昇腾MindSpeed RL的Partial rollout特性代码解析
Partial rollout 核心思想是通过对长序列 response 推理样本做提前中断,并在下次推理过程中对当前样本进行续推,从而避免单一的长尾样本对推理过程造成资源浪费。通过该能力,我们可以降低长序列推理场景下的长尾样本对端到端性能的影响。下面对该特性的代码实现做深入解读。
昇腾MindSpeed RL的Partial rollout特性代码解析
Partial rollout 核心思想是通过对长序列 response 推理样本做提前中断,并在下次推理过程中对当前样本进行续推,从而避免单一的长尾样本对推理过程造成资源浪费。通过该能力,我们可以降低长序列推理场景下的长尾样本对端到端性能的影响。下面对该特性的代码实现做深入解读。
相关代码
mindspeed_rl/trainer/grpo_trainer_hybrid.py
mindspeed_rl/trainer/utils/transfer_dock.py
mindspeed_rl/workers/base_worker.py
mindspeed_rl/workers/actor_hybrid_worker.py
mindspeed_rl/models/actor_rollout_hybrid.py
mindspeed_rl/models/rollout/vllm_engine.py
概述
同步模式
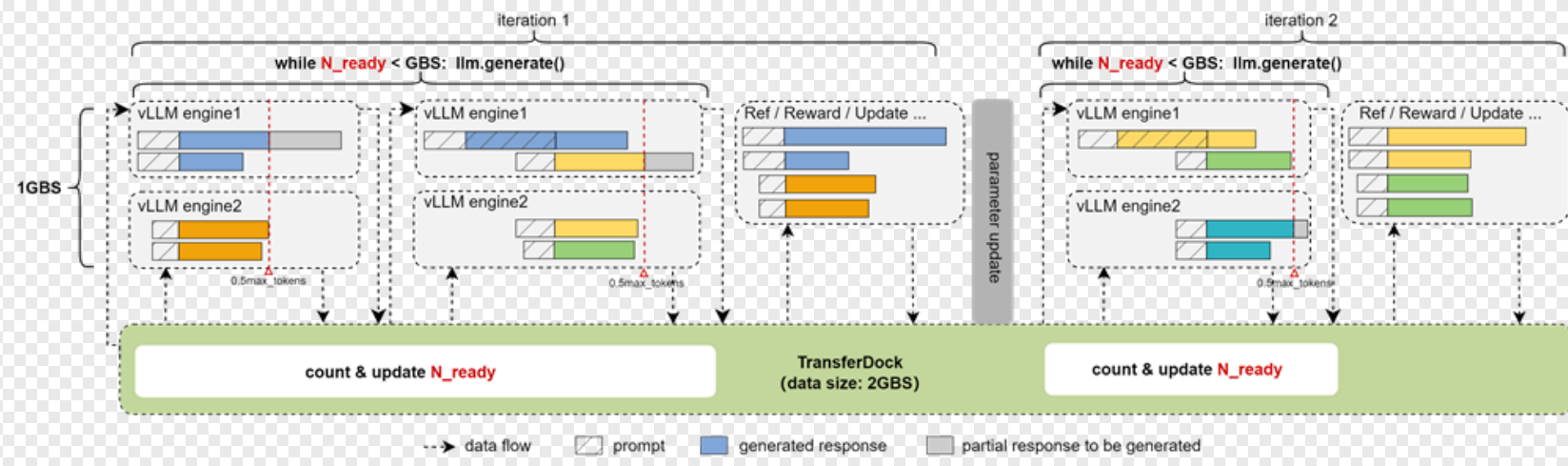
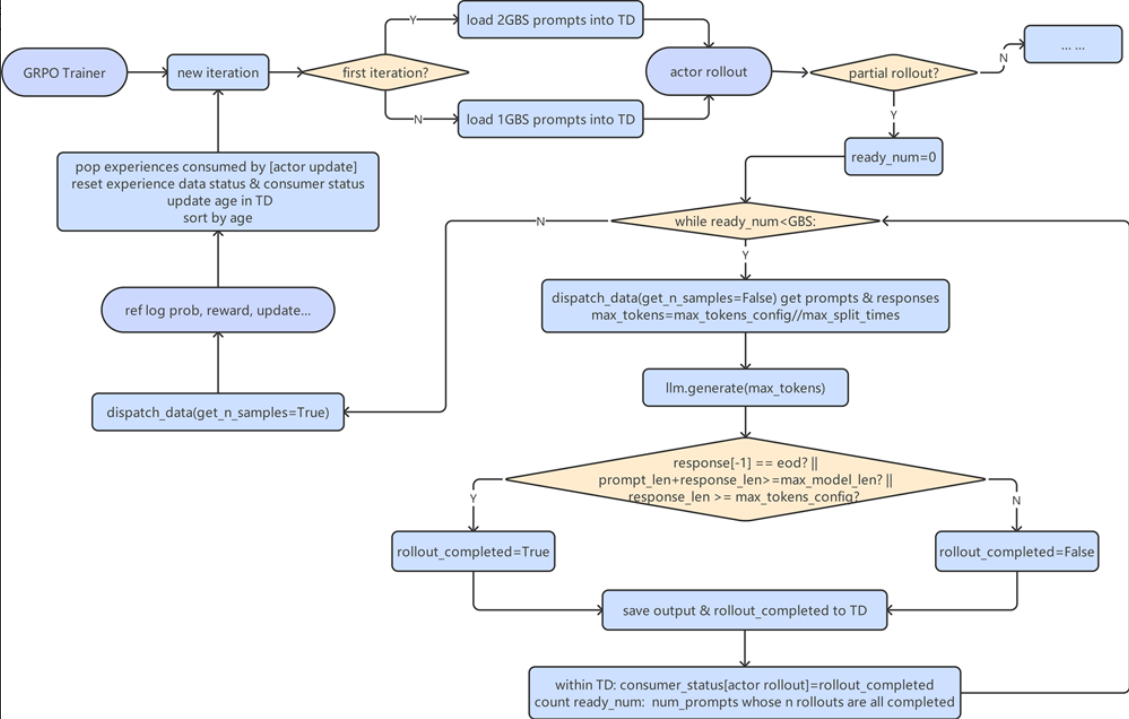
同步模式大致的逻辑是这样的:
- 根据最大推理长度(max_len)和次数(max_age或者partial_rollout_max_split)设置推理截断点(max_len/max_age),partial_rollout_max_split决定最多几轮完成序列推理
- 首先加载2GBS的数据到TransferDock
- 循环检查该条件是否满足,不满足则循环推理:ready_num >= GBS(ready_num 为有几个prompt的n_sample全部完成推理)
- 每次从TransferDock中取1GBS的数据用于推理,取的数据包括未推理过的prompt和上次推理被截断的prompt,上次推理被截断的prompt会被优先取出来
- iteration内通过index顺序保证
- 每次从TransferDock中取1GBS的数据用于推理,取的数据包括未推理过的prompt和上次推理被截断的prompt,上次推理被截断的prompt会被优先取出来
|
#mindspeed_rl.trainer.utils.transfer_dock.GRPOTransferDock._sample_ready_index sampled_indexes = [int(i) for i in usable_indexes[:experience_count]] |
-
-
- 跨iteration通过clear保证,clear会更新age,并且调到sort_every_n_samples_by_age,根据数据的age进行排序,保证age大的数据先推理
- 其中推理完成的数据、以及达到推理截断点仍没有推理完的序列,会被放入TransferDock(存prompt、response、rollout_completed状态等)
-
- 当满足ready_num >= GBS,则进入后续计算任务,计算reward,logprob,update等
异步模式
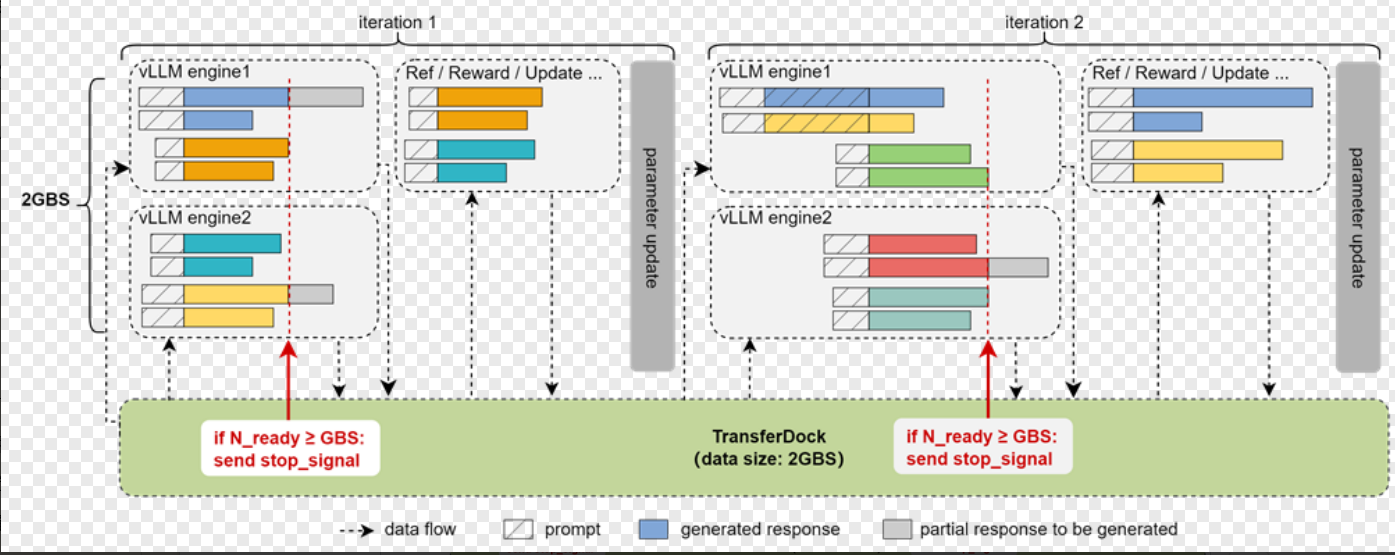
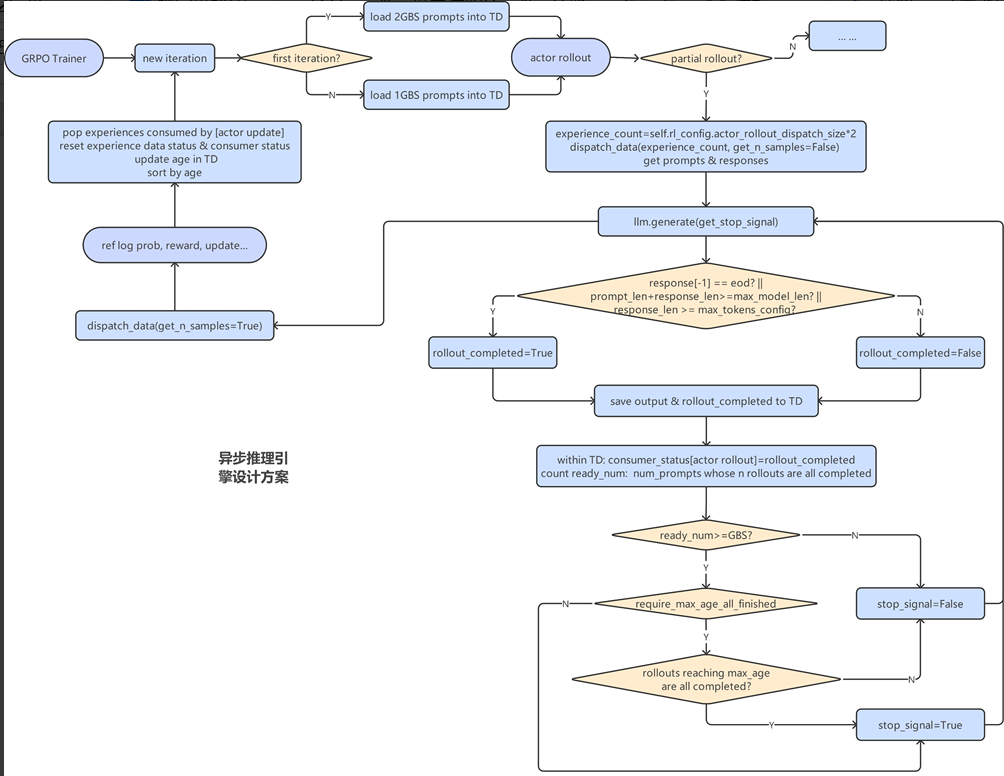
异步模式的大致逻辑是这样的:
- 通过配置文件的async_engine参数控制是否开启异步模式
- 首先加载2GBS的数据到TransferDock
- 从TransferDock读取2GBS的数据,调用vLLM_engine进行异步推理
- 每个推理完成的数据,会把response以及rollout_completed状态等存入TD
- 并且定期获取stop_signal状态,判断条件一般还是ready_num是否大于等于GBS,如果设置了require_max_age_all_finished=True,还需要检查达到max_age的reponses是否在本iteration完成了,如果满足上面条件,stop_signal设置为True
- 如果stop_signal设置为True,vLLM_engine会停止推理,进入后续的计算任务,计算reward,logprob,update等
两种模式比较
相比于同步模式,异步模式主要有以下主要的不同点:
- 异步模式没有像同步模式一样,设置推理截断点。
- 异步推理直接拿2GBS数据推理,同步是1GBS
- 同步模式数据写TransferDock,检查ready_num>=GBS条件,都是在完成1GBS的处理后,批量操作(需要等一个时间点);而异步模式则有数据推理完成就立刻写TransferDock,检查ready_num>=GBS条件频率也很高(目前是vLLM engine每推理20个token,检查一次)
- 控制推理停止的方式不同:
- 同步模式是在完成每1GBS的处理后,去检查是否满足ready_num>=GBS,决定需不需要继续推理
- 异步模式是通过stop_signal实现更精细的控制
主要实现介绍
基础设施GRPOTransferDock
主要实现了下面功能
- 推理控制逻辑:控制继续推理,还是做训练的后续处理(ref_prob reward update等)
- 同步模式主要通过all_consumed
- 异步模式主要通过get_update_ready
- 辅助函数:find_all_consumed_n_samples_groups
- 数据读写TransferDock针对partial rollout的适配
- get_experience
- put_experience
- _sample_ready_index
- _sample_ready_index_n_samples
- 数据跨train iteration操作:部分数据一个iteration推理不完,会被截断
- clear:对于训练使用完的数据做清理,更新被截断response的age
- sort_every_n_samples_by_age:根据age对数据排序,保证age大数据先处理
训练调用主要流程RayGRPOTrainer.fit
训练主要的流程都在fit中实现
封装后的基础设施BaseWorker
基于TransferDock的all_consumed、get_experience、put_experience做了针对分布式训练的适配
- all_consumed:无改动,但会被调用
- dispatch_transfer_dock_data:针对partial rollout有少量传参的变动
- collect_transfer_dock_data:无改动,但会被调用
rollout推理逻辑实现
