多模态基础介绍
文本 (Text)图像 (Image)音频 (Audio)视频(Video)等,在AI学习我们又通常分为多模态理解和多模态生成。多模态理解:模型接收图像、音频或视频,将其转化为计算机可理解的语义或文本。比如:给一张照片,问AI“图里的人在干什么?多模态生成:模型根据输入的指令(通常是文本),创造出新的视觉、听觉内容。比如:视频素材生成。MindSpeed-MM:华为昇腾面向大规模分布式训练的多模态
关注公众号:AI模力圈
作者:ming-L
简介
多模态是指人工智能模型具备同时处理、理解和整合多种不同形式信息(即“模态”)的能力,常见的模态包括:文本 (Text)、图像 (Image)、音频 (Audio)、视频 (Video)等,在AI学习我们又通常分为多模态理解和多模态生成。
- 多模态理解:模型接收图像、音频或视频,将其转化为计算机可理解的语义或文本。比如:给一张照片,问AI“图里的人在干什么?”
- 多模态生成:模型根据输入的指令(通常是文本),创造出新的视觉、听觉内容。比如:视频素材生成。
现在昇腾MindSpeed加速库,适配了多个多模态模型,具有较好的性能和效果,如生成式大模型FLUX,理解类大模型Qwen3-vl等等,具体可以参考该开源仓:MindSpeed-MM:华为昇腾面向大规模分布式训练的多模态大模型套件,支撑多模态生成、多模态理解。 - AtomGit | GitCode - 多模态理解经典架构
本篇章主要讲解多模态的经典架构,下面用 kimi-vl 的架构图来作为示例。kimi-vl运用了经典的多模态架构(经典三段式:VIT+Projector+LLM),这是当前一种将视觉信息与语言模型能力相融合的主流范式。
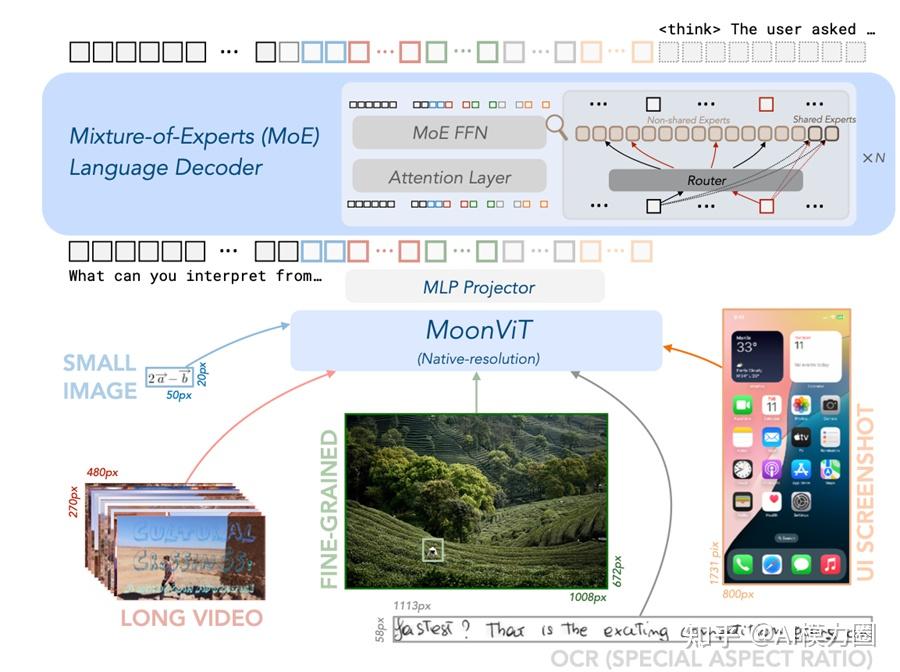
- ViT (Vision Transformer):负责视觉特征提取。它将输入图像分割成小块(Patch),通过线性投影转换为嵌入向量,并加入位置编码,最后由Transformer编码器处理,输出视觉特征序列。
- Projector (适配器):通常是一个简单的线性层或小型MLP。其核心作用是进行维度对齐,将ViT输出的视觉特征维度,映射到LLM词嵌入向量的维度空间,形成visual tokens。
- LLM (大语言模型):作为认知与推理的核心。视觉令牌与文本令牌会在序列中进行拼接或交错,然后一同输入LLM。LLM通过自注意力机制共同处理这两种模态的信息,并最终生成文本响应。
代码示例
下面提供 qwen3-vl 的代码例子,可以看到 qwen3-vl -moe 中初始化 init 的时候分别定义了 visual(即vit)和 language_model(即 LLM)两个模型;但是这里我们没有看到 Projector 的定义,因为 Projector 一般就是个简单的 MLP,不需要单独初始化一个 model。
@auto_docstring
