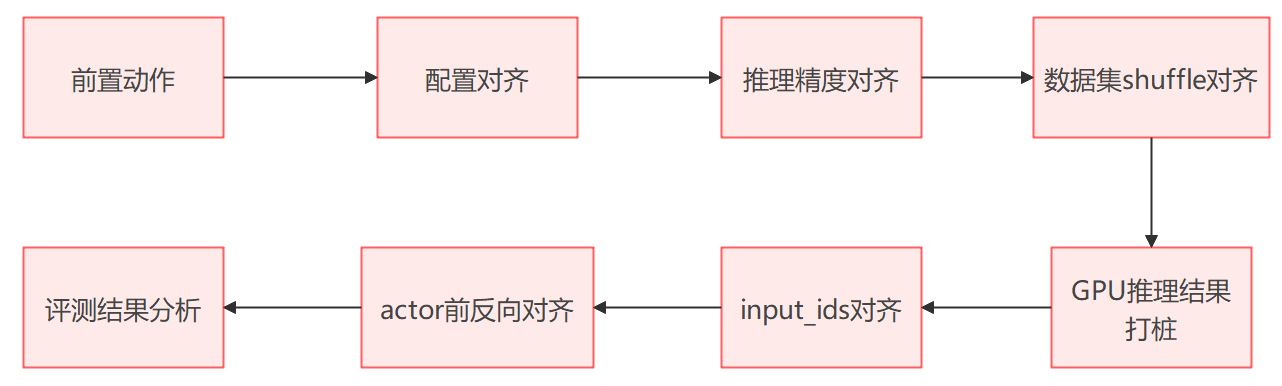
2.1 精度对齐前置动作
- 基线获取: GPU长跑基线获取。
- 打桩数据获取: GPU rollout dump数据,对齐prompt和rollout才可以完全对齐inputids,进而可以对比网络前反向。
- 下游任务评分打通: 打通MindSpeed-RL权重转换成GPU做评估需要的权重格式,如果使用vllm进行评估,需要转换成hf格式。正式评估前需要测试权重转换和评估得分正常。
- 准备GPU训练环境: 有些精度对齐的步骤需要在GPU上进行调试,比如打印中间变量和dump网络前反向。
2.2 精度问题定位方法论
2.2.1 配置对齐
配置对齐时,我们整理了verl和mindspeed-rl中的配置在表格中并逐一比对,经过踩坑发现了基础容易配错的地方:
| MindSpeed-RL | Verl | 差异 |
|---|---|---|
| actor_config.lr_warmup_fraction | actor_rollout_ref.actor.optim.lr_warmup_steps_ratio | 名字不同,都代表lr warmup阶段step比例 |
| rl_config.mini_batch_size | actor_rollout_ref.actor.ppo_mini_batch_size | RL的mini_batch_size是乘过n_sample的 |
| megatron_training.seq_len | promt_lenght + response_length | |
| megatron_training.train_iters | megatron_training.epoch | 目前需根据实际的数据集大小配置,精度对齐阶段可参考GPU日志配置,否则会影响数据集shuffle的随机性 |
| megatron_training.rms_norm_eps | 模型的config.json | Qwen2.5-32B是1e-6,Qwen2.5-7B是1e-7, Qwen2.5-32B/7B-instruct都是1e-7,具体需和GPU日志对齐 |
| megatron_training.tokenizer | megatron_training.tokenizer | 需确认tokenizer内容是否一致,如eos_id和pad_id |
2.2.2 推理精度对齐
推理精度对齐的标准是数据集评分NPU和GPU评分结果绝对误差在1%以内。
如果在GPU上使用vllm进行评测的方案,可以直接将方案迁至NPU上,使用vllm-ascend进行数据集评测。若评分结果误差在1%以内,则可以认为NPU上MindSpeed-RL的推理部分精度对齐。
如果没有评测方案,可以使用vllm在开源数据集上使用NPU和GPU进行评测,如使用opencompass评测,比较GPU和NPU的评分误差是否在1%以内。
2.2.3 数据集shuffle对齐
在4月底版本的MindSpeed-RL中,数据集shuffle的实现方式和verl中的实现是不一致的。MindSpeed-RL是使用的megatron的方式打乱数据集:对取数据的index列表进行shuffle,打乱取数据的index的顺序。verl是通过结合使用Randomsampler和torch.Generator,实现数据集的shuffle。