- 同步模式和异步模式推理的实现,异步模式的推理停止控制主要在VLLMInferEngine中实现
- 调用顺序为:ActorHybridWorkerBase调用ActorRolloutHybrid,ActorRolloutHybrid调用VLLMInferEngine;
- 另外会调用BaseWorker中的几个方法,用于和TransferDock互动。
下面是主要相关实现:
- ActorHybridWorkerBase
- generate_sequences
- sync_generate_process
- async_generate_process
- ActorRolloutHybrid
- generate_sequences
- VLLMInferEngine
- generate_sequences
- async_generate_sequences
更细粒度的介绍可以看下面对实现细节的介绍
实现细节
RayGRPOTrainer
初始化
__init__
其中使用partial rollout,td_max_len(即prompt_num)扩充为普通模式的2倍
|
#mindspeed_rl.trainer.grpo_trainer_hybrid.RayGRPOTrainer.__init__ self.enable_partial_rollout = self.partial_rollout_max_split > 1 if self.enable_partial_rollout: self.td_max_len = self.global_batch_size * 2 else: self.td_max_len = self.global_batch_size self.transfer_dock_init() |
transfer_dock_init
上面初始化的self.td_max_len、self.partial_rollout_max_split等参数传给GRPOTransferDock初始化
|
#mindspeed_rl.trainer.grpo_trainer_hybrid.RayGRPOTrainer.transfer_dock_init def transfer_dock_init(self): self.transfer_dock = GRPOTransferDock.remote( prompts_num=self.td_max_len, # max sample num n_samples_per_prompt=self.n_samples_per_prompt, metrics=self.metrics, max_age=self.partial_rollout_max_split, GBS_train=self.global_batch_size, # GBS_train addition_columns=self.dataset_additional_keys ) |
fit
加载2GBS数据,包括推理和后续处理reward,logprob,update,clear等都在fit中调用
加载2GBS的数据到TransferDock
- 这里面有两次put_prompts_experience操作和put_experience操作,实现加载2GBS的数据集数据到TransferDock
- 注意第二次put_prompts_experience的时候有了参数add_another_batch。
|
#mindspeed_rl.trainer.grpo_trainer_hybrid.RayGRPOTrainer.fit if self.enable_partial_rollout: first_batch = next(data_iters) batch, indexes = put_prompts_experience(first_batch, self.n_samples_per_prompt, self.dataset_additional_keys) ray.get(self.transfer_dock.put_experience.remote(data_dict=batch, indexes=indexes, is_prompt=True)) logger.info(f'training start, put first batch') while iteration < self.train_iters: last_iter = iteration == self.train_iters - 1 with Timer(name='iteration', logger=None) as all_timer: batch = next(data_iters) if self.enable_partial_rollout: if not last_iter: # and batch is not None: # None? batch, indexes = put_prompts_experience(batch, self.n_samples_per_prompt, self.dataset_additional_keys, add_another_batch=True) ray.get(self.transfer_dock.put_experience.remote(data_dict=batch, indexes=indexes, is_prompt=True)) else: batch_dict, indexes = put_prompts_experience(batch, self.n_samples_per_prompt, self.dataset_additional_keys) ray.get(self.transfer_dock.put_experience.remote(data_dict=batch_dict, indexes=indexes, is_prompt=True)) |
模型训练流程
|
def fit(self, data_iters): ...... if self.enable_partial_rollout: first_batch = next(data_iters) batch, indexes = put_prompts_experience(first_batch, self.n_samples_per_prompt, self.dataset_additional_keys) ray.get(self.transfer_dock.put_experience.remote(data_dict=batch, indexes=indexes, is_prompt=True)) logger.info(f'training start, put first batch') while iteration < self.train_iters: last_iter = iteration == self.train_iters - 1 with Timer(name='iteration', logger=None) as all_timer: batch = next(data_iters) if self.enable_partial_rollout: if not last_iter: # and batch is not None: # None? batch, indexes = put_prompts_experience(batch, self.n_samples_per_prompt, self.dataset_additional_keys, add_another_batch=True) ray.get(self.transfer_dock.put_experience.remote(data_dict=batch, indexes=indexes, is_prompt=True)) ...... self.actor_worker.generate_sequences(blocking=self.blocking) # compute rm scores. rule_reward = [] for reward_worker in self.reward_list: if isinstance(reward_worker, RayActorGroup): reward_worker.compute_rm_score(blocking=self.blocking) else: rule_reward.append(reward_worker.compute_rm_score.remote()) ray.get(rule_reward) # compute advantages, executed on the driver process self.compute_advantage(blocking=True, guarantee_order=self.guarantee_order) # compute reference log_prob self.ref_worker.compute_ref_log_prob(blocking=self.blocking) # compute old log_prob if not self.skip_actor_log_prob: self.actor_worker.compute_log_prob(blocking=self.blocking) self.actor_worker.wait_all_ref_objs_run_over() self.ref_worker.wait_all_ref_objs_run_over() for reward in self.reward_list: if hasattr(reward, 'wait_all_ref_objs_run_over'): reward.wait_all_ref_objs_run_over() # update actor self.actor_worker.update(self.kl_ctrl, self.skip_actor_log_prob) ...... ray.get(self.transfer_dock.clear.remote()) ...... logger.info('after grpo training is done') ray.shutdown() |
GRPOTransferDock
初始化
__init__
其中:self.max_len = prompts_num * n_samples_per_prompt。TransferDock存储空间扩充为原来的2倍。
重要变量:
- global_ready_mask:如果一个prompt组完成所有n_sample的推理,那么改组内所有response的对应位置在global_ready_mask中置为1
- rollout_completed:标志当前样本是否完成rollout:正常推理完成或者到达max_tokens(eod || max_tokens)
- GBS_train:训练的global_batchsize
- max_age:partial_rollout_max_split
- age:落后当前actor参数的训练步数
- stop_partial_rollout_signal:控制异步推理停止的signal
|
#mindspeed_rl.trainer.utils.transfer_dock.GRPOTransferDock.__init__ self.max_age = max_age self.GBS_train = GBS_train self.rollout_completed = torch.zeros(self.max_len, dtype=torch.int32) # 标志当前样本是否完成rollout:eod || max_tokens self.age = torch.zeros(self.max_len, dtype=torch.int32) # 落后当前actor参数的训练步数,是否需要按age排序?age的更新需要在TD逐出和重排序的时候做 self.enable_partial_rollout = max_age > 1 # max_age = 1 是续推0次,因为rollout_completed的判断是在TD外面做的 if self.enable_partial_rollout: self.stop_partial_rollout_signal = False self.global_ready_mask = torch.zeros(self.max_len, dtype=torch.int32) |
推理控制逻辑
用于控制继续进行actor_rollout推理,还是进入后续阶段reward、ref_logprob、update的流程。判断条件是actor_rollout(推理)阶段是否有GBS_train个prompt完成全部n_sample的推理,如果凑够了GBS_train个数据,就可以进入后续阶段流程,否则继续actor_rollout推理。
all_consumed
- 对于partial rollout有两个作用:
- 判断actor_rollout(推理)阶段是否有GBS_train个prompt完成全部n_sample的推理,如果有返回True,否则返回False
- 其他阶段:某阶段(consumer)数据是否都被消费完
- 它是推理控制逻辑的主要实现
- 如果有GBS_train个prompt完成全部n_sample的推理,则进入后续reward、ref_logprob、update的流程
- 否则继续对prompt进行推理
- 在self.actor_worker.generate_sequences(blocking=self.blocking)的self.all_consumed会调用到all_consumed,用于上面判断
- stop_partial_rollout_signal会发送到infer_engine(VLLM),用于异步模式的推理控制
- self.global_ready_mask会用于后续get_experience中作为sample indexes的判断条件之一。
|
