解决LLM推理“脑裂”难题:Kubernetes LeaderWorkerSet(LWS)组件在大模型推理部署中的应用
摘要:Google开源的LeaderWorkerSet(LWS)解决了Kubernetes在LLM分布式推理场景中的痛点。传统Deployment和StatefulSet难以满足模型推理对Pod协同和弹性的需求,而LWS通过组级生命周期管理(1个Leader+多个Worker的副本组架构)、LeaderReady启动策略及独占拓扑功能,完美适配vLLM等框架。LWS支持原子化扩缩容、版本一致性保障
导读:
在大规模语言模型(LLM)推理场景中,张量并行(TP)与流水线并行(PP)已成为标配,这要求多节点、多GPU必须像“连体婴”一样协同工作 。然而,传统的Kubernetes工作负载却难以应对这一需求:Deployment无法保证Pod间的版本一致性,容易导致服务“脑裂”;StatefulSet严格的顺序重建策略又限制了高并发下的快速弹性 。
如何在Kubernetes上实现以“组”为单位的原子化管理?Google开源的 LeaderWorkerSet (LWS) 给出了解法。本文将深入拆解LWS的架构原理,探讨其如何通过组级生命周期管理、LeaderReady启动策略及独占拓扑功能,完美适配vLLM等分布式推理框架。
大规模语言模型(LLM)推理对计算资源要求较高,得靠多节点、多GPU的分布式计算架构来撑场面——通过Tensor Parallelism(张量并行)把模型参数拆到不同GPU上,再用Pipeline Parallelism(流水线并行)给不同节点分配计算步骤,最终实现多设备齐心协力搞推理。不过传统的Kubernetes工作负载虽然能搭起基础部署框架,但面对分布式推理的核心需求时,短板就挺明显了。而LeaderWorkerSet组件,刚好能精准解决这些麻烦事。
一、传统Kubernetes工作负载的局限性
Deployment和StatefulSet是Kubernetes里最常用的两种工作负载,但放到LLM分布式推理这个场景里,就有点“水土不服”了,很难满足高性能、高弹性的核心要求:
Deployment:Deployment本来是为无状态应用设计的,临时拿来部署LLM推理也不是不行,但它管不好Pod之间的“协作关系”和统一的生命周期。比如滚动更新的时候,它默认一个一个Pod更,很容易出现新版本Pod都跑起来了,老版本还在那儿干活的情况。可Tensor Parallelism架构下,所有Pod得一起加载完整模型参数才能Ready,版本不一致,服务可用性肯定受影响。
StatefulSet:StatefulSet能管有状态应用,比如给Pod分配固定身份、按顺序部署,表面看挺符合LLM推理对节点身份的要求。但StatefulSet对Pod的删除和重建策略较为严格,可能影响服务的快速恢复,难以实现LLM推理服务所需的快速弹性伸缩。
二、LWS在大模型推理部署场景下的优势
为了解决传统工作负载的问题云星算力调度平台接入的计算集群集成了LeaderWorkerSet插件。它是专门为AI推理场景设计的CRD资源,设计思路就是冲着解决分布式推理的协同、弹性和运维需求来的,和LLM推理的部署特性非常匹配,核心优势为:
组级生命周期管理,用于支持组级别的弹性伸缩、滚动升级和重启,提升服务高可用性。LWS会把一起干同一个推理任务的多个Pod分成一个“副本组”,里面有1个Leader Pod(组长)和多个Worker Pod(组员)。在弹性伸缩时,是以副本组为单位做扩缩容。
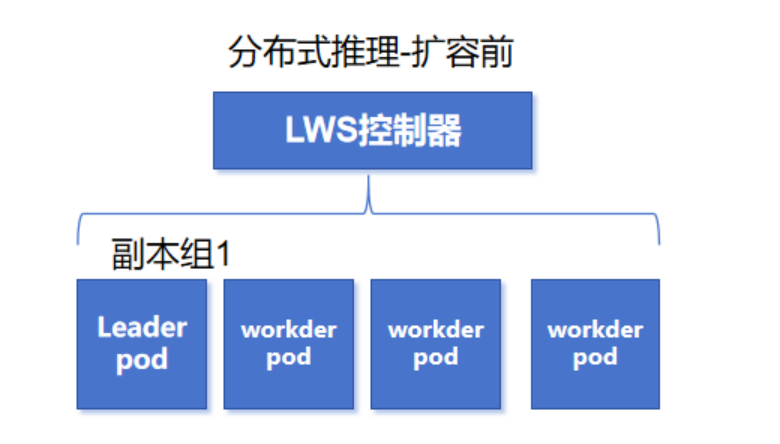
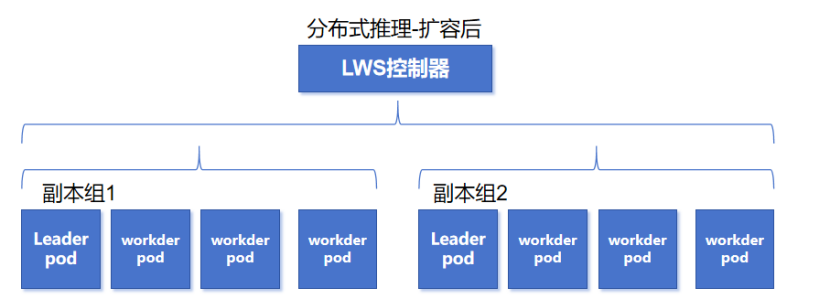