经过改写MindSpeed-RL的数据集shuffle方式后,MindSpeed-RL的数据shuffle方式和verl对齐。
将MindSpeed-RL的随机种子actor_config.seed设置成和verl的相同(verl中默认是0)即可对齐数据集的shuffle顺序。在训练过程中也可以通过观察MindSpeed-RL打桩的prompts和verl相同,或者通过比较日志中两边的prompt_length max/min/mean严格对齐,来验证数据集shuffle对齐。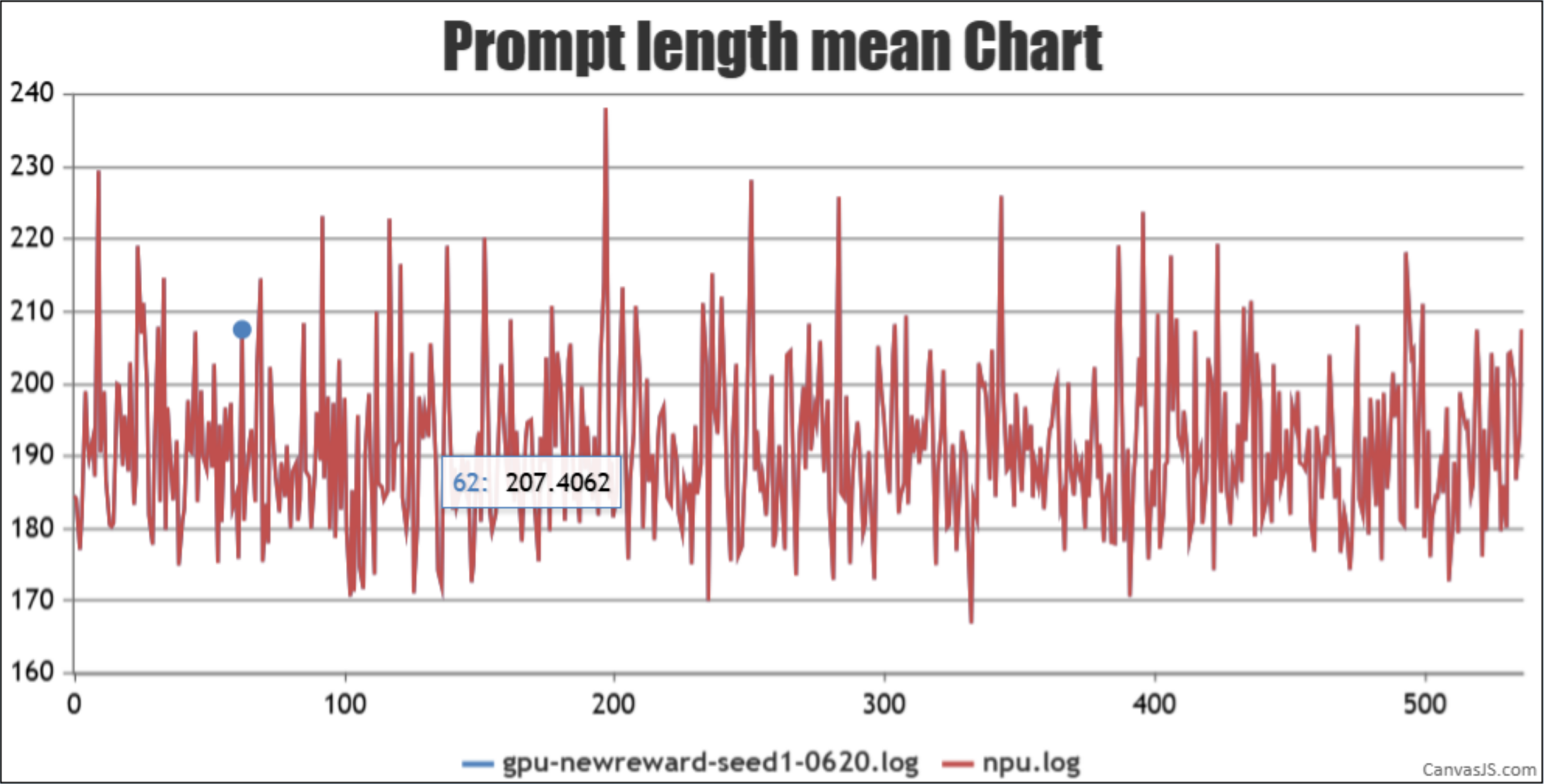
2.2.4 GPU推理结果打桩
和预训练、微调不同,强化学习训练模型使用的输入是通过推理得到的,但推理存在着随机性,且因为grpo算法使用到的group norm需要利用推理的随机性推理出一组不同的结果,因此难以保证GPU和NPU推理的结果完全一致。因此,在NPU侧,我们通过读取从GPU上dump下来的rollout数据,来保证推理的结果对齐。
在对齐GPU和NPU的输入prompt前提下,读取GPU对应的response,就可以对齐模型输入的inputids,方便后续训练部分对齐。
MindSpeed-RL里的dump代码如下,可以参考(mindspeed_rl/models/rule_verifier.py的verifier中):
dump_json_list = []
if config.dump_rollout:
for data_idx, (response, label) in enumerate(zip(responses, labels)):
dump_json_list.append({
"prompt": prompts[data_idx // config.n_samples_per_prompt],
"response": response,
"label": label
})
for idx, fun_verifier in enumerate(verifier_function):
... # Some code here
if config.dump_rollout:
for data_idx, score in enumerate(scores):
dump_json_list[data_idx][fun_verifier] = score
if config.dump_rollout:
with open("mindspeed-rl-rollout.log", "a", encoding="utf-8") as f:
for json_obj in dump_json_list:
f.write(json.dumps(json_obj, ensure_ascii=False) + "\n")
2.2.5 input_ids对齐
在不打桩rollout的前提下,如果对齐了数据集shuffle,可以进行input_ids对齐。
对齐了数据集shuffle,也就对齐了输入prompt。分别打印GPU和NPU的input ids,可以在GPU打印的input ids中寻找到和NPU侧完全相同的prompt ids部分。input ids中剩下部分的input ids包含response ids和pad ids。
