Ascend C生态纵览:工具链、社区资源与最佳学习路径
想在昇腾生态里从“小白”变成“老炮”?光会写Ascend C代码,顶多算个“码农”;真正的高手,得是“生态玩家”。这篇文章,我不跟你复读官方文档,我要给你画一张完整的“藏宝图”。第一,是昇腾CANN那套复杂但精密的“生产线”(工具链),从代码怎么变成NPU指令,到性能怎么调,这条线上的每个工具都是你的瑞士军刀。第二,是华为和社区攒下的“资源库”,训练营、认证、开源项目、大佬云集的论坛,这些地方藏着
目录
🔍 2.3 性能分析器(Ascend Insight):你的“X光透视仪”
📄 摘要
想在昇腾生态里从“小白”变成“老炮”?我这多年摸爬滚打得出的结论是:光会写Ascend C代码,顶多算个“码农”;真正的高手,得是“生态玩家”。这篇文章,我不跟你复读官方文档,我要给你画一张完整的“藏宝图”。这张图包含三部分:第一,是昇腾CANN那套复杂但精密的“生产线”(工具链),从代码怎么变成NPU指令,到性能怎么调,这条线上的每个工具都是你的瑞士军刀。第二,是华为和社区攒下的“资源库”,训练营、认证、开源项目、大佬云集的论坛,这些地方藏着真经,也藏着机会。第三,也是最重要的,是一条被验证过无数次的“打怪升级路径”,我会告诉你,在什么阶段该干什么、重点学什么、避开哪些坑,让你用最短的时间,从“下载安装包”到能写出性能不输官方库的算子。看完这篇,你不会成为理论家,但会成为知道“弹药库在哪、怎么用、何时用”的实战派。
🧭 第一部分 为什么你需要关心“生态”而不仅仅是“语法”?
很多新手一上来就埋头啃《Ascend C编程指南》,吭哧吭哧写了个Add算子,一跑性能还不如直接调aclblas。挫败感满满,然后得出“Ascend C不好用”的结论。兄弟,你这不叫学技术,你这叫“拿着手术刀当菜刀用”。
在异构计算这个行当干了十几年,我见过太多这样的开发者。他们缺的不是编码能力,而是对完整工具链的认知和对社区资源的利用能力。这就像你要造一辆车,光学了怎么拧螺丝(语法),不知道有生产线(工具链),也不知道有零部件市场(社区资源),更不知道老司机们总结的装配顺序(学习路径),你能造出好车才怪。