举个例子:我使用LWS初始化部署了一个分布式推理大模型,占用4个计算节点,那么这个推理副本组一共有1个leader 和3个worker 。当该推理服务负载过高需要扩容时,LWS按组扩容,最低扩容出1个新的副本组,所以额外需要4个计算节点。
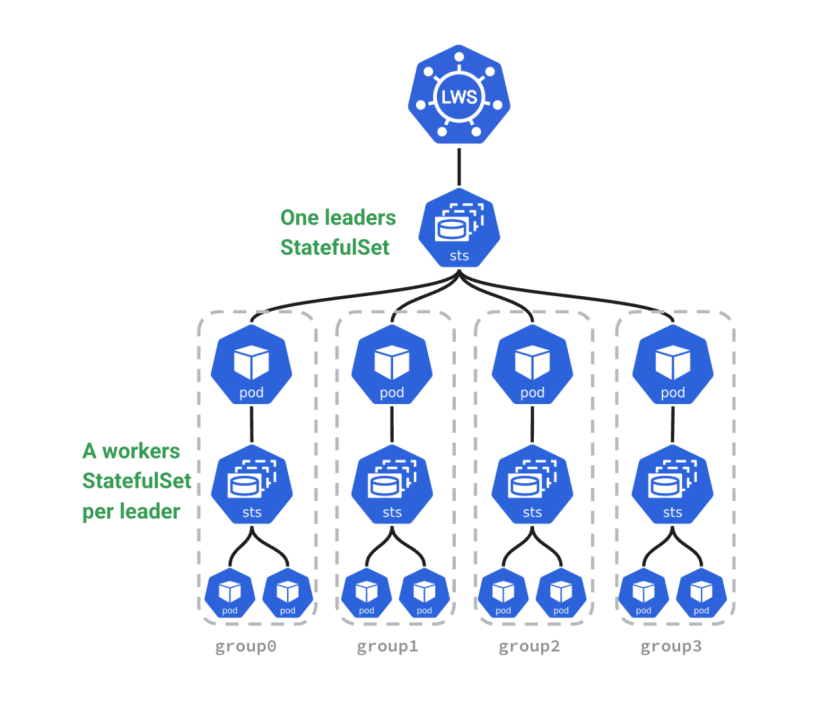
三、LWS概要介绍
简单来说,LeaderWorkerSet就是Kubernetes专门为AI/大模型推理场景量身打造的工作负载类型。它的核心思路很巧妙:把多个Pod编成一个“副本组”,当成一个整体来管。这种架构让vLLM、SGLang这些推理框架的分布式部署变得简单,解决了传统工作负载在LLM推理里的那些痛点,现在已经成了大模型推理部署的优选方案。下面是LWS的架构图:
四、安装指南
4.1版本要求
需使用版本 ≥ 1.26 的 Kubernetes 集群。
4.2通过 Helm 安装
若需通过 Helm 在集群中安装 LWS 的正式发布版本,执行以下命令:
CHART_VERSION=0.7.0
helm install lws oci://registry.k8s.io/lws/charts/lws \
--version=$CHART_VERSION \
--namespace lws-system \
--create-namespace \
--wait --timeout 300s也可执行以下命令安装:
VERSION=v0.7.0
helm install lws https://github.com/kubernetes-sigs/lws/releases/download/$VERSION/lws-chart-$VERSION.tgz \
--namespace lws-system \
--create-namespace \
--wait --timeout 300s五、Demo示例
5.1第一个demo
以下为一个LeaderWorkerSet示例:
apiVersion: leaderworkerset.x-k8s.io/v1
kind: LeaderWorkerSet
metadata:
name: leaderworkerset-sample
spec:
replicas: 3
leaderWorkerTemplate:
size: 4
workerTemplate:
spec:
containers:
- name: nginx
image: nginxinc/nginx-unprivileged:1.27
resources:
limits:
cpu: "100m"
requests:
cpu: "50m"
ports:
- containerPort: 8080若要列出属于某个LeaderWorkerSet(LWS)的所有Pod,可执行如下命令:
kubectl get pods --selector=leaderworkerset.sigs.k8s.io/name=leaderworkerset-sample输出结果类似如下:
NAME READY STATUS RESTARTS AGE
leaderworkerset-sample-0 1/1 Running 0 6m10s
leaderworkerset-sample-0-1 1/1 Running 0 6m10s
leaderworkerset-sample-0-2 1/1 Running 0 6m10s
leaderworkerset-sample-0-3 1/1 Running 0 6m10s
leaderworkerset-sample-1 1/1 Running 0 6m10s
leaderworkerset-sample-1-1 1/1 Running 0 6m10s
leaderworkerset-sample-1-2 1/1 Running 0 6m10s
