vLLM-ascend搭配GPRO训练(TRL)在昇腾NPU上搭建部署与性能优化调试
在生成式人工智能从实验室研究迈向大规模生产应用的过程中,推理引擎的效率成为了关键制约因素。长久以来,这一领域由 NVIDIA GPU 及其成熟的 CUDA 生态主导。但随着全球 AI 算力需求持续呈现指数级增长,推动算力供应多元化已成为行业共同趋势。华为昇腾系列 AI 处理器——尤其是 Atlas 800 A2(搭载 Ascend 910B 芯片)集群——凭借其在 FP16/BF16 混合精度计算
通过此次性能调优之后,vllm-ascend推理性能可以大幅提升40-50%
一、前言 (vLLM-ascend的演进)
在生成式人工智能从实验室研究迈向大规模生产应用的过程中,推理引擎的效率成为了关键制约因素。长久以来,这一领域由 NVIDIA GPU 及其成熟的 CUDA 生态主导。但随着全球 AI 算力需求持续呈现指数级增长,推动算力供应多元化已成为行业共同趋势。华为昇腾系列 AI 处理器——尤其是 Atlas 800 A2(搭载 Ascend 910B 芯片)集群——凭借其在 FP16/BF16 混合精度计算上的强大性能,正逐步成为国内高性能 AI 算力的重要选择。