pad ids是input ids末尾的pad id重复序列,很容易分辨,剩下的就是response ids。通过对比response ids的末尾,可以检查GPU和NPU的response ids末尾是否具有相同的eos token。

在打桩rollout的前提下,对齐数据集shuffle后,input ids除去pad ids部分应该可以完全对齐。如果发现GPU和NPU有一对几乎完全相同的两个inputids,只有很小的区别,可能是模板没有对齐,或是tokenizer的配置没有对齐。
2.2.6 actor前反向对齐
在rollout打桩且input ids已经完全对齐的前提下,可以使用mstt工具或手动插入hook打印来对比训练阶段的actor前反向精度。
- 如果需要对比前向和反向,建议使用mstt的dump工具,可以参考PyTorch 场景的精度比对
- 如果只对比反向,怀疑算子精度问题可以dump工具,怀疑模型上的问题可以使用monitor工具
- 如果只对比前向,可以手动插入hook代码,可以参考下面的代码:
import torch
iteration = 0
def forward_hook(name): # print datatype, shape, norm of inputs and output of forward
def print_dtype_hooks(module, inputs, output):
global iteration
if 0 <= iteration:
# 打印层的名称和输出数据的dtype
if isinstance(inputs, tuple):
for ind, value in enumerate(inputs):
if value is None:
print(f"inputs, {name}, index={ind}, None")
elif isinstance(value, torch.Tensor) and inputs[ind].data_ptr() != None: #校验data_ptr是否为空
try:
print('xxxxxxx')
print(name)
print(inputs[ind].data_ptr())
print(inputs[ind])
print(
f"inputs, {name}, index={ind}, DataType:{inputs[ind].dtype}, Shape:{inputs[ind].shape}, "
f"Norm:{inputs[ind].float().norm().item()} "
f"mean: {torch.mean(inputs[ind].float())} min: {torch.min(inputs[ind].float())} "
f"max: {torch.max(inputs[ind])}"
)
print('xxxxxxx')
except Exception as e:
print(e)
elif isinstance(inputs, torch.Tensor):
print(
f"input0, {name}, DataType: {inputs.dtype}, Shape:{inputs.shape}, Norm:{inputs.norm().item()} "
f"mean: {torch.mean(inputs)} min: {torch.min(inputs)} max: {torch.max(inputs)}")