昇腾的CANN生态,经过这些年的发展,已经初步形成了一个闭环:
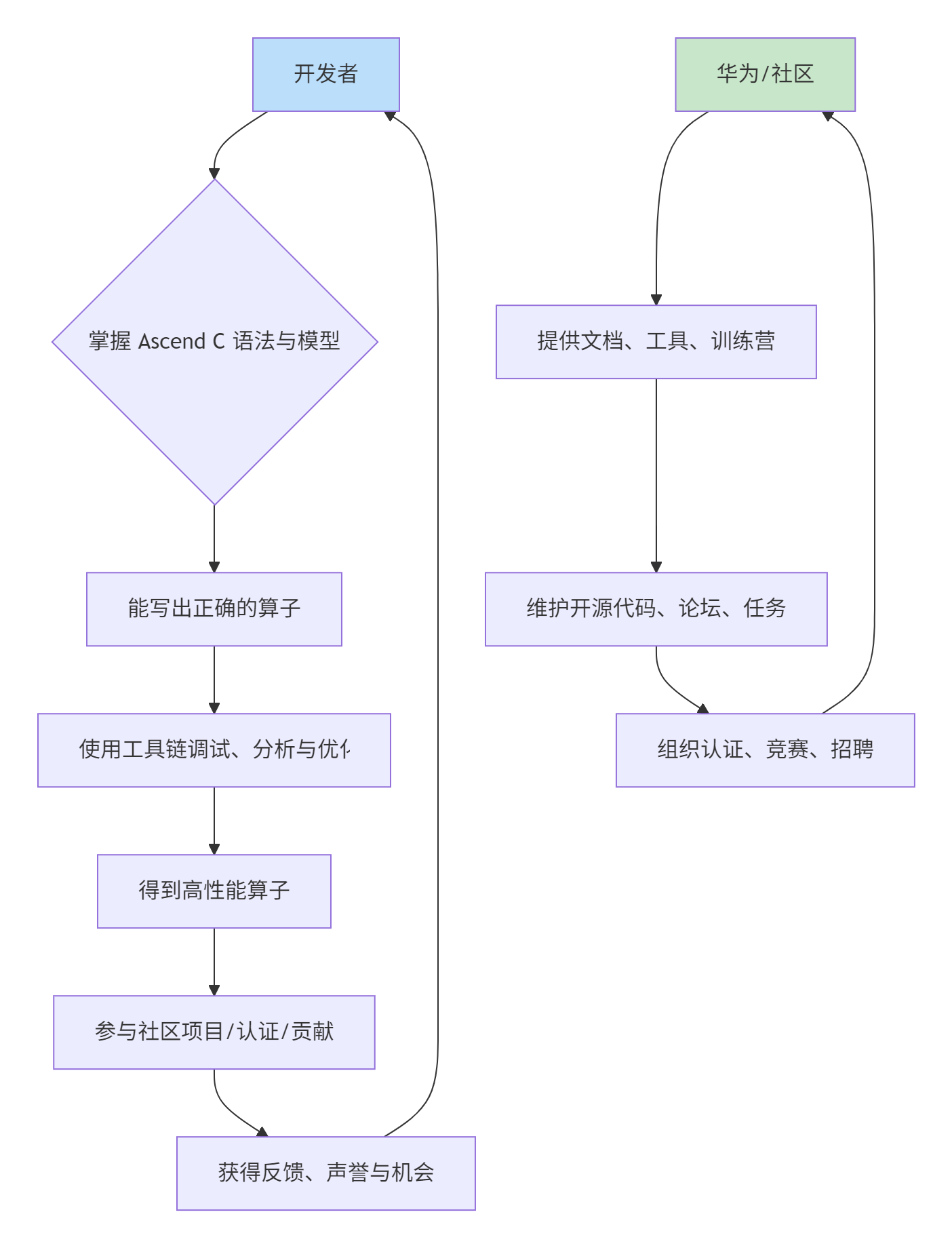
这个闭环里,工具链是让你从“正确”到“高效”的放大镜和手术刀。社区资源是让你从“独行”到“共舞”的广场和舞台。而学习路径,就是穿梭于其间的导航。
下面,我们就先拆解这个生态里最硬核的部分:工具链。
🛠️ 第二部分 工具链深潜:从代码到极致性能的“生产线”
别被“工具链”这个词吓到。你可以把它想象成一条精密的芯片生产线。你的Ascend C源代码是原材料,经过这条线的各道工序,最终变成在NPU上飞奔的、性能榨干的机器码。
📦 2.1 核心工具一览与分工
先上个总览图,看看这条“生产线”的全貌:
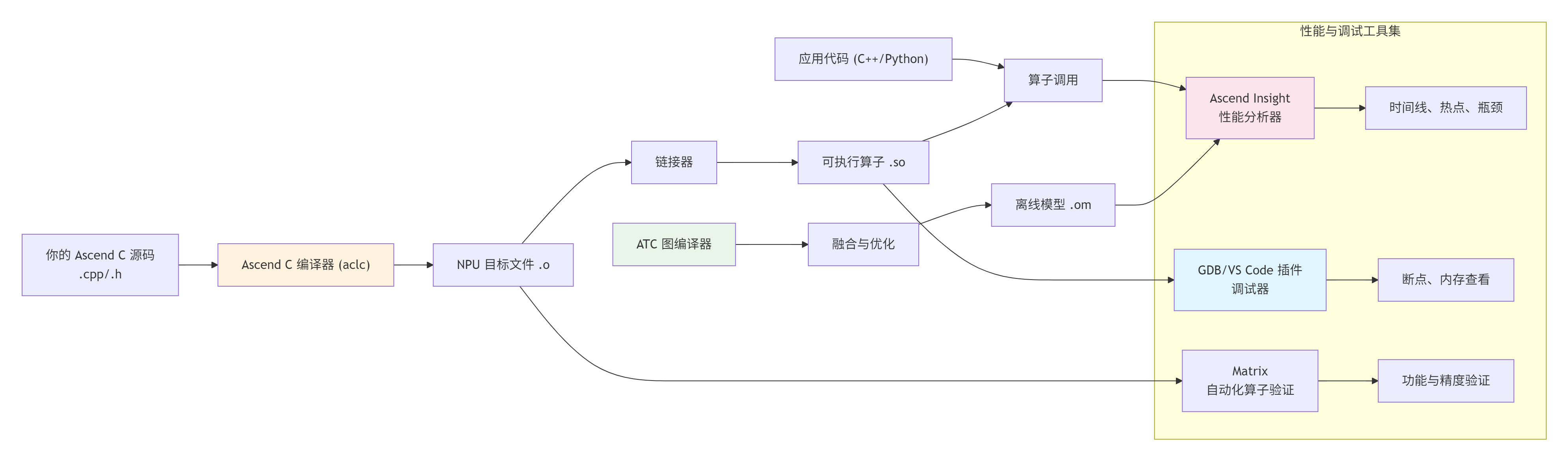
下面我们挑几个最核心、你一定会用到的工具重点讲。
⚙️ 2.2 编译器(aclc):不只是“翻译官”
aclc(Ascend C Compiler)是工具链的基石。但很多人以为它就是个C++编译器换了个名字,大错特错。它是一个“目标导向”的编译器,它的优化策略会根据你写的代码是__global__(核函数)还是__host__(主机函数)而截然不同。
核函数编译的“隐藏关卡”:
当你编译一个带有__global__ __aicore__的函数时,aclc会做一系列神奇的操作:
-
自动向量化与循环展开:它会尝试把你写的循环,转换成NPU向量指令。但它的自动决策不一定最优。这时就需要你通过代码结构(比如用
#pragma或特定内置函数)来“提示”编译器。 -
寄存器分配与优化:NPU的AI Core寄存器文件是有限的。编译器会尽全力让最常用的变量(比如循环索引、累加器)待在寄存器里。但如果你的核函数里声明了太多局部变量,或者
block太大,它就会被迫把一些变量“溢出”(Spill)到更慢的本地内存,性能骤降。 -
生成流水线代码:对于明显的计算-搬运模式,
aclc可能会尝试生成双缓冲(Double Buffer)的指令排布,让数据搬运和计算重叠。
如何与编译器“斗智斗勇”?