vLLM 作为当前开源社区中备受瞩目的大语言模型推理框架,以其前沿的 PagedAttention 算法有效解决了显存碎片化问题,在吞吐量方面表现卓越。然而,早期 vLLM 深度耦合于 NVIDIA 生态,适配其他硬件往往需要深入修改核心代码,带来较高的开发和维护门槛。随着 vLLM 推出硬件可插拔架构,硬件后端得以被解耦为独立插件,大幅降低了新硬件的接入成本。
正是在此背景下,vLLM-Ascend 作为官方支持的社区插件应运而生。它使 vLLM 能够无缝调用昇腾 NPU 的算力资源,实现基于国产化硬件的高性能、高效率大模型推理。本文将介绍 vLLM-Ascend 的设计思路与实现特点,并展示其如何助力开发者更便捷地在昇腾平台上部署和优化大模型推理任务。
vLLM-ascend开源社区地址:https://github.com/vllm-project/vllm-ascend
vLLM-ascend官方指导手册:https://docs.vllm.ai/projects/vllm-ascend-cn/zh-cn/latest/index.html
二、昇腾NPU环境安装
此次我们使用arm的机器搭配910B1
昇腾社区首页:https://www.hiascend.com/cann
我们首先进入社区版CANN包下载
下载CANN包:
这里我们使用8.3.RC2版本,下载对应arm和910b的 toolkit、kernels、nnal的run包
方式1:在昇腾社区上勾选对应要下载的包,就可以通过浏览器下载到本地,然后使用xftp等工具传到服务器上。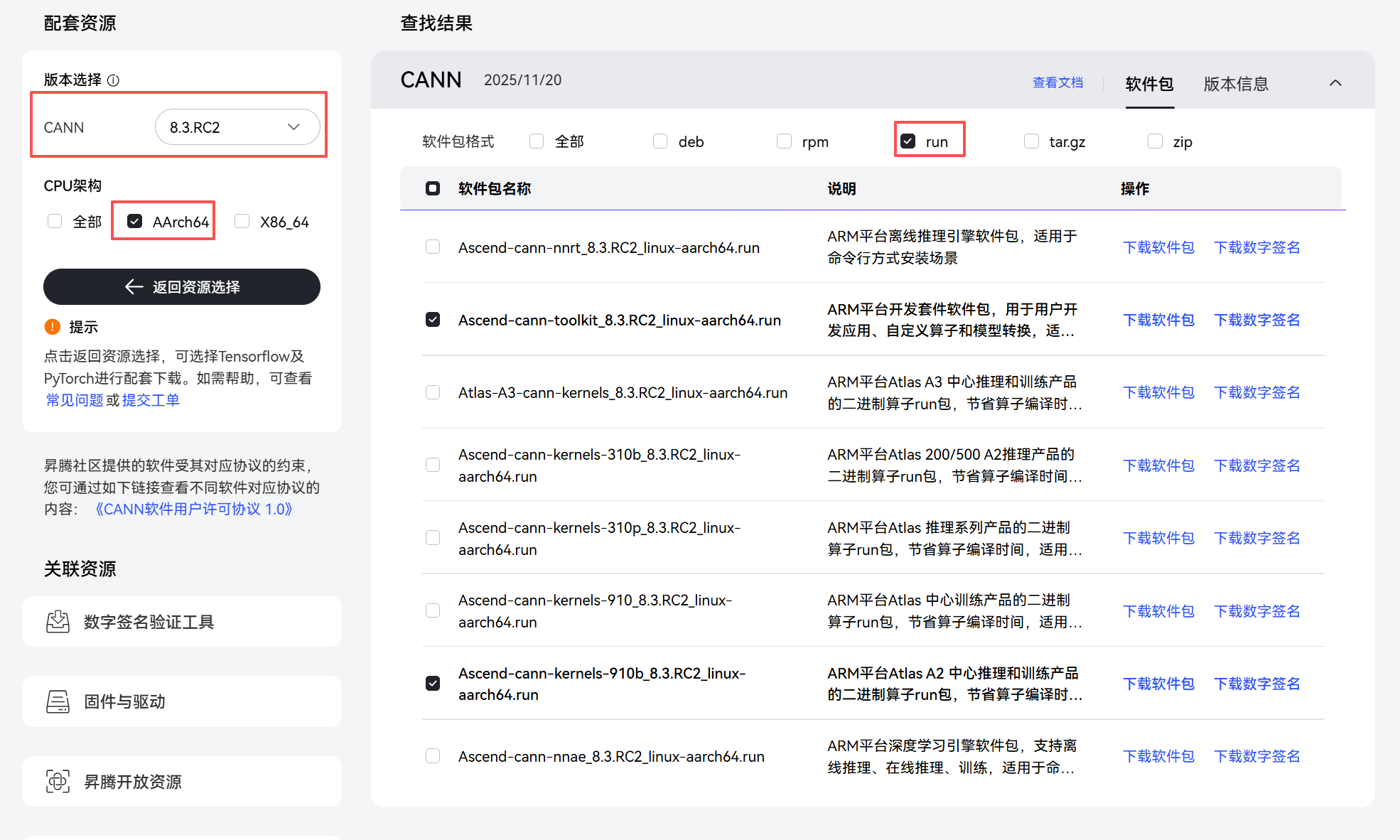
