基于 SGLang Chunked-Prefill 支持 Block-Wise Diffusion LLM 框架
在使用 0.95 阈值解码时,LLaDA2.0-flash-CAP 实现了 500 TPS 的速度,明显优于普通版的 LLaDA2.0-flash(383 TPS),并在小批量处理场景下,比自回归基准模型(分别为 258 TPS 和 237 TPS)快了约 1.9 倍。因此,实现高效的批处理成为我们必须解决的关键问题,核心改动是让 SGLang 能够在单个计算周期内,同时处理来自多个请求的扩散块,
在蚂蚁集团,我们始终致力于提升大规模人工智能的效率与能力。我们很高兴地宣布在与 SGLang 社区合作中引入了对扩散大语言模型(dLLM)的支持。通过利用现有的分块预填充(Chunked-Prefill)机制,该方案实现了:
- 无缝集成:
内置 SGLang 框架,不改动核心架构
- 性能继承:
该框架受益于 SGLang 现有的推理优化技术
- 极高灵活性:
为用户定义扩散解码算法提供了充分的灵活性
英文 Blog
- Power Up Diffusion LLMs: Day‑0 Support for LLaDA 2.0
https://lmsys.org/blog/2025-12-19-diffusion-llm/
- RFC: Block Diffusion Large Language Model (dLLM) Framework In SGLang
https://github.com/sgl-project/sglang/issues/12766
背景:新挑战的出现
近期,LLaDA 的发布在学界和业界引起广泛关注。蚂蚁集团与中国人民大学合作研究发现,dLLM 凭借其独特的执行方式,在模型效果上已能够媲美传统的自回归(AR)模型。更重要的是,dLLM 采用并行解码策略,推理速度显著提升。dLLM 用更多的算力换取了更低的延迟体验,在低延迟的应用场景中表现突出。