if isinstance(output, tuple):
for ind, value in enumerate(output):
if value is None:
print(f"output, {name}, index={ind}, None")
elif isinstance(value, torch.Tensor):
print(
f"output, {name}, index={ind}, DataType:{output[ind].dtype}, Shape:{output[ind].shape}, "
# f"Norm:{output[ind].norm().item()} "
f"mean: {torch.mean(output[ind])} "
f"min: {torch.min(output[ind])} max: {torch.max(output[ind])}")
elif isinstance(output, torch.Tensor):
try:
print(
f"output0, {name}, DataType:{output.dtype}, "
# f"Shape:{output.shape}, Norm:{output.norm().item()} "
f"mean: {torch.mean(output)} min: {torch.min(output)} max: {torch.max(output)}")
except Exception as e:
print(e)
return print_dtype_hooks
def register_hooks(model):
for name, module in model.named_modules():
# 过滤掉不需要的模块
if torch.distributed.get_rank() % 8 == 0:
if isinstance(module, (torch.nn.Module)): # 根据需要调整条件
print_forward_hook = forward_hook(name)
module.register_forward_hook(print_forward_hook)
在模型初始化(参考mindspeed_rl/workers/actor_hybrid_worker.py的_build_model_optimizer里调用self.setup_model_and_optimizer)之后,调用上面定义的register_hooks(model)方法。
def _build_model_optimizer(self):
actor_module, optimizer, opt_param_scheduler = self.setup_model_and_optimizer(
self.model_provider, self.model_type.encoder_or_decoder)
# 插入hook方法调用
register_hooks(actor_module[0])
self.iteration = self.get_iteration()
return actor_module, optimizer, opt_param_scheduler