方式2:在昇腾社区上勾选对应要下载的包,在浏览器中找到复制下载链接,在服务器上使用wget直接下载
下载命令:
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/CANN/CANN%208.3.RC2/Ascend-cann-kernels-910b_8.3.RC2_linux-aarch64.run?response-content-type=application/octet-stream -O Ascend-cann-kernels-910b_8.3.RC2_linux-aarch64.run
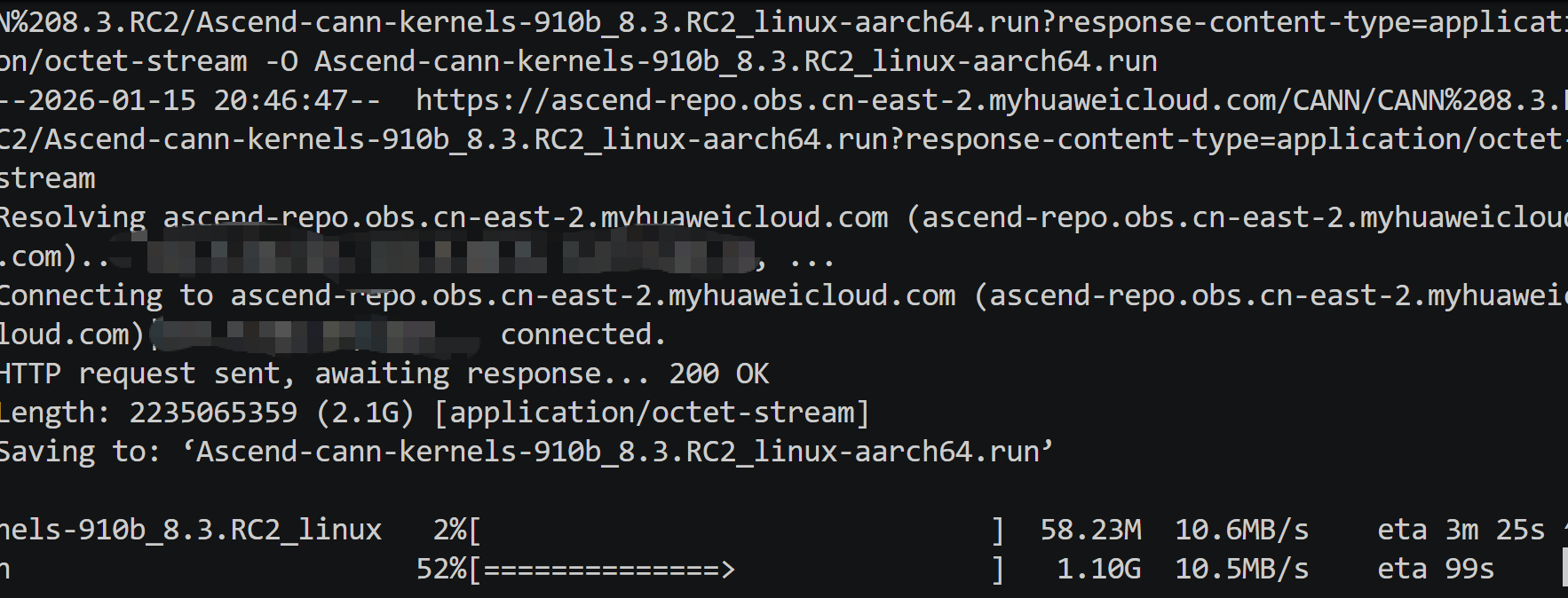
安装命令:
bash Ascend-cann-kernels-910b_8.3.RC2_linux-aarch64.run --quiet --install --install-path=/xxxxxxx/cann/env/
安装可能会遇到的报错:
1、.run 或安装的文件目录权限不够,需要修改权限为755
2、装包的顺序也有要求(包之间有依赖关系,按照所需安装的包和报错提示来安装)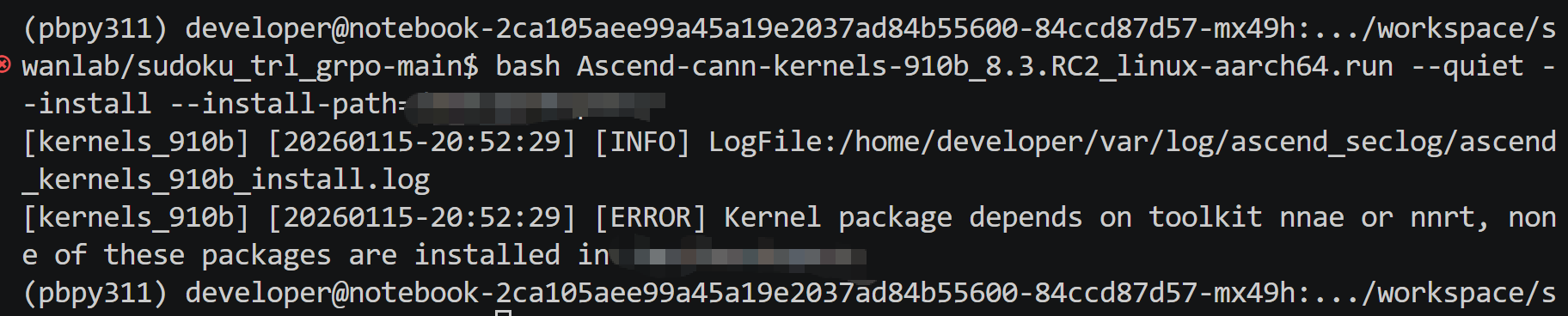
(直接按照官方的安装指导顺序安装就不会出错,先装驱动固件,再装Toolkit、Kernels、NNAL)