同时,随着 dLLM 参数规模的不断增长,我们也观察到了其与 AR 大模型类似的 Scaling Law。为了追求更强大的 dLLM,蚂蚁团队训练了拥有 100B 参数的 LLaDA2.0-flash 模型(https://huggingface.co/papers/2512.15745)。在训练 LLaDA2.0-flash 的过程中,我们面临了诸多 AI 基础设施方面的工程挑战,尤其是模型评测和强化学习(RL)后训练阶段的效率与稳定性的问题。
此前,尽管已有一些 dLLM 推理引擎,例如 Fast-dLLM 等在算法调试和扩散解码方法验证方面表现非常优秀,但在支撑大规模 dLLM 的评测与后训练方面仍缺乏生产级的服务能力,例如在批处理、请求调度、RL 生态整合及并行能力等方面尚有欠缺。
而 SGLang 作为当前主流的 LLM 推理引擎,在工程水位、技术先进性和生态完整性上优势明显:
-
生产稳定:已在数千家企业中部署,具备稳定可靠的工程基础;
-
技术领先:内置大量先进推理优化技术,社区持续贡献新的优化方案;
-
生态完善:与 RL 后训练环节高度集成。
此前,SGLang 仅支持传统的自回归计算模式,尚未适配扩散语言模型的计算方式。因此,蚂蚁集团 DeepXPU 团队与 SGLang dLLM 小组进行合作,来解决核心挑战:如何在保持 SGLang 原有架构完整的前提下,引入对扩散大语言模型的支持,来充分利用 SGLang 已有的优化能力,站在巨人的肩膀上。
方案设计:发现并利用现有路径
关于当前 dLLM 的发展趋势,我们观察到两个关键变化:由于全向注意力扩散计算开销大、KV Cache 利用率低,主流 dLLM 正逐渐转向块扩散解码架构(Block Diffusion)。有意思的是,块扩散的计算模式与 SGLang 现有的“分块预填充(Chunked Prefill)”机制非常相似。
