SLAM前端中的GPU加速——以vins-fusion-gpu和ORB_SLAM2_CUDA为例
内存管理流和事件图像处理特征检测几何检测:CannyEdgeDetector, Hough系列, CornersDetector光流计算:多种光流算法(Brox, Farneback, PyrLK, TV-L1等)立体视觉:多种立体匹配算法(BM, SGM, Belief Propagation等)背景减除:多种背景建模算法(MOG, MOG2, GMG, FGD)对象检测匹配与分类系统工具下表整
1 GPU
GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device)。
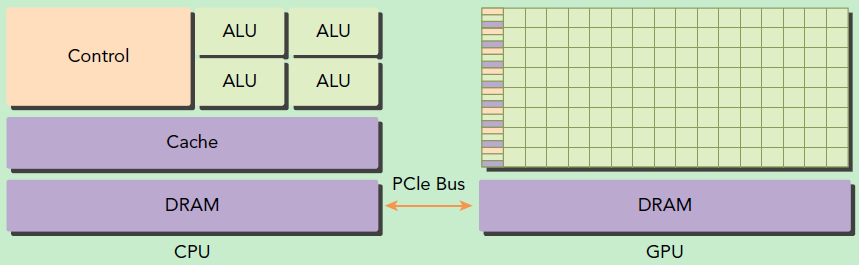
可以看到GPU包括更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,而CPU的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务。另外,CPU上的线程是重量级的,上下文切换开销大,但是GPU由于存在很多核心,其线程是轻量级的。因此,基于CPU+GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重点处理数据密集型的并行计算程序,从而发挥最大功效。
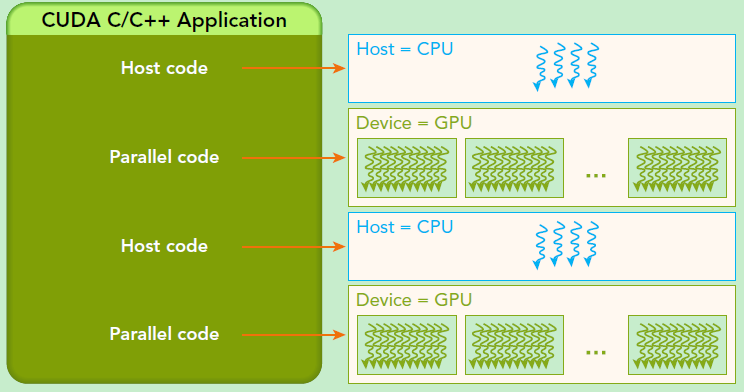
CUDA是NVIDIA公司所开发的GPU编程模型,它提供了GPU编程的简易接口,基于CUDA编程可以构建基于GPU计算的应用程序,将cpu指令翻译成GPU指令。CUDA提供了对其它编程语言的支持,如C/C++,Python,Fortran等语言。
2 opencv cuda模块说明
cv::cuda 是 OpenCV 中专门用于 GPU 加速计算的模块,它提供了与 CUDA 兼容的 NVIDIA GPU 上进行并行图像处理和计算机视觉算法的功能。
不管是vins-fusion-gpu还是ORB_SLAM2_CUDA,都直接使用了opencv cuda模块或在其基础上改进来实现前端的GPU加速。
https://docs.opencv.org/4.x/d1/d1a/namespacecv_1_1cuda.html
https://docs.opencv.org/4.x/d1/d1e/group__cuda.html
以下是OpenCV CUDA模块中主要类的作用说明表格:
|
类名 |
主要作用 |
关键功能 |
|---|---|---|
| GpuMat |
GPU内存中的矩阵容器 |
存储图像和矩阵数据,类似cv::Mat的GPU版本 |
| Stream |
CUDA流管理 |
管理异步操作序列,实现并发执行 |
| Event |
CUDA事件管理 |
记录时间点和操作同步 |
| HostMem |
固定内存管理 |
优化主机-设备数据传输性能 |
| DeviceInfo |
GPU设备信息查询 |
获取CUDA设备属性和能力信息 |
| BufferPool |
流缓冲区池 |
为CUDA流预分配和重用内存缓冲区 |
| Filter |
图像滤波基类 |
派生各种滤波器(高斯、中值、卷积等) |
| Convolution |
卷积运算 |
执行图像卷积或互相关操作 |
| LookUpTable |
查找表变换 |
使用预定义查找表进行像素值转换 |
| DFT |
离散傅里叶变换 |
执行频域变换和逆变换 |
| CannyEdgeDetector |
Canny边缘检测 |
检测图像边缘并提取轮廓 |
| HoughLinesDetector |
霍夫直线检测 |
检测图像中的直线 |
| HoughCirclesDetector |
霍夫圆检测 |
检测图像中的圆形 |
| HoughSegmentDetector |
霍夫线段检测 |
检测图像中的线段 |
| CornersDetector |
角点检测器基类 |
派生各种角点检测算法 |
| CornernessCriteria |
角点响应计算 |
计算角点响应图(如Harris角点) |
| FastFeatureDetector |
FAST特征点检测 |
快速检测图像角点特征 |
| ORB |
ORB特征检测与描述 |
检测ORB特征点并计算描述子 |
| SURF_CUDA |
SURF特征检测与描述 |
GPU加速的SURF特征提取 |
| HOG |
HOG特征提取与检测 |
计算方向梯度直方图,用于对象检测 |
| Feature2DAsync |
异步特征检测接口 |
支持异步执行的特征检测和描述提取 |
| DescriptorMatcher |
描述子匹配器 |
匹配关键点描述子(如BF匹配、FLANN) |
| CascadeClassifier |
级联分类器 |
用于对象检测(支持HAAR和LBP级联) |
| CLAHE |
限制对比度自适应直方图均衡 |
增强图像对比度,避免过度增强 |
| DenseOpticalFlow |
稠密光流算法接口 |
计算每个像素的运动向量 |
| SparseOpticalFlow |
稀疏光流算法接口 |
计算特征点的运动向量 |
| BroxOpticalFlow |
Brox光流算法 |
基于变分法的光流计算 |
| FarnebackOpticalFlow |
Farneback光流算法 |
多项式展开的光流计算 |
| DensePyrLKOpticalFlow |
稠密金字塔LK光流 |
基于金字塔的稠密光流 |
| SparsePyrLKOpticalFlow |
稀疏金字塔LK光流 |
基于金字塔的稀疏光流 |
| OpticalFlowDual_TVL1 |
TV-L1光流算法 |
全变分L1正则化的光流计算 |
| NvidiaHWOpticalFlow |
NVIDIA硬件光流接口 |
使用NVIDIA硬件加速的光流计算 |
| StereoBM |
立体匹配块匹配算法 |
计算立体图像对的视差图 |
| StereoSGM |
半全局立体匹配 |
改进的立体匹配算法,质量更高 |
| StereoBeliefPropagation |
立体匹配置信传播 |
使用置信传播算法的立体匹配 |
| StereoConstantSpaceBP |
恒定空间置信传播 |
内存优化的置信传播立体匹配 |
| DisparityBilateralFilter |
视差图双边滤波 |
对视差图进行联合双边滤波优化 |
| BackgroundSubtractorMOG |
混合高斯背景建模 |
基于高斯混合模型的背景减除 |
| BackgroundSubtractorMOG2 |
改进混合高斯背景建模 |
自适应高斯混合模型背景减除 |
| BackgroundSubtractorGMG |
GMG背景减除算法 |
基于统计的背景建模算法 |
| BackgroundSubtractorFGD |
前景检测算法 |
复杂场景的前景/背景分割 |
| TemplateMatching |
模板匹配 |
在图像中搜索模板位置 |
| ImagePyramid |
图像金字塔 |
构建图像金字塔用于多尺度处理 |
| FastOpticalFlowBM |
快速块匹配光流 |
基于块匹配的快速光流计算 |
| TargetArchs |
目标架构检查 |
检查CUDA模块构建的NVIDIA架构支持 |
| GpuMatND |
多维GPU矩阵 |
存储多维数据的GPU容器 |
| GpuData |
GPU数据包装结构 |
底层GPU数据管理 |
| EventAccessor |
事件访问器 |
获取底层cudaEvent_t句柄 |
| StreamAccessor |
流访问器 |
获取底层cudaStream_t句柄 |
| FGDParams |
FGD算法参数结构 |
前景检测算法的参数配置 |
主要类别总结:
-
内存管理:GpuMat, HostMem, BufferPool, GpuMatND
-
流和事件:Stream, Event, StreamAccessor, EventAccessor
-
图像处理:Filter, Convolution, LookUpTable, DFT, CLAHE
-
特征检测:FastFeatureDetector, ORB, SURF_CUDA, HOG
-
几何检测:CannyEdgeDetector, Hough系列, CornersDetector
-
光流计算:多种光流算法(Brox, Farneback, PyrLK, TV-L1等)
-
立体视觉:多种立体匹配算法(BM, SGM, Belief Propagation等)
-
背景减除:多种背景建模算法(MOG, MOG2, GMG, FGD)
-
对象检测:CascadeClassifier, HOG
-
匹配与分类:DescriptorMatcher, TemplateMatching
-
系统工具:DeviceInfo, TargetArchs
opencv cuda使用流程
以resize为例 读取图像到CPU内存(cv::Mat)。
将图像上传到GPU内存(cv::cuda::GpuMat)。