class Qwen3VLMoeModel(Qwen3VLMoePreTrainedModel):
base_model_prefix = ""
_checkpoint_conversion_mapping = {}
# Reference: fix gemma3 grad acc # 37208
accepts_loss_kwargs = False
config: Qwen3VLMoeConfig
_no_split_modules = ["Qwen3VLMoeTextDecoderLayer", "Qwen3VLMoeVisionBlock"]
def __init__(self, config):
super().__init__(config)
self.visual = Qwen3VLMoeVisionModel._from_config(config.vision_config)
self.language_model = Qwen3VLMoeTextModel._from_config(config.text_config)
self.rope_deltas = None # cache rope_deltas here架构运作流程
基于多模态理解类模型的经典架构,其前向流程一般是这样的

- 图像/视频等经过 vit转换成视觉特征
- 视觉特征经过 projector 进行映射,注入到 LLM 中
- LLM共同处理视觉和语言两种模态信息,训练理解能力,最终可以基于输入的其他模态(img,video等)去理解其中内容。
多模态生成经典架构
- 以经典DIT模型结构为例,目前是 Sora、Stable Diffusion 3、Wan2.1 等顶级视频和图像生成模型的核心。
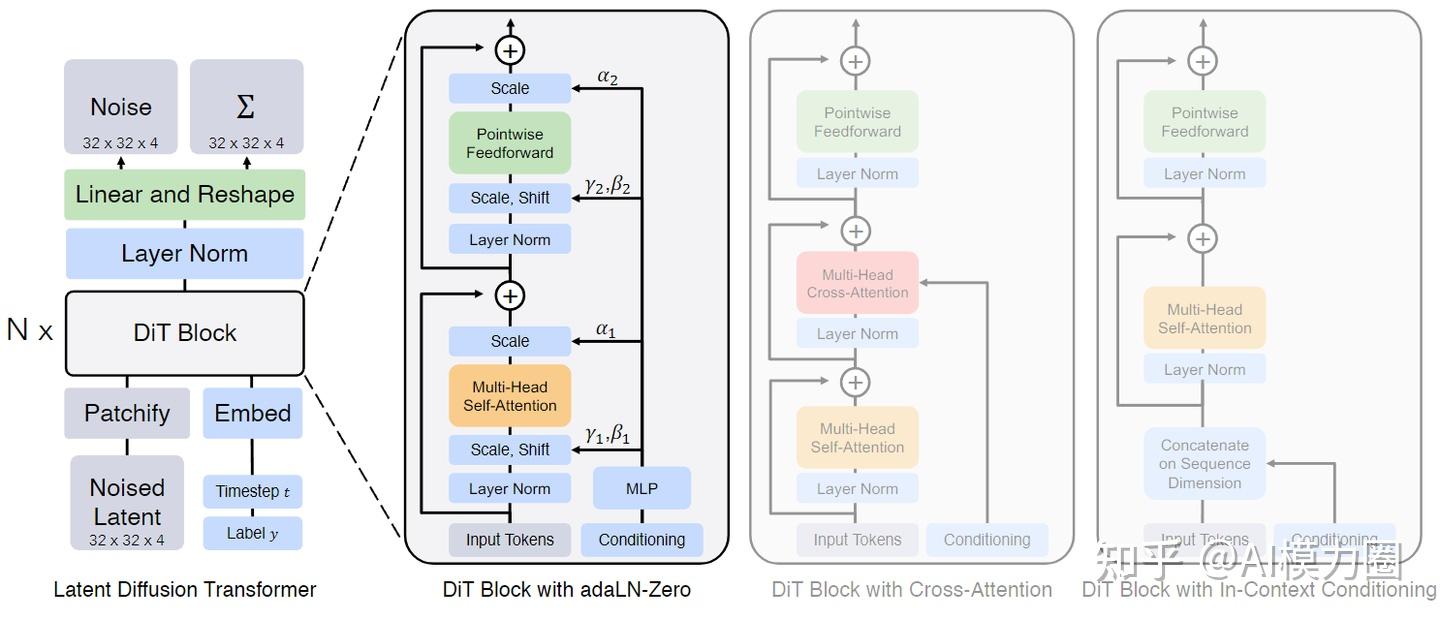
DiT 并不是在原始像素上操作,而是在潜在空间(Latent Space)中进行。其架构主要由以下四个部分组成:
- VAE (Variational Autoencoder):
- Encoder:将高分辨率图像(如 256x256x3)压缩成低维度的潜在表示(Latent, 如 32x32x4)。
- Decoder:在最后阶段,将生成的潜变量还原回像素空间。
- Patchify(切片化):
- 将二维的潜在表示划分为一系列(Patches)。类似于 ViT,这步将空间维度转化为序列维度(Tokens)。
- DiT Block(核心 Transformer 模块):
- 这是 DiT 的灵魂。它采用了多层 Transformer 结构,并引入了条件注入机制(Conditioning)。
- 最经典的设计是 adaLN-Zero (Adaptive Layer Norm),它通过预测缩放和移位参数来控制信息的流动。
- Linear Decoder(线性解码层):
- 将 Transformer 输出的 Token 序列重新排列并投影回潜在表示的形状,以预测噪声。