系统架构
我们目前的方案,正是近似 SGLang 的 Chunked Prefill 执行流,为块扩散语言模型提供计算支持,从而使 dLLM 能够无缝融入 SGLang 现有生态。
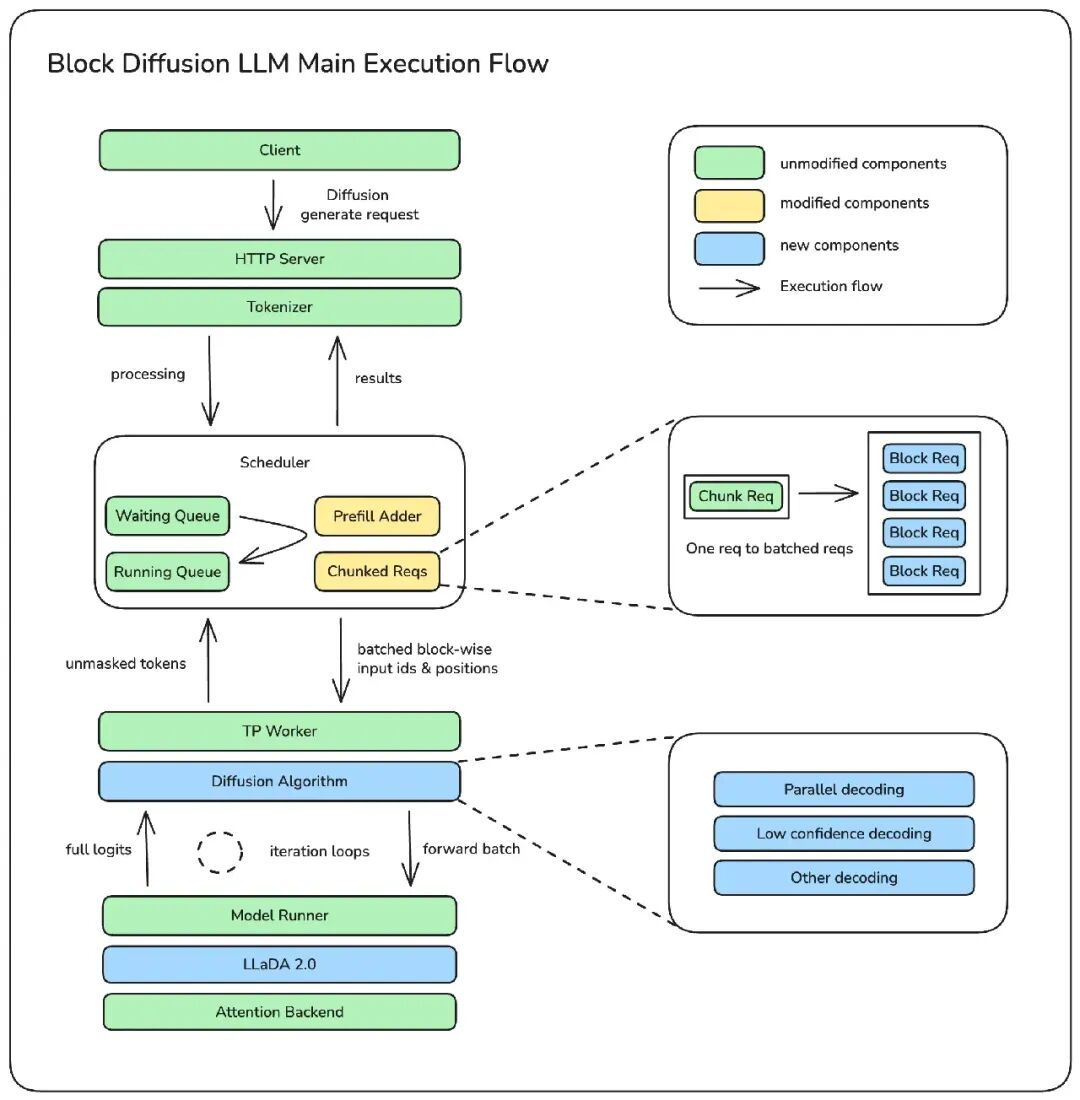
如图所示,这一方案对 SGLang 框架本身的改动非常小,核心抽象和执行流程基本保持不变。近似现有的 Chunked-Prefill 机制,重点对资源管理器(Prefill Adder)和调度实现进行了改造适配。
在 SGLang 中,Chunked Prefill 原本是为了最大化 GPU 利用率而设计,因此 Prefill 对于请求单个块的大小通常设置得较大(根据 GPU 型号,长度设置在 2K 到 16K 之间)。当序列足够长时,一次只处理一个请求。
但dLLM 的解码过程有所不同:它是在“块”级别上对请求序列进行分割。以 LLaDA2.0 为例,每个块的大小仅为 32 个 token。如果继续沿用 SGLang 一次处理一个大请求的做法,GPU 性能将无法得到有效利用。因此,实现高效的批处理成为我们必须解决的关键问题,核心改动是让 SGLang 能够在单个计算周期内,同时处理来自多个请求的扩散块,从而显著提升计算效率。
此外,在实际的解码执行环节,我们在 TP Worker 和 Model Runner 之间新增了一个扩散算法抽象层。当系统识别出当前模型为扩散模型时,执行流程便会自动转入这一专用分支,调用对应的扩散算法来完成整个块(Block)的解码。引入这一算法抽象层,使得底层工程优化对上层变得透明。算法工程师无需再关注具体的底层实现细节,只需在此抽象层内专注于编写他们期望的解码算法逻辑即可。
注意力掩码 (Attention Mask)