注意:如果不考虑切分本身引入精度误差,建议在精度对比时mindspeed-rl只切PP,这样网络中间的激活值都是不经过切分的,可以直接比对。
2.2.7 评测结果分析
GPU和NPU评测结果的差异和数据集和模型都有关,根据经验,评测的具体某一项的分数可能有差异,但评测总分的差异应该在2%以内。
3. 案例分享
3.1 配置对齐案例
以本文的实验为例,遇到过两个长跑精度问题,都是因为配置细节没有对齐导致的。
问题一:
通过对比input_ids分析差异,发现提供的tokenizer和GPU上使用的不一致。提供的tokenizer路径是开源下载的Qwen2.5-7B-Instruct,而在GPU上使用的tokenizer是之前训练Qwen2.5-7B得到的,保存权重文件夹名没有包含模型的信息,导致本文误以为是Qwen2.5-7B-Instruct模型。具体差异是,Qwen2.5-7B-Instruct config.json中的eos_token_id是151645,而Qwen2.5-7B的config.json中的eos_token_id是151643。
eos_token_id的差异导致MindSpeed-RL在去padding的过程中误把eos_token也去掉了,模型的输入的input_ids中没有eos_token,导致模型学习不到正确的eos_token的位置,最终模型最终在训练500step后NPU出现训崩问题,response length快速下降至0附近,随着response length的下降,reward也快速下降,最终出现了训崩问题。
问题二:
因为默认的yaml中没有rms_norm_eps配置项,在配置对齐时没有对模型中的rms_norm_eps参数进行配置,按照MindSpeed-RL中的代码逻辑,使用的是默认的1e-6,但GPU上使用的是1e-7,导致在长跑到1500步后出现了reward长跑下降问题。
3.2 GPU推理结果打桩案例
在GPU采集了rollout打桩数据,包括每条数据的prompt,response,task,step,reward。这些数据保存在一个日志文件中,每一行是一个json字符串,包含着这些数据项。使用python的json.loads可以很方便地读取这些数据。但本文也注意到,dump下来的prompt和response都是不完整的——prompt会缺少6~7个特殊字符无法dump下来,response会固定缺少一个eos_token。
因此,在NPU侧,本文通过读取GPU上dump下来的rollout数据,在保证GPU和NPU的输入prompt对齐的前提下,读取GPU对应的response,对GPU的response使用tokenizer进行encode并添加eos_token,这样可以对齐模型输入的inputids。
3.3 input_ids对齐案例
在不打桩的前提下,prompt对齐,在GPU打印的inputids中找到和NPU相同的prompt ids片段,对比剩下的inputids,也就是response ids和pad ids。通过对比response ids的末尾,发现GPU response的末尾有eos_token_id,且GPU的eos_token_id和pad_id是相同的,而NPU response的末尾没有eos_token_id。