创建CUDA版本的resize函数对象或直接使用CUDA函数。
执行resize操作。
将结果下载回CPU内存。
#include <iostream>
#include <opencv2/opencv.hpp>
#include <opencv2/cudawarping.hpp> // CUDA的图像变换操作
#include <opencv2/cudaimgproc.hpp> // CUDA的图像处理操作
#include <chrono>
int main() {
// 检查CUDA是否可用
if (!cv::cuda::getCudaEnabledDeviceCount()) {
std::cerr << "CUDA device not available!" << std::endl;
return -1;
}
// 打印CUDA设备信息
cv::cuda::printCudaDeviceInfo(cv::cuda::getDevice());
// 1. 读取原始图像到CPU内存
cv::Mat src_host = cv::imread("input.jpg");
if (src_host.empty()) {
std::cerr << "Could not read image!" << std::endl;
return -1;
}
std::cout << "Original image size: " << src_host.cols << "x" << src_host.rows << std::endl;
// 2. 创建目标尺寸
cv::Size new_size(src_host.cols / 2, src_host.rows / 2);
// 使用CUDA的resize函数(推荐)
{
// 将图像上传到GPU内存
cv::cuda::GpuMat src_device, dst_device;
src_device.upload(src_host);
auto start = std::chrono::high_resolution_clock::now();
// 在GPU上执行resize操作
cv::cuda::resize(src_device, dst_device, new_size, 0, 0, cv::INTER_LINEAR);
// 等待GPU操作完成
cv::cuda::Stream stream;
stream.waitForCompletion();
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start);
std::cout << "CUDA resize time: " << duration.count() << " microseconds" << std::endl;
// 将结果下载到CPU内存
cv::Mat dst_host;
dst_device.download(dst_host);
cv::imwrite("output_cuda_resize.jpg", dst_host);
std::cout << "Resized to: " << dst_host.cols << "x" << dst_host.rows << std::endl;
}
// 与CPU版本对比
{
auto start = std::chrono::high_resolution_clock::now();
cv::Mat dst_host;
cv::resize(src_host, dst_host, new_size, 0, 0, cv::INTER_LINEAR);
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start);
std::cout << "CPU resize time: " << duration.count() << " microseconds" << std::endl;
cv::imwrite("output_cpu_resize.jpg", dst_host);
}
return 0;
}
3 vins-fusion-gpu
VINS-Fusion-gpu是在前端的特征点提取与光流跟踪两个阶段都做了GPU加速,具体代码可以见feature_tracker.cpp
https://gitee.com/maxibooksiyi/VINS-Fusion-gpu/blob/speed_opti/vins_estimator/src/featureTracker/feature_tracker.cpp
3.1 特征点提取
cv::cuda::GpuMat cur_gpu_img(cur_img);
cv::cuda::GpuMat d_prevPts;
TicToc t_gg;
cv::cuda::GpuMat gpu_mask(mask);
// printf("gpumat cost: %fms\n",t_gg.toc());
cv::Ptr<cv::cuda::CornersDetector> detector = cv::cuda::createGoodFeaturesToTrackDetector(cur_gpu_img.type(), MAX_CNT - cur_pts.size(), 0.01, MIN_DIST);
// cout << "new gpu points: "<< MAX_CNT - cur_pts.size()<<endl;
detector->detect(cur_gpu_img, d_prevPts, gpu_mask);
// std::cout << "d_prevPts size: "<< d_prevPts.size()<<std::endl;
if(!d_prevPts.empty())
n_pts = cv::Mat_<cv::Point2f>(cv::Mat(d_prevPts));
else
n_pts.clear();
cv::cuda::createGoodFeaturesToTrackDetector 函数,这是 OpenCV CUDA 模块中 GPU 加速版本的角点检测器。 https://docs.opencv.org/4.x/dc/d6d/group__cudaimgproc__feature.html
函数概述
这是 GPU 加速的 Shi-Tomasi 角点检测器,功能与 CPU 版本的 cv::goodFeaturesToTrack 相同,但利用 NVIDIA GPU 进行并行计算,显著提升检测速度。
算法原理
基于 Shi-Tomasi 角点检测方法(是 Harris 角点检测的改进)。
Harris 角点检测:通过计算图像窗口在各个方向上移动时的灰度变化强度来判断角点。
Shi-Tomasi 改进:定义了一个角点响应函数 R = min(λ1, λ2),其中 λ1 和 λ2 是图像的自相关矩阵的特征值。
如果 R 大于某个阈值,则认为是“好”的角点。
相比于 Harris,Shi-Tomasi 对角点的判断更稳定。
函数原型
cv::Ptr<cv::cuda::CornernessCriteria> cv::cuda::createGoodFeaturesToTrackDetector(
int srcType, // 输入图像类型
int maxCorners = 1000, // 最大角点数量
double qualityLevel = 0.01, // 角点质量阈值
double minDistance = 0.0, // 角点间最小距离
int blockSize = 3, // 计算窗口大小
bool useHarrisDetector = false, // 是否使用Harris算法
double harrisK = 0.04 // Harris算法参数
);返回类型:cv::Ptr<cv::cuda::CornernessCriteria> - 一个智能指针,指向 GPU 角点检测器对象。
参数详解
|
参数 |
类型 |
说明 |
|---|---|---|
srcType |
int |
输入图像类型
,必须是以下之一: |
maxCorners |
int |
最大角点数量(默认1000) |
qualityLevel |
double |
角点质量阈值(0.0-1.0) |
minDistance |
double |
角点间最小欧氏距离 |
blockSize |
int |
计算角点响应的窗口大小(奇数,≥3) |
useHarrisDetector |
bool |
true
: Harris角点检测 |
harrisK |
double |
Harris算法的自由参数(默认0.04) |
3.2 光流跟踪
cur_gpu_img = cv::cuda::GpuMat(_img);
right_gpu_img = cv::cuda::GpuMat(_img1);
cv::cuda::GpuMat prev_gpu_pts(prev_pts);
cv::cuda::GpuMat cur_gpu_pts(cur_pts);
cv::cuda::GpuMat gpu_status;
cur_gpu_pts = cv::cuda::GpuMat(predict_pts);