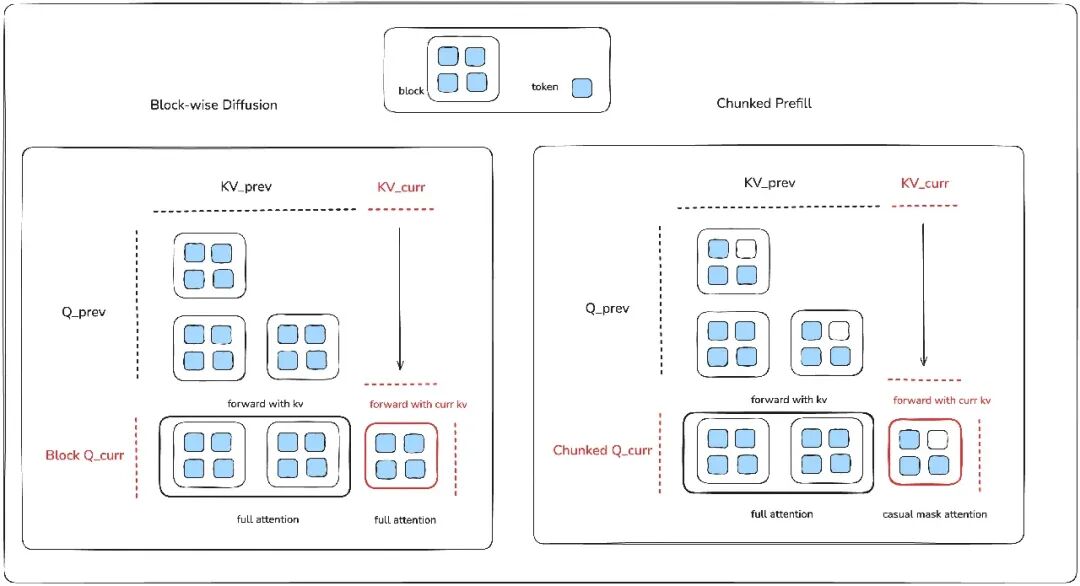
在单次模型前向传递中,块扩散与分块预填充最大的区别体现在注意力掩码的处理上。块扩散采用的是块级因果掩码,而 AR 模型的分块预填充则使用的是传统的逐 token 因果掩码。
我们可以将块扩散理解为对分块预填充机制的一种扩展。在注意力计算环节,一次前向传递主要分为两部分,最终将两者的输出拼接起来:
-
上下文查询:使用当前块的查询向量 Q_curr 对已有的 KV Cache 进行双向注意力计算。这一步的目标是让当前块能够充分感知历史上下文信息,对块扩散和分块预填充来说,这部分计算逻辑是相同的。
-
块内查询:使用 Q_curr 与当前块自身的键值(KV)进行计算。
1. 块扩散在此环节使用双向注意力,允许块内 token 之间相互关注;
2. 而分块预填充则必须使用因果掩码,保持自回归的先后顺序约束。
我们可以借助一个几何图形来直观理解:如果将 Q_curr 对应的注意力掩码可视化,那么分块预填充(因果掩码)呈现为梯形或三角形,而块扩散(双向注意力)则对应一个完整的矩形。
效果展示
来看一段 LLaDA2.0-flash-CAP(100B / BF16)与 gpt-oss-120B(117B / MXFP4)在流式输出时的对比演示。测试任务是用 10 种编程语言分别实现快速排序,这类任务比较适合 dLLM 发挥优势。实验在 8×H20 硬件上进行,LLaDA2.0-flash-CAP 使用我们适配的 SGLang dLLM(TP8)运行,gpt-oss-120B 则在相同硬件上采用 SGLang 标准自回归流程。从结果可见,在此场景下 LLaDA2.0-flash-CAP 实现了935 tokens/s 的吞吐量,显著高于对照模型的 263 tokens/s。