代码示例
class DiT(nn.Module):
def __init__(
self,
input_size=32, # Latent 的空间尺寸 (例如 VAE 压缩后是 32x32)
patch_size=2, # 每个 patch 的大小
in_channels=4, # Latent 的通道数 (如 SD 的 VAE 是 4)
hidden_size=1152, # Transformer 的维度
depth=28, # Block 的层数
num_heads=16, # 注意力头数
num_classes=1000, # 条件类别数
):
super().__init__()
self.in_channels = in_channels
self.patch_size = patch_size
self.num_patches = (input_size // patch_size) ** 2
# 1. Patch Embedding (切片投影)
self.x_embedder = nn.Linear(patch_size * patch_size * in_channels, hidden_size)
# 2. Timestep & Class Embedding (条件嵌入)
self.t_embedder = nn.Sequential(
nn.Linear(256, hidden_size), # 假设输入是预处理好的正弦余弦特征
nn.SiLU(),
nn.Linear(hidden_size, hidden_size)
)
self.y_embedder = nn.Embedding(num_classes, hidden_size)
# 3. Position Embedding (可学习或固定的位置编码)
self.pos_embed = nn.Parameter(torch.zeros(1, self.num_patches, hidden_size))
# 4. DiT Blocks (堆叠 Transformer 层)
self.blocks = nn.ModuleList([
DiTBlock(hidden_size, num_heads) for _ in range(depth)
])
# 5. Final Layer (还原回 Latent 形状)
self.final_layer = nn.Sequential(
nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6),
nn.Linear(hidden_size, patch_size * patch_size * in_channels)
)
self.initialize_weights()架构运作流程


昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)