通过分析代码发现,NPU response的末尾原来是有eos_token_id的,但被误以为是pad_id所以被去掉了。进一步分析发现是tokenizer的问题:在GPU上用的tokenizer是Qwen2.5-7B的,但目录名字是实验名,看不出来是什么模型,而提供的是Qwen2.5-7B-Instruct模型。
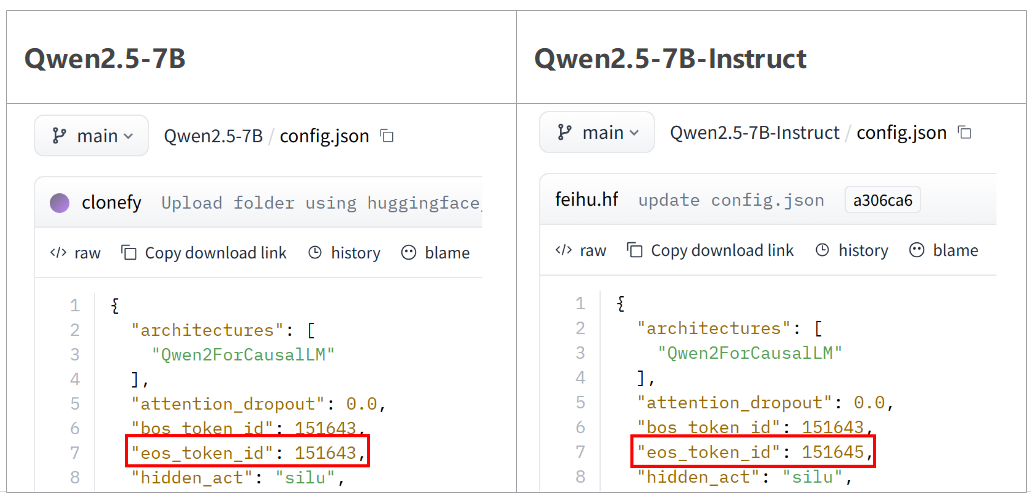
Qwen2.5-7B-Instruct的config.json里的eos_token_id是151645,generation_config.json里的eos_token_id是[151645, 151643],pad_token_id是151643。使用Qwen2.5-7B-Instruct的tokenizer,使用vllm推理得到的response里eos_token_id是151643,但代码判断eos_token_id是151645和pad_token_id不同,所以把eos_token_id当做pad_token_id去掉了,导致NPU的input_ids里没有eos_token_id。对齐GPU和NPU的tokenizer后,NPU上的长跑500步训崩问题解决了。
3.4 actor前向对齐案例
本文实验遇到7b长跑1500步以后NPU出现reward下降问题,经过对比actor网络前向发现,经过layernorm层后,NPUdump的结果和GPU出现较大差异,排查layernorm配置,定位到mindspeed-rl中的rms_norm_eps和GPU上的未对齐。
mindspeed-rl中如果不进行配置,使用的是默认是1e-6。huggingface中Qwen 2.5-7B/32B模型的rms_norm的eps如下表所示。对齐rms_norm_eps后长跑reward下降问题解决。
| 模型 | pretrained | instruct |
|---|---|---|
| Qwen 2.5 7B | 1e-6 | 1e-6 |
| Qwen 2.5 32B | 1e-5 | 1e-6 |
3.5 评测结果分析案例
评测结果的差异和数据集和模型都有关。实验中途更新过一次数据集,更换数据集中的数学问题的难易程度后,GPU和NPU的评分对比结果出现了较大差异:使用数学问题比较难的数据集,math评分NPU比GPU高很多,但beh评分和GPU接近;使用数学问题比较简单的数据集,math评分NPU和GPU接近,但beh评分NPU比GPU高1%。
四、性能调优
4.1 性能观测指标
在性能调优中,用来评判模型性能优劣的参数指标主要分两种:耗时和模型吞吐(tps)。一般情况下,由于模型拉起训消耗的时间成本较高,在性能调优的过程中我们一般关注前三步的耗时以及吞吐,在性能调优到较优配置下后,再进行长跑验证。
4.1.1 单步耗时&长跑平均耗时
迭代耗时主要关注timing/all指标参数,其指代了在当前迭代中的模型耗时总时间。而timing/all由多个模块的耗时组成,其中占比较大的时间为:update时间,rollout推理时间,ref计算和old_log_prob计算时间。在性能调优时,可以关注这几个参数指标哪个占了总时间的比例,来决定重点优化的方向。
4.1.2 吞吐 (tokens/p/s)
以下是RL仓中计算模型吞吐的公式,主要计算的是模型的单步吞吐。(按die计算,A3机器需要*2后统计)