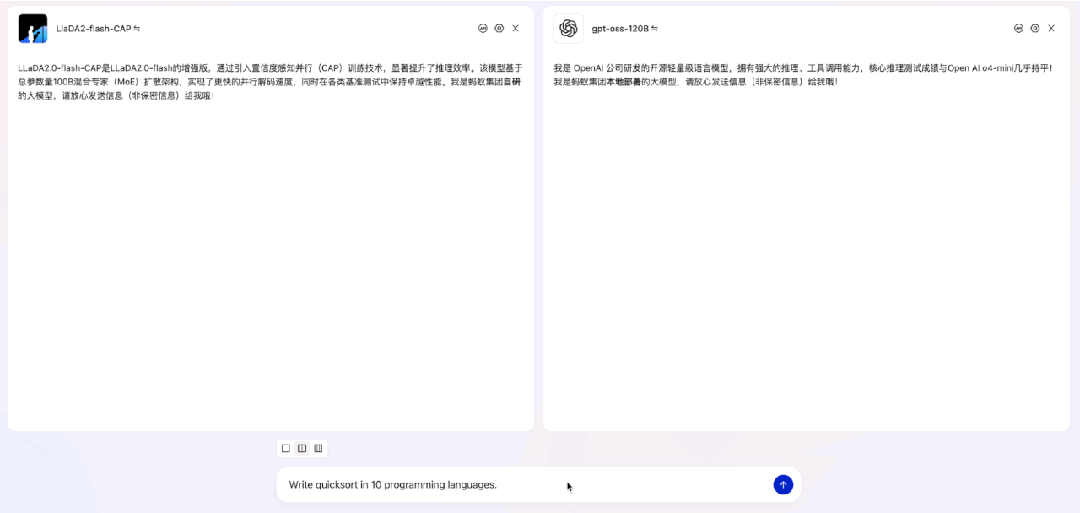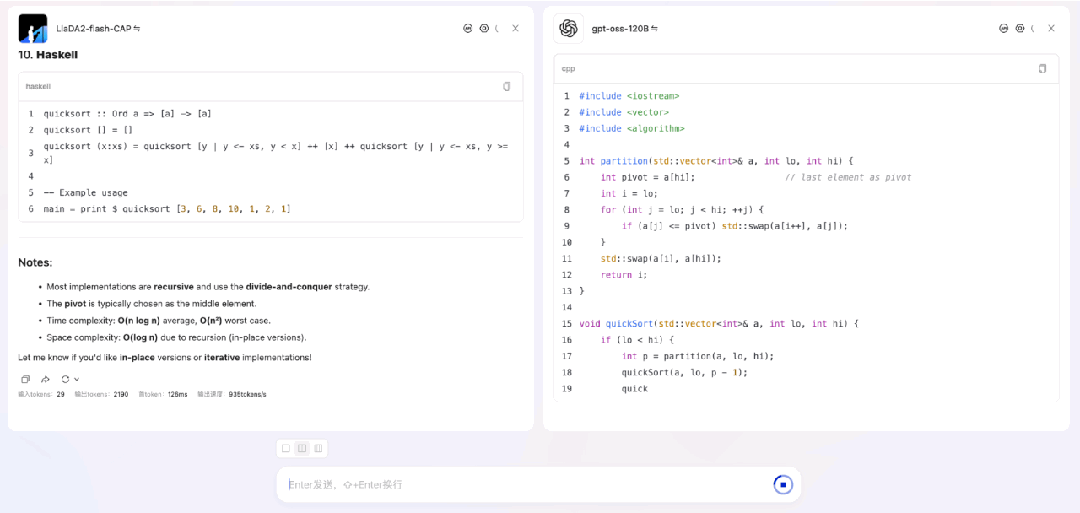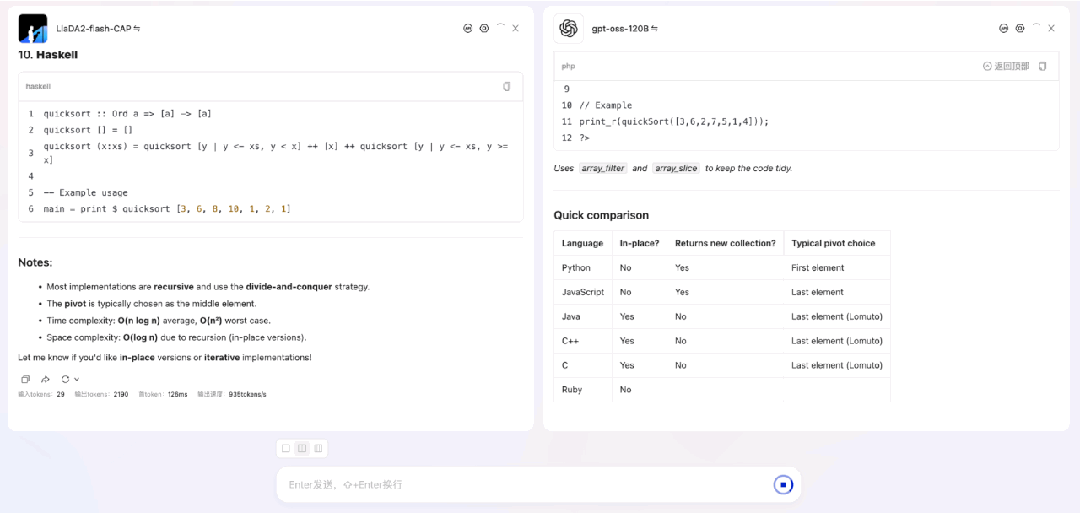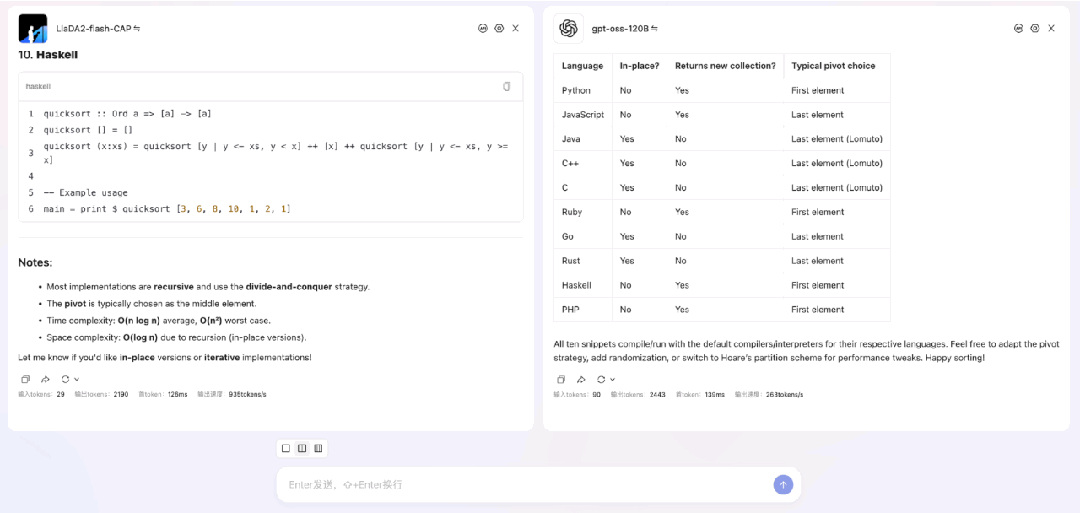
需要说明的是,SGLang dLLM 支持与自回归模型相同的流式输出方式,区别在于它每次输出的是一个完整块(例如 32 个token),而非单个 token。
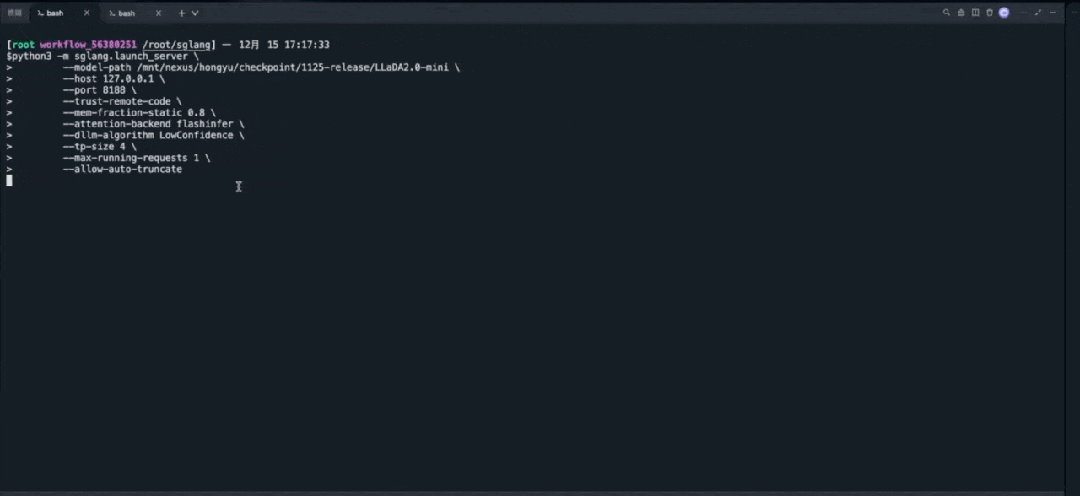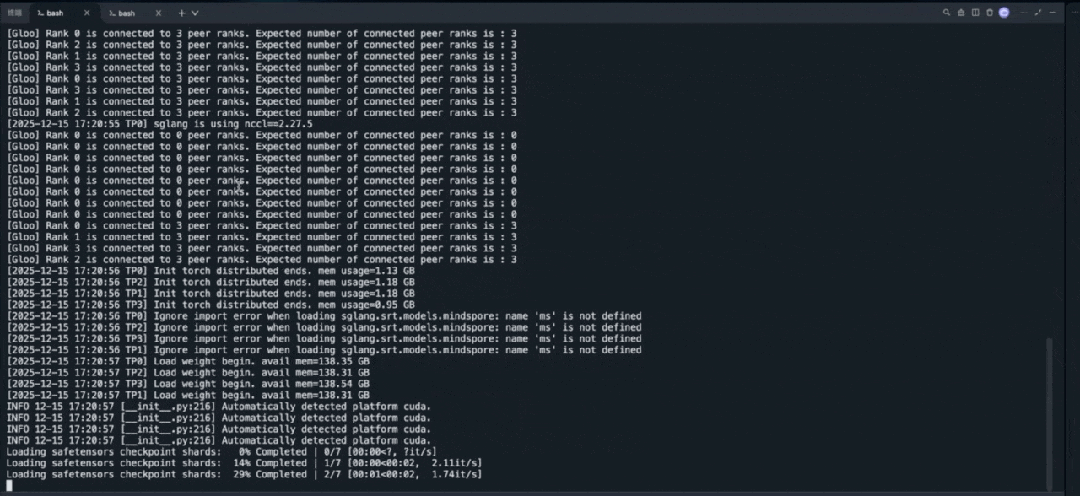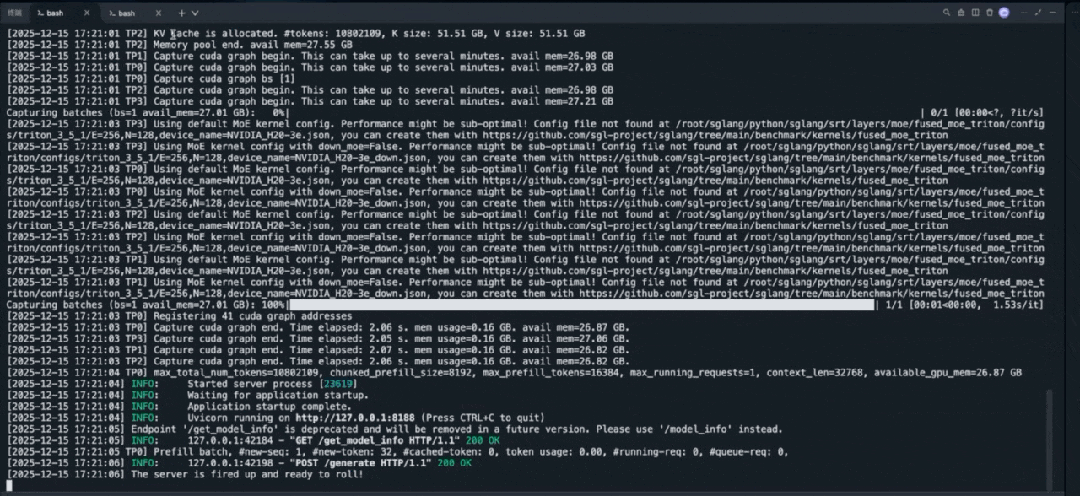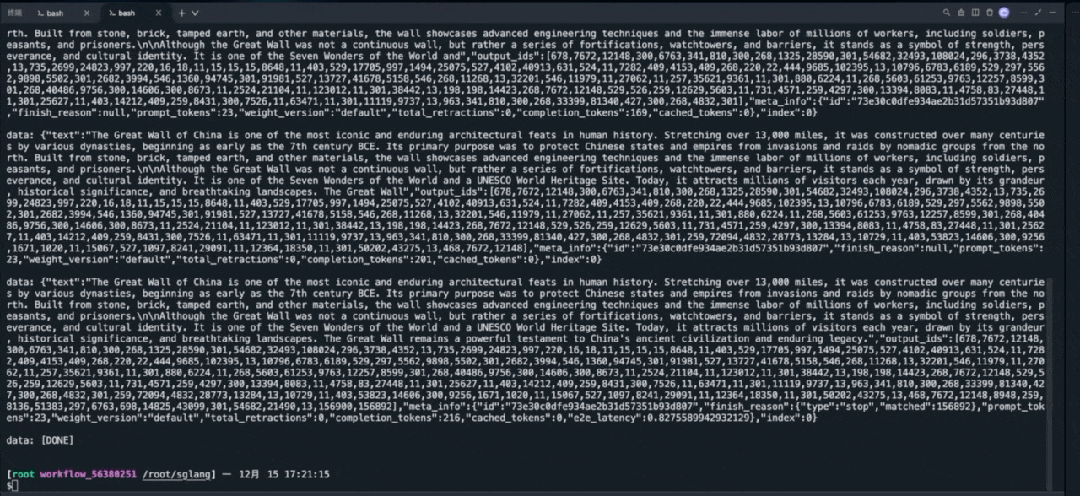
如何使用
启动命令示
python3 -m sglang.launch_server \
--model-path inclusionAI/LLaDA2.0-mini \ # 示例 HF/本地路径
--dllm-algorithm LowConfidence \
--dllm-algorithm-config ./config.yaml \ # 可选。若未设置则使用算法默认值。
--host 0.0.0.0 \ --port 30000注意:使用 --dllm-algorithm-config 对所选的 --dllm-algorithm 算法进行高级配置。此功能实现了解耦了算法配置和启动参与,允许用户自定义灵活的算法参数。
客户端代码片段示例
与其他支持的模型一样,dLLM 可以通过 REST API 或离线引擎 API 使用。
SGLang 服务器模式:使用 Curl 命令发送生成请求
curl -X POST "[http://127.0.0.1:30000/generate](http://127.0.0.1:30000/generate)" \