分享一个实战经验:我们曾经优化一个复杂的卷积核,无论如何调整BLOCK_SIZE,性能都上不去。最后用编译器生成的汇编(SASS)一看,发现关键的循环被编译器“过度展开”了,导致指令缓存(I-Cache)命中率暴跌。我们在源代码中插入了一个编译指示#pragma unroll(4),明确告诉编译器“这个循环只展开4层”,性能立刻提升了20%。
// 示例:告诉编译器如何展开循环
#define UNROLL_FACTOR 4
__aicore__ void my_kernel(...) {
// ... 一些代码
#pragma unroll(UNROLL_FACTOR)
for (int i = 0; i < ELEMENTS_PER_THREAD; i += UNROLL_FACTOR) {
// 处理 data[i] 到 data[i+UNROLL_FACTOR-1]
}
// ... 更多代码
}给你的建议:永远不要相信编译器的优化是完美的。对于性能关键的核函数,要习惯性地用-S或--keep选项保留中间汇编文件,结合性能分析工具,看看编译器到底把你的代码变成啥样了。
🔍 2.3 性能分析器(Ascend Insight):你的“X光透视仪”
如果说编译器决定了性能的上限,那分析器就是帮你逼近这个上限的向导。Ascend Insight(早期版本可能叫msprof)是NPU版的nvprof或vtune。
它能回答三个灵魂问题:
-
我的算子,时间都花在哪了? (时间线视图)
-
NPU的硬件资源,用满了吗? (AI Core利用率、内存带宽)
-
为什么没跑满?瓶颈是卡在哪了? (瓶颈分析)
看一张真实项目中的性能分析摘要图(模拟数据):
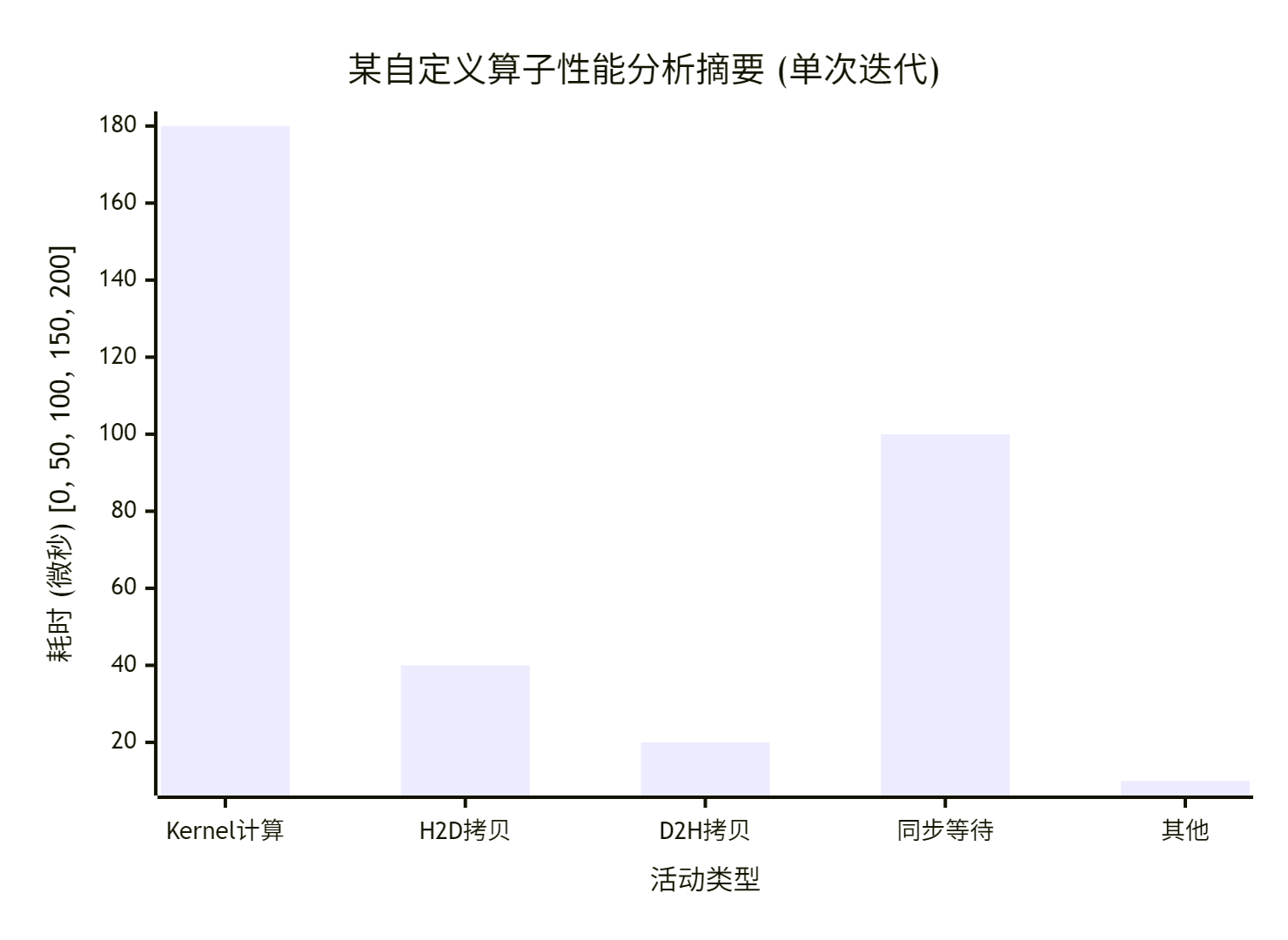
从这张图我们能读出什么?
-
计算不是瓶颈:Kernel计算时间占比高,但AI Core利用率只有65%,说明计算密度不够,或者内存访问模式差,导致Core经常在等数据。
-
拷贝是瓶颈:H2D拷贝带宽远低于峰值,说明数据准备或传输可能有问题。也许你在Host侧用的是
malloc分配的pinned memory?换成aclrtMallocHost分配的主机锁定内存,带宽能上去一大截。 -
同步是杀手:同步等待时间长得不正常。检查代码里是不是在循环里频繁调用了
aclrtSynchronizeStream?试着把同步移到循环外,或者用异步操作和事件(Event)来协同。
高级玩法:Trace View
这才是分析器的精髓。它把Host侧的函数调用、Runtime API、Device侧的Kernel执行、内存拷贝,全都放到一条统一的时间线上。你会看到:
-
Kernel之间的“空隙”(Bubble):如果Kernel不连贯,中间有大段空白,说明Host侧任务下发太慢,或者有同步阻塞。
-
“排队”的Kernel:如果多个Kernel在时间线上堆叠在一起,说明它们可能被提交到了同一个Stream,无法并发。考虑使用多Stream。
-
意外的“小Kernel”:发现一些你根本没写过的、名字奇怪的微小Kernel(比如
Memcpy、Cast、Transpose)。这往往是框架或编译器插入的隐式操作,是性能的“隐藏刺客”。你需要重构代码来消除它们。
🧪 2.4 自动化测试与验证工具(Matrix)
企业级开发和个人玩票的最大区别之一,就是测试的完备性。你写的算子,不仅要在你的环境下跑通,还要在各种奇奇怪怪的输入形状、数据类型、边界条件下都能工作,并且精度符合要求。
手动测试?累死你,而且覆盖不全。Matrix(或类似工具)就是干这个的。你可以把它理解为一个算子级的CI/CD(持续集成/持续部署)框架。
它能帮你做什么?