cv::Ptr<cv::cuda::SparsePyrLKOpticalFlow> d_pyrLK_sparse = cv::cuda::SparsePyrLKOpticalFlow::create(
cv::Size(21, 21), 1, 30, true);
d_pyrLK_sparse->calc(prev_gpu_img, cur_gpu_img, prev_gpu_pts, cur_gpu_pts, gpu_status);
vector<cv::Point2f> tmp_cur_pts(cur_gpu_pts.cols);
cur_gpu_pts.download(tmp_cur_pts);
cur_pts = tmp_cur_pts;
vector<uchar> tmp_status(gpu_status.cols);
gpu_status.download(tmp_status);
https://docs.opencv.org/4.x/d7/d05/classcv_1_1cuda_1_1SparsePyrLKOpticalFlow.html
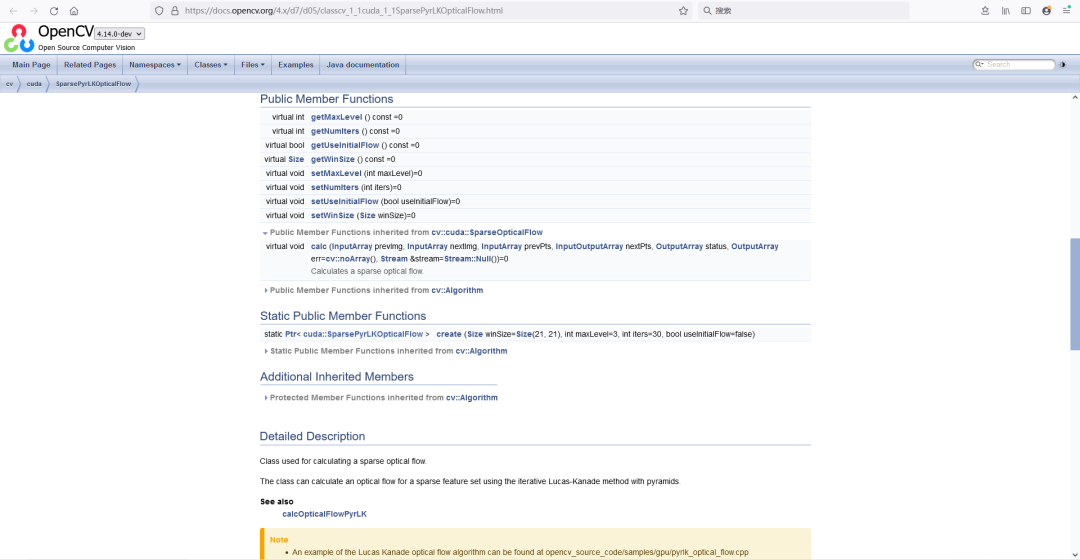
virtual void calc(
InputArray prevImg, // 前一帧图像(GPU内存)
InputArray nextImg, // 后一帧图像(GPU内存)
InputArray prevPts, // 前一帧的特征点坐标
InputOutputArray nextPts, // 计算得到的后一帧对应点坐标(输入输出参数)
OutputArray status, // 每个特征点的跟踪状态(1成功,0失败)
OutputArray err = cv::noArray(), // 每个特征点的误差
Stream &stream = Stream::Null() // CUDA流,用于异步计算
) = 0;4 ORB_SLAM2_CUDA
https://github.com/yunchih/ORB-SLAM2-GPU2016-final/
https://github.com/thien94/ORB_SLAM2_CUDA
https://github.com/SYSU-FishTouchers/ORB_SLAM3_MOKAI/
这里依次给了三个仓库地址,仓库一和仓库二是加入加入GPU加速的ORBSLAM2仓库库三是加入GPU加速的ORBSLAM3,仓库二和仓库三都有参考仓库一,这里选择ORB_SLAM2_CUDA来进行说明,ORB_SLAM2_CUDA我自己也亲自在OrinNX上部署运行过。
ORBSLAM的ORB特征提取是基于opencv的ORB特征提取代码改动而来,包括GPU加速的ORB特征提取CUDA代码也是基于opencv的ORB特征提取CUDA代码小改而来的,主要改动是让特征点尽可能地分散到图片的整个区域而不是只有在纹理明显的区域有特征点。
所以我们可以先看看opencv自带的GPU加速的ORB特征提取。
4.1 cv::cuda::ORB
cv::cuda::ORB 是 OpenCV 的 CUDA 模块中实现 ORB (Oriented FAST and Rotated BRIEF) 特征检测和描述子提取的类。它利用 GPU 加速,适合需要高性能视觉处理的应用。
这个类的成员函数主要可以分为创建与销毁、核心操作、参数设置、以及工具函数这几大类。
核心成员函数分类介绍
下表整理了 cv::cuda::ORB 的主要成员函数及其作用,部分函数继承自基类 cv::Feature2D 或 cv::cuda::Feature2DAsync。
|
分类 |
函数名 |
主要作用 |
|---|---|---|
| 创建与销毁 | create |
静态工厂方法,用于创建一个 |
~ORB |
虚析构函数,负责正确释放对象资源。 |
|
| 核心操作 | detect |
在输入图像中检测关键点(CPU版本,结果存在CPU内存中)。 |
detectAsync |
(异步)
在图像中检测关键点,结果留在GPU内存中,可与CUDA流协同工作,不阻塞CPU。 |
|
compute |
为给定的关键点计算描述子(CPU版本)。 |
|
computeAsync |
(异步)
为给定的关键点计算描述子,结果留在GPU内存中。 |
|
detectAndCompute |
同时检测关键点并计算描述子(CPU版本)。 |
|
detectAndComputeAsync |
(异步)
同时检测关键点并计算描述子,所有操作和结果都在GPU上,是GPU加速的核心。 |
|
convert |
将GPU内部表示的关键点数组转换为标准的 |
|
| 参数设置与查询 | setBlurForDescriptor
/ |
设置/获取在计算描述子前是否对图像进行模糊处理,这有助于提高描述子的质量。 |
setMaxFeatures
/ |
设置/获取要保留的最大特征点数量。 |
|
setNLevels
/ |
设置/获取高斯金字塔的层数。 |
|
setScaleFactor
/ |
设置/获取金字塔的缩放因子。 |
|
setEdgeThreshold
/ |
设置/获取检测边缘的阈值,边界附近不检测特征点。 |
|
setFirstLevel
/ |
设置/获取起始金字塔层。 |
|
setWTA_K
/ |
设置/获取计算BRIEF描述子时,每个字节对应的点数(2、3或4)。 |
|
setScoreType
/ |
设置/获取评分方式( |
|
setPatchSize
/ |
设置/获取用于计算BRIEF描述子的patch大小。 |
|
setFastThreshold
/ |
设置/获取FAST角点检测的阈值。 |
|
| 其他工具函数 | descriptorSize |
获取描述子的字节大小。 |
descriptorType |
获取描述子的数据类型(通常是 |
|
defaultNorm |
获取用于比较描述子的默认范数类型(通常是 |
|
empty |
检查算法对象是否为空(例如,是否成功创建)。 |
|
clear |
清除算法状态,释放内存。 |
|
save
/ |
将算法参数保存到文件或从文件读取。 |
https://docs.opencv.org/4.x/da/d44/classcv_1_1cuda_1_1ORB.html
使用流程
通常使用 cv::cuda::ORB 的步骤如下:
-
调用
create静态方法创建实例并设置参数。 -
调用
detectAndComputeAsync等异步方法在GPU上执行检测和描述子计算。 -
如果需要,调用
convert将GPU上的关键点数据转换到CPU端进行后续处理。
以下是一个使用 cv::cuda::ORB::detectAndComputeAsync 的完整示例。该函数在 GPU 上异步执行特征检测与描述子计算,需要配合 cv::cuda::Stream 管理并发,最后通过 convert 和 download 将结果取回 CPU。
#include <iostream>
#include <opencv2/opencv.hpp>
#include <opencv2/cudaorb.hpp>
#include <opencv2/cudafeatures2d.hpp>
#include <opencv2/core/cuda.hpp>
int main()
{
// 1. 检查是否有可用的 CUDA 设备
if (cv::cuda::getCudaEnabledDeviceCount() == 0)
{
std::cerr << "No CUDA-capable device found!" << std::endl;
return -1;
}
cv::cuda::setDevice(0); // 选择第一个 GPU
// 2. 读取图像并上传到 GPU
cv::Mat img = cv::imread("image.jpg", cv::IMREAD_GRAYSCALE);
if (img.empty())
{
std::cerr << "Failed to load image!" << std::endl;
return -1;
}
cv::cuda::GpuMat d_img;
d_img.upload(img);
// 3. 创建 ORB 特征检测器(使用默认参数)
cv::Ptr<cv::cuda::ORB> orb = cv::cuda::ORB::create();
// 4. 创建 CUDA 流,用于异步操作
cv::cuda::Stream stream;
// 5. 声明 GPU 上的输出容器
cv::cuda::GpuMat d_keypoints; // 内部格式的关键点
cv::cuda::GpuMat d_descriptors; // 描述子
// 6. 异步执行检测与描述子计算
// 参数:图像,掩码(无掩码传 cv::noArray()),关键点输出,描述子输出,
// 是否使用提供的 keypoints(false 表示自动检测),流
orb->detectAndComputeAsync(d_img, cv::noArray(), d_keypoints, d_descriptors, false, stream);