安装后记得source一下环境变量:
source /xxxxxxx/cann/env/ascend-toolkit/set_env.sh
CANN软件安装指导:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/83RC1/softwareinst/instg/instg_quick.html?Mode=PmIns&InstallType=netconda&OS=openEuler&Software=cannToolKit
三、trl+vLLM+vLLM-ascend环境安装
(python 3.11环境)
使用pip install安装即可 或者 使用vllm+vllm-ascend源码安装(开源代码仓中都有源码编译指导)
vLLM开源仓地址:vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs
vLLM-ascend开源仓地址:https://github.com/vllm-project/vllm-ascend
pip install trl==0.26.2
pip install vllm==0.11.0
pip install vllm-ascend==0.11.0-rc1
可能会遇到的报错,vllm 和 vllm-ascend支持的torch版本不同(可以先uninstall torch,在装vllm/vllm-ascend时会安装对应版本,可能会有warning,不影响)
启动项目期间可以会遇到缺少某些包的报错,直接pip install就好
四、项目启动部署
本次使用的是Qwen2.5-3B模型 推理
模型下载链接:https://www.modelscope.cn/models/Qwen/Qwen2.5-3B-Instruct
1、使用trl拉起vllm-ascend服务端
ASCEND_RT_VISIBLE_DEVICES=1 trl vllm-serve --model ./models/Qwen2.5-3B-Instruct/ > run_serve.log 2>&1 &
# ASCEND_RT_VISIBLE_DEVICES是指定NPU的设备,默认为0
使用trl拉起客户端init_communicator时可能会遇到的报错:
找不到device
当前规避方法:注释掉卡号检测,指定卡号防止冲突。
需要修改trl的拉起vllm serve的文件(…/python3.11/site-packages/trl/scripts/vllm_serve.py),参考代码pr:https://github.com/huggingface/trl/pull/4789
2、运行对应的trl的训练脚本
五、vLLM-ascend推理性能优化
本次使用的是910B1(64GB显存) 1卡部署Qwen2.5-3B模型 推理