-
自动生成测试用例:你定义好输入张量的范围(如
shape: [1~1024, 1~1024],dtype: [float16, float32]),它能自动生成海量测试数据。 -
与参考实现对比:通常需要一个CPU的NumPy实现作为“黄金标准”(Golden Reference)。
Matrix会分别运行你的Ascend C算子和参考实现,对比结果。 -
精度验证:不是简单的
==,而是计算相对误差|your_out - ref_out| / (|ref_out| + eps),并统计最大误差、平均误差,看是否在可接受范围内(如1e-3for fp16)。 -
回归测试:每次代码改动后,一键跑所有历史用例,确保没引入新bug。
一个简化的测试配置示例(YAML格式):
# test_sigmoid.yaml
operator: CustomSigmoid
inputs:
- name: x
dtype: [float16, float32]
shape: [[1], [16, 256], [32, 128, 64]] # 多种形状
range: [-10.0, 10.0] # 数值范围
outputs:
- name: y
dtype: same_as_input
validation:
reference: numpy_sigmoid # 指向一个Python函数
atol: 1e-3 # 绝对容差
rtol: 1e-3 # 相对容差
metric: [max_diff, mean_squared_error] # 统计的指标用上Matrix,你才能拍着胸脯说:“我的算子,质量有保障。”
🤝 第三部分 社区资源全景:你的“外挂”与“加速器”
工具链让你“能打”,社区资源则决定你能“打多远”、“打多高”。昇腾的社区,经过这几年的运营,已经从一个简单的“技术支持论坛”,进化成了一个有活力、有沉淀、有机会的开发者生态圈。
🏫 3.1 训练营:手把手带你“上路”
图片里提到的“CANN训练营”,是社区最经典的入门活动。但参加过的人都知道,训练营和训练营之间,差距巨大。一个好的训练营,应该是一个精心设计的“学习漏斗”。
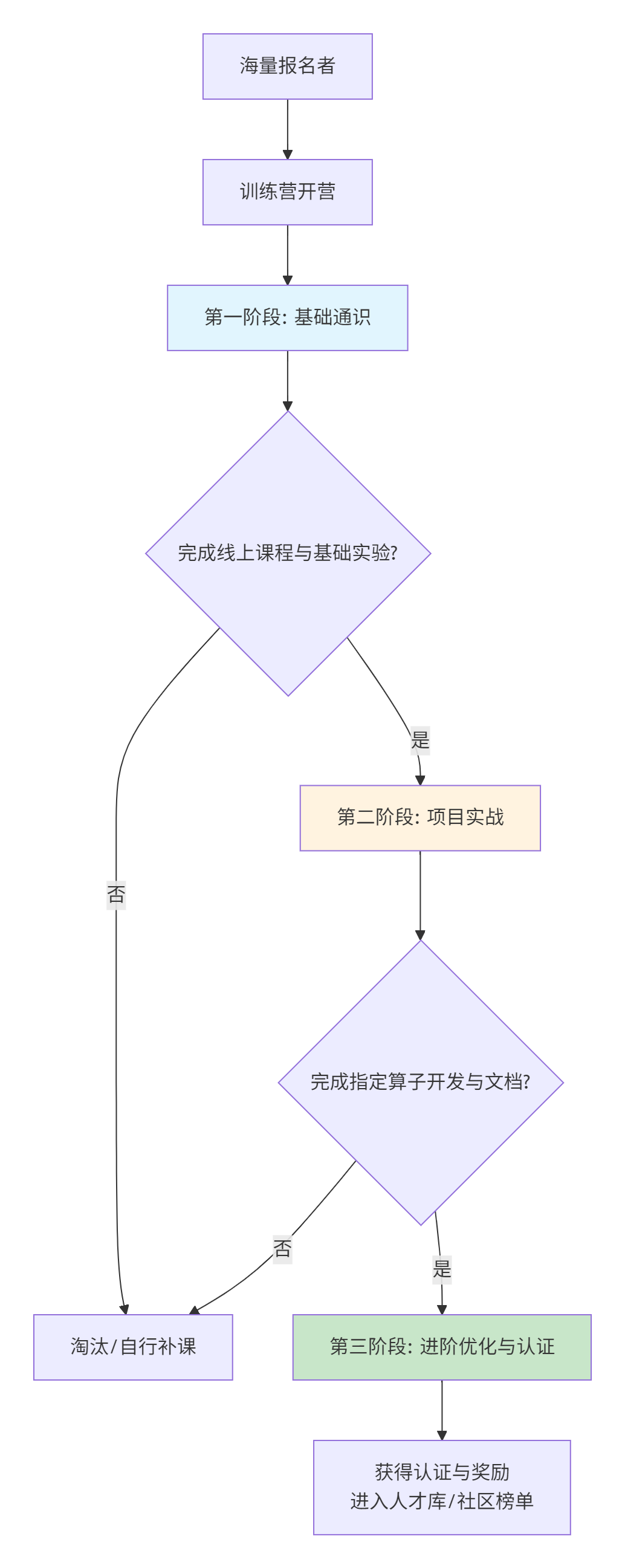
如何从训练营获得最大收益?