// 7. 将结果从 GPU 取回 CPU(需等待异步操作完成)
std::vector<cv::KeyPoint> keypoints;
cv::Mat descriptors;
// 7.1 等待流中所有任务完成
stream.waitForCompletion();
// 7.2 将 GPU 关键点转换为标准 KeyPoint 向量
orb->convert(d_keypoints, keypoints);
// 7.3 下载描述子(此时流已同步,可直接 download)
d_descriptors.download(descriptors);
// 8. 输出统计信息
std::cout << "Detected " << keypoints.size() << " keypoints." << std::endl;
std::cout << "Descriptors size: " << descriptors.size() << ", type: " << descriptors.type() << std::endl;
// 9. (可选)在 CPU 上绘制并显示特征点
cv::Mat img_with_kp;
cv::drawKeypoints(img, keypoints, img_with_kp, cv::Scalar::all(-1), cv::DrawMatchesFlags::DEFAULT);
cv::imshow("Keypoints", img_with_kp);
cv::waitKey(0);
return 0;
}
关键说明
-
异步与同步:
detectAndComputeAsync调用后会立即返回,实际计算在 GPU 后台进行。必须调用stream.waitForCompletion()或cuda::Stream::waitForCompletion()确保结果可用,然后再执行convert和download。 -
关键点转换:
detectAndComputeAsync输出的关键点存储在GpuMat中,格式为 ORB 内部使用的紧凑表示,必须通过orb->convert()转换为标准的std::vector<cv::KeyPoint>才能被 OpenCV 的其他函数使用。 -
描述子下载:
d_descriptors是一个GpuMat,可以直接调用.download()将数据复制到 CPU 端的cv::Mat。 -
掩码支持:如果只需要处理图像的部分区域,可以传入一个
GpuMat掩码(与图像同大小,非零区域参与检测)。
编译与运行
确保 OpenCV 已编译并启用了 CUDA 模块(opencv_cuda* 系列库)。编译命令示例(Linux):
g++ orb_example.cpp -o orb_example `pkg-config --cflags --libs opencv4` -lopencv_cudaorb -lopencv_cudafeatures2d运行时将显示检测到的特征点图像,并输出数量与描述子信息。
4.2 opencv的fast.cu和orb.cu
https://github.com/opencv/opencv_contrib/blob/4.x/modules/cudafeatures2d/src/fast.cpp
https://github.com/opencv/opencv_contrib/blob/4.x/modules/cudafeatures2d/src/orb.cpp
https://github.com/opencv/opencv_contrib/blob/4.x/modules/cudafeatures2d/src/cuda/fast.cu
https://github.com/opencv/opencv_contrib/blob/4.x/modules/cudafeatures2d/src/cuda/orb.cu
在opencv仓库(不是opencv_contrib)里也有一些cu文件,看git记录,可能是后来把opencv里的cu文件移动到了opencv_contrib里。
https://github.com/opencv/opencv/blob/master/modules/gpu/src/cuda/fast.cu
https://github.com/opencv/opencv/blob/master/modules/gpu/src/cuda/orb.cu
4.3 ORB-SLAM中ORB特征提取核心步骤
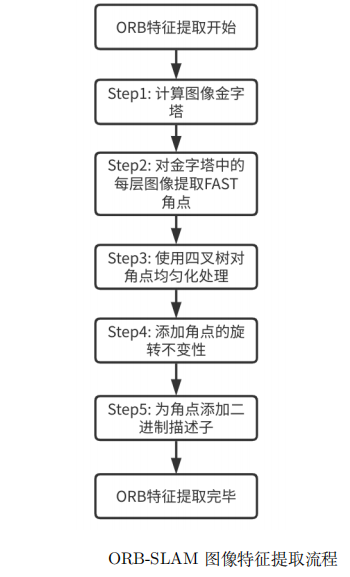
主要目标: 为单帧图像提取出数量固定、质量高、分布均匀的ORB特征点。
1. 构建图像金字塔(尺度不变性)
-
参数: 通常使用8层金字塔,尺度因子为1.2(例如OpenCV ORB默认设置)。
-
操作: 将原始图像按
scale=1.2逐层缩放,得到8幅不同分辨率的图像。特征点将在每一层独立检测。
2. 分网格进行FAST角点初筛
-
目的: 初步控制特征点分布,避免全部集中在高纹理区域。
-
操作:
-
将当前金字塔层的图像划分为
H x W个网格(例如,若图像为640x480,网格大小可设为30x30)。 -
在每个网格内独立运行FAST角点检测器(通常使用
FAST-9-16,即连续9个点比中心亮/暗)。 -
在每个网格内,保留响应值(即角点“尖锐”程度,可用Harris角点响应值近似)最大的前
N个点(例如N=5),作为该网格的候选关键点。
-
3. 四叉树均匀化筛选(关键创新)四叉树和八叉树的区别其实就是一个二维一个三维,所以某种程度上这和构建八叉树地图类似。
-
目的: 在保证特征点质量的前提下,实现全局最优的均匀分布,并精确控制最终提取的特征点总数。
-
操作流程(递归过程): 假设我们最终需要提取
N_final个特征点(例如1000个)。-
如果此时保留的点数仍超过
N_final,则仅保留全局响应值最高的N_final个点。 -
如果保留的点数不足
N_final,则降低FAST检测阈值,重新执行步骤2-4,直到满足数量要求或达到最低阈值。
-
递归分裂直到达到终止条件(如节点内点数<=1,或节点区域过小)。
-
从所有叶子节点(不再分裂的节点)中,每个节点只保留响应值最大的那个关键点。
-
每个树节点对应图像的一个矩形区域。
-
如果一个节点包含的关键点数 > 1,且节点的图像区域面积足够大,则将该节点均等分裂为4个子节点。
-
分裂后,将属于该节点的关键点分配到4个子节点中。
-
初始化: 将所有网格检测到的候选关键点放入一个列表。
-
划分: 如果当前列表中的关键点数超过
N_final,则将整个图像范围作为初始节点,构建一棵四叉树。 -
递归分裂:
-
节点选择:
-
数量控制:
-
-
效果: 经过四叉树筛选后,特征点在图像平面上分布非常均匀,这极大提高了后续特征匹配和位姿估计的鲁棒性。
4. 计算关键点方向(灰度质心法)
-
对于每个通过四叉树筛选的关键点,在其所在金字塔层的图像上,以关键点为中心,取一个圆形区域(半径与尺度相关)。
-
计算该圆形区域的图像矩,并求出其质心。
-
关键点方向
θ = atan2(m01, m10)。 -
此时得到的是oFAST关键点(位置x, y, 尺度level, 方向θ)。
5. 生成rBRIEF描述子
-
根据关键点的尺度和方向,在其所在金字塔层的图像上,取一个
S x S(如31x31)的正方形区域。 -
对该正方形区域进行高斯平滑(OpenCV中默认使用σ=2的核),以增强描述子的抗噪能力。
-
使用预定义的256对随机采样点(BRIEF模式),计算BRIEF描述子的核心步骤是在特征点周围半径为16的圆域内选取256对点对,每个点对内比较得到1位,共得到256位的描述子,为保计算的一致性,工程上使用特定设计的点对pattern,在程序里被硬编码为成员变量了. 但根据关键点的方向θ旋转这些点对坐标(rBRIEF)。
-
比较每对旋转后坐标的像素强度,生成一个256位的二进制字符串,即为该关键点的描述子。
4.4 相比于opencv的改进的地方
下面从 ORB-SLAM3 源码(基于官方仓库 UZ-SLAMLab/ORB_SLAM3)中提取关键代码片段,并与 OpenCV 的实现进行对比,直观展示改进地方。
1.双阈值机制
OpenCV ORB:使用全局固定阈值(通过 fastThreshold 参数设置),对整幅图像应用 FAST 角点检测,低纹理区域容易无特征。
ORB-SLAM3:在 ORBextractor::ComputeKeyPointsOctTree() 中,将图像划分为网格(cell),对每个网格先尝试高阈值,若特征点不足则用低阈值重试。
// 来自 ORB_SLAM3/src/ORBextractor.cc 中的 ComputeKeyPointsOctTree 函数(简化)
// 初始化高阈值和低阈值
const int iniThFAST = 20; // 高阈值
const int minThFAST = 7; // 低阈值
// 遍历所有图像金字塔层
for (int level = 0; level < nlevels; ++level) {
// 计算该层的网格行列数
const int nCols = width / cellSize;
const int nRows = height / cellSize;