leaderworkerset-sample-1-3 1/1 Running 0 6m10s
leaderworkerset-sample-2 1/1 Running 0 6m10s
leaderworkerset-sample-2-1 1/1 Running 0 6m10s
leaderworkerset-sample-2-2 1/1 Running 0 6m10s
leaderworkerset-sample-2-3 1/1 Running 0 6m10s5.1Pod的多模板配置
若指定了leaderTemplate字段,LWS支持为Leader Pod和Worker Pod配置不同模板;若未指定该字段,则workerTemplate模板将同时应用于Leader Pod和 Worker Pod。
apiVersion: leaderworkerset.x-k8s.io/v1
kind: LeaderWorkerSet
metadata:
name: leaderworkerset-sample
spec:
replicas: 3
leaderWorkerTemplate:
size: 4
leaderTemplate:
spec:
workerTemplate:
spec:5.3启动策略
.spec.startupPolicy用于控制Worker有状态集(StatefulSet)相对于其LeaderPod的创建时机,包含以下两种配置选项:
- LeaderCreated(默认):LeaderPod对象一旦创建,LWS控制器便会立即创建Worker有状态集。此策略不保证Leader与Worker之间的就绪顺序。
- LeaderReady:LWS控制器会延迟创建Worker有状态集,直至LeaderPod处于就绪(Ready)状态。
apiVersion: leaderworkerset.x-k8s.io/v1
kind: LeaderWorkerSet
metadata:
name: leaderworkerset-sample
spec:
startupPolicy: LeaderReady
replicas: 3
leaderWorkerTemplate:
...5.4LWS与拓扑调度的专属绑定
LWS的注解leaderworkerset.sigs.k8s.io/exclusive-topology可定义LWS副本与拓扑调度的1:1绑定关系。例如,为提升分布式推理的跨节点通信效率,需将某个LWS副本调度至同一机架,可按如下配置实现:
apiVersion: leaderworkerset.x-k8s.io/v1
kind: LeaderWorkerSet
metadata:
name: leaderworkerset-sample
annotations:
leaderworkerset.sigs.k8s.io/exclusive-topology: rack
spec:
replicas: 3
leaderWorkerTemplate:
...六、算力调度平台集成LWS构建LLM大模型推理能力
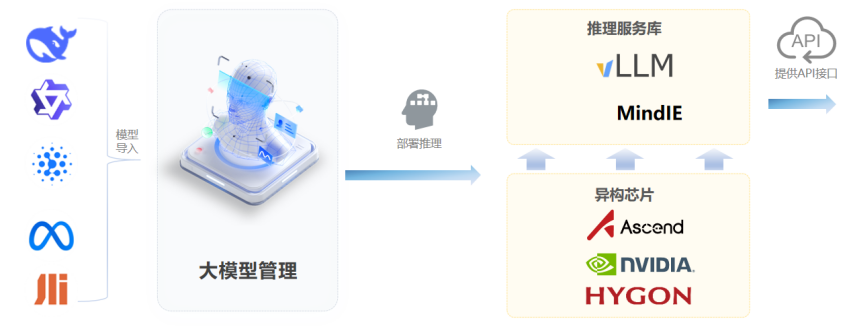
算力调度平台的大模型推理服务功能,支持用户将LLM大模型权重文件上传到平台统一管理,支持创建推理服务,平台自动将纳管的LLM大模型部署到计算节点,对外提供OpenAI兼容的API接口。
算力调度平台的模型自动部署功能基于LWS构建,支持推理服务快速扩缩容。
📡更多系列文章、开源项目、关键洞察、深度解读、技术干货
🌟请持续关注佳杰云星
💬欢迎在评论区留言,或私信博主交流 大模型推理架构 经验~

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)