#mindspeed_rl.trainer.utils.transfer_dock.GRPOTransferDock.all_consumed def all_consumed(self, consumer: str): if self.enable_partial_rollout: ...... if consumer == 'actor_rollout': #all_consumed_group_num:几个prompt完成全部n_sample的推理 #global_ready_mask:长度为max_len,如果一个prompt组完成所有的rollout,那么该组相应response位置为1,用于后续get_experience sample的判断条件 all_consumed_group_num, global_ready_mask, _ = self.find_all_consumed_n_samples_groups(consumer='actor_rollout') #异步模式信号 self.stop_partial_rollout_signal = all_consumed_group_num >= self.GBS_train self.global_ready_mask = global_ready_mask #partial_rollout循环控制逻辑:是否有GBS_train个prompt完成全部n_sample的推理 return all_consumed_group_num >= self.GBS_train else: #开启partial_rollout,其他阶段的判断GBS_train*n_samples数据是否都被消费完 return self.experience_consumer_status[consumer].sum() == self.GBS_train * self.n_samples_per_prompt else: #未开启partial_rollout,数据是否都被消费完判断 return self.experience_consumer_status[consumer].sum() == self.max_len |
find_all_consumed_n_samples_groups
- 判断有多少个prompt组(一个prompt对应n_samples_per_prompt个response)已经完成所有轮次的rollout。
- 判断依据是self.rollout_completed
- 被all_consumed调用
- 返回值:
- all_consumed_group_count:完成rollout的组的数量
- global_mask:长度为max_len,全局就绪掩码,如果一个prompt组完成所有的rollout,那么该组内所有response的对应位置在global_mask中置为1,用于后续get_experience。
- all_consumed_group_start_indices:长度为prompt个数的list,记录已经完成rollout的组的起始索引位置
get_update_ready
主要用于异步模式控制推理是否继续进行,作用是判断stop_signal状态,判断条件有两个:
- 一个是ready_num是否大于等于GBS
- 如果设置了require_max_age_all_finished=True,还需要检查达到max_age的reponses是否在本iteration完成了
如果满足上面条件,stop_signal设置为True
数据读写TransferDock
这部分重点是针对截断数据重新处理做了一些适配
put_experience
- 如果是rollout阶段,会走下面逻辑。
- 根据data_dict中的rollout_completed列,设置self.rollout_completed
- self._put把数据存入TransferDock(不包含rollout_completed列)
- 根据self.rollout_completed,设置self.experience_consumer_status['actor_rollout'][indexes],rollout_completed=1的位是rollout阶段已经处理完的项,0是未完成的项。
- 如果某个数据推理过程被截断,会调用put_experience把它存入TransferDock
- 调用put_experience的时候,根据rollout_completed把experience_consumer_status['actor_rollout']重新设置为0,这样被截断的数据在下次推理时可以再次读取使用
- 对于put_experience参数is_prompt为True的情况,即训练最开始放入TransferDock的训练数据集数据,会做下面处理:
- 把self.experience_data_status['responses']、self.experience_data_status['response_length']设置为1,表示responses、response_length列数据ready。新加入的prompts,还没有推理responses、response_length怎么会ready呢?这里主要是为了新加数据能和上一轮推理被截断的数据一起处理做的操作,上一轮推理被截断的数据会向TransferDock存入responses、response_length,并标记两列的self.experience_data_status为1(调用_put存数据都会做这个操作),为了新加的prompt和上一轮被截断的数据一起处理,选取新一轮用于推理的数据,所以才这样处理。
|
#mindspeed_rl.trainer.utils.transfer_dock.GRPOTransferDock.put_experience def put_experience( self, data_dict: Dict[str, Union[Tensor, List[Tensor]]], indexes: List[int] = None, is_prompt: bool = False ): ...... if "responses" in experience_columns: # 确定是rollout阶段 if self.enable_partial_rollout: # 确定partial rollout功能开启 rollout_completed_col_id = experience_columns.index('rollout_completed') rollout_completed_column = experience.pop(rollout_completed_col_id) experience_columns.pop(rollout_completed_col_id) for i, idx in enumerate(indexes): if idx >= 0: if rollout_completed_column[i][0] == 1: self.rollout_completed[idx] = 1 