参考性能优化贴:vLLM-Ascend 性能调优与调试完全指南_昇腾主版块_昇腾论坛
vLLM/vLLM-ascend默认参数调整
由于本次项目是基于trl框架拉起的,所以启动配置需要在trl拉起客户端的代码(…/python3.11/site-packages/trl/scripts/vllm_serve.py)中添加(如果使用纯vllm/vllm-ascend框架,可以加在启动命令中)
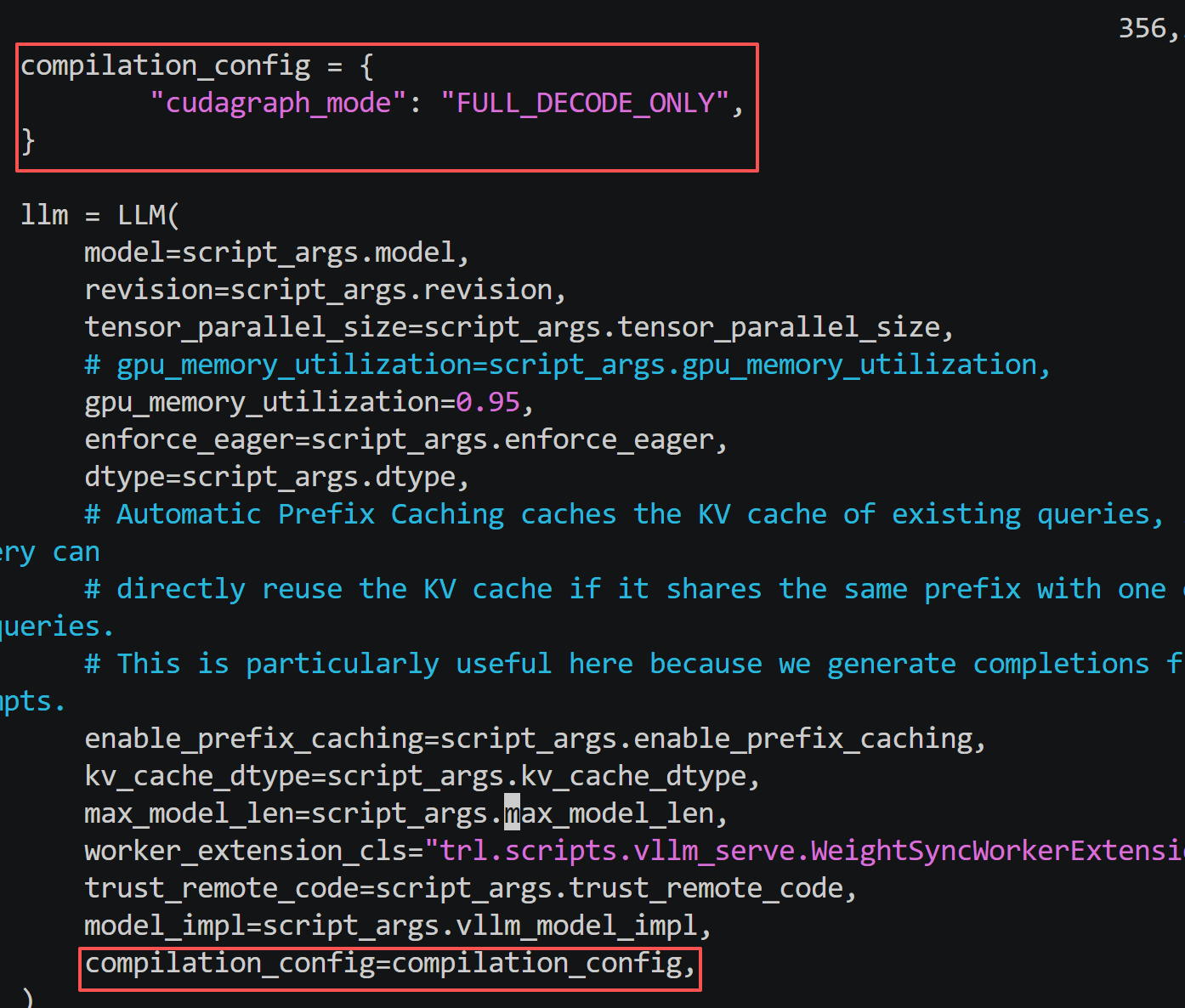
性能提升最大的配置:
compilation_config = {
“cudagraph_mode”:“FULL_DECODE_ONLY”,
}
vllm的cudadgraph_mode默认是FULL_AND_PIECEWISE但是vllm-ascend当前不支持该模式
来自vllm-ascend源码:
# TODO: Full graph is fully supported later, and the default value will be set to full graph.
if compilation_config.cudagraph_mode == CUDAGraphMode.FULL_AND_PIECEWISE:
compilation_config.cudagraph_mode = CUDAGraphMode.PIECEWISE