vector<cv::KeyPoint> keysToDistribute; // 临时存储当前层所有特征点
// 遍历每个网格
for (int i = 0; i < nRows; i++) {
for (int j = 0; j < nCols; j++) {
// 计算网格在图像中的 ROI
int minX = j * cellSize;
int minY = i * cellSize;
int maxX = minX + cellSize + 6; // +6 是为了保证 FAST 检测时边界充足
int maxY = minY + cellSize + 6;
if (maxX > width) maxX = width;
if (maxY > height) maxY = height;
vector<cv::KeyPoint> vKeysCell;
// 先用高阈值 FAST 检测
FAST(mvImagePyramid[level].rowRange(minY, maxY).colRange(minX, maxX),
vKeysCell, iniThFAST, true);
// 如果高阈值提取不到特征,则用低阈值
if (vKeysCell.empty()) {
FAST(mvImagePyramid[level].rowRange(minY, maxY).colRange(minX, maxX),
vKeysCell, minThFAST, true);
}
// 将检测到的关键点坐标加上网格偏移量
for (auto &kp : vKeysCell) {
kp.pt.x += minX;
kp.pt.y += minY;
keysToDistribute.push_back(kp);
}
}
}
// 对该层所有特征点进行四叉树均匀化分配
vector<cv::KeyPoint> & keypoints = allKeypoints[level];
keypoints = DistributeOctTree(keysToDistribute, minBorderX, maxBorderX,
minBorderY, maxBorderY, nDesiredFeatures[level], level);
}
关键点:
-
每个网格独立检测,保证全图覆盖。
-
双阈值保证了即使弱纹理区域也能提取到一些特征。
2.四叉树均匀化
OpenCV ORB:直接返回 FAST 检测到的所有角点,然后按响应值排序选取前 N 个,特征点容易扎堆。
ORB-SLAM3:通过 DistributeOctTree() 函数递归分割图像区域,确保特征点分布均匀。
// 来自 ORB_SLAM3/src/ORBextractor.cc 中的 DistributeOctTree 函数(核心逻辑)
vector<cv::KeyPoint> ORBextractor::DistributeOctTree(
const vector<cv::KeyPoint>& vToDistributeKeys, const int &minX,
const int &maxX, const int &minY, const int &maxY, const int &N,
const int &level)
{
// 计算初始节点数(根据图像宽高比决定)
const int nIni = round(static_cast<float>(maxX-minX)/(maxY-minY));
const float hX = static_cast<float>(maxX-minX)/nIni;
list<ExtractorNode> lNodes; // 节点链表
vector<ExtractorNode*> vpIniNodes;
vpIniNodes.resize(nIni);
// 创建初始节点(水平分割)
for(int i=0; i<nIni; i++) {
ExtractorNode ni;
ni.UL = cv::Point2i(hX*static_cast<float>(i),0);
ni.UR = cv::Point2i(hX*static_cast<float>(i+1),0);
ni.BL = cv::Point2i(ni.UL.x, maxY-minY);
ni.BR = cv::Point2i(ni.UR.x, maxY-minY);
ni.vKeys.reserve(vToDistributeKeys.size());
lNodes.push_back(ni);
vpIniNodes[i] = &lNodes.back();
}
// 将特征点分配到初始节点中
for(auto &kp : vToDistributeKeys) {
int n = (kp.pt.x - minX) / hX; // 计算属于哪个节点
vpIniNodes[n]->vKeys.push_back(kp);
}
// 四叉树分裂:只要节点数少于目标 N,且节点可分裂(包含特征点且区域可再分)
while((int)lNodes.size() < N) {
int prevSize = lNodes.size();
auto lit = lNodes.begin();
while(lit != lNodes.end()) {
if(lit->vKeys.size() == 1) { // 只有一个特征点的节点不再分裂
lit++;
continue;
}
// 尝试分裂当前节点为四个子节点
if(lit->vKeys.size() > 1) {
ExtractorNode n1, n2, n3, n4;
lit->DivideNode(n1, n2, n3, n4); // 根据特征点分布分裂
// 将包含特征点的子节点加入链表
if(n1.vKeys.size() > 0) {
lNodes.push_front(n1);
if(n1.vKeys.size() > 1) bFinish = false;
}
// ... 类似处理 n2, n3, n4
lit = lNodes.erase(lit); // 删除原节点
} else {
lit++;
}
}
// 如果没有节点可分裂或已达到目标数,则退出
if((int)lNodes.size() >= N || (int)lNodes.size() == prevSize) break;
}
// 从每个节点中选取响应值最大的一个特征点
vector<cv::KeyPoint> result;
for(auto &node : lNodes) {
auto &vKeys = node.vKeys;
auto best = max_element(vKeys.begin(), vKeys.end(),
[](const cv::KeyPoint &a, const cv::KeyPoint &b) {
return a.response < b.response;
});
result.push_back(*best);
}
return result;
}
关键点:
-
递归分割图像区域,直到节点数达到目标特征点数。
-
每个节点仅保留响应最强的点,确保特征在空间上均匀分布。
3.流程与参数优化
OpenCV ORB:通用实现,包含方向计算、描述子生成等多种功能,代码冗余,速度较慢。
ORB-SLAM3:针对 SLAM 场景做了定制优化:
-
提前分配内存:在构造函数中预先分配金字塔图像和描述子矩阵。
-
精简描述子计算:只计算需要的描述子,避免不必要的拷贝。
-
移除非必要的 OpenCV 通用计算:例如不调用
cv::ORB::create,而是完全自己实现提取流程。
下面是 ORB-SLAM3 的 operator() 入口函数片段,展示了整体流程的优化:
// ORB_SLAM3/src/ORBextractor.cc 中的 operator() 函数
void ORBextractor::operator()(InputArray _image, vector<KeyPoint>& _keypoints,
OutputArray _descriptors)
{
// 1. 构建图像金字塔(直接使用预先分配的内存)
ComputePyramid(_image);
// 2. 用四叉树方法计算每层的特征点(上面已介绍)
vector<vector<KeyPoint> > allKeypoints;
ComputeKeyPointsOctTree(allKeypoints);
// 3. 计算所有特征点的方向(使用灰度质心法)
int nfeatures = 0;
for (int level = 0; level < nlevels; ++level)
nfeatures += allKeypoints[level].size();
// 4. 计算描述子(使用高斯平滑后的图像,并调用自定义的 computeDescriptors 函数)
Mat descriptors;
// 预先分配描述子矩阵
_descriptors.create(nfeatures, 32, CV_8U);
descriptors = _descriptors.getMat();
// 逐层处理,提取描述子
// ...