m e a n _ s e q u e n c e _ l e n g t h = m e t r i c s _ r e s u l t [ ′ r e s p o n s e _ l e n g t h / m e a n ′ ] + m e t r i c s _ r e s u l t [ ′ p r o m p t _ l e n g t h / m e a n ′ ] mean\_sequence\_length = metrics\_result['response\_length/mean'] + metrics\_result['prompt\_length/mean'] mean_sequence_length=metrics_result[′response_length/mean′]+metrics_result[′prompt_length/mean′]
t p s = m e a n _ s e q u e n c e _ l e n g t h ∗ g b s ∗ n _ s a m p l e s / w o r l d _ s i z e / t i m e _ a l l tps = mean\_sequence\_length * gbs * n\_samples / world\_size / time\_all tps=mean_sequence_length∗gbs∗n_samples/world_size/time_all
4.2 性能调优三板斧
注:实验配置为8k+4k off-policy配置,且npu机器型号为Atlas 800T A2 a+x 16卡机器,以下调优配置经验建议根据实际场景进行应用
4.2.1 并行策略调整
经过多组调优实验验证,7B和32B最优并行配置如下:
4.2.2 mbs&max_num_seq调整
训练mbs
调整训练mbs效果不明显。该参数指代对于actor update任务每次前向+反向的(Prompt, Response)对数量;对于GRPO算法,设置时需指定考虑n_samples_per_prompt之后的值。
微调训练micro_batch_size参数,可尝试,实验无明显效果。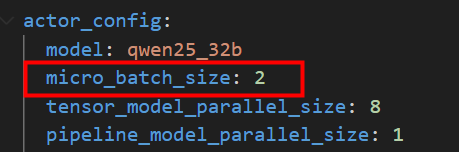
推理mbs
推理配置中(generate_config)的micro_batch_size参数建议拉满(当前最新版本代码会自动拉满), 最大mbs计算公式:
m a x _ m b s = g b s ∗ n _ s a m p l e s / d a t a _ p a r a l l e l _ s i z e max\_mbs = gbs * n\_samples / data\_parallel\_size max_mbs=gbs∗n_samples/data_parallel_size
计算代码:
32B性能调优中,将推理TP2PP1 -> TP4PP1,推理mbs从256 -> 512调整后,性能提升 12%,所以可以尝试调整推理dp换推理mbs进行调优。
max_num_seqs
max_num_seqs 定义了 vLLM 同时处理的**最大请求序列数, **建议拉满,即和推理的max_mbs一致。
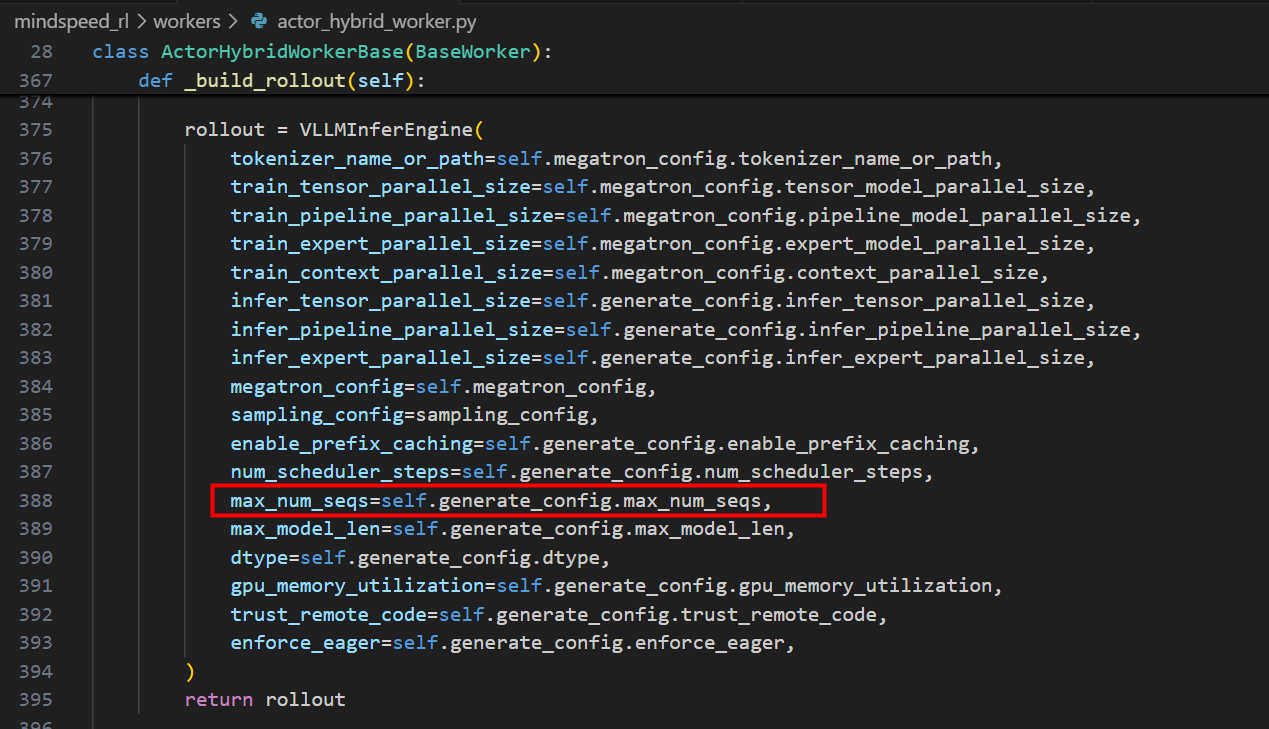