-
别当“观光客”:很多人报了名,听完直播就结束了。你要动手。直播里的代码,一定要在环境里敲一遍,跑通,然后尝试修改参数,看看结果怎么变。
-
利用好“助教”和“同学”:训练营的交流群不是用来吹水的。把你调试不过的报错信息、看不懂的代码截图扔进去。99%的问题,助教或早一步的同学都遇到过。这是最快的解决问题途径。
-
瞄准“项目实战”:基础课是“学”,项目才是“习”。把项目要求的算子,不仅实现功能,还要尝试去优化性能。把你的优化思路和结果(哪怕只有一点点提升)写到实验报告里,这会是简历上非常漂亮的一笔。
🎓 3.2 能力认证:你的“官方段位”
华为的“Ascend C算子开发能力(中级)认证”,越来越有含金量。它不再是简单的选择题考试,而是实打实的项目实操。图片里提到的“Sigmoid算子”开发任务,就是典型的认证考题。
认证的真正价值是什么?
-
对个人:一个权威的、可验证的能力背书。在求职、参与开源项目、接洽企业合作时,这是打破信任壁垒的硬通货。
-
对社区/企业:一个高效的人才筛选机制。能通过认证,至少说明这个人有基本的动手能力、能看懂文档、能解决环境问题。
通关秘籍(图片里提到了,我展开讲):
认证考题通常分解为几个文件,考察你对Ascend C算子开发固定范式的理解:
-
Kernel实现 (
kernel.cpp):考察你最基本的__aicore__函数编写、内存操作和并行计算思维。 -
Host侧封装 (
host.cpp):考察你如何调用Kernel、管理内存、处理流。这里的关键是理解Tiling策略——如何把一个大任务合理切分给成千上万个AI Core。 -
算子信息注册 (
op_info.cpp):考察你如何将自定义算子接入CANN框架,让上层(如TensorFlow/PyTorch插件)能够调用。
一个常见的坑:认证环境可能是离线的,没有互联网。你平时依赖的ctrl+c/ctrl+v从StackOverflow找答案行不通了。所以,考前一定要在模拟环境里,把开发、编译、运行的完整流程闭卷走几遍,把常用API记在脑子里。
🌐 3.3 开源项目与代码仓库:站在巨人肩上
“不要重复造轮子”是程序员的美德。在昇腾生态里,轮子主要集中在两个地方:
-
CANN 官方仓库 (
gitee.com/ascend/cann):这是核心。除了源码,更重要的是里面的samples目录。那里的例子,是官方工程师写的、符合最佳实践的“样板代码”。从最简单的向量加到复杂的卷积,应有尽有。你的学习顺序应该是:先跑通样例,然后模仿着写,最后再去创新。 -
ModelZoo (
gitee.com/ascend/modelzoo):这里不仅有模型,更有大量模型的昇腾实现。看这些代码,你能学到:-
如何用Ascend C实现复杂的算子(如Attention)。
-
如何组织一个大型算子工程。
-
性能和精度调优的实际技巧。
-
最重要的是,你能看到顶尖的昇腾开发者是如何思考问题的。
-
参与开源:当你能力足够,去给这些仓库提Issue和Pull Request。哪怕只是修复一个文档错别字,也是一个开始。这能让你进入社区核心开发者的视野,获得意想不到的指导机会。
💬 3.4 技术论坛与社群:永不落幕的“技术峰会”
昇腾社区论坛、微信/钉钉的技术交流群,是“活”的知识库。这里你能看到:
-
最新的Bug和解决方案:官方文档来不及更新,但某个工程师在论坛里的回复可能救你于水火。
-
未被文档化的“黑魔法”:某些高级API的隐藏用法、某个编译器选项的真实效果,只在老手们的讨论中流传。
-
一线的需求与趋势:其他公司用昇腾在做什么项目,遇到了什么难题。这可能是你未来的职业方向或创业灵感。
在社群提问的艺术:
-
烂问题:“我的代码报错了,怎么办?”(附一张巨大的、模糊的截图)
-
好问题:“我在开发
Sigmoid算子,使用aclc编译时遇到链接错误:undefined reference to ‘func_name‘。我已确认在.cpp文件中定义了该函数,并在.h中声明。我的编译命令是aclc -I./include src/kernel.cpp src/host.cpp -o op.so。环境是CANN 7.0。请问可能是什么原因?”后者包含了上下文、错误信息、你的尝试、你的环境,别人一眼就能看出问题(比如,可能是函数签名不一致,或者没加
extern “C“),帮你解答的效率极高。
🧭 第四部分 最佳学习路径:从入门到高手的“导航图”
结合我带了无数新人的经验,以及社区成功开发者的轨迹,我为你绘制了下面这张“导航图”。这张图不是时间表,而是能力进阶的里程碑。
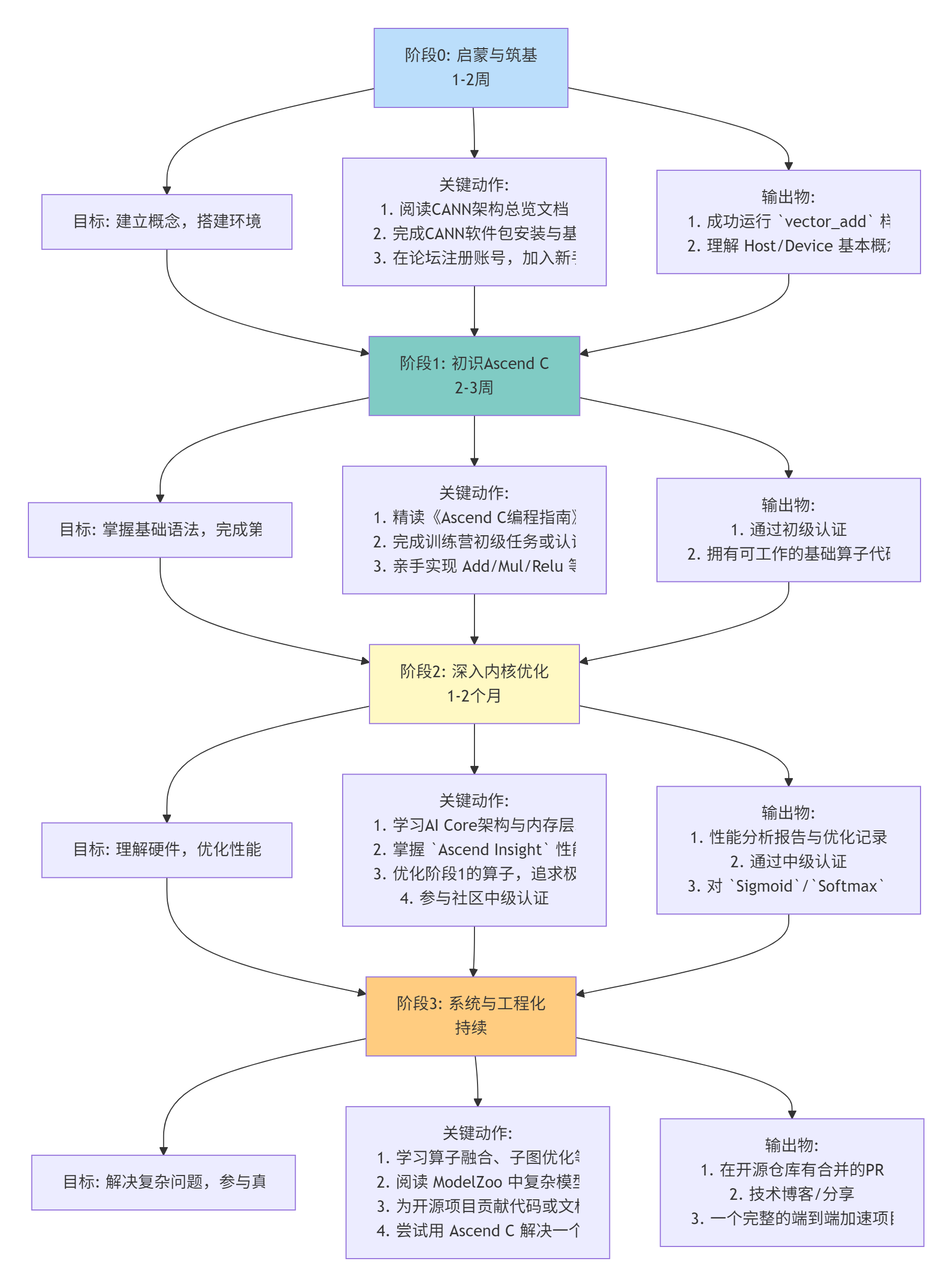
针对每个阶段的一些“私货”建议:
-
阶段0:环境搭建是第一个拦路虎。如果卡住了,别死磕。立刻去论坛搜错误信息,99%有人遇到过。还没有?马上发帖提问。时间最宝贵。
-
阶段1:不要满足于“跑通”。要问“为什么”。为什么核函数要加
__global__ __aicore__?为什么内存拷贝要用aclrtMemcpy?搞懂背后的设计理念,后面学起来会快十倍。 -
阶段2:这是“劝退”高发区,也是“高手”孵化区。性能优化会反复折磨你,一个参数调几天可能毫无进展。这时,一定要用数据说话,依赖
Ascend Insight,找到真正的瓶颈。多和社区里的优化高手交流,他们点拨一句,可能省你一周。 -
阶段3:尝试把你学到的技能“变现”。可以是写技术文章建立影响力,可以是在公司内部推动昇腾的应用,也可以是参与社区项目赢得荣誉。技术只有在解决真实问题时,才有价值。
🧪 第五部分 实战:一个完整的“Sigmoid”算子诞生记