self._put(experience_columns, experience, indexes) # partial_rollout为了能重新利用截断数据,将其消费状态置为0(rollout_completed为0,意味着之前没消费完), if ("responses" in experience_columns) and self.enable_partial_rollout: self.experience_consumer_status['actor_rollout'][indexes] = copy.deepcopy(self.rollout_completed[indexes]) #is_prompt是新让如TransferDock的数据集数据,responses位为未ready,为了和截断数据一起使用,做如下置位 if self.enable_partial_rollout and is_prompt: self.experience_data_status['responses'][indexes] = 1 self.experience_data_status['response_length'][indexes] = 1 for i in indexes: self.experience_data['responses'][i] = torch.tensor([-1], dtype=torch.int32) self.experience_data['response_length'][i] = torch.tensor([0], dtype=torch.int32) |
get_experience
- 调用self._sample_ready_index采样indexes,没有采用负载均衡算法,而是按照顺序采样
- 根据采样的indexes,调用self._get(experience_columns, indexes)从TransferDock取数据
- 对于actor_rollout阶段,取到数据后,马上把下面状态置为0。这样后续处理,可以根据他们的状态判断responses等数据是否ready可用
- 如果取到的数据少于请求的数量,则用最后一条数据填充
|
#mindspeed_rl.trainer.utils.transfer_dock.GRPOTransferDock.get_experience def get_experience( ...... ): ...... indexes = self._sample_ready_index( consumer, experience_count, experience_columns, use_batch_seqlen_balance=use_batch_seqlen_balance ) ...... experience = self._get(experience_columns, indexes) if consumer == "actor_rollout" and self.enable_partial_rollout: ...... # 读完数据,responses状态置为未ready(因为还没有generate完) self.experience_data_status["responses"][indexes] = 0 self.experience_data_status["response_length"][indexes] = 0 ...... |
_sample_ready_index
自动选一批对当前消费者可用的数据索引,如果开启partial rollout并且是actor_rollout阶段,会调用它。此时没有采用负载均衡算法,而是按照顺序采样
|
#mindspeed_rl.trainer.utils.transfer_dock.GRPOTransferDock._sample_ready_index def _sample_ready_index( ...... ): #采样条件:如果不是rollout阶段,要确保update_ready_indexes(prompt的n_sample都ready),因为要按group打分等 if self.enable_partial_rollout and consumer != 'actor_rollout': update_ready_indexes = self.global_ready_mask == 1 usable_indexes = (not_consumed_indexes & data_ready_indexes & update_ready_indexes).nonzero(as_tuple=True)[0] #rollout阶段采样,没上面讲究多 else: usable_indexes = (not_consumed_indexes & data_ready_indexes).nonzero(as_tuple=True)[0] #采样方法:好处保证顺序 if self.enable_partial_rollout and consumer == 'actor_rollout': sampled_indexes = [int(i) for i in usable_indexes[:experience_count]] |
_sample_ready_index_n_samples
和上面功能类似,什么时候用,为什么没有用,有空再细看下
数据跨train iteration
sort_every_n_samples_by_age
对experience数据按照age排序
clear
- 在RayGRPOTrainer.fit一个iteration的最后,会调用clear,对消费完的indexes做置位,包括:
- self.experience_consumer_status
- self.experience_data_status
- self.experience_data
- self.global_ready_mask
- self.rollout_completed
- 更新age
- 调用sort_every_n_samples_by_age对数据按照age排序
- stop_partial_rollout_signal置为False
|