m a x _ n u m _ s e q s = g b s ∗ n _ s a m p l e s / d a t a _ p a r a l l e l _ s i z e max\_num\_seqs = gbs * n\_samples / data\_parallel\_size max_num_seqs=gbs∗n_samples/data_parallel_size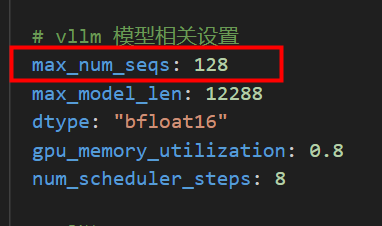
该参数在以下位置传入VLLMInferEngine进行初始化:
4.2.3 特性优化
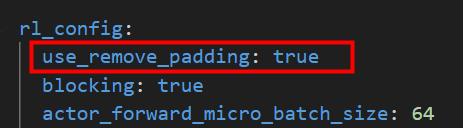
remove padding特性
核心代码:mindspeed_rl/utils/remove_padding.py
原理:去掉input ids末尾的pad ids,结合配置中的megatron_training.variable_seq_lengths,实现动态长度训练。
效果:接入remove_padding特性后,性能 提升15%
分析原因:本实验的序列长度较长,且序列长度不均衡,padding方案对模型性能的优化较大
COC特性
原理:将大模型训练过程中,其ColumnParallelLinear和RowParallelLinear部分的前反向均存在相互毗邻、顺序依赖的计算通信组合,计算为Matmul,而通信则为AllReduce(不开启序列并行)或AllGather和ReduceScatter(开启序列并行)。计算通信并行 CoC (Communication Over Computation)特性可通过计算和通信任务分别拆分成更细粒度的子任务来实现相互的流水掩盖。
效果:训练部分接入coc特性后,性能 提升6-8%
二级流水
当前代码仓已默认开启,开启方法:
在config/env/runtime_env.yaml配置中加入
TASK_QUEUE_ENABLE: ‘2’
配置为“2”时:开启task_queue算子下发队列Level 2优化,算子下发任务如图所示。
Level 2优化:包含Level 1的优化并进一步平衡了一、二级流水的任务负载,主要是将workspace相关任务迁移至二级流水,掩盖效果更好,性能收益更大。该配置仅在二进制场景生效,建议配置值为Level 2优化。
注意:ASCEND_LAUNCH_BLOCKING设置为“1”时,task_queue算子队列关闭,TASK_QUEUE_ENABLE设置不生效;TASK_QUEUE_ENABLE配置为“2”时,由于内存并发,可能导致运行中NPU内存峰值上升。
五、总结和展望
通过项目实践,我们发现在8k推4k场景下,MindSpeed-RL的Qwen2.5-7B/32B GRPO精度,性能都能够满足预期。在迁移的过程中,我们发现MindSpeed-RL的和Verl相比,代码结构更加清晰简洁,和MindSpeed加速库特性更加适配,且支持异构方案和异步流水。
当前强化学习的模型和算法需求还很多,模型方面例如Qwen3,算法方面DPO、PPO和DAPO。另外,MindSpeed-RL的性能还有很大的优化空间,包括推理部分的VLLM性能和在线推理、训练部分的性能,还有许多优化特性在开发和实现中。相信随着模型、特性和功能的进一步完善,MindSpeed-RL未来一定会越来越好用。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)