我们以图片中提到的“Sigmoid算子”作为蓝本,走一个完整的开发流程。这里不仅仅是写Kernel,而是展示如何利用我们前面讲的工具链和社区资源。
🚀 5.1 环境准备与项目初始化
第一步:获取资源
-
从CANN仓库的
samples目录找到算子开发样例。假设我们找到了/samples/operator/Add。 -
把这个样例复制一份,重命名为
Sigmoid。这就是我们的项目脚手架。
第二步:理解目录结构
Sigmoid/
├── CMakeLists.txt # 编译脚本
├── data.py # 生成测试数据的脚本 (如果有)
├── include/
│ ├── sigmoid.h # 算子头文件 (需要修改)
│ └── sigmoid_tiling.h # Tiling策略定义 (需要修改)
├── op_host/
│ └── sigmoid_host.cpp # Host侧代码 (需要修改)
├── op_kernel/
│ └── sigmoid_kernel.cpp # Kernel代码 (需要修改)
└── run/
└── run.sh # 一键运行脚本 (需要修改)第三步:搭建调试环境
-
在VSCode中安装C/C++插件和华为昇腾插件。
-
配置
CMake工具链指向CANN的aclc。 -
配置调试器(
gdbserver)连接远程NPU设备。 -
这一步很繁琐,但一劳永逸。社区有详细的图文教程,跟着做。
⚙️ 5.2 Kernel实现:从数学公式到并行代码
Sigmoid公式:y=1+e−x1
一个直观但低效的实现:
// 初版 sigmoid_kernel.cpp (低效示例)
#include “sigmoid_tiling.h”
__global__ __aicore__ void sigmoid_kernel(const float* x, float* y, const SigmoidTiling* tiling) {
int idx = GET_BLOCK_IDX(); // 当前处理块索引
int offset = idx * tiling->tile_length; // 本块数据起始偏移
int remain = tiling->total_length - offset;
int deal_len = min(tiling->tile_length, remain);
// 为每个元素计算Sigmoid
for (int i = 0; i < deal_len; ++i) {
float val = x[offset + i];
y[offset + i] = 1.0f / (1.0f + expf(-val));
}
}问题:循环内每次计算都要调用昂贵的expf函数,且是标量计算,没有利用向量指令。
优化版实现:
// 优化版 sigmoid_kernel.cpp
#include “sigmoid_tiling.h”
#include <cmath>
constexpr int VEC_LEN = 8; // 假设一次处理8个float
__global__ __aicore__ void sigmoid_kernel_opt(const float* __restrict__ x, float* __restrict__ y, const SigmoidTiling* tiling) {
int idx = GET_BLOCK_IDX();
int offset = idx * tiling->tile_length;
int remain = tiling->total_length - offset;
int deal_len = min(tiling->tile_length, remain);
// 1. 处理向量化部分
int vec_deal_len = (deal_len / VEC_LEN) * VEC_LEN;
for (int i = 0; i < vec_deal_len; i += VEC_LEN) {
// 一次性加载8个float (伪代码,实际用向量加载指令)
float8 vec_x = vload8(&x[offset + i]);
// 向量化计算 Sigmoid: 1.0 / (1.0 + exp(-x))
// 这里需要用到向量化的 exp 和除法。Ascend C 可能提供内置函数。
float8 vec_neg_x = -vec_x;
float8 vec_exp = vexpf8(vec_neg_x); // 向量化exp
float8 vec_denom = 1.0f + vec_exp;
float8 vec_y = 1.0f / vec_denom; // 向量化除法
vstore8(&y[offset + i], vec_y);
}
// 2. 处理尾部剩余标量
for (int i = vec_deal_len; i < deal_len; ++i) {
float val = x[offset + i];
y[offset + i] = 1.0f / (1.0f + expf(-val));
}
}优化点:
-
__restrict__关键字告诉编译器指针不重叠,便于优化。 -
手动进行循环向量化,一次处理8个数据,充分利用硬件。
-
使用了假设的向量化数学函数(
vexpf8),在实际Ascend C中,可能需要调用特定的内置函数或库。
🔧 5.3 Host侧封装与Tiling策略
Tiling是精髓:如何把100万个元素的任务,合理分给1000个AI Core?