for (int level = 0; level < nlevels; ++level) {
// 计算该层所有特征点的描述子
computeDescriptors(workingMat, keypointsLevel, descriptors.rowRange(offset, offset+keypointsLevel.size()),
pattern);
}
}
对比 OpenCV 实现(以 OpenCV 4.x 的 orb.cpp 为例,简略):
// OpenCV 的 ORB::detectAndCompute 内部流程:
// 1. 构建金字塔(可能调用 pyrDown)
// 2. 对每层进行 FAST 检测(使用全局阈值)
// 3. 对所有关键点计算 Harris 响应并排序取前 N 个
// 4. 计算方向(灰度质心)
// 5. 计算描述子(类似 ORB-SLAM3)
// 但 OpenCV 的实现中包含了更多通用逻辑(如参数检查、多线程调度、兼容不同数据类型等),且没有四叉树分配步骤。
关键优化点:
-
完全控制内存分配,避免动态分配开销。
-
特征点提取与分配一体化,避免中间数据拷贝。
-
代码精简,只包含 SLAM 需要的功能。
总结
通过上述代码对比,可以清晰地看到 ORB-SLAM3 的 ORB 特征提取器在三个层面的针对性改进:
-
双阈值机制(
ComputeKeyPointsOctTree中的网格级 FAST 检测)保证弱纹理区域也能提取到特征。 -
四叉树均匀化(
DistributeOctTree函数)实现空间分布均匀,避免特征扎堆。 -
流程与参数优化(整体框架设计)提升运行速度,减少不必要的计算。
这些改进使得 ORB-SLAM3 在实时性和鲁棒性上显著优于直接使用 OpenCV 的 ORB 特征。
下面两张图片是分别用opencv进行的ORB特征提取和用ORBSLAM里的ORBextractor进行的ORB特征提取,可以明显看到,ORBSLAM提取出的ORB特征分布更加均匀。
opencv ORB

ORBSLAM ORB

图片参考自:https://www.cnblogs.com/wangnb/p/15843864.html
4.5 ORB_SLAM2_CUDA中的cu文件
https://gitee.com/maxibooksiyi/ORB_SLAM2_CUDA/tree/maxitest_on_OrinNX/src/cuda
这些文件是 ORB-SLAM2_CUDA 项目中 GPU 加速模块的核心组件。下面说明每个文件的作用: 看这些cu文件对应的头文件可以更好理解
1. Allocator_gpu.cu
主要功能:GPU内存管理
2. Cuda.cu
主要功能:提供CUDA设备的同步功能cudaDeviceSynchronize()的作用
这是CUDA运行时API的关键函数:
阻塞主机线程:直到所有之前发出的CUDA操作(内核调用、内存拷贝等)都完成为止
错误检查:确保之前的所有CUDA操作都成功完成
同步点:创建CPU和GPU之间的同步点
3. Fast_gpu.cu
主要功能:GPU加速的FAST角点检测和方向计算
4. Orb_gpu.cu
主要功能:GPU加速的描述子计算
Fast_gpu.cu和Orb_gpu.cu主要参考的opencv里的fast.cu和orb.cu。
https://github.com/opencv/opencv_contrib/blob/4.x/modules/cudafeatures2d/src/cuda/fast.cu
https://github.com/opencv/opencv_contrib/blob/4.x/modules/cudafeatures2d/src/cuda/orb.cu
4.5.1 OpenCV 中的 fast.cu 和 orb.cu 与 ORB_SLAM2_CUDA 中的 Fast_gpu.cu 和 Orb_gpu.cu的异同
OpenCV 中的 fast.cu 和 orb.cu 与 ORB_SLAM2_CUDA 中的 Fast_gpu.cu 和 Orb_gpu.cu 呈现出清晰的继承与定制关系。后者在保持核心算法不变的前提下,进行了针对性重构和优化,以适应 ORB-SLAM2 系统的实时性需求和简洁性要求。以下从相同点和不同点两个维度进行综合对比分析。
4.5.1.1 相同点
1. 核心算法完全一致
-
FAST 角点检测
-
16 邻域采样模式、差分类型判断(
diffType)、掩码计算(calcMask)、角点判别(isKeyPoint)以及二分搜索响应分数(cornerScore)的代码一字不差。 -
常量表
c_table内容完全相同,均用于快速查找连续 9 个像素的序列。
-
-
ORB 描述子生成
-
基于亮度比较的 32 字节描述子生成逻辑(WTA_K=2)完全一致:对 16 对点进行 8 次比较,将结果按位拼成一个字节。
-
采样点坐标的旋转公式:
x' = x*cosθ - y*sinθ, y' = x*sinθ + y*cosθ实现方式相同。
-
-
IC_Angle 方向计算
-
计算图像矩
m01和m10的累加方式、使用c_u_max表、圆周对称处理等代码完全一致(该部分在 OpenCV 中位于orb.cu,在 ORB-SLAM2 中移至Fast_gpu.cu)。
-
2. 底层 CUDA 编程模式相似
-
均使用
PtrStep访问二维图像,使用short2存储关键点坐标(整数精度)。 -
均采用原子操作进行计数(OpenCV 用全局变量
g_counter,ORB-SLAM2 用显式传入的指针counter_ptr)。 -
均包含基于共享内存的规约(
reduce)以合并线程计算结果。
3. 错误检查与流支持
-
均使用
cudaSafeCall或类似宏检查 CUDA 调用。 -
均支持通过
cudaStream_t参数实现异步执行(虽然 OpenCV 中默认同步,但接口留有流参数)。
4.5.1.2 不同点
1. 功能划分与文件组织
|
功能模块 |
OpenCV |
ORB-SLAM2_CUDA |
|---|---|---|
| FAST 检测 | fast.cu
包含完整检测+非极大抑制 |
Fast_gpu.cu
包含检测+非极大抑制+IC_Angle |
| ORB 描述子 | orb.cu
包含 Harris、方向、描述子、排序 |
Orb_gpu.cu
仅包含描述子生成 |
| 方向计算 | orb.cu
中的 |
整合到 |
| 排序与 Harris |
包含在 |
完全移除(ORB-SLAM2 使用 FAST 得分替代) |
2. 并行策略与性能优化
-
FAST 检测
-
OpenCV:每个线程处理 1 个像素,网格大小为
(img.cols-6, img.rows-6)。 -
ORB-SLAM2:每个线程处理 4 个连续行(通过循环展开),大幅提高线程利用率,减少内核启动次数。
-
非极大抑制:OpenCV 使用独立内核后处理;ORB-SLAM2 在检测内核中当场判断是否为局部最大值,避免二次遍历。
-
-
ORB 描述子
-
OpenCV:二维网格
grid.x = divUp(dsize,32),grid.y = divUp(npoints,8),每个线程块处理多个关键点和多个描述子字节。 -
ORB-SLAM2:一维网格,每个关键点独占一个块,块内 32 个线程并行生成 32 字节描述子,简化了索引计算,可能减少全局内存访问延迟。
-
3. 内存与数据管理
-
模式存储
-
OpenCV:将模式数组
pattern_x/pattern_y作为内核参数传入(全局内存)。 -
ORB-SLAM2:使用
__constant__内存存储模式,通过loadPattern提前加载,访问延迟更低。
-
-
关键点数据
-
OpenCV:将位置和角度分开为
loc和angle_数组。 -
ORB-SLAM2:直接使用
KeyPoint结构体(包含位置、角度、尺度等),数据更紧凑,便于与 CPU 端交互。
-
-
计数器
-
OpenCV:全局设备变量
g_counter,需要cudaGetSymbolAddress获取指针。 -
ORB-SLAM2:显式传入计数器指针
counter_ptr,灵活性更高。
-
4. 阈值处理与自适应
-
OpenCV 使用单一阈值进行 FAST 检测。
-
ORB-SLAM2 引入双阈值机制:先用高阈值检测,若无角点则用低阈值再次检测,提高角点数量稳定性,适应不同纹理区域。
5. 封装与易用性
-
OpenCV 提供的是底层函数,用户需自行管理内存、流和同步。
-
ORB-SLAM2 将 GPU 功能封装为C++ 类(
GpuFast、IC_Angle、GpuOrb),在构造/析构中自动分配/释放设备内存,并提供async/join接口,无缝融入 ORB-SLAM2 的多线程架构。
6. 依赖与兼容性
-
OpenCV 代码依赖 OpenCV 自身的数据类型和宏,且通过
#if !defined CUDA_DISABLER控制编译。 -
ORB-SLAM2 代码依赖
helper_cuda.h(NVIDIA 示例常用),并额外引入Utils.hpp,对 OpenCV 的依赖集中在核心数据结构(如GpuMat)。
4.5.1.3 总结:继承与定制的关系
|
项目 |
相似度 |
说明 |
|---|---|---|
| 核心算法 |
100% |
FAST 检测、IC_Angle、描述子生成的数学逻辑完全复用 OpenCV 实现。 |
| 代码结构 |
60% |
文件重新组织,功能模块合并或裁剪,但许多设备函数(如 |
| 性能优化 |
- |
ORB-SLAM2 在并行粒度、内存使用、异步执行方面做了针对性优化。 |
| 功能完整性 |
70% |
ORB-SLAM2 去除了排序、Harris 响应等非必要模块,专注于特征提取核心。 |
ORB-SLAM2_CUDA 中的 GPU 代码是在 OpenCV CUDA 模块基础上的深度定制——保留了全部核心算法,但重构了并行策略、内存布局和封装接口,以实现更高的运行效率和更简洁的集成。两者是源与流的关系。
4.6 ORBextractor.cc
https://gitee.com/maxibooksiyi/ORB_SLAM2_CUDA/blob/maxitest_on_OrinNX/src/ORBextractor.cc
ORBextractor.cc 里面共包含以下六个函数
-
ORBextractor构造函数
初始化尺度金字塔参数
计算每层金字塔应提取的特征点数量
加载ORB模式点和UMax表到GPU
-
operator() 主流程
输入图像检查和金字塔构建
八叉树关键点提取
异步GPU描述子计算流水线
关键点尺度坐标调整和结果收集
void ORBextractor::operator()( InputArray _image, InputArray _mask, vector<KeyPoint>& _keypoints,
OutputArray _descriptors)
{
PUSH_RANGE("ORBextractor", 0);
if(_image.empty())
return;
Mat image = _image.getMat();
assert(image.type() == CV_8UC1 );
// Pre-compute the scale pyramid
ComputePyramid(image);
vector<vector<KeyPoint>> allKeypoints;
ComputeKeyPointsOctTree(allKeypoints);
Mat descriptors;
int nkeypoints = 0;
for (int level = 0; level < nlevels; ++level) {
nkeypoints += (int)allKeypoints[level].size();
}
if( nkeypoints == 0 ) {
_descriptors.release();
} else {
_descriptors.create(nkeypoints, 32, CV_8U);
descriptors = _descriptors.getMat();
}
_keypoints.clear();
_keypoints.reserve(nkeypoints);
int offset = 0;
for (int level = 0; level < nlevels; ++level)
{