vllm-ascend官方文档中查阅得知v0.11.0rc1支持FULL_DECODE_ONLY,还不支持FULL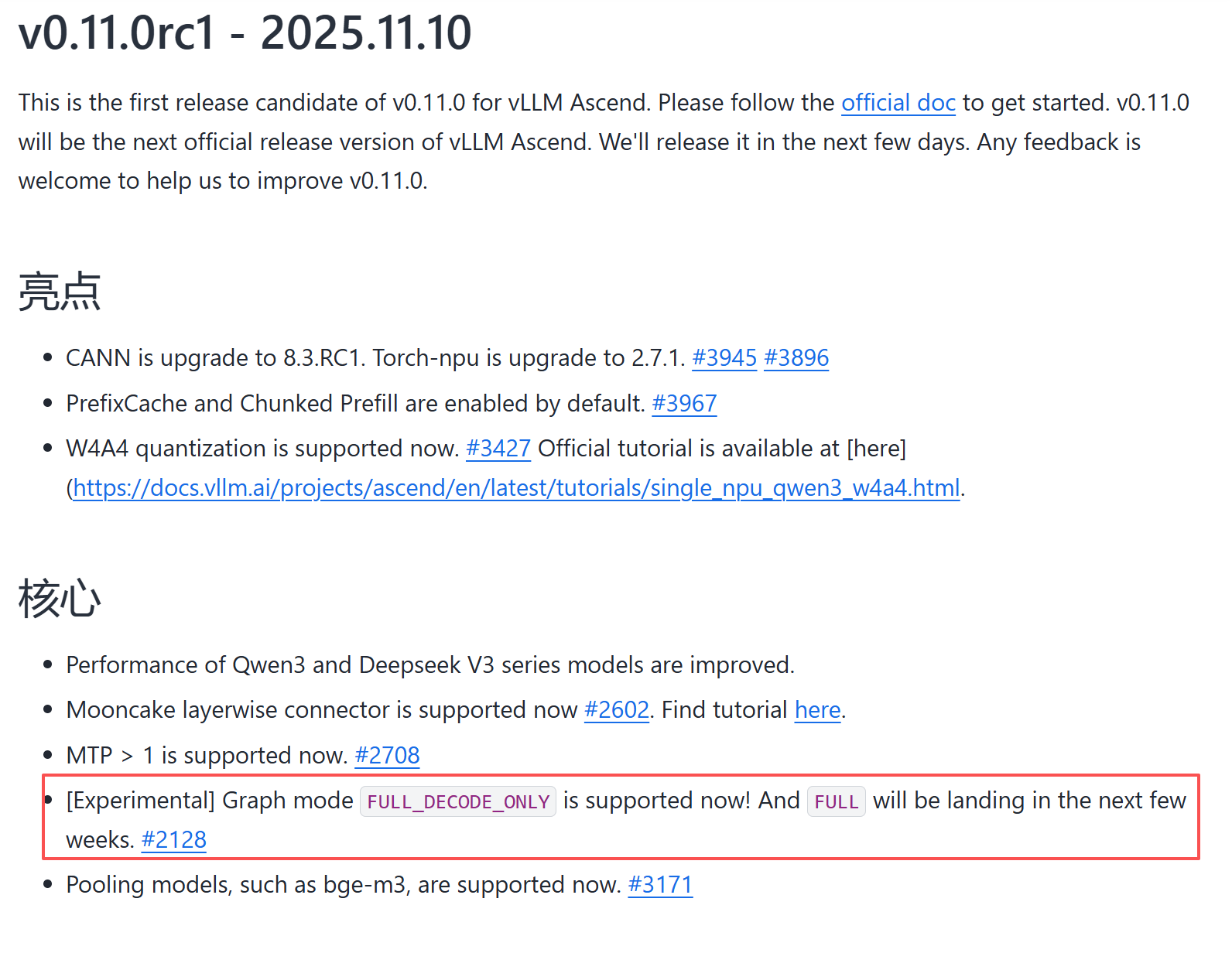
vllm-ascend官方文档中查阅得知v0.12.0rc1中,FULL_DECODE_ONLY即使不是默认设置,但是推荐开启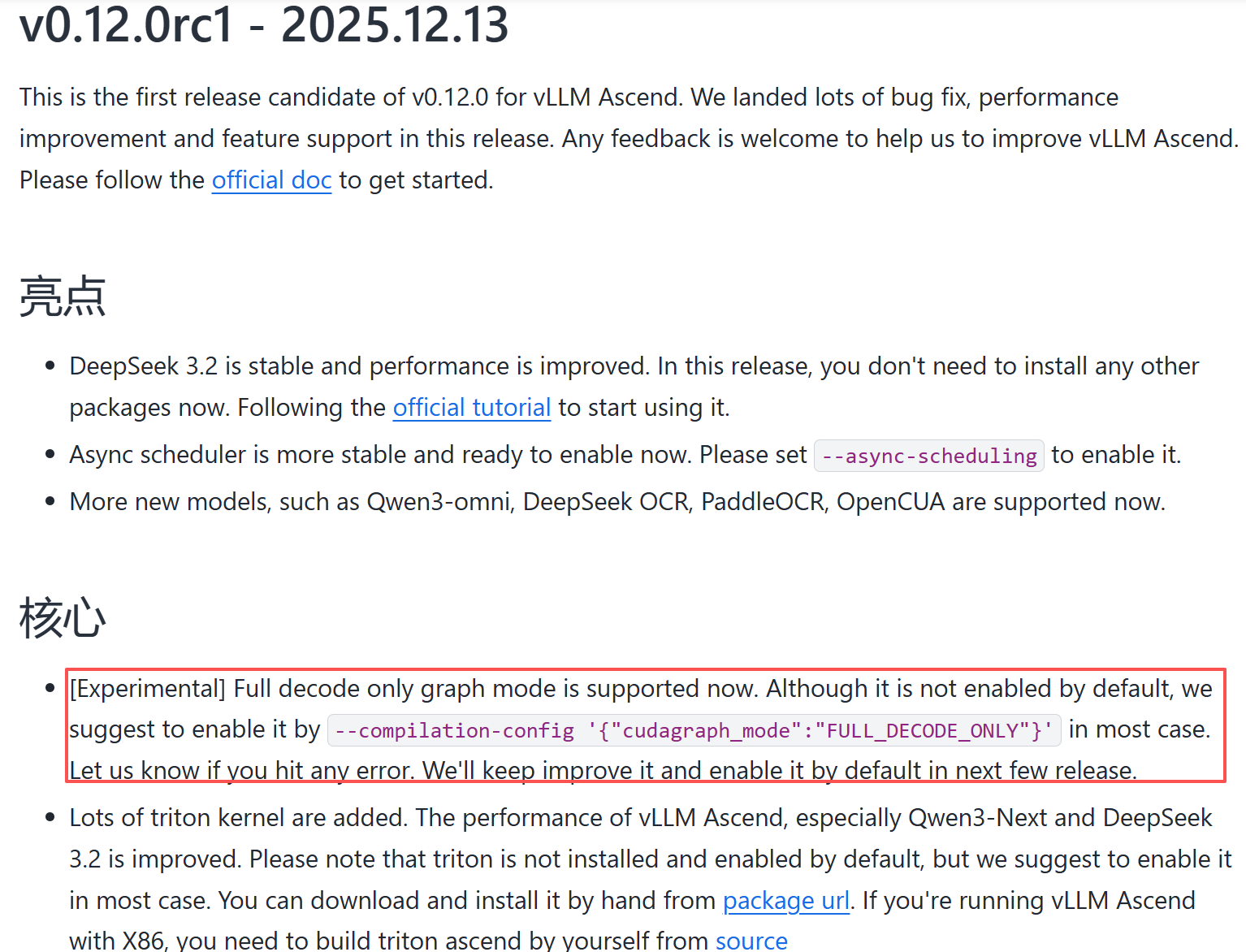 vllm-ascend后续可能会支持FULL和FULL_AND_PIECEWISE
vllm-ascend后续可能会支持FULL和FULL_AND_PIECEWISE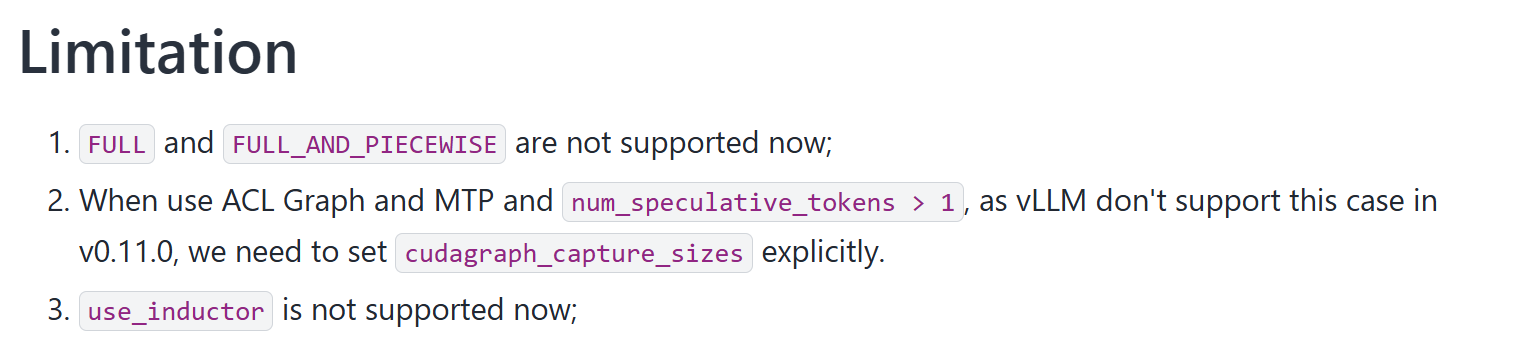
其他配置:
async_scheduling,开启异步调度,这个配置在vllm-ascend0.11.0版本中是默认开启的
block-size=32 (vllm的pageAttention分块大小,默认值为16(对gpu比较友好),本次在910B1中调测下来 32 64 128中 32性能最优)
gpu-memory-utilization=0.95 (默认值为0.9,我们使用小模型+大显存(64GB)的卡部署模型,可以拉高显存利用率到0.95,具体拉高到多少就要调测看能不能稳定推理不报错(因为看到5090卡(32GB显存)上部署用的默认配置0.9,这里我们64GB显存就试试0.95,是可以稳定跑推理不报错的))