// sigmoid_tiling.h
typedef struct {
int32_t total_length; // 总数据长度
int32_t tile_length; // 每个核处理的数据长度
} SigmoidTiling;
// sigmoid_host.cpp (片段)
aclError Sigmoid(void* x, void* y, int32_t total_length, aclrtStream stream) {
// 1. 计算Tiling
int32_t block_num = 256; // 假设启动256个block
int32_t tile_len = (total_length + block_num - 1) / block_num; // 向上取整
SigmoidTiling tiling{total_length, tile_len};
// 2. 将Tiling结构体拷贝到Device
void* tiling_device = nullptr;
ACL_CHECK(aclrtMalloc(&tiling_device, sizeof(tiling), ...));
ACL_CHECK(aclrtMemcpy(tiling_device, sizeof(tiling), &tiling, sizeof(tiling), ACL_MEMCPY_HOST_TO_DEVICE));
// 3. 启动Kernel
rtL2Ctrl_t* l2ctrl = nullptr;
ACL_CHECK(aclrtKernelLaunch((void*)sigmoid_kernel_opt, block_num, l2ctrl, stream,
x, y, tiling_device));
// 4. 释放资源 (略)
return ACL_SUCCESS;
}Tiling的考量:block_num(并行度)和tile_len(负载)需要平衡。太多block可能导致调度开销大,太少则无法利用所有计算核心。一个经验是让block_num是AI Core数量的整数倍,并且tile_len是向量宽度的整数倍。
🧪 5.4 测试、验证与性能分析
-
功能测试:写一个简单的C++测试程序,生成随机数据,调用你的算子,并用CPU计算对比。
-
使用Matrix:编写YAML测试描述文件,进行大规模、自动化的精度测试。
-
性能分析:
-
用
Ascend Insight分析你的Kernel。 -
关键指标:AI Core利用率、内存带宽、L1/L2缓存命中率。
-
尝试调整
VEC_LEN、block_num,观察性能变化,找到最优组合。
-
记录你的优化过程,这本身就是一份宝贵的技术财富。下图展示了一个假设的优化迭代过程:
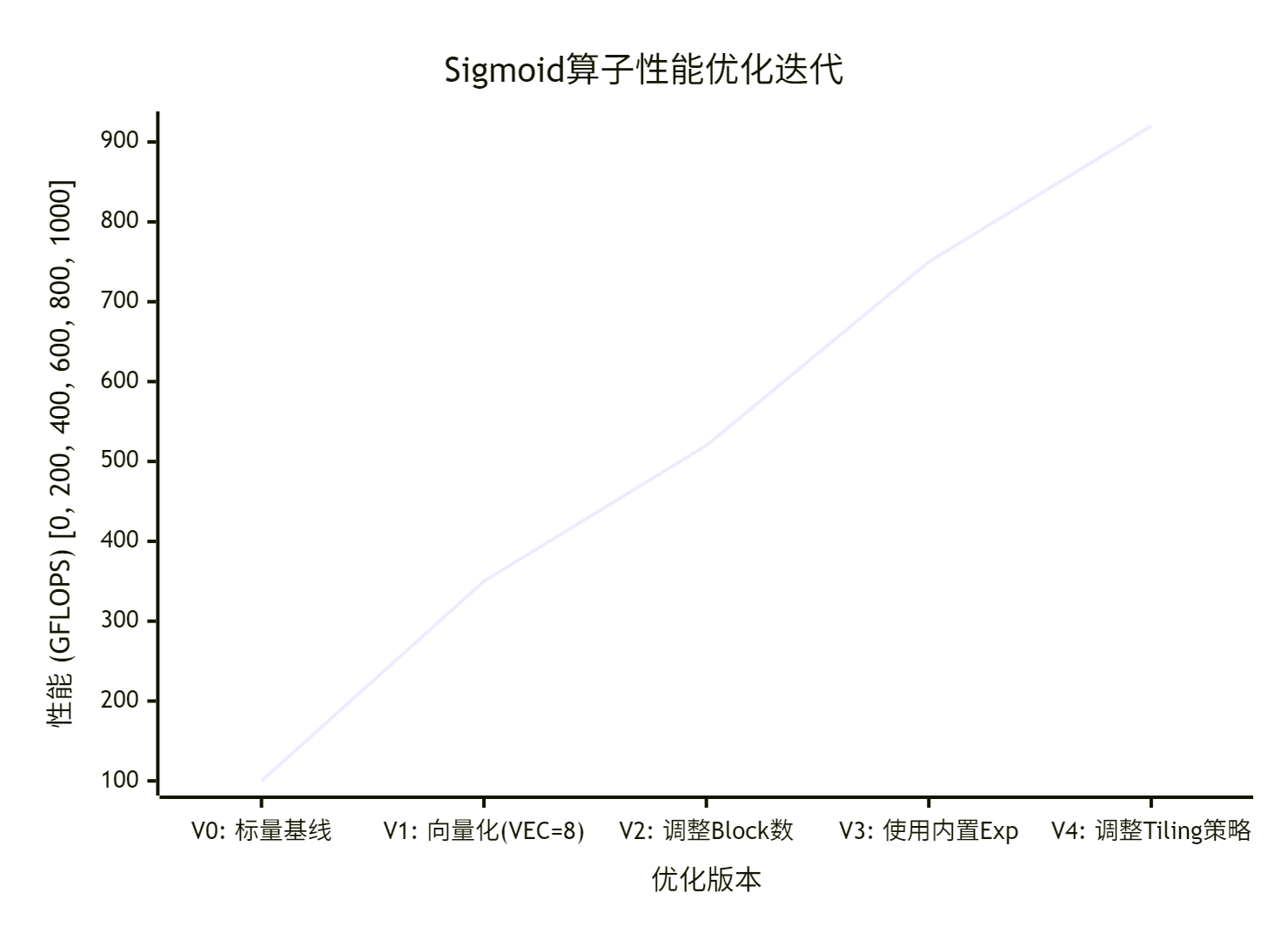
🏢 第六部分 通往专家之路:思维、案例与避坑
当你掌握了单个算子的开发,你的视野应该上升到系统层面。
🧠 6.1 思维转型:从“算子作者”到“系统架构师”
-
从“快”到“省”:早期追求算子的峰值性能(FLOPS)。后期要追求能效比(FLOPS per Watt)和资源利用率。在一个模型中,让所有算子平衡地跑起来,比某个算子单独飞更重要。
-
从“实现”到“抽象”:看到
Conv、LSTM、Attention,不再想“怎么写”,而是想“它们由哪些基础计算模式(Pattern)构成?能否设计一个更通用的、可参数化的超级算子,通过配置来生成它们?” 这就是编译器的思维。 -
从“编码”到“设计”:动手写代码前,花更多时间在设计文档上。明确算子的接口、功能、性能目标、测试方案、潜在风险。这能节省大量的调试时间。