-H "Content-Type: application/json" \
-d '{
"text": [
"<role>SYSTEM</role>detailed thinking off<|role_end|><role>HUMAN</role>写出从1到128的数字<|role_end|><role>ASSISTANT</role>",
"<role>SYSTEM</role>detailed thinking off<|role_end|><role>HUMAN</role>简要介绍长城<|role_end|><role>ASSISTANT</role>"
],
"stream": true,
"sampling_params": {
"temperature": 0,
"max_new_tokens": 1024
}
}'SGLang 引擎模式:
-
import sglang as sgl def main(): llm = sgl.Engine(model_path="inclusionAI/LLaDA2.0-mini", dllm_algorithm="LowConfidence", max_running_requests=1, trust_remote_code=True) prompts = [ "<role>SYSTEM</role>detailed thinking off<|role_end|><role>HUMAN</role>简要介绍长城<|role_end|><role>ASSISTANT</role>" ] sampling_params = { "temperature": 0, "max_new_tokens": 1024, } outputs = llm.generate(prompts, sampling_params) print(outputs) if __name__ == '__main__': main()
性能表现
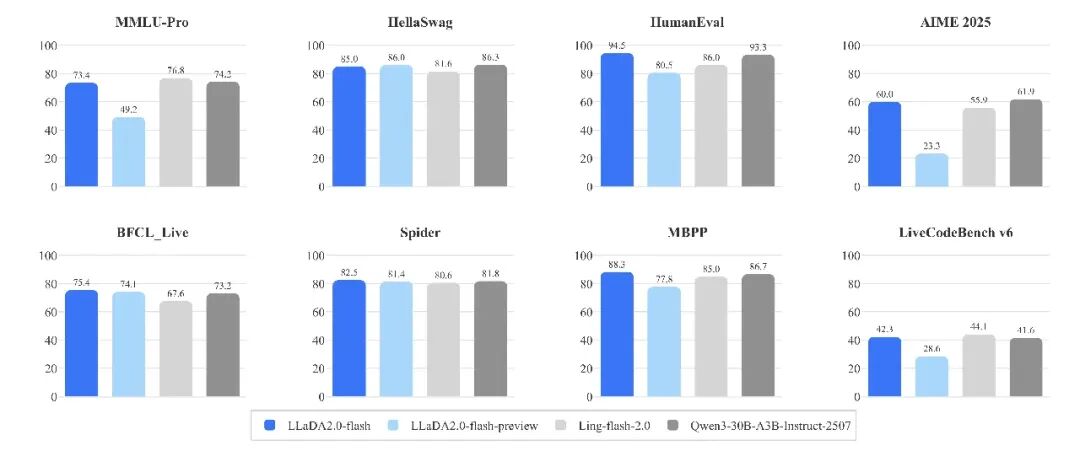
我们在一系列标准任务上,将 LLaDA2.0-flash 与同等规模的先进自回归模型(AR)进行了性能对比测试。整体来看,LLaDA2.0 在推理任务上的表现能够达到与同类规模模型相当的水平,同时在吞吐速度上具备明显优势。
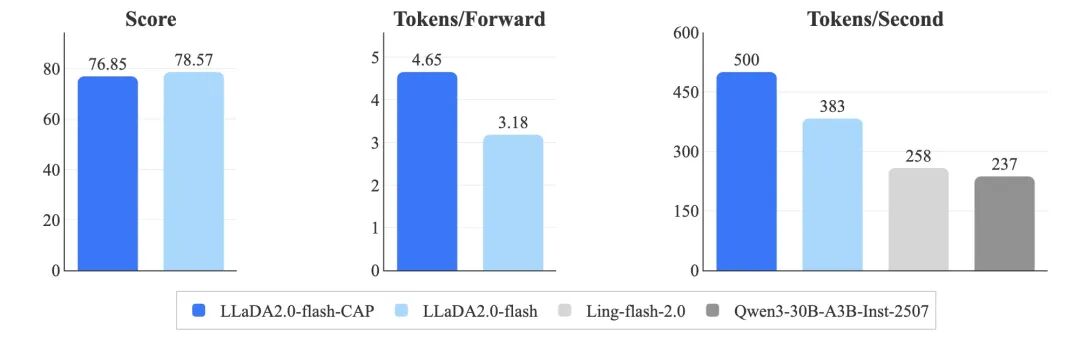
以下是 LLaDA2.0‑flash 两项辅助性能指标的具体情况:
-
在 12 项标准测试中,我们比较了是否采用“置信度感知并行”(CAP)训练的模型平均得分,以及单次前向推理能生成的 token 数量(TPF)。
-
LLaDA2.0‑flash 在 HumanEval、MBPP、GSM8K 和 CRUXEval 四个测试集上,与规模相当的自回归模型进行了推理速度(tokens/秒)的对比。
所有测试均在统一环境中进行(SGLang + TP8 + H20),保证了扩散型大语言模型与自回归基准模型之间的公平比较。在使用 0.95 阈值解码时,LLaDA2.0-flash-CAP 实现了 500 TPS 的速度,明显优于普通版的 LLaDA2.0-flash(383 TPS),并在小批量处理场景下,比自回归基准模型(分别为 258 TPS 和 237 TPS)快了约 1.9 倍。
发展路线图 (Roadmap)
当前实现已完全支持以下功能:
-
块扩散 LLM 框架主逻辑
-
KV Cache 支持
-
LLaDA-2.0-mini/flash 模型集成
-
自定义解码算法
-
流式 I/O 能力
-
Batching 批处理支持
-
张量并行 / 专家并行
-
CUDA Graph
中长期路线图