#mindspeed_rl.trainer.utils.transfer_dock.GRPOTransferDock.clear def clear(self): if self.enable_partial_rollout: #iteration结束,走完训练流程的数据indexes,可以清理 all_consumed_indexes = (self.experience_consumer_status["actor_train"] == 1).nonzero(as_tuple=True)[0] if all_consumed_indexes.numel() > 0: #清理指定indexes的消费状态、ready状态、数据(数据不用了) for key in self.experience_consumer_status: self.experience_consumer_status[key][all_consumed_indexes] = 0 self._clear_experience_data_and_status(indexes=all_consumed_indexes) #数据age更新:未清理的数据age+1 self.age = self.age + (self.experience_data_status['input_ids'] == 1).to(torch.int32) self.age[all_consumed_indexes] = -1 #更新其他状态 self.global_ready_mask[all_consumed_indexes] = 0 self.rollout_completed[all_consumed_indexes] = 0 #对数据按照age排序 self.sort_every_n_samples_by_age() ...... self.stop_partial_rollout_signal = False |
辅助:
put_prompts_experience
将原始的数据集中的batch转换为n_sample_per_prompt份,放入transferDock前的准备工作。
在partial rollout模式下,增加了add_another_batch的判断,主要用于处理加入的第二个GBS
|
#mindspeed_rl.trainer.utils.transfer_dock.put_prompts_experience prompt_nums = len(prompt_length) if add_another_batch: indexes = [prompt_nums + i for i in range(prompt_nums)] elif indexes is None: indexes = [i for i in range(len(prompt_length))] |
BaseWorker
all_consumed
略
dispatch_transfer_dock_data
这里partial_rollout对get_experience传参有些区别(再细看)
|
#mindspeed_rl.workers.base_worker.BaseWorker.dispatch_transfer_dock_data elif enable_partial_rollout: # 获取单条数据,不满足的位置补重复样本 dp_world_size = self.parallel_state.get_data_parallel_world_size() batch_data, index = ray.get(self.td.get_experience.remote(experience_consumer_stage, experience_columns, experience_count, dp_world_size, indexes=indexes, get_n_samples=get_n_samples)) else: batch_data, index = ray.get( self.td.get_experience.remote(experience_consumer_stage, experience_columns, experience_count, indexes=indexes, get_n_samples=get_n_samples, use_batch_seqlen_balance=self.rl_config.use_dp_batch_balance)) |
|
#mindspeed_rl.workers.base_worker.BaseWorker.dispatch_transfer_dock_data if rank_flg: batch_data, batch_data_length = pack_experience_columns( experience_consumer_stage, batch_data, experience_count, enable_partial_rollout=enable_partial_rollout) |
collect_transfer_dock_data
略
ActorHybridWorkerBase
推理适配partial rollout的详细逻辑在此实现,重点有以下几点:
- 适配截断数据重新处理:
- 把之前截断数据取出来,prompt和partial response拼一起,重新作为输入
- 如果完成推理,把之前的partial response和新的response拼一起,作为完整的response
- 区分同步异步处理逻辑
- 数据读取逻辑不同
- 数据处理逻辑,停止逻辑不同
初始化:
__init__
|
#mindspeed_rl.workers.actor_hybrid_worker.ActorHybridWorkerBase.__init__ self.enable_partial_rollout = self.rl_config.partial_rollout_max_split > 1 |
推理逻辑
generate_sequences
详细介绍如下:
- 同步模式和异步模式用于推理的batch量(experience_count)是有区别的
|
#mindspeed_rl.workers.actor_hybrid_worker.ActorHybridWorkerBase.generate_sequences if self.enable_partial_rollout and (self.rl_config.async_engine or self.iteration == self.megatron_config.train_iters - 1): #异步模式能把2GBS都读进来(刚开始处理数据是这样的) incomplete_resp_num = ray.get(self.td.get_incomplete_response_num.remote()) experience_count = int(np.ceil(incomplete_resp_num / self.generate_config.data_parallel_size)) else: #同步模式读1GBS去推理 experience_count = self.rl_config.actor_rollout_dispatch_size |
- 同步模式下:
- 调用self.all_consumed判断actor_rollout(推理)阶段是否有GBS_train个prompt完成全部n_sample的推理
- 如果未完成,进入循环逻辑,不断从TransferDock读数据,进行推理;
- 否则跳出推理循环,进入后续阶段reward、ref_logprob、update的流程
- 同步异步模式调用不同的方法推理
|