vector<KeyPoint>& keypoints = allKeypoints[level];
int nkeypointsLevel = (int)keypoints.size();
if(nkeypointsLevel==0)
continue;
// preprocess the resized image
cv::cuda::GpuMat &gMat = mvImagePyramid[level];
// Compute of Gaussion Blur is pipelined into `ComputeKeyPointsOctTree()`
// Compute the descriptors
// Pipeline the CPU and GPU work
if (level == 0) {
gpuOrb.launch_async(gMat, keypoints.data(), keypoints.size());
}
Mat desc = descriptors.rowRange(offset, offset + nkeypointsLevel);
gpuOrb.join(desc);
offset += nkeypointsLevel;
if (level + 1 < nlevels) {
vector<KeyPoint>& keypoints = allKeypoints[level+1];
gpuOrb.launch_async(mvImagePyramid[level+1], keypoints.data(), keypoints.size());
}
// Scale keypoint coordinates
// TODO: This part shall be done by GPU
if (level != 0)
{
float scale = mvScaleFactor[level]; //getScale(level, firstLevel, scaleFactor);
for (vector<KeyPoint>::iterator keypoint = keypoints.begin(),
keypointEnd = keypoints.end(); keypoint != keypointEnd; ++keypoint)
keypoint->pt *= scale;
}
// And add the keypoints to the output
_keypoints.insert(_keypoints.end(), keypoints.begin(), keypoints.end());
}
POP_RANGE;
}
-
ComputePyramid函数
GPU内存管理:首次调用时分配金字塔内存
异步流水线:使用CUDA流实现图像金字塔构建的并行处理
边界扩展:为每层图像添加反射边界
void ORBextractor::ComputePyramid(Mat image) {
if (mvImagePyramidAllocatedFlag == false) {
// first frame, allocate the Pyramids
for (int level = 0; level < nlevels; ++level) {
float scale = mvInvScaleFactor[level];
Size sz(cvRound((float)image.cols*scale), cvRound((float)image.rows*scale));
Size wholeSize(sz.width + EDGE_THRESHOLD*2, sz.height + EDGE_THRESHOLD*2);
cuda::GpuMat target(wholeSize, image.type(), cuda::gpu_mat_allocator);
// cuda::GpuMat target(wholeSize, image.type());
mvImagePyramidBorder.push_back(target);
mvImagePyramid.push_back(target(Rect(EDGE_THRESHOLD, EDGE_THRESHOLD, sz.width, sz.height)));
}
mvImagePyramidBorder.resize(nlevels);
mvImagePyramid.resize(nlevels);
mpGaussianFilter = cv::cuda::createGaussianFilter(mvImagePyramid[0].type(), mvImagePyramid[0].type(), Size(7, 7), 2, 2, BORDER_REFLECT_101);
mvImagePyramidAllocatedFlag = true;
}
for (int level = 0; level < nlevels; ++level) {
float scale = mvInvScaleFactor[level];
Size sz(cvRound((float)image.cols*scale), cvRound((float)image.rows*scale));
cuda::GpuMat target(mvImagePyramidBorder[level]);
// Compute the resized image
if (level != 0) {
cuda::resize(mvImagePyramid[level-1], mvImagePyramid[level], sz, 0, 0, INTER_LINEAR, mcvStream);
cuda::copyMakeBorder(mvImagePyramid[level], target, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101, cv::Scalar(), mcvStream);
} else {
cuda::GpuMat gpuImg(image);
cuda::copyMakeBorder(gpuImg, target, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101, cv::Scalar(), mcvStream);
}
}
mcvStream.waitForCompletion();
}
-
ComputeKeyPointsOctTree函数
多层级处理:对每个金字塔层级分别处理
GPU异步流水线:
FAST关键点检测(当前层) 方向计算和高斯模糊(上一层) 实现计算与数据传输重叠八叉树关键点分布:确保关键点在图像中均匀分布
void ORBextractor::ComputeKeyPointsOctTree(vector<vector<KeyPoint>>& allKeypoints)
{
allKeypoints.resize(nlevels);
const int minBorderX = EDGE_THRESHOLD-3;
const int minBorderY = minBorderX;
for (int level = 0; level < nlevels; ++level)
{
const int maxBorderX = mvImagePyramid[level].cols-EDGE_THRESHOLD+3;
const int maxBorderY = mvImagePyramid[level].rows-EDGE_THRESHOLD+3;
vector<cv::KeyPoint> vToDistributeKeys;
vToDistributeKeys.reserve(nfeatures*10);
// software pipelining
if (level == 0) {
gpuFast.detectAsync(mvImagePyramid[level].rowRange(minBorderY, maxBorderY).colRange(minBorderX, maxBorderX));
}
gpuFast.joinDetectAsync(vToDistributeKeys);
if (level + 1 < nlevels) {
const int maxBorderX = mvImagePyramid[level+1].cols-EDGE_THRESHOLD+3;
const int maxBorderY = mvImagePyramid[level+1].rows-EDGE_THRESHOLD+3;
gpuFast.detectAsync(mvImagePyramid[level+1].rowRange(minBorderY, maxBorderY).colRange(minBorderX, maxBorderX));
}
// compute orientations and Gaussian Blur 也就是方向计算和高斯模糊
if (level != 0) {
ic_angle.launch_async(mvImagePyramid[level-1], allKeypoints[level-1].data(), allKeypoints[level-1].size(), HALF_PATCH_SIZE, minBorderX, minBorderY, level-1, PATCH_SIZE * mvScaleFactor[level-1]);
cv::cuda::GpuMat &gMat = mvImagePyramid[level-1];
mpGaussianFilter->apply(gMat, gMat, ic_angle.cvStream());
}
vector<KeyPoint> & keypoints = allKeypoints[level];
keypoints.reserve(nfeatures);
PUSH_RANGE("DistributeOctTree", 3);
keypoints = DistributeOctTree(vToDistributeKeys, minBorderX, maxBorderX, minBorderY, maxBorderY,mnFeaturesPerLevel[level], level);
POP_RANGE;
// Add border to coordinates and scale information
// Merged into IC_Angle
// compute orientations
// PS. I think this is a bug ? Seems like the launch and join needs to be in the same loop iteration else it breaks
if (level != 0) {
ic_angle.join(allKeypoints[level-1].data(), allKeypoints[level-1].size());
}
} // loop every level
// compute orientations
cv::cuda::GpuMat &gMat = mvImagePyramid[nlevels-1];
ic_angle.launch_async(gMat, allKeypoints[nlevels-1].data(), allKeypoints[nlevels-1].size(), HALF_PATCH_SIZE, minBorderX, minBorderY, nlevels-1, PATCH_SIZE * mvScaleFactor[nlevels-1]);
mpGaussianFilter->apply(gMat, gMat, ic_angle.cvStream());
ic_angle.join(allKeypoints[nlevels-1].data(), allKeypoints[nlevels-1].size());
}
-
DistributeOctTree函数
自适应网格划分:递归划分图像区域直到满足停止条件
停止条件:
节点数 ≥ 目标特征点数 所有节点都只有一个关键点 达到最大迭代次数关键点筛选:每个节点保留响应值最大的关键点
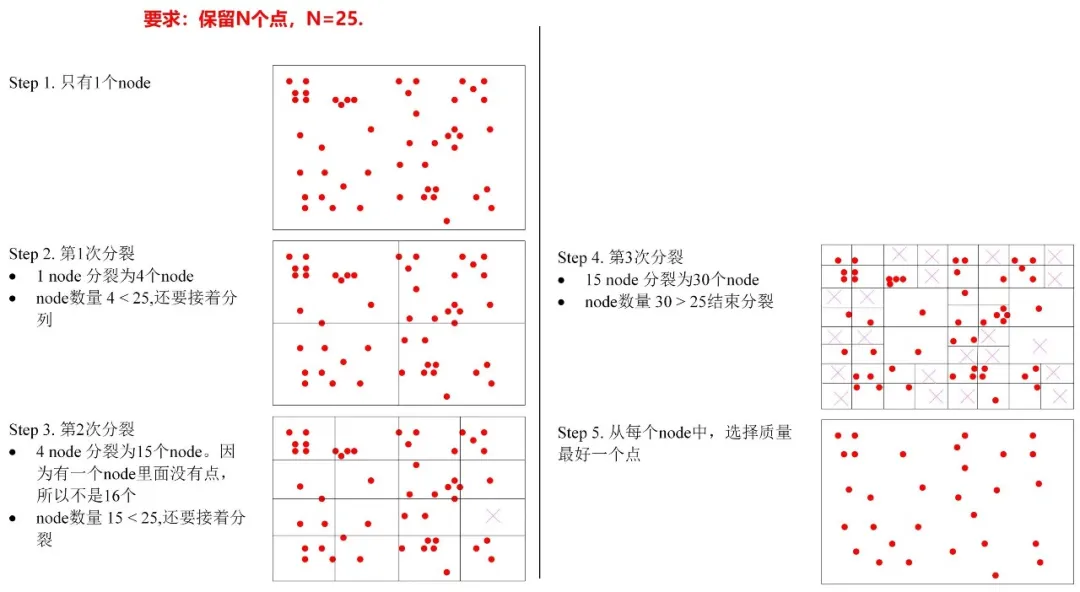
总结下就是:不断将存在特征点的图像区域进行4等分,直到分出了足够多的分区,每个分区内只保留响应值最大的特征点.