📈 6.2 企业级案例解读:语音识别引擎的端到端延迟优化
背景:一家云服务厂商,要将语音识别服务部署在昇腾服务器上。识别引擎包含:音频预处理(FFT)、声学模型(RNN-T)、语言模型(Transformer)、后处理。
挑战:端到端延迟要求<100ms,但初期部署延迟>200ms。
我们的优化旅程:
-
分析:用
Ascend Insight抓取完整请求的Trace。发现40%的时间花在Host-Device的数据拷贝和格式转换上,尤其是音频预处理(在CPU)和声学模型(在NPU)之间。 -
优化1:流水线重构:
-
将音频预处理(FFT、梅尔滤波器组)用Ascend C重写,作为整个推理流水线的第一个算子。
-
实现“双缓冲”:当NPU在执行第N帧的声学模型时,Host正在准备第N+1帧的音频数据。两者重叠。
-
-
优化2:算子融合:
-
声学模型中的多个
LayerNorm+Linear+ReLU小算子,融合成一个自定义大算子。 -
Transformer解码步中的
Beam Search逻辑,从Host移到Device,避免每一步结果都D2H。
-
-
优化3:模型轻量化与量化:
-
与算法团队合作,对模型进行INT8量化,在精度损失<0.5%的前提下,将计算和访存量减少一半。
-
-
结果:端到端延迟从>200ms降低到65ms,满足SLA。服务器单卡并发路数提升3倍。
这个案例的启示:企业级优化是一个系统工程,涉及算法、算子、运行时、编译等多个层面。你需要和不同角色的人沟通,并用数据(Profiling)说服他们。
⚠️ 6.3 高级避坑指南
-
内存一致性:NPU可能有多个内存空间(HBM、DDR、片上存储)。确保你的数据在正确的空间,用正确的API访问。混用会导致极难调试的随机错误。
-
异步与同步:深刻理解
Stream和Event。默认流是全局的,容易造成意外的同步。为独立的任务链使用不同的流,并在需要时用事件同步。 -
数值稳定性:在NPU上,
float16的表示范围小,计算exp(x)在x较大时容易溢出。在写算子时,要有数值稳定性的考虑(比如,对于Sigmoid,可以用x > 0 ? 1/(1+exp(-x)) : exp(x)/(1+exp(x))来避免exp(-大数)溢出)。 -
平台差异:昇腾910、310P、910B,硬件特性有差异。你的算子可能需要在不同平台上微调参数(如
BLOCK_SIZE)。在代码中用宏或运行时检测来适配。
🎯 总结
走遍昇腾生态这“十年”,我的最大感受是:这是一场马拉松,不是百米冲刺。 最快的入门方式,不是熬夜啃完所有文档,而是立即动手,在真实的问题中学习。用熟工具链,融入社区,遵循一条被验证的路径。
Ascend C生态正在飞速成熟,机会窗口依然敞开。现在投入时间,你积累的不仅是技术,更是对未来AI算力格局的深刻理解。这可能是你职业生涯中,最具前瞻性的一笔投资。
最后,用我喜欢的一句话结尾:“The best time to plant a tree was 20 years ago. The second best time is now.” 学习昇腾,就是现在。
📚 参考链接
-
昇腾社区官方首页- 生态入口与资源中心
-
Ascend C官方文档- 最权威的技术参考
-
昇腾样例仓库- 大量实用示例代码
-
MindStudio工具介绍- 开发环境详细指南
-
昇腾论坛- 技术交流与问题解答
🚀 官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 22
22 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)