#mindspeed_rl.workers.actor_hybrid_worker.ActorHybridWorkerBase.generate_sequences while self.all_consumed(experience_consumer_stage, sorted_indexes, use_vllm=True) > 0: batch_data, index = self.dispatch_transfer_dock_data( experience_consumer_stage, experience_columns, experience_count, tp_size=self.megatron_config.tensor_model_parallel_size, cp_size=self.megatron_config.context_parallel_size, cp_algo=self.megatron_config.context_parallel_algo, indexes=sorted_indexes.pop(0) if self.rl_config.guarantee_order else None, use_vllm=True, get_n_samples=not self.enable_partial_rollout, enable_partial_rollout=self.enable_partial_rollout ) if batch_data and index: if self.rl_config.async_engine: logger.info(f"do async generate process.") self.async_generate_process(batch_data, index, pad_token_id) else: self.sync_generate_process(batch_data, experience_count, index, pad_token_id) if self.enable_partial_rollout: torch.distributed.barrier() |
sync_generate_process
同步模式推理逻辑:
- 对于之前阶段被截断的数据,会把prompt, response拼接,用于作为vllm推理的输入
- 通过max_tokens限制推理长度
- 标记rollout_completed位,response中有eod位,或者promt+response长度超过max_model_len,或者response长度超过max_tokens会标记为完成,具体条件参照下面代码
- 将推理生成的数据写入TransferDock
|
#mindspeed_rl.workers.actor_hybrid_worker.ActorHybridWorkerBase.generate_process def async_generate_process(self, batch_data, experience_count, index, pad_token_id): ...... if self.enable_partial_rollout: ...... #把prompt, response拼接重新作为输入(主要针对之前截断数据) prompts_for_vllm = [torch.cat( (prompt, response), dim=0) for prompt, response in zip(prompts, responses_partial)] prompts_list = [prompt.numpy().tolist() for prompt in prompts_for_vllm] if self.enable_partial_rollout: #限制推理生成的长度:max_tokens max_tokens = self.generate_config.sampling_config["max_tokens"] // self.rl_config.partial_rollout_max_split responses_pad_right = \ self.actor_hybrid.generate_sequences( copy.deepcopy(prompts_list), max_tokens=max_tokens, n=1, extra_info=batch_data) ...... if self.enable_partial_rollout: #response重新拼接:之前截断的部分+新生成部分 new_responses = [] for response_partial, response in zip(responses_partial, responses): new_resp = torch.cat((response_partial, response), dim=0) ...... new_responses.append(new_resp) responses = new_responses ...... if self.enable_partial_rollout: #标记rollout_completed位,response中有eod位,或者promt+response长度超过max_model_len,或者response长度超过max_tokens会标记为完成 finish_status = [torch.tensor([0])] * len(responses_length) for idx, _ in enumerate(responses): if responses[idx][-1] == self.tokenizer.eod or \ (prompt_length_data[idx][0] + responses_length[ idx][0] >= self.generate_config.max_model_len) or responses_length[ idx][0] >= self.generate_config.sampling_config["max_tokens"]: finish_status[idx] = torch.tensor([1]) outputs["rollout_completed"] = finish_status #将推理生成的数据写入TransferDock self.collect_transfer_dock_data(outputs, index, use_vllm=True) |
async_generate_process
异步模式推理逻辑,注意会传入stop_singal_func
|
#mindspeed_rl.workers.actor_hybrid_worker.ActorHybridWorkerBase.async_generate_process if self.enable_partial_rollout: response_generator = self.actor_hybrid.generate_sequences( copy.deepcopy(prompts_list), indexes=index, n=1, async_engine=True, stop_singal_func=self.get_partial_rollout_stop_signal, ) |