-
DivideNode函数
四叉树划分:将节点均匀分为4个子区域
关键点分配:根据关键点坐标分配到对应子节点
终止标记:标记只有一个关键点的节点
这几个函数的关系是,核心是operator()函数,它包含了全部流程,operator()函数调用了ComputeKeyPointsOctTree函数和ComputePyramid函数,ComputeKeyPointsOctTree函数调用了DistributeOctTree函数,DistributeOctTree函数调用了DivideNode函数。
operator()函数为特征点提取中的主函数,也是最重要的一个函数,这是一个仿函数。之所以说本函数是主函数,因为他直接或间接的调用了除构造函数外的所有函数,它完整的实现了特征提取功能(金字塔构建、给每层金字塔分配特征点数、给金字塔每层图像扩充图像边界,提取/分配/筛选特征点,计算特征点的方向信息和描述子等)

仿函数又称为函数对象是一个能行使函数功能的类,仿函数是定义了一个含有operator()成员函数的对象,可以视为一个一般的函数,只不过这个函数功能是在一个类中的运算符operator()中实现,是一个函数对象。
ORBextractor::operator()函数被调用使用的地方在ORB_SLAM2_CUDA\src\Frame.cc的Frame::ExtractORB函数里,这也是ORBextractor类在整个项目中唯一被调用的地方。
void Frame::ExtractORB(int flag, const cv::Mat &im)
{
if(flag==0)
(*mpORBextractorLeft)(im,cv::Mat(),mvKeys,mDescriptors);
else
(*mpORBextractorRight)(im,cv::Mat(),mvKeysRight,mDescriptorsRight);
}4.7 GPU加速部分
4.7.1 图像金字塔构建
这部分代码在ComputePyramid函数里
GPU操作:
cuda::resize(): 图像下采样
cuda::copyMakeBorder(): 图像边界扩展
在ORBextractor::ComputePyramid函数里,Pyramid就是金字塔的意思
cuda::resize(mvImagePyramid[level-1], mvImagePyramid[level], sz, 0, 0, INTER_LINEAR, mcvStream);
cuda::copyMakeBorder(mvImagePyramid[level], target, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101, cv::Scalar(), mcvStream);
注意这里仅仅指构建金字塔也就是图片的缩放用了GPU,金字塔层与层之间还是串行处理的,不是每层同时并行提取特征点。
用copyMakeBorder的原因:
保护边缘特征点的检测与描述
FAST角点检测需要比较中心像素与周围半径3的圆环上的16个像素。若不填充,图像边缘的特征点会因采样点超出图像范围而被直接丢弃。
BRIEF描述子计算前需对图像进行高斯模糊,该操作也需要读取特征点邻域像素。
EDGE_THRESHOLD = 19 大于FAST的半径3,额外预留的16像素正是为高斯模糊等滤波操作提供的安全边界。
边界反射(BORDER_REFLECT_101)的选择
该模式将边缘外的像素“镜像”为内部像素(如 abcdefg → gfedcba,但中心元素不重复),相比单纯复制边界像素(BORDER_REPLICATE)或填零(BORDER_CONSTANT),能更自然地延续图像纹理,避免在滤波时引入突兀的假边缘。
( https://mp.weixin.qq.com/s/c_ybCMJ7q4bnCBb3CHSRoQ )函数void ORBextractor::ComputePyramid(cv::Mat image)逐层计算图像金字塔,对于每层图像进行以下两步: 1)先进行图片缩放,缩放到mvInvScaleFactor对应尺寸. 2)在图像外补一圈厚度为19的padding(提取FAST特征点需要特征点周围半径为3的圆域,计算ORB描述子需要特征点周围半径为16的圆域). 下图表示图像金字塔每层结构: 1)深灰色为缩放后的原始图像. 2)包含绿色边界在内的矩形用于提取FAST特征点. 3)包含浅灰色边界在内的整个矩形用于计算ORB描述子.

4.7.2 FAST关键点检测
gpuFast.detectAsync(mvImagePyramid[level].rowRange(minBorderY, maxBorderY).colRange(minBorderX, maxBorderX));4.7.3 方向计算
ic_angle.launch_async(mvImagePyramid[level-1], allKeypoints[level-1].data(), allKeypoints[level-1].size(), HALF_PATCH_SIZE, minBorderX, minBorderY, level-1, PATCH_SIZE * mvScaleFactor[level-1]);4.7.4 高斯模糊
mpGaussianFilter = cv::cuda::createGaussianFilter(mvImagePyramid[0].type(), mvImagePyramid[0].type(), Size(7, 7), 2, 2, BORDER_REFLECT_101); //这句在ComputePyramid函数里
mpGaussianFilter->apply(gMat, gMat, ic_angle.cvStream());
4.7.5 ORB描述子计算
gpuOrb.launch_async(mvImagePyramid[level+1], keypoints.data(), keypoints.size());和ORB特征点的提取步骤做对比,就可以很好明白上述含有GPU的步骤,FAST角点,方向计算,高斯模糊(方向计算和高斯模糊都是为了进行描述子计算),描述子计算,都对应在里面了。就四叉树均匀化是CPU运行,其他基本是在GPU上,还有需要注意的是金字塔层与层之间是串行处理的,就是一层处理完再处理下一层,单单一层内的特征点提取什么的才用到GPU。
再本质地概括,就是提取角点+计算描述子(方向计算和高斯模糊都是为了计算描述子),用的GPU,因为每个特征点的处理都相互独立,这个很好理解,另外再加个金字塔构建用GPU,这个也好理解。
其中高斯模糊和创建金字塔的下采样是直接调用的cv::cuda里的函数。
5 参考资料
3D视觉工坊 ORB-SLAM2代码详解:特征点提取器ORBextractor https://mp.weixin.qq.com/s/c_ybCMJ7q4bnCBb3CHSRoQ
ORB特征提取 https://www.cnblogs.com/wangnb/p/15843864.html
ORB-SLAM3保姆级教程:详解特征点提取 https://blog.csdn.net/CV_Autobot/article/details/131606977
deepseek https://chat.deepseek.com/

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)