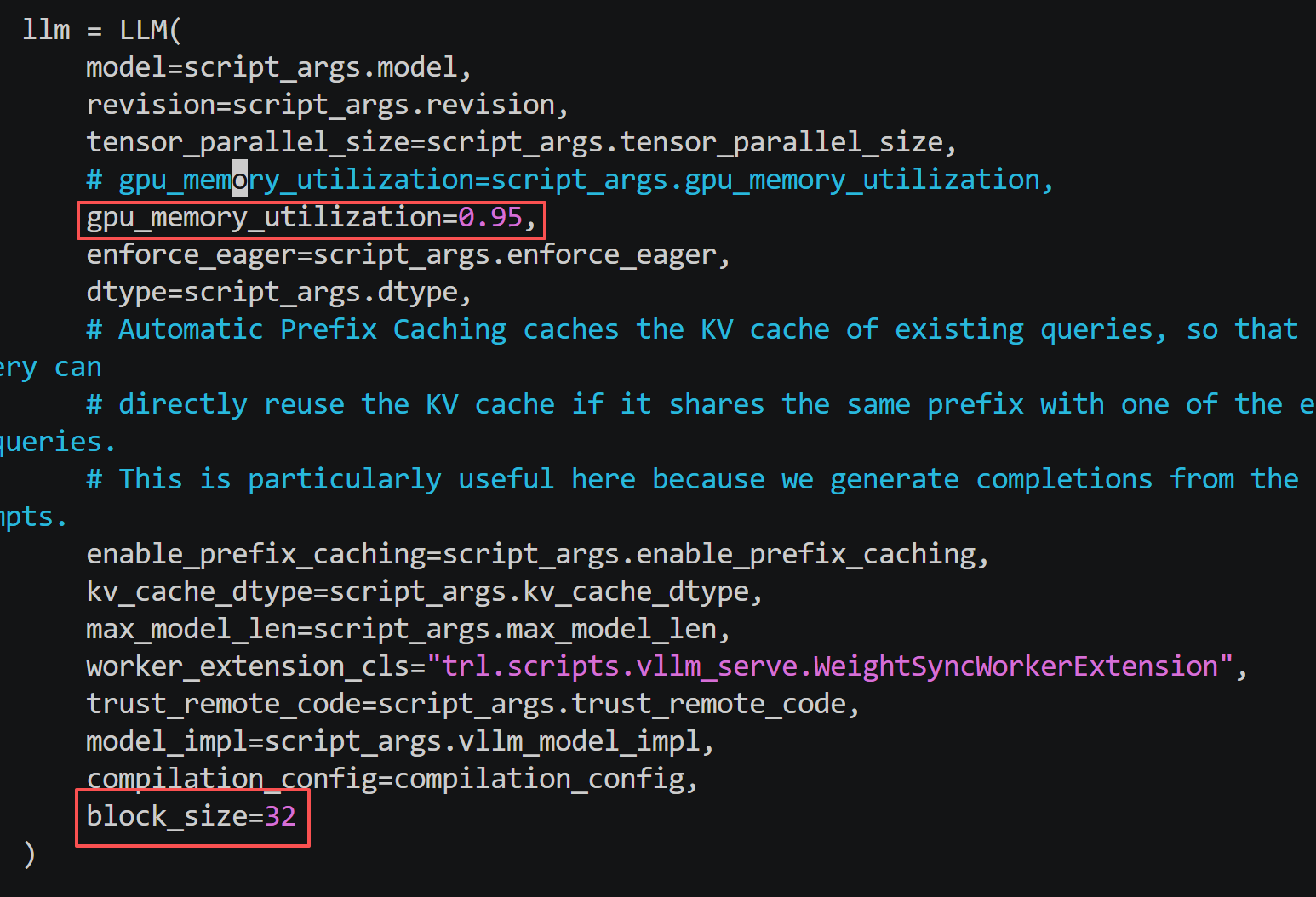
上面几个参数配置调整之后,推理性能可以大幅提升(推理速度提升40-50%),还有一些其他的参数,经尝试后提升不大,各位也可以都基于自己的项目试试
其他配置参考:
https://zhuanlan.zhihu.com/p/1916898243423500022
https://docs.vllm.ai/en/latest/usage/index.html
https://docs.vllm.com.cn/en/latest/configuration/engine_args.html#modelconfig
https://cloud.baidu.com/article/3262475
https://blog.csdn.net/flyfish1986/article/details/147956194
https://blog.csdn.net/qianggezhishen/article/details/149228511
https://www.hiascend.com/document/detail/zh/Pytorch/720/comref/Envvariables/Envir_007.html

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)