推理控制逻辑
get_partial_rollout_stop_signal
调用td.get_update_ready,用于获取stop_signal状态,以此来控制vLLM Engine推理是否继续进行
后续计算(ref_logprob、update等)
主要在从TransferDock读取数据的时候,传入self.enable_partial_rollout
|
#mindspeed_rl.workers.actor_hybrid_worker.ActorHybridWorkerBase.compute_log_prob #mindspeed_rl.workers.actor_hybrid_worker.ActorHybridWorkerBase.update #mindspeed_rl.workers.reference_woker.ReferenceWorkerBase.compute_ref_log_prob batch_data, index = self.dispatch_transfer_dock_data(experience_consumer_stage, experience_columns, experience_count, tp_size=self.megatron_config.tensor_model_parallel_size, cp_size=self.megatron_config.context_parallel_size, cp_algo=self.megatron_config.context_parallel_algo, indexes=sorted_indexes.pop( 0) if self.rl_config.guarantee_order else None, get_n_samples=self.enable_partial_rollout) |
ActorRolloutHybrid
generate_sequences
这里主要就是对vLLM Engine进行了调用,区分了同步模式和异步模式调用
|
#mindspeed_rl.models.actor_rollout_hybrid.ActorRolloutHybrid.generate_sequences def generate_sequences( self, prompts_list: List[List[int]], indexes=None, async_engine=False, stop_singal_func=None, **kwargs) -> Tensor: if async_engine: res = self.inference_actor.async_generate_sequences( prompts_list, indexes, stop_singal_func=stop_singal_func, **kwargs, ) else: res = self.inference_actor.generate_sequences(prompts_list, **kwargs)[0] return res |
VLLMInferEngine
下面是同步和异步模式,对vLLM Engine调用的核心逻辑
generate_sequences
顺序模式,直接把idx_list输入,等全部处理完返回结果
|
@torch.no_grad() def generate_sequences(self, idx_list, **kwargs): self.init_cache_engine() ... with self.update_sampling_params(**kwargs): response = self.llm.generate( prompts=prompts, sampling_params=self.sampling_params, prompt_token_ids=idx_list, use_tqdm=False ) outs = self._post_process_outputs(response) self.free_cache_engine() return outs |
async_generate_sequences
异步模式:
- 先把idx_list全部加入engine待处理队列中
- 不断调用self.engine.step()驱动推理一步一步向前执行,并查询是否有prompt处理完成,每完成一条立刻通过yield返回上层调用者处理
- 另外每20 step会获取STOP_SIGNAL状态,用于决定是否停止vLLM Engine推理
|
@torch.no_grad() def async_generate_sequences(self, idx_list, indexes, stop_singal_func=None, **kwargs): STOP_SIGNAL = None with self.update_sampling_params(**kwargs): for i, prompt_token_ids in enumerate(idx_list): request_id = f"req_{indexes[i]}_{uuid.uuid4().hex[:6]}" self.engine.add_request( request_id=request_id, prompt={"prompt_token_ids": prompt_token_ids}, params=self.sampling_params ) count = 0 while self.engine.has_unfinished_requests(): count += 1 if stop_singal_func is not None and count % 20 == 0: STOP_SIGNAL = stop_singal_func() step_outputs = self.engine.step() for output in step_outputs: if output.finished or STOP_SIGNAL: request_id = output.request_id index = int(request_id.split("_")[1]) prompt_ids = [torch.tensor(idx_list[indexes.index(index)])] index = [index] response_ids = self._post_process_outputs([output]) yield (prompt_ids, *response_ids), index if STOP_SIGNAL: self.engine.abort_request([request_id]) |

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 12
12 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)