近期 Roadmap:https://github.com/sgl-project/sglang/issues/14199
-
支持更多 SGLang 现有的系统优化技术
-
集成更多通用的扩散解码算法(如 Fast-dLLM v2)
-
兼容非块扩散的 dLLM 模型(如 LLaDA & RND1)
参考文献
-
LLaDA1 技术报告:
https://arxiv.org/pdf/2502.09992 -
LLaDA2 技术报告:
https://huggingface.co/papers/2512.15745 -
Fast-dLLM v2 技术报告:
https://arxiv.org/pdf/2509.26328
致谢
此项工作离不开以下多方团队的紧密协作:
-
蚂蚁集团 DeepXPU 团队: 李泽寰, 别体伟, 江忠辉, 姚菁华, 高玉嵩, 龚明亮, 谈鉴锋
-
蚂蚁集团 inclusionAI 团队: 陈琨, 黄泽楠, 刘琳, 陈福元, 杜仑, 郑达
-
SGLang dLLM 团队: 姚锦炜, Mick Qian, 尹良升, BBuf, 朱邦华, 赵晨阳
-
NVIDIA Fast-dLLM 团队: 吴成岳, 张浩, 谢恩泽, 韩松
关于我们
蚂蚁集团 DeepXPU 团队致力于:
-
Software & Hardware Co-Design:深入分析 GPU 等AI芯片硬件架构,打磨极致的算子与显存优化技术,优化大模型引擎,构建异构虚拟化能力。通过系统建设优化,计算效率逼近硬件性能极限,构建面向大模型的 AI 系统生态 和 提升智算集群效率。
-
Algorithm & System Co-Design:从系统的角度,和算法团队紧密配合,共同探索大模型结构和范式创新,面向大规模 AI 应用场景进行系统级